- Title: Falcon-H1R Pushing the Reasoning Frontiers with a Hybrid Model for Efficient Test-Time Scaling
- ArXiv ID: 2601.02346
- 발행일: 2026-01-05
- 저자: Falcon LLM Team, Iheb Chaabane, Puneesh Khanna, Suhail Mohmad, Slim Frikha, Shi Hu, Abdalgader Abubaker, Reda Alami, Mikhail Lubinets, Mohamed El Amine Seddik, Hakim Hacid
📝 초록
대규모 언어 모델(LLMs)은 복잡한 추론 작업을 수행하는 데 있어 큰 성과를 거두었으며, 이는 훈련 및 추론 시 확장성을 통해 달성되었습니다. 훈련 확장을 통해 LLMs는 더 복잡한 문제 해결 능력을 갖추게 되지만, 이를 위해 필요한 계산 자원이 증가하고 고급 데이터가 제한적일 수 있습니다. 이러한 문제를 해결하기 위해 시험 시간 확장(TTS)이라는 새로운 방법론이 도입되었으며, 이는 추가적인 추론 시 계산 자원을 할당하여 잠재적인 추론 능력을 향상시킵니다. Falcon-H1R은 TTS 방법론을 활용해 추론 효율성을 높이는 7B 모델입니다.
💡 논문 해설
#### 3개의 핵심 기여
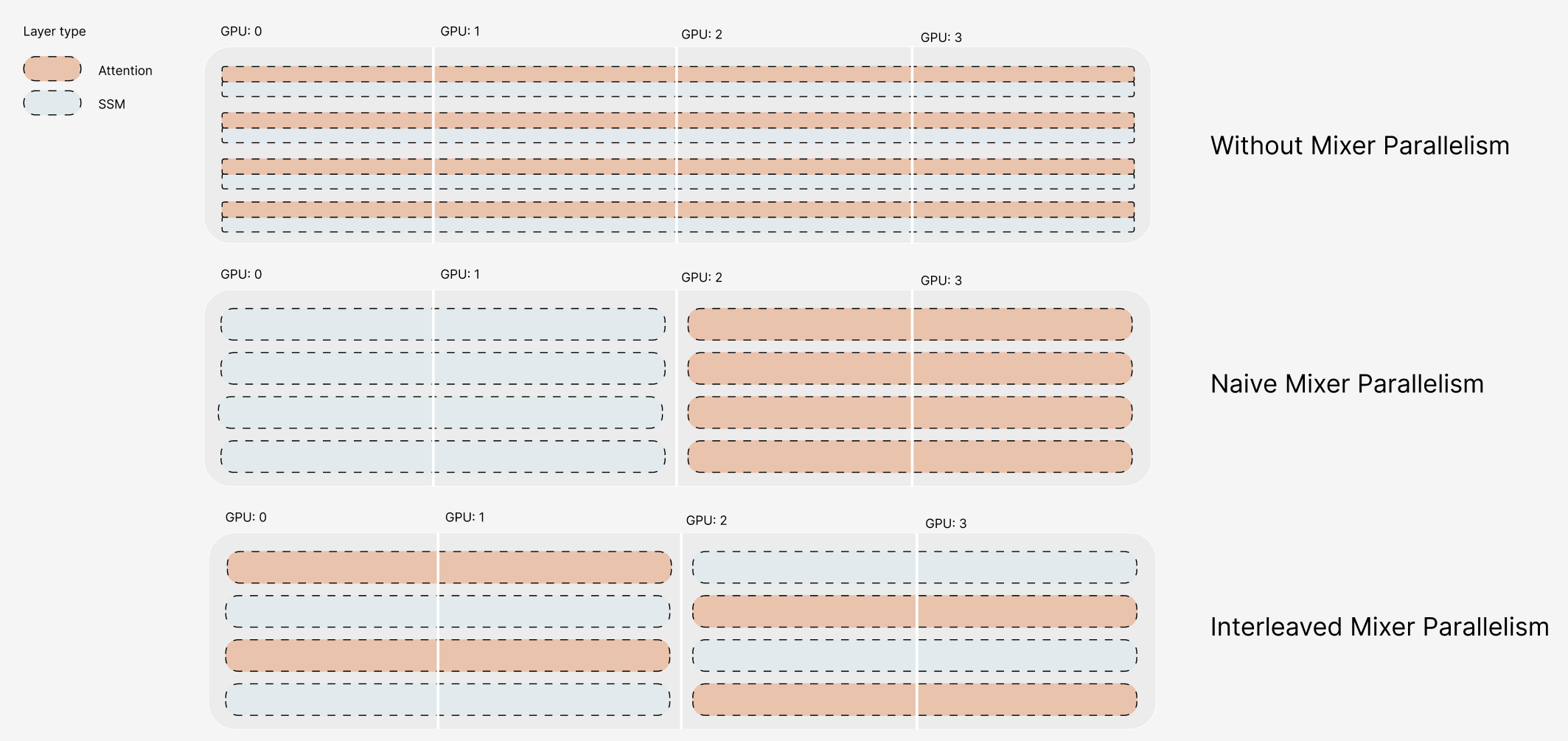
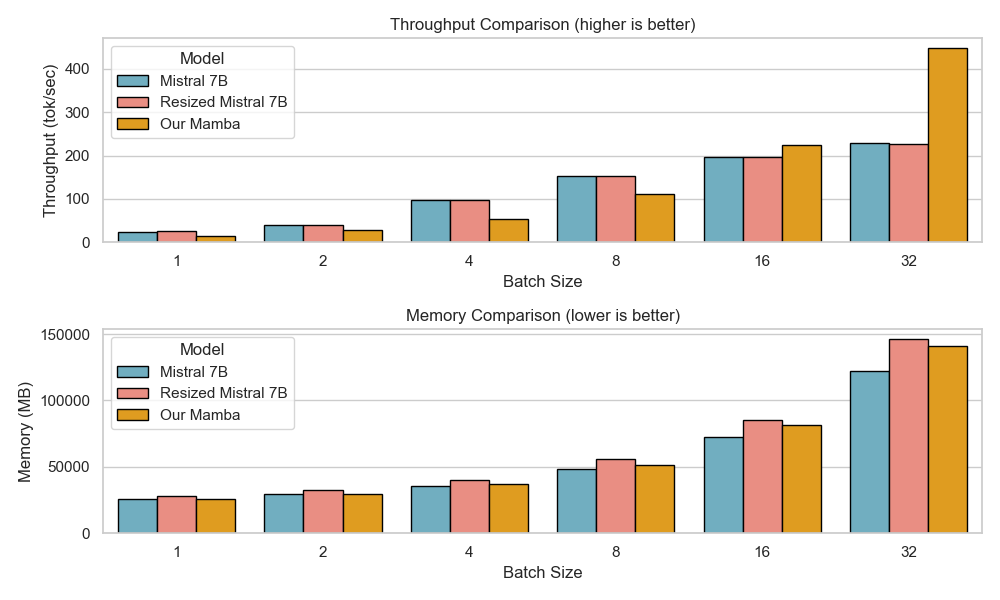
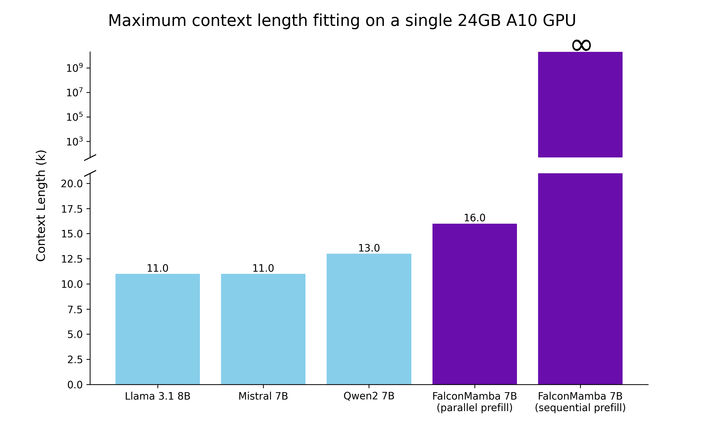
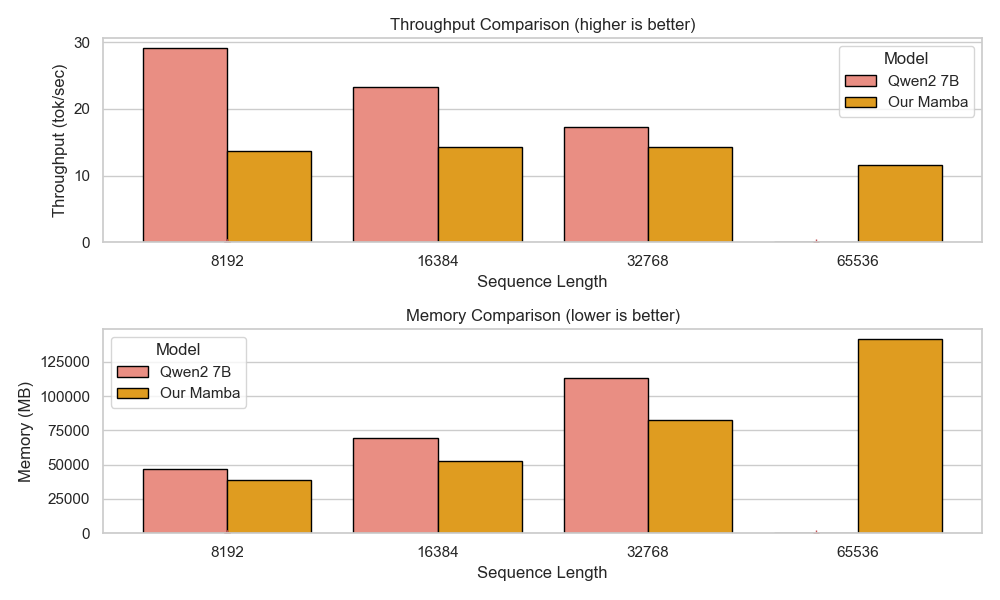
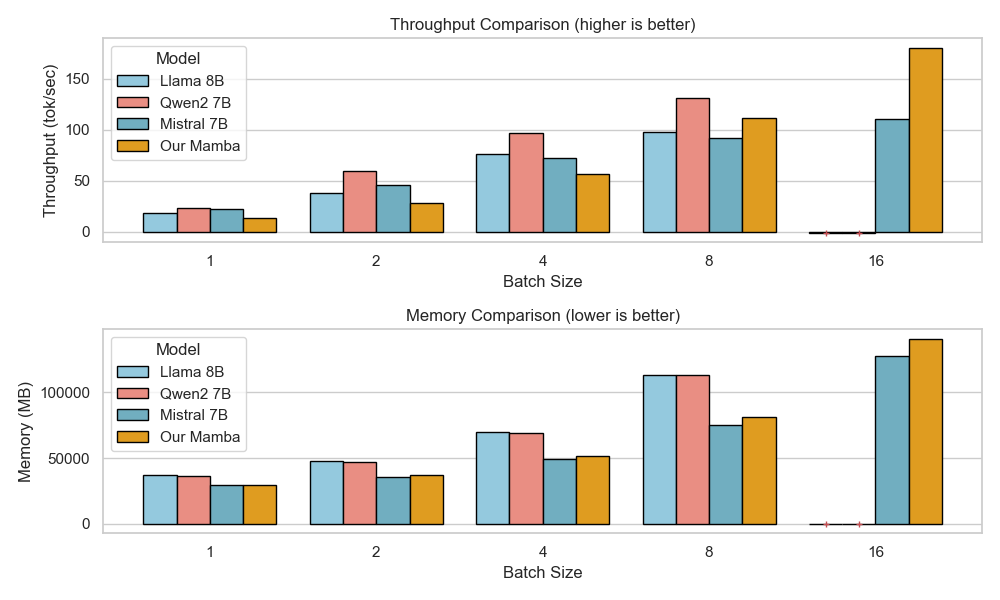
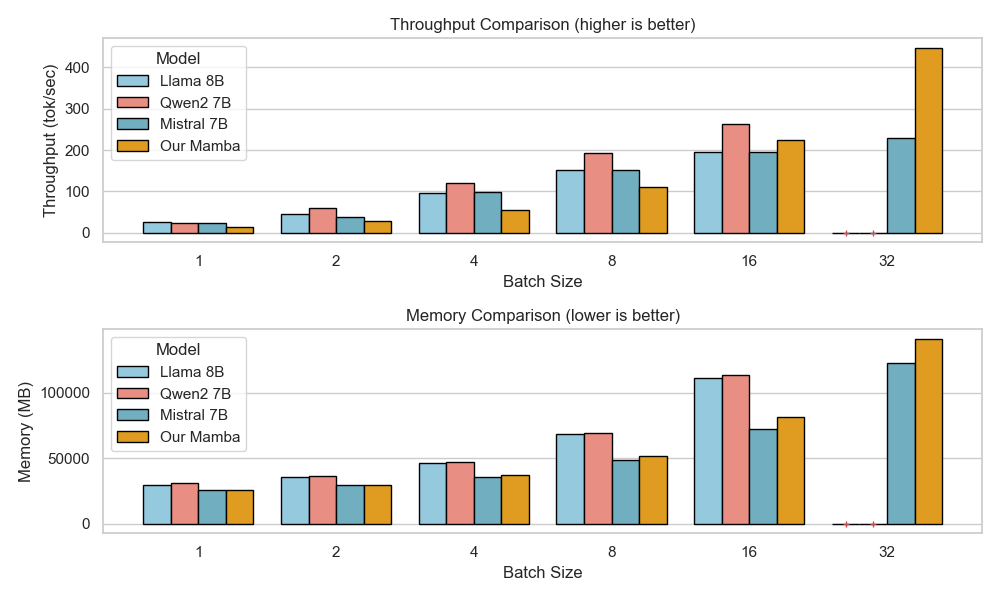
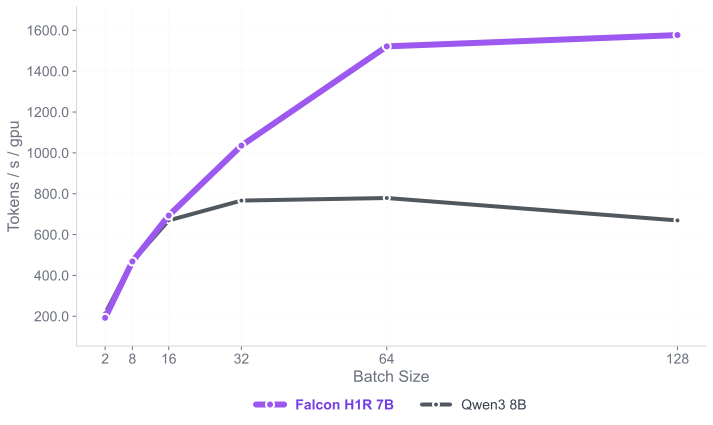
하이브리드 아키텍처를 통한 효율적인 추론: Falcon-H1R은 Transformer–Mamba 하이브리드 구조를 사용해 높은 처리 속도와 낮은 메모리 사용을 제공합니다. 이는 대규모 배치 작업에서 뛰어난 성능을 발휘하며, 병렬 추론 확장에 이상적인 기반이 됩니다.
강력한 훈련 전략: Falcon-H1R은 긴 추론 경로를 포함하는 데이터셋에서 시작하여 감독 학습과 강화학습을 통해 훈련됩니다. 이를 통해 다양한 도메인에서 높은 성능을 달성하며, 특히 수학 문제 해결 및 코드 생성 등에서 우수한 결과를 보여줍니다.
TTS를 통한 효율성 및 정확도 개선: Falcon-H1R은 추론 비용을 줄이면서도 뛰어난 추론 성능을 제공합니다. 이를 통해 TTS 방법론의 효과를 극대화하며, 다양한 추론 벤치마크에서 우수한 결과를 보여줍니다.
단순 설명과 유머러스 메타포 (Sci-Tube 스타일)
하이브리드 아키텍처: Falcon-H1R은 “Transformer와 Mamba"라는 두 마법사의 협력으로 만들어졌습니다. Transformer는 빠른 처리 속도를, Mamba는 효율적인 메모리를 제공합니다. 이 두 가지의 결합이 바로 Falcon-H1R입니다.
강력한 훈련 전략: Falcon-H1R은 “수학 마스터"와 “코드 프로그래머"라는 두 스승에게서 배우며, 다양한 문제를 해결할 수 있는 능력을 갖추었습니다.
TTS를 통한 효율성 및 정확도 개선: Falcon-H1R은 “시간 여행 기계"를 사용해 미래의 결과를 예측하고 최적의 결정을 내리는 데 필요한 계산 비용을 줄이는 방법론을 활용합니다.
📄 논문 발췌 (ArXiv Source)
2026-01-30
Falcon-H1R: 효율적인 시험 시간 확장(TTS)을 위한 하이브리드 모델로 추론 전선 향상하기
Falcon LLM Team[^1]
Iheb Chaabane Puneesh Khanna Suhail Mohmad Slim Frikha
Shi Hu Abdalgader Abubaker Reda Alami Mikhail Lubinets
Mohamed El Amine Seddik Hakim Hacid
대규모 언어 모델(LLMs)은 복잡한 추론 작업을 수행하는 데 있어 큰 성과를 거두었으며, 이는 훈련 및 추론 시 확장성을 통해 달성되었습니다.
훈련 확장: 고급 데이터로 감독 학습(SFT)을 진행하고 이를 강화학습(RL)으로 최적화합니다.
추론 확장: 복수의 해결책 체인을 생성 및 집계하는 병렬 사고 방법론을 제안합니다.
훈련 확장 전략은 LLMs가 점점 더 복잡한 추론 작업에 대처할 수 있도록 했습니다. 그러나 최근 연구에서 순수한 사전 학습의 진전이 계산 자원 요구 증가와 고급 데이터 부족으로 인해 둔화되고 있음을 지적하고 있습니다. 이러한 문제를 해결하기 위해 시험 시간 확장(TTS)이라는 새로운 방법론이 도입되었으며, 이는 추가적인 추론 시 계산 자원을 할당하여 잠재적인 추론 능력을 향상시킵니다.
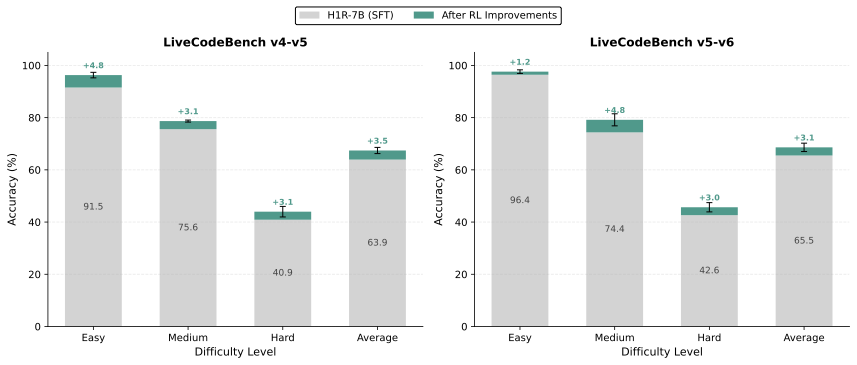
TTS는 논리적 추론에 중점을 둔 영역에서 큰 성과를 거두었습니다. 수학에서는 여러 추론 체인을 샘플링하고 일관된 솔루션을 선택함으로써 정확도가 향상됩니다. 코드 생성에서는 다양한 후보를 생성하고 실행을 통해 검증하여 기능적 정확성을 높입니다. 다중 단계 및 과학 추론에서는 Tree-of-Thoughts와 같은 탐색 기반 추론 접근법이 구성적 사고를 강화하며, 에이전트 및 진화 방법은 이러한 아이디어를 개방형 과학 발견에 확장합니다.
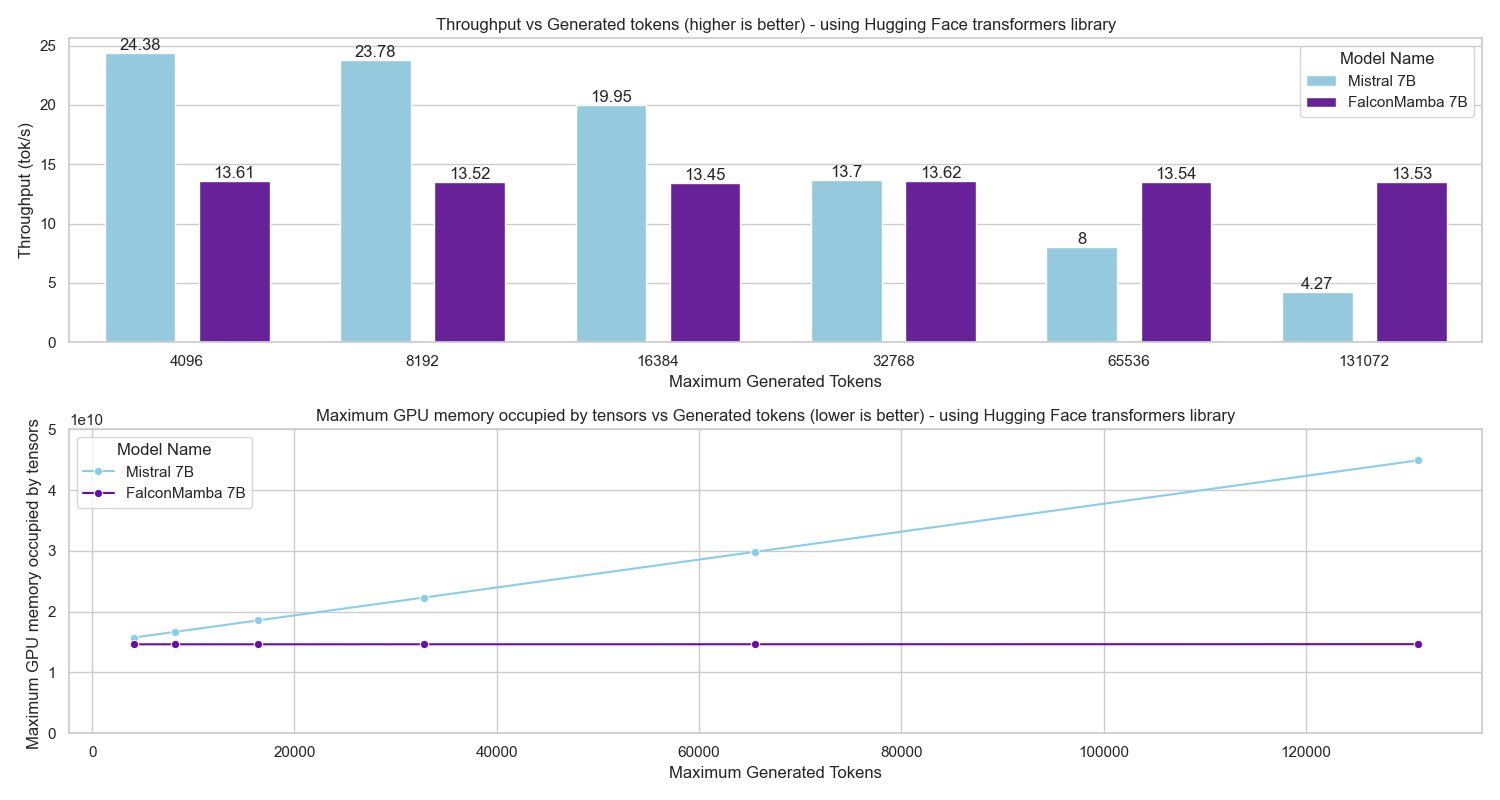
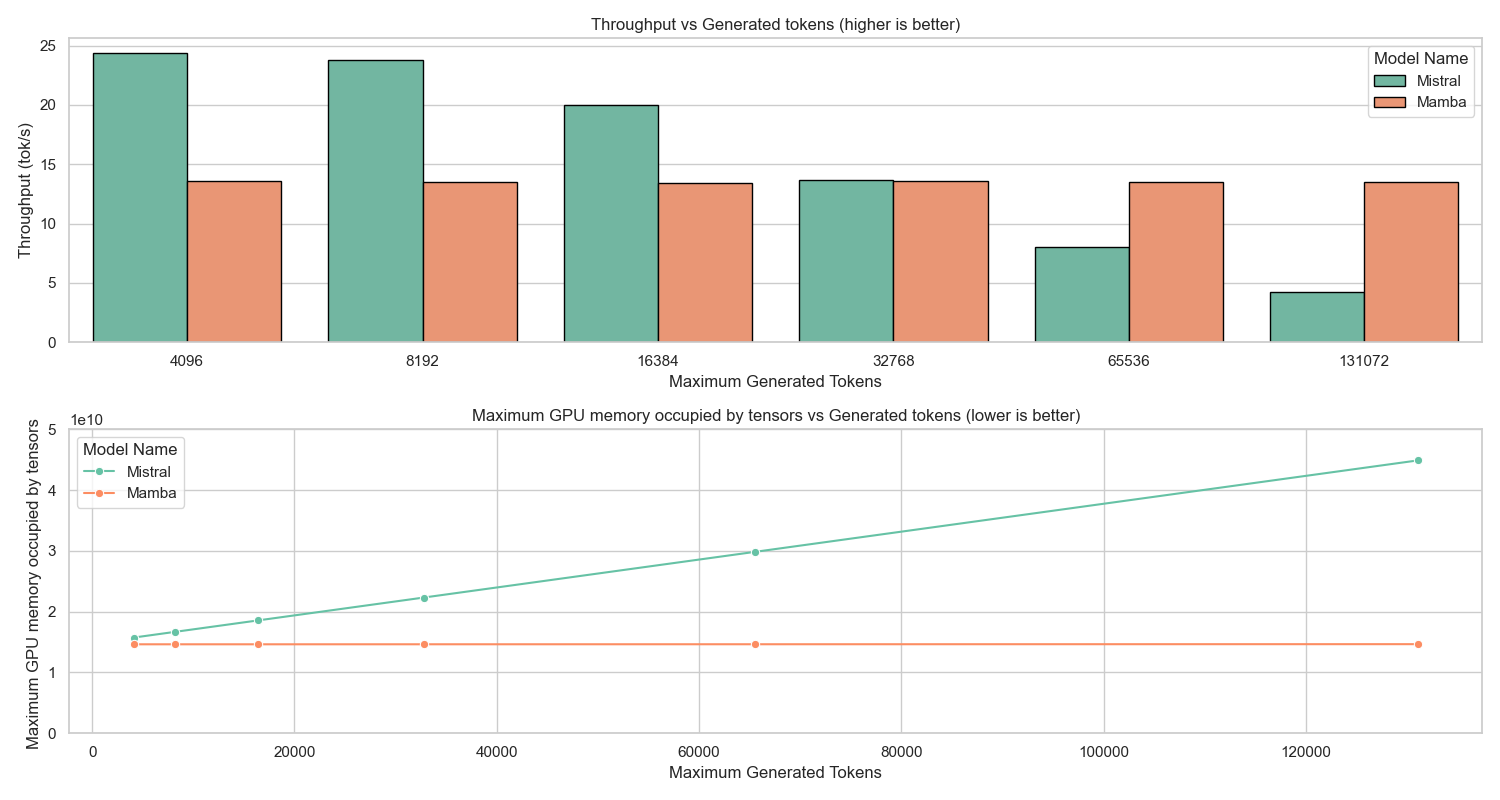
추론 시 계산 자원을 증가시키면 신뢰성과 교정을 향상시킬 수 있지만, 이는 높은 추론 비용을 초래할 수 있습니다. 특히 대규모 병렬 배치와 긴 시퀀스를 처리하는 모델에서는 효율성을 유지하면서 강력한 기본 정확도를 달성하는 것이 중요합니다.
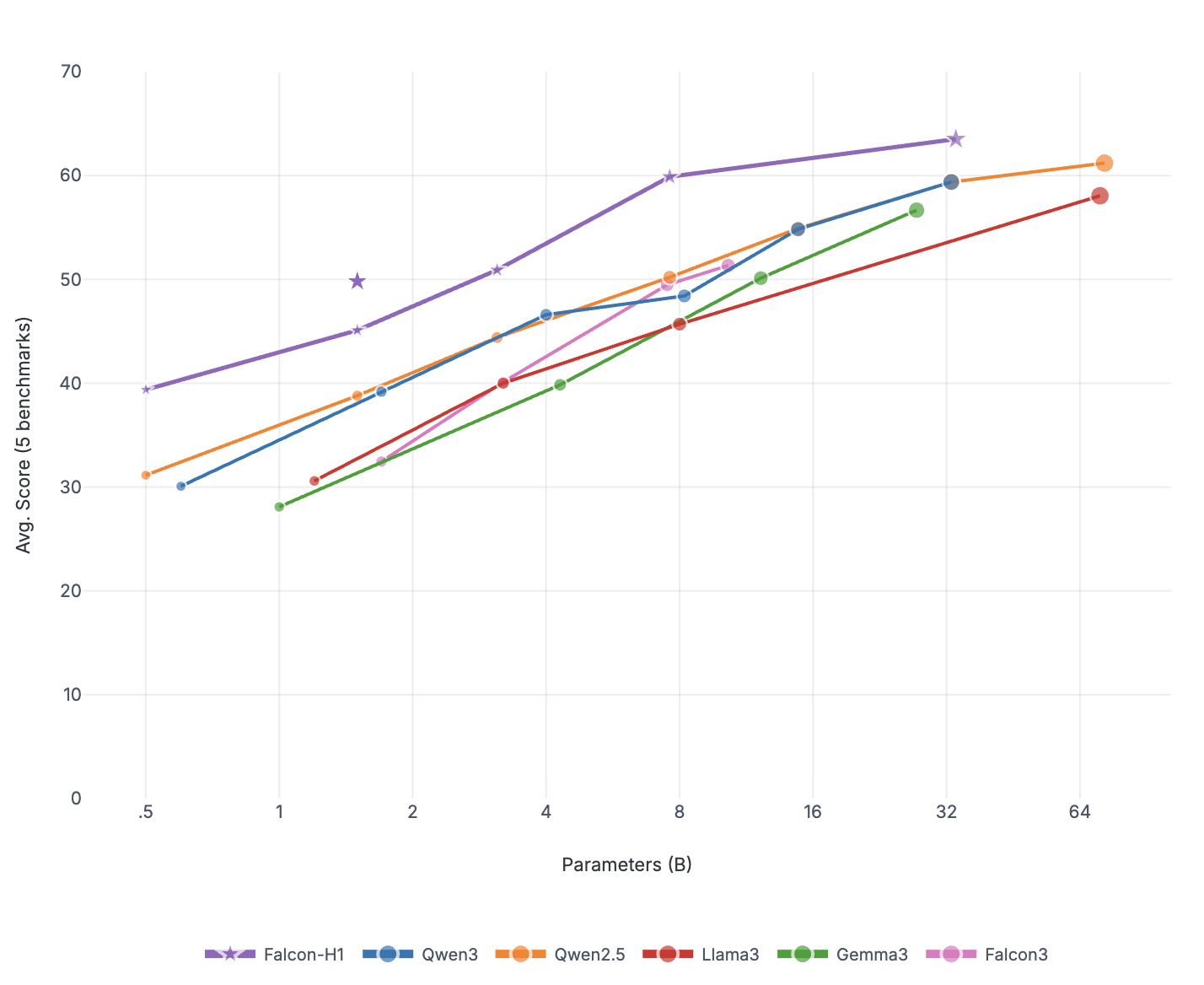
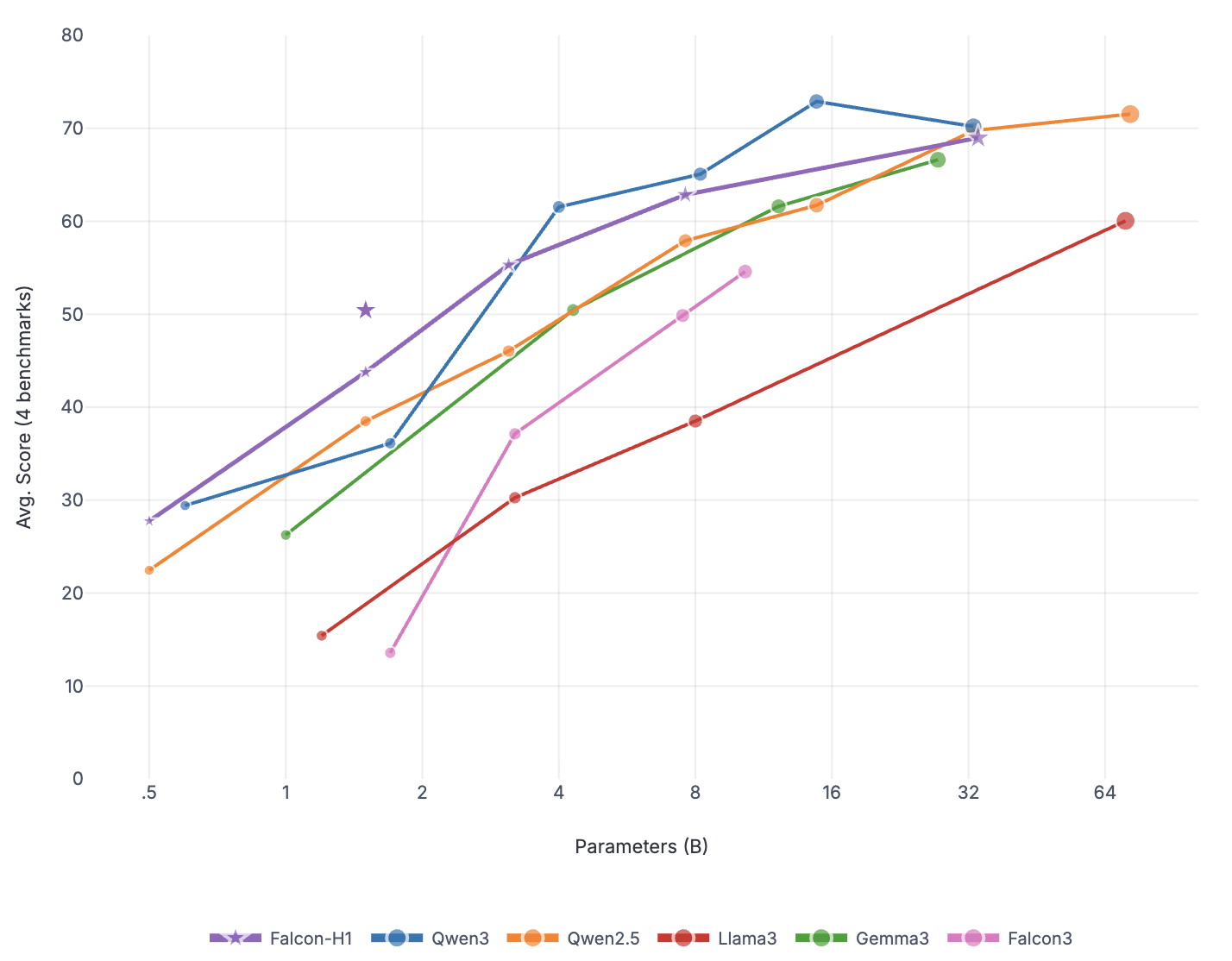
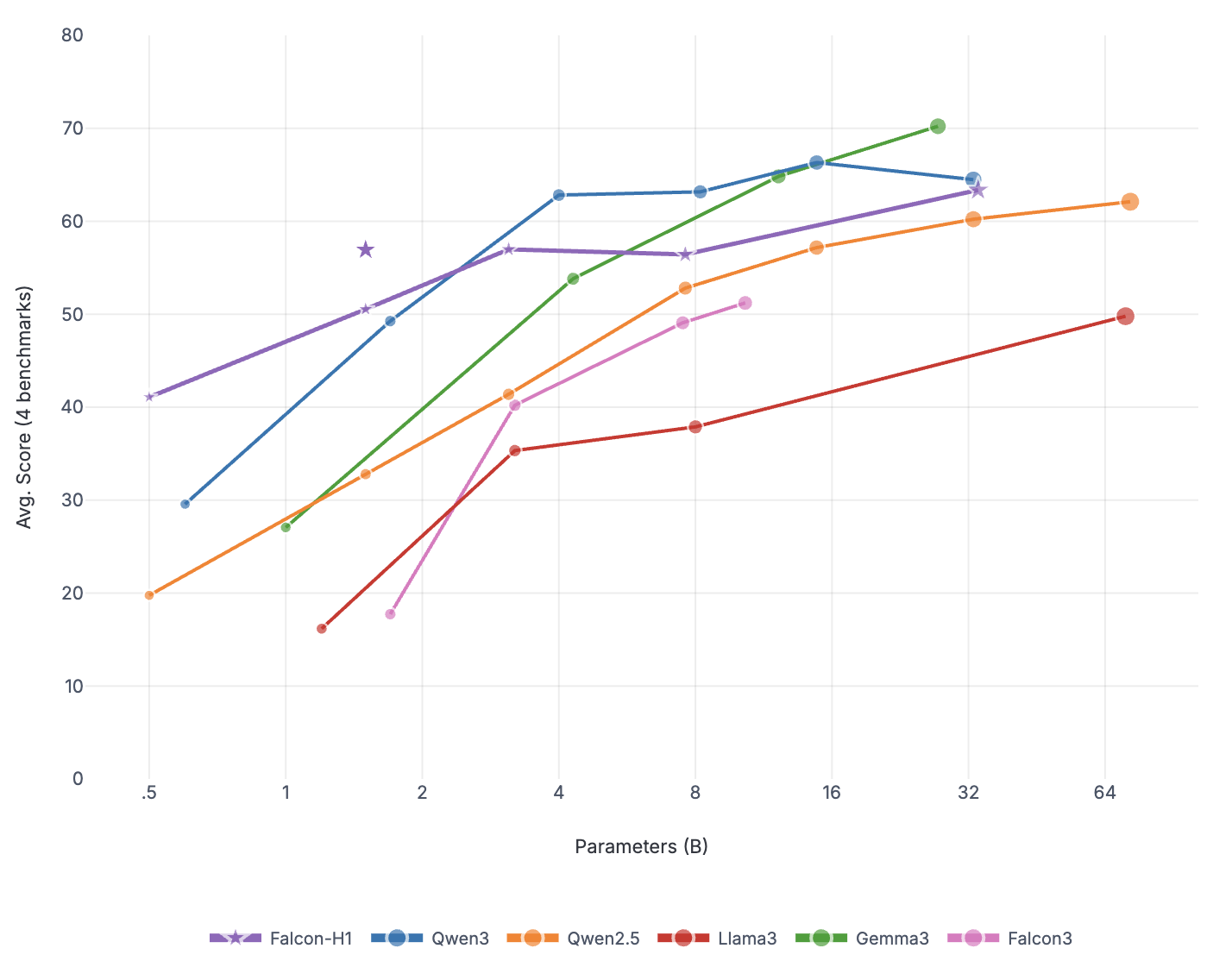
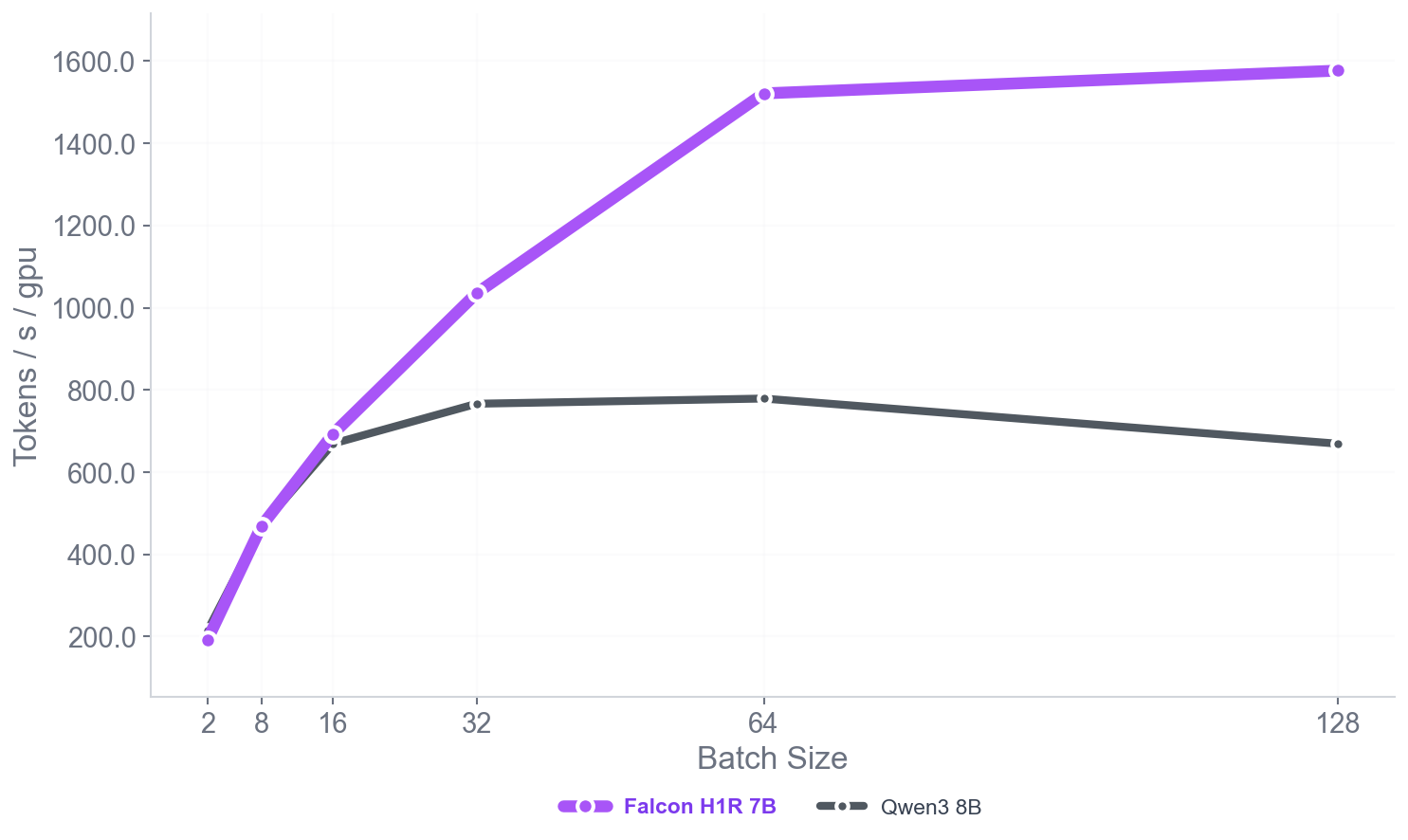
Falcon-H1R-7B는 Falcon-H1 시리즈의 하이브리드 Transformer–Mamba 아키텍처를 기반으로, 추가 SFT 및 RL 확장을 통해 제작되었습니다. 이 모델은 8B~32B 체계와 경쟁하면서도 추론 오버헤드를 크게 줄이는 컴팩트한 모델입니다.
TTS 방법을 통합하고 약한 추론 체인 동안 동적으로 필터링하는 것으로, Falcon-H1R은 더 많은 병렬 체인을 수용하며 효과적인 조기 중지가 가능합니다. 이러한 특성으로 인해 Falcon-H1R은 정확도와 확장성을 요구하는 논리적 추론 작업에 강력한 기반을 제공합니다.
기여: 우리는 추론 효율성을 극대화하기 위해 하이브리드 Transformer-SSM 아키텍처를 활용한 7B 추론 최적화 모델, Falcon-H1R을 소개합니다. 이 연구의 주요 기여는 다음과 같습니다:
TTS를 통한 효율적인 추론을 위한 하이브리드 아키텍처: Falcon-H1 아키텍처를 활용해 병렬 추론 확장에 이상적인 기반을 제공합니다.
강력한 훈련 전략: 긴 추론 경로를 포함하는 데이터셋에서 시작하여 감독 학습 및 강화학습을 통해 훈련됩니다.
TTS를 통한 효율성 및 정확도 개선: Falcon-H1R은 추론 비용을 줄이면서도 뛰어난 추론 성능을 제공합니다.
구조: 본 기술 보고서의 나머지 부분에서는 우리의 결과를 달성하기 위해 취한 단계에 대한 명확하고 포괄적인 개요를 제공합니다. 제 2장은 감독 학습(SFT) 단계에 대한 세부 사항을 설명하며, 데이터 처리, 필터링, 실험 및 훈련 세부 사항이 포함됩니다. 제 3장에서는 강화학습(RL) 단계를 다룹니다. 제 4장은 다양한 추론 벤치마크에 대한 평가 방법론과 결과를 제시합니다. 마지막으로, 제 5장은 시험 시간 확장을 위한 실험 및 결과에 대해 깊이 있게 논의합니다.
Cold-start SFT 단계
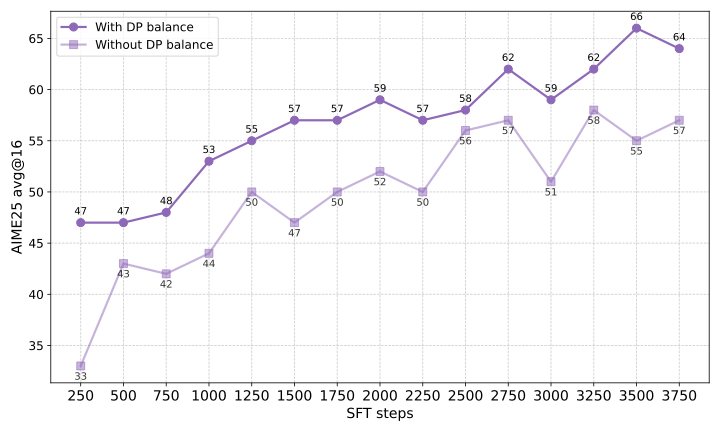
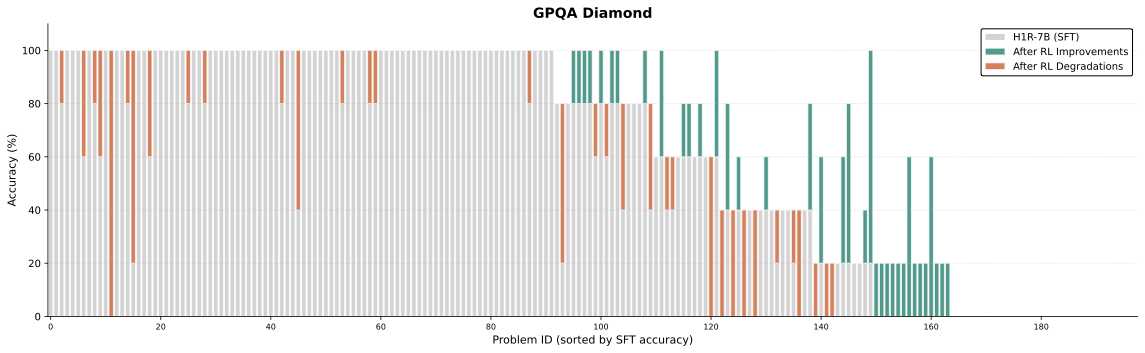
기본 모델의 추론 능력을 더욱 강화하기 위해 현재 패러다임에서는 cold-start 감독 학습(SFT) 단계를 먼저 진행합니다. 이는 RLVR 훈련이 평균 정확도를 개선하는 데 효과적이지만, 해결 가능한 문제의 범위를 확장하는 데 제한적일 수 있음을 보여줍니다.
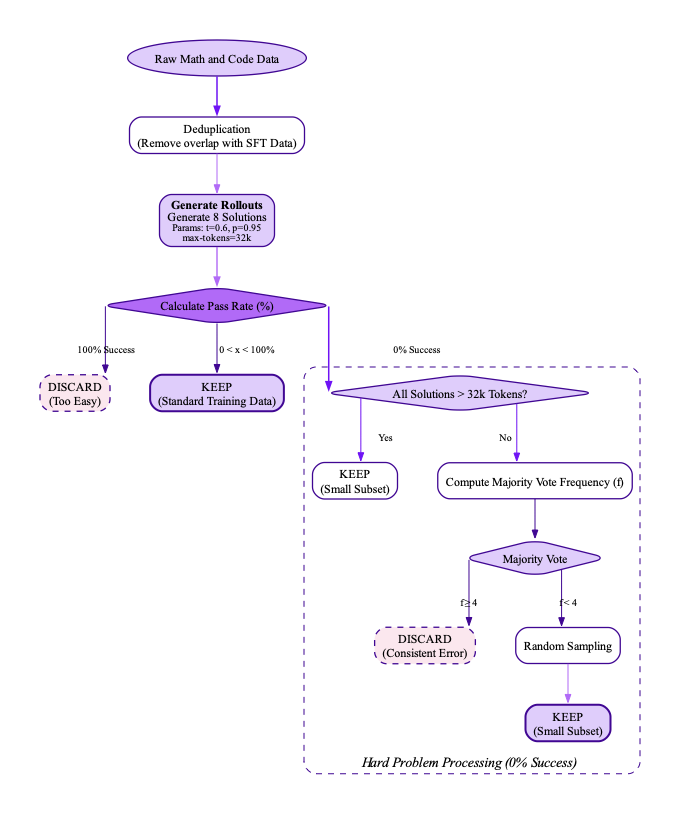
데이터 필터링 및 처리
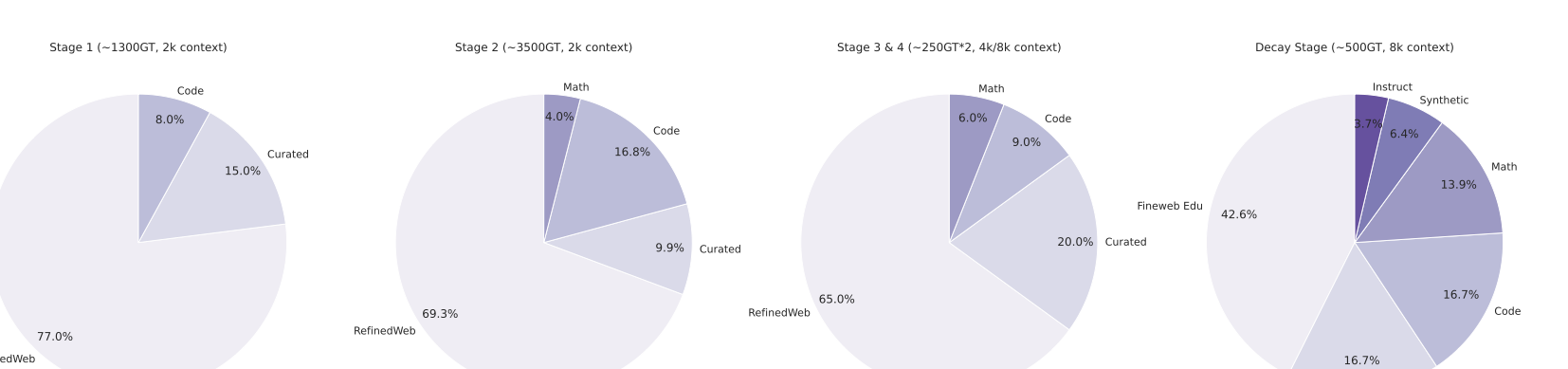
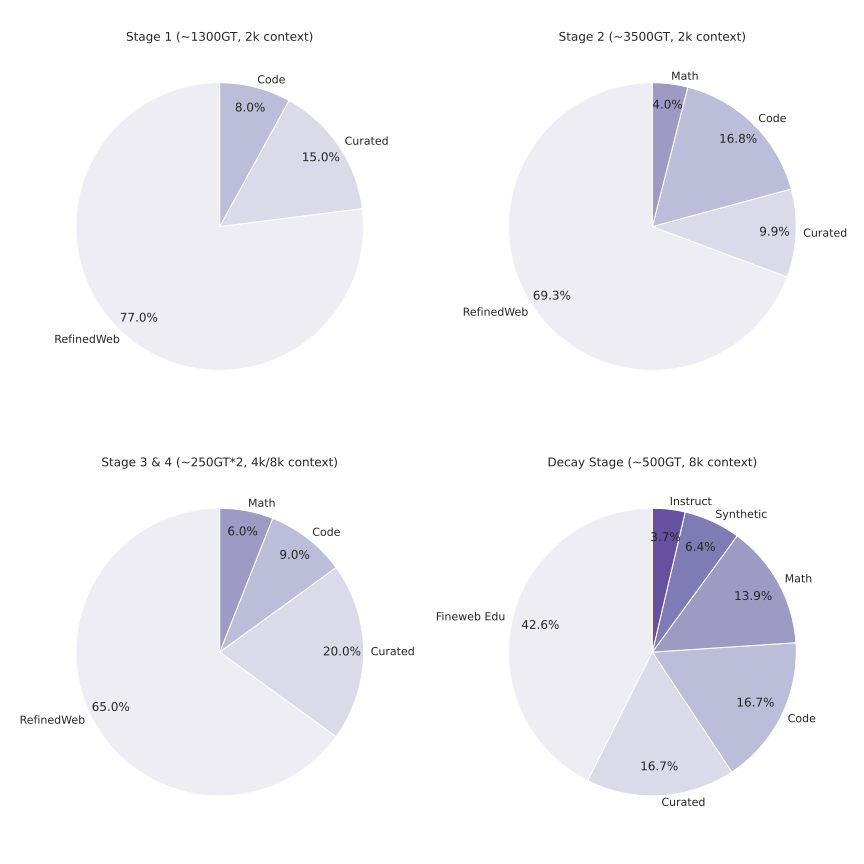
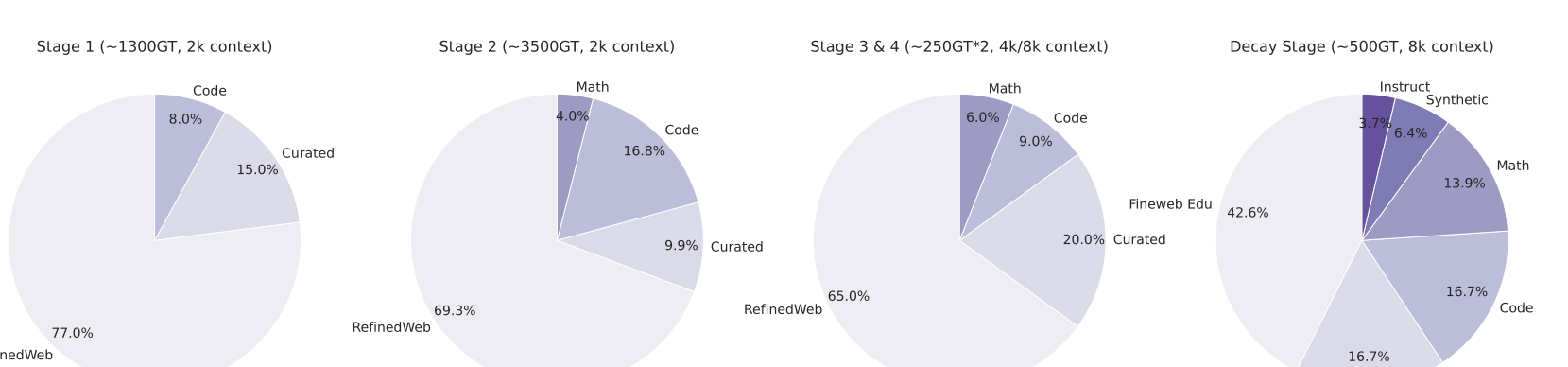
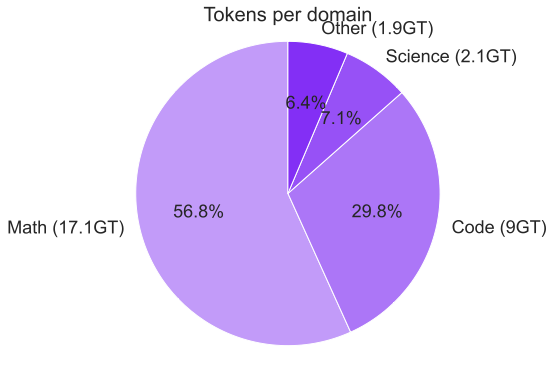
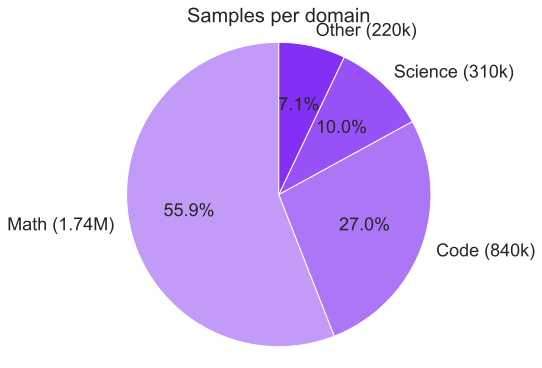
다양한 도메인에서 긴 추론 경로가 생성된 다양한 데이터셋을 엄격히 검증하고 필터링했습니다. 이 중, 수학, 코딩(특히 Python과 C++), 과학, 기타 분야로 구성되었습니다. 코딩 데이터는 알고리즘적 사고와 기능적 정확성을 강조하였으며, 수학 및 과학 작업은 검증된 정답을 우선시하였습니다.
수학 문제의 경우 Math-Verify와 LLM 기반 검증을 사용하여 확실성과 유연성을 보장했습니다. 또한 빈 추론 내용이나 최종 답변이 없는 인스턴스, 수학 솔루션에 최종 답변이 없거나 문법 오류가 있는 코드를 제거하였습니다.
/>
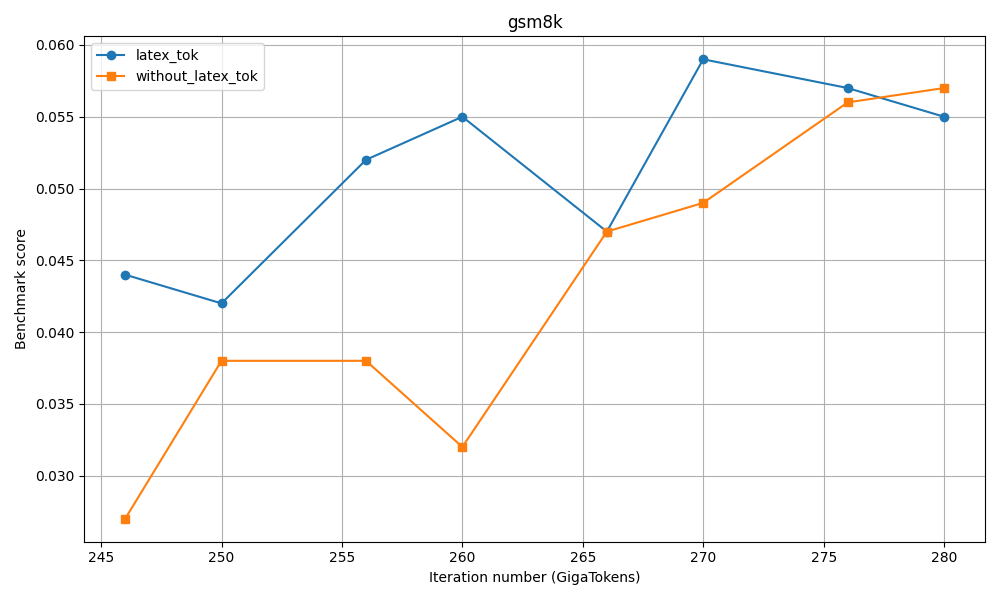
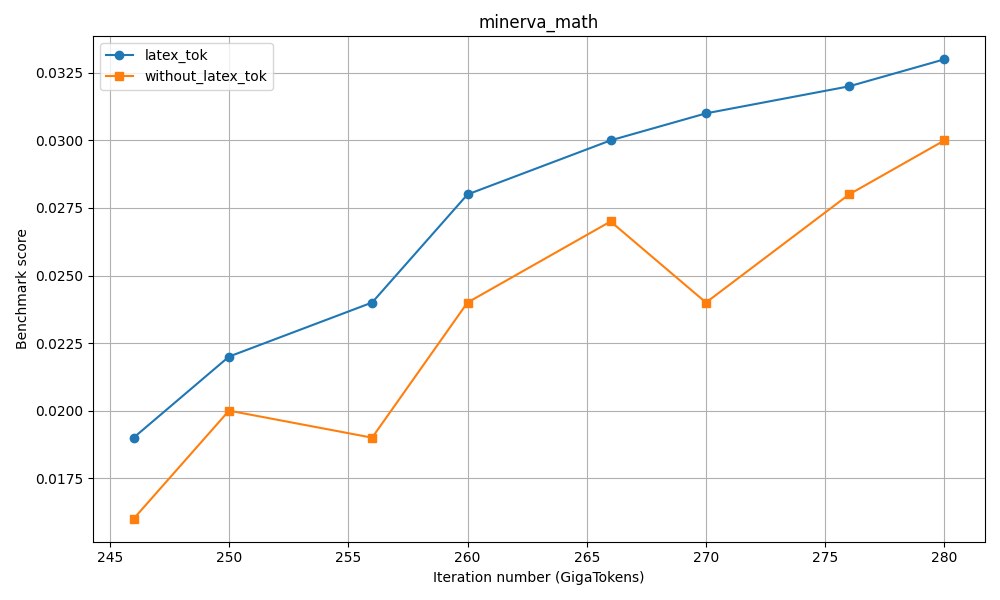
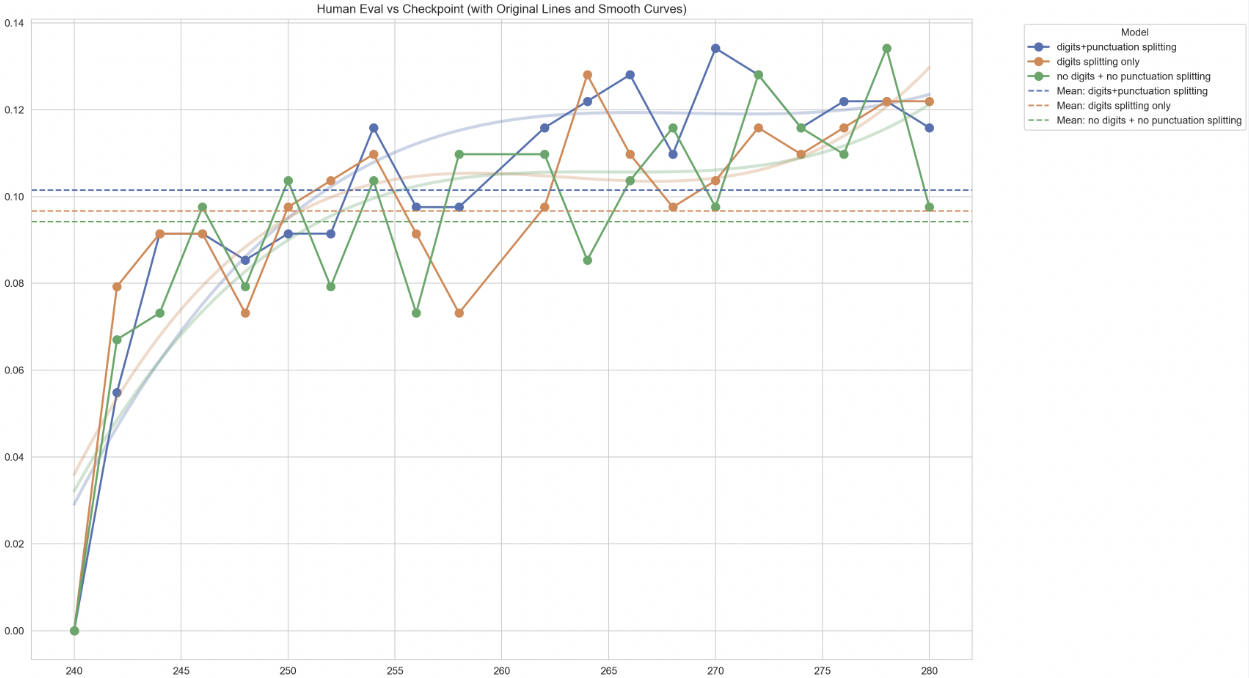
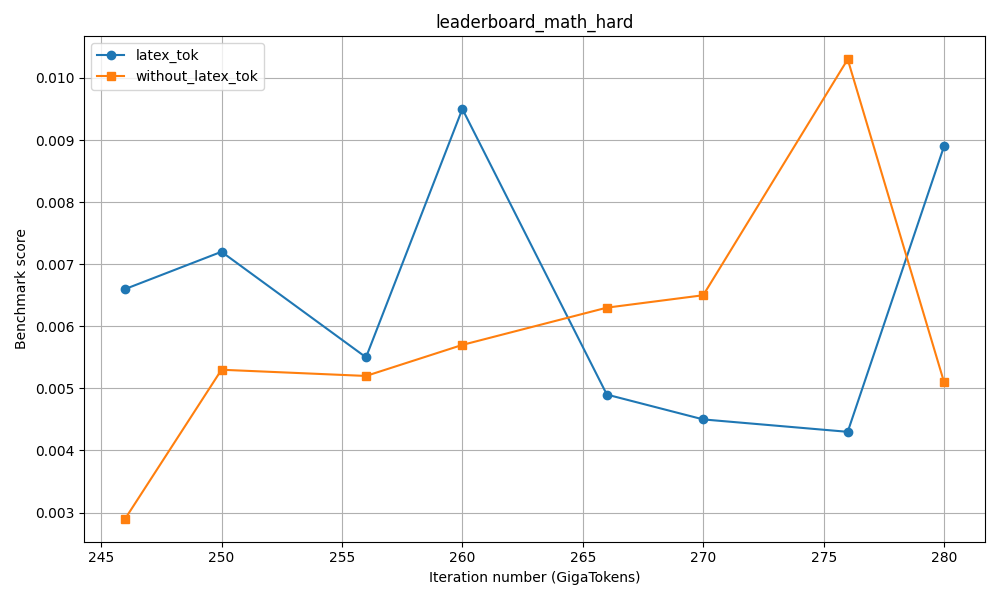
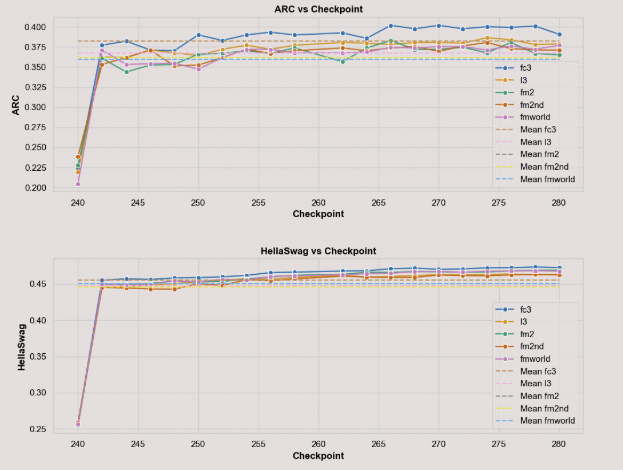
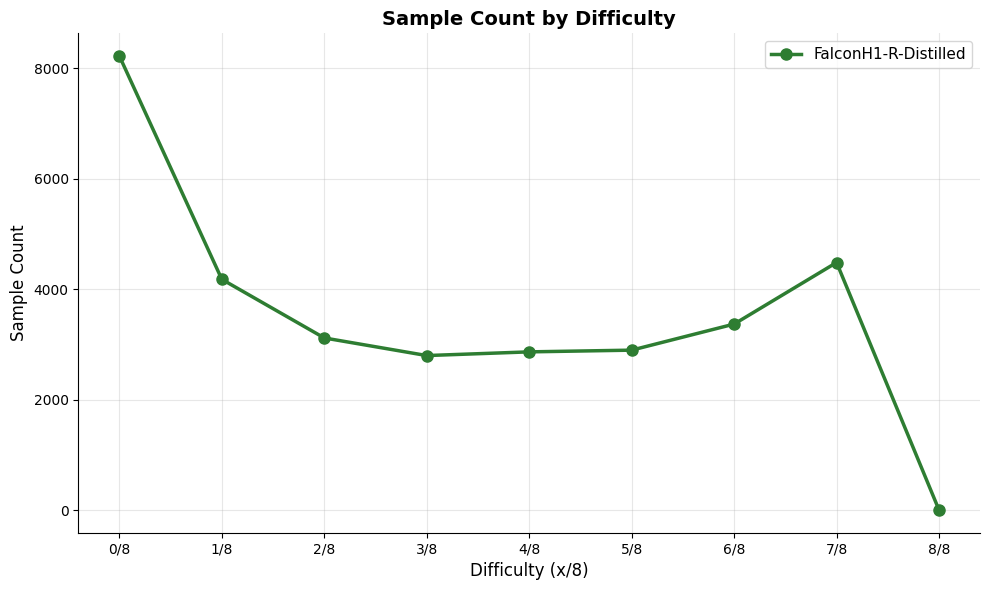
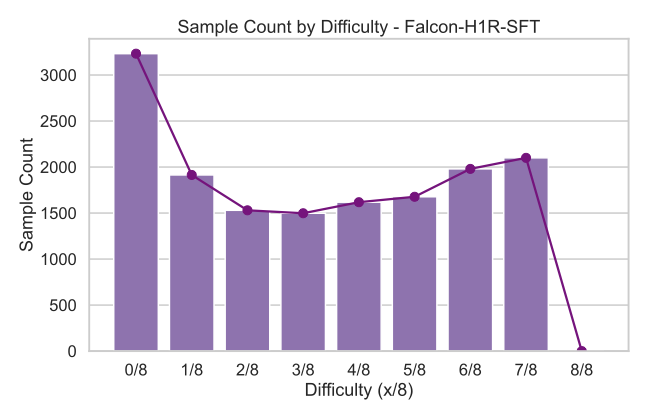
도메인별 SFT 단계에서의 응답 토큰 수 분포. "기타" 카테고리는 IF, Chat, Safety 및 Tool 호출 데이터를 포함합니다.
실험 및 주요 발견
SFT 단계 최적화를 위해 다음과 같은 축을 기반으로 여러 실험을 진행했습니다: 학습률 튜닝, 입력 프롬프트 당 솔루션 롤아웃 수량, 잘못된 롤아웃 포함, 교사 모델 혼합, 도메인별 데이터 혼합 및 데이터 가중치 전략.
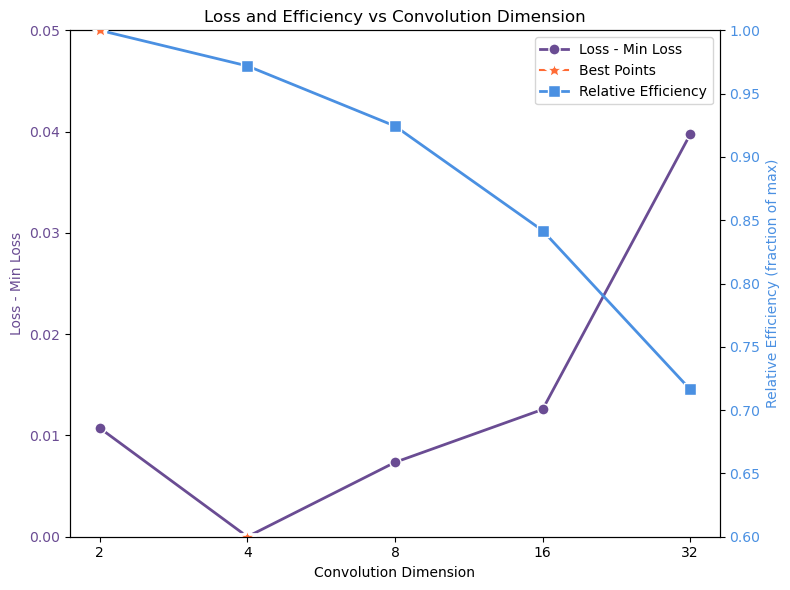
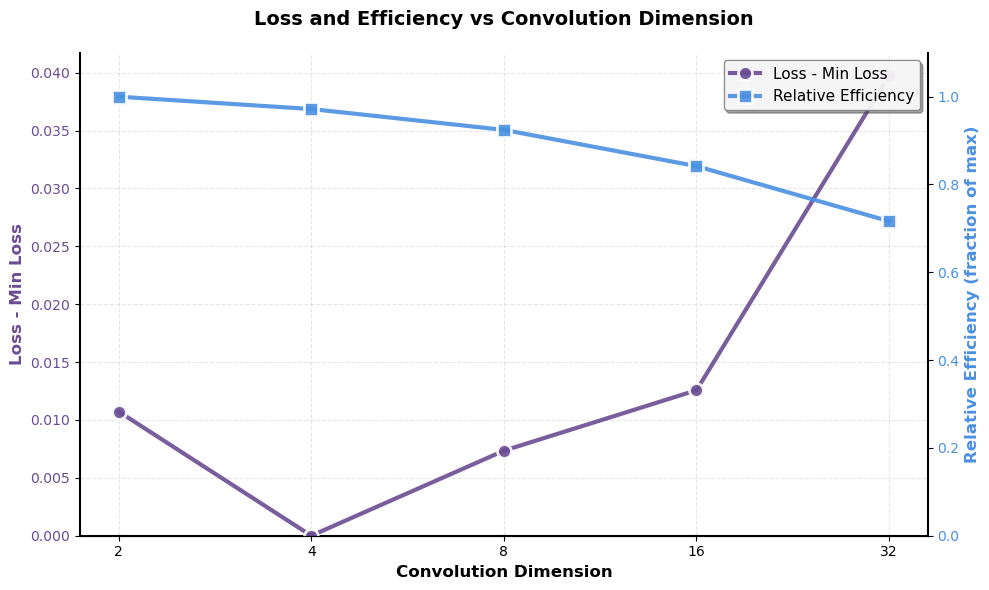
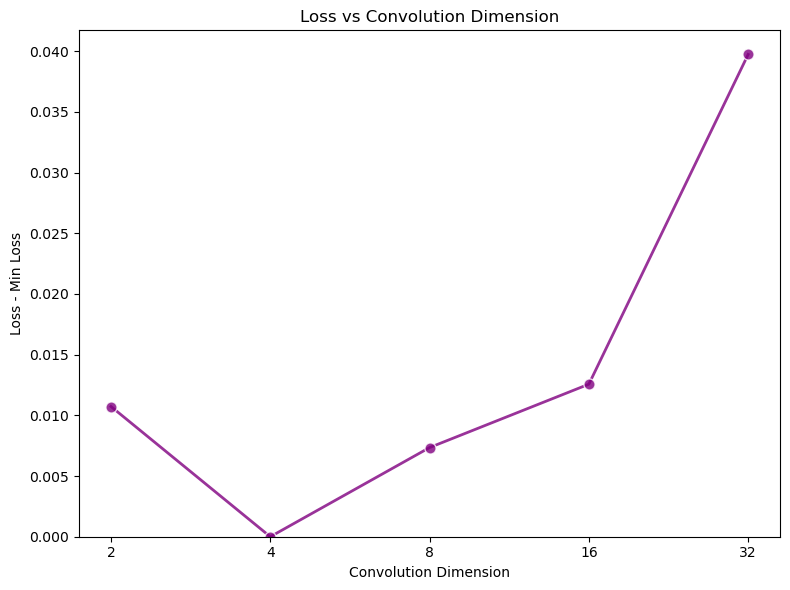
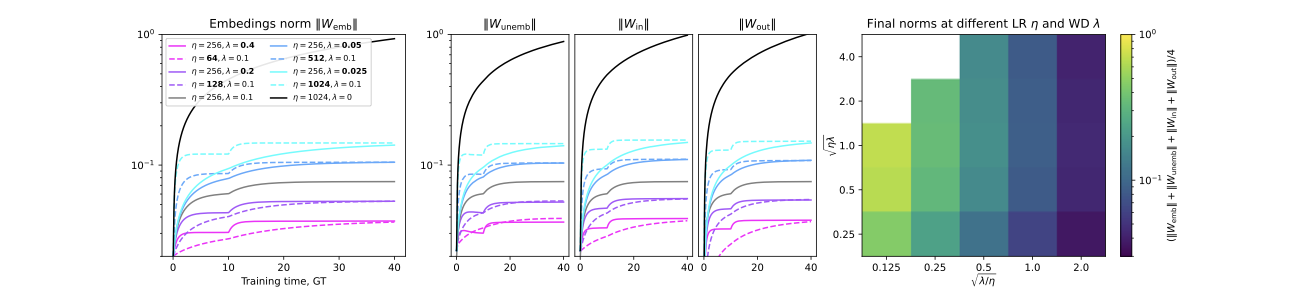
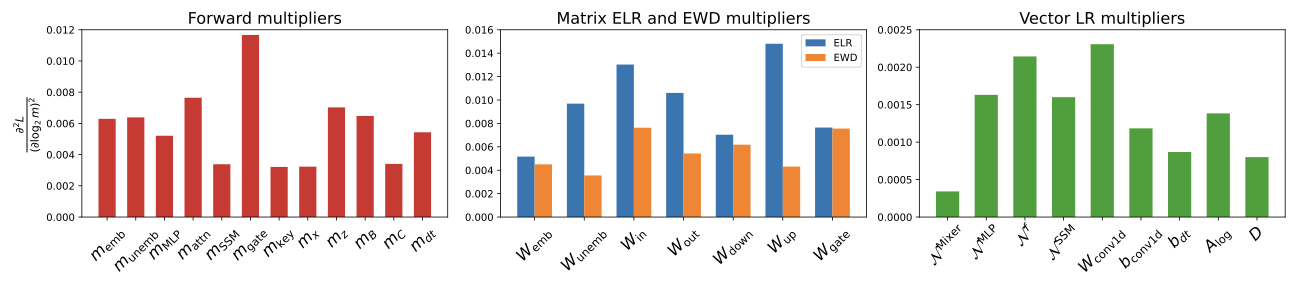
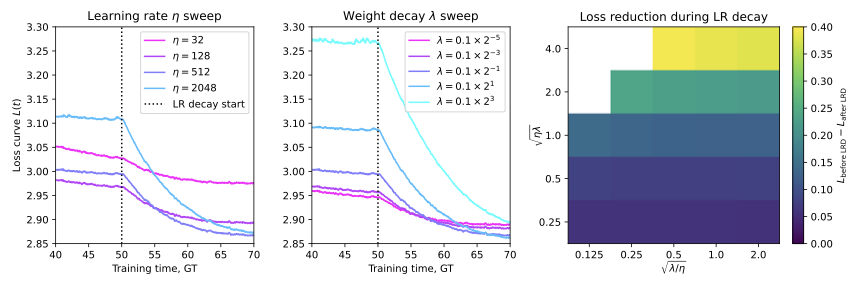
학습률 튜닝: 핵심 추론 벤치마크에서 최상의 검증 성능을 달성하기 위해 대표적인 훈련 코퍼스의 10%를 사용하여 그리드 서치를 진행했습니다. 또한 $\mu P$를 활용해 Falcon-H1 시리즈의 다양한 모델 크기에 대한 훈련 하이퍼파라미터 전달성을 보장하였습니다.
큰 학습률($`1024\cdot10^{-6}`$)은 실험에서 가장 우수한 성능을 보였으며, 일반적인 SFT 설정에서 추천되는 작은 값보다 빠른 수렴 및 더 나은 하류 작업 성능을 제공합니다.
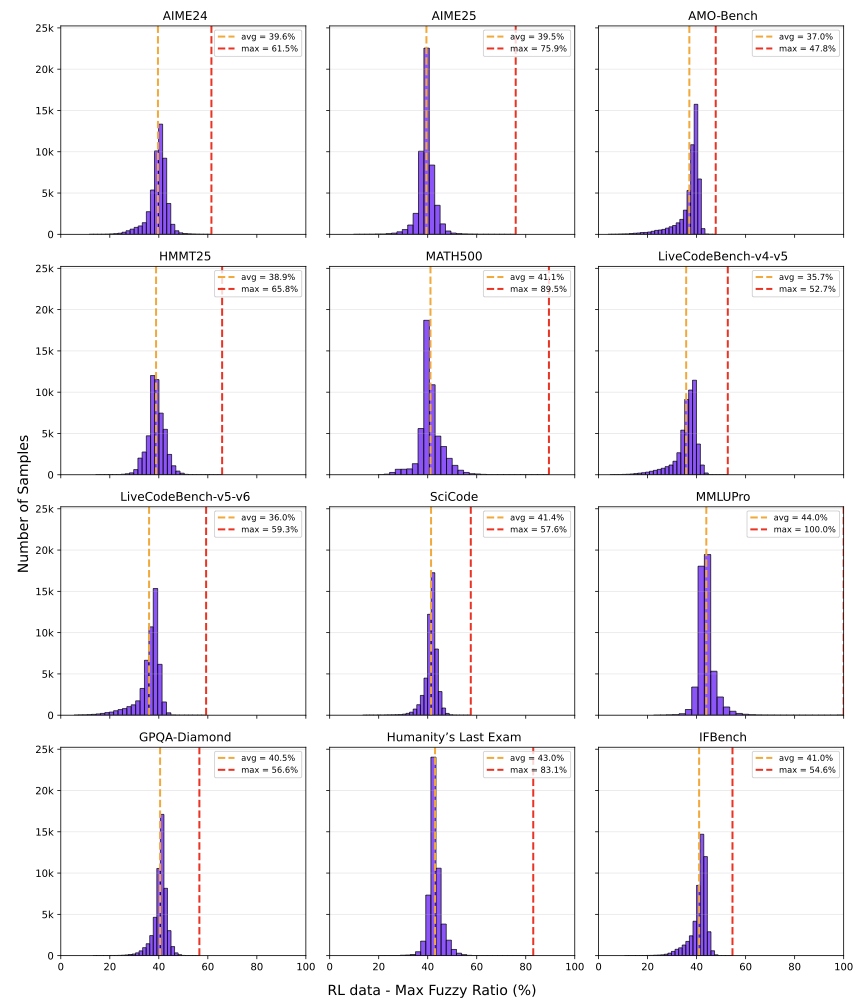
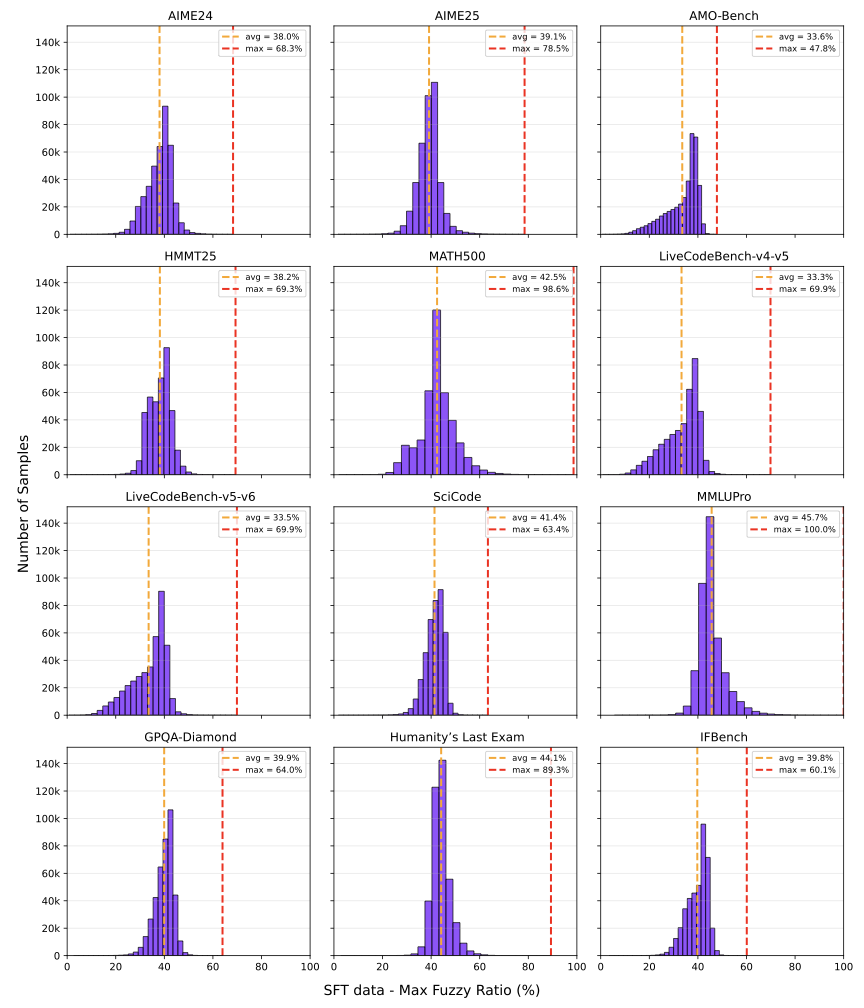
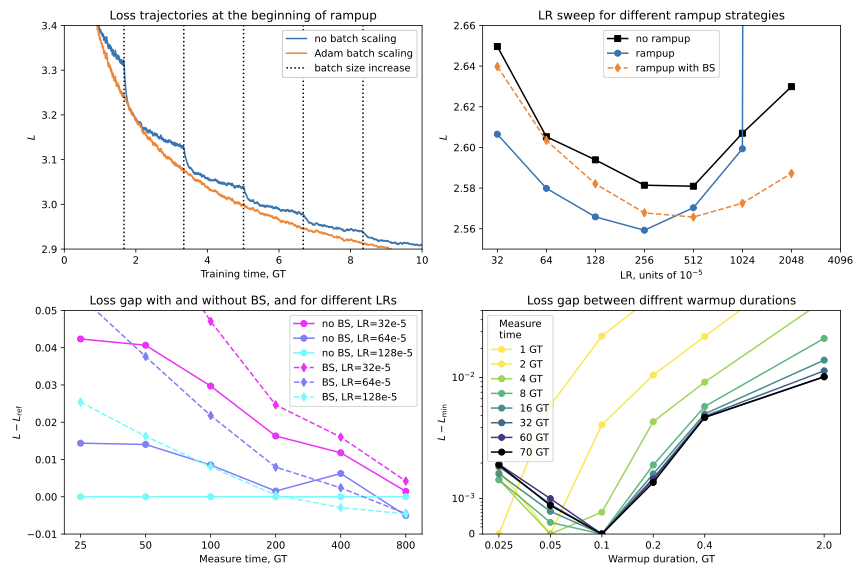
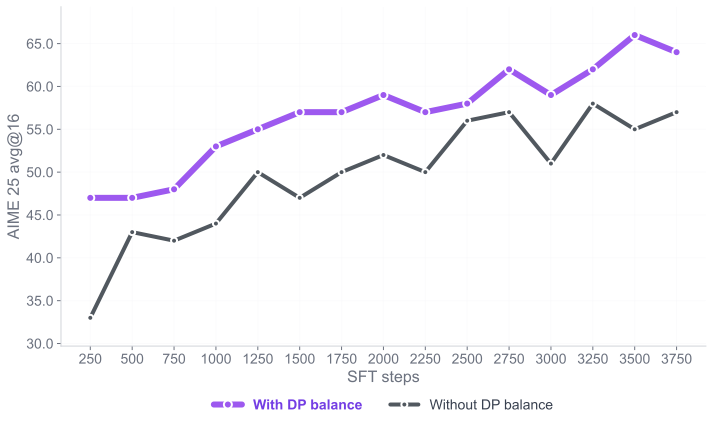
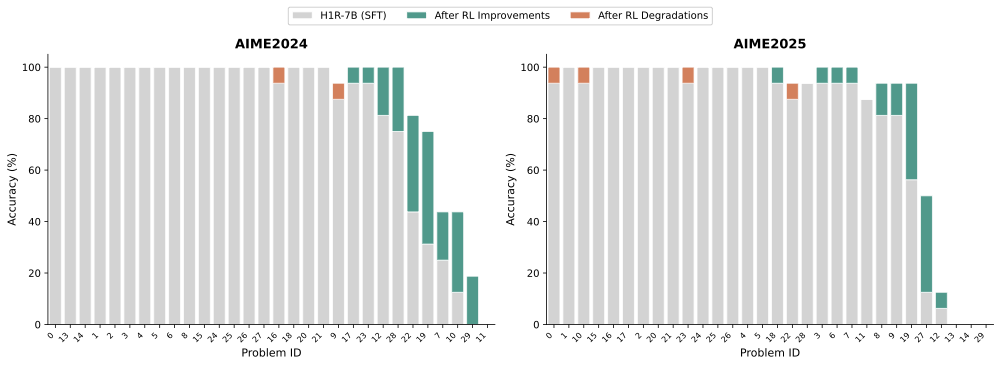
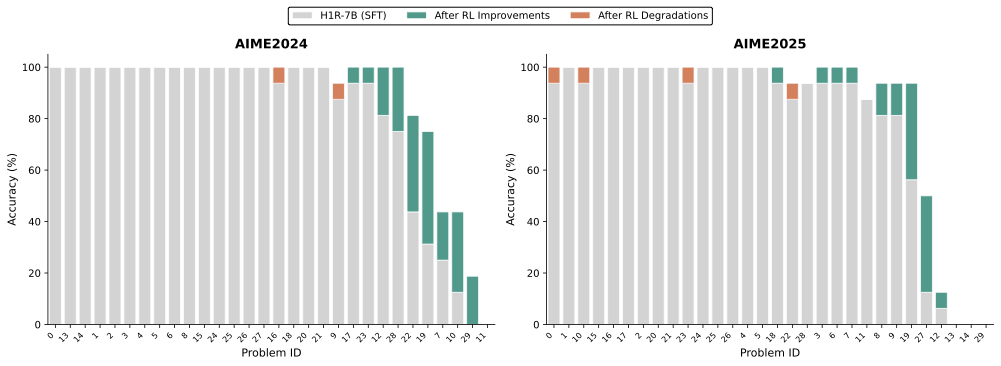
롤아웃 수량 및 정확도 분석: 문제 인스턴스 당 솔루션 롤아웃 수를 바꾸어 실험했습니다. 복잡한 문제에 대한 다양한 추론 경로를 노출함으로써 모델이 강력하고 일반화 가능한 문제 해결 기술을 습득하는 데 중요함을 확인하였습니다.
롤아웃 수가 많을수록($`n=12`$) 성능 향상 효과가 컸으며, 특히 어려운 문제에서는 더욱 두드러졌습니다. 잘못된 롤아웃 포함은 어려운 문제에서만 미세한 개선을 보였지만, 쉽게 또는 중간 난이도의 문제가 아닌 경우 훈련 신호에 약간의 노이즈를 추가할 수 있었습니다.
교사 모델 혼합: 다양한 교사 모델로부터 생성된 추론 경로를 혼합하여 실험했습니다. 도메인 내부 또는 도메인 간 시드를 사용하였습니다. 초기 가설은 다양한 교사의 출력을 혼합하면 데이터 다양성이 증가하고 일반화 성능이 향상될 것이라고 생각되었습니다.
도메인 간 교사 모델 혼합은 반작용적이었습니다. 여러 교사로부터 생성된 데이터를 사용한 학습은 출력 엔트로피가 높아지고 평가 점수가 낮아졌습니다. 다양한 교사의 추론 스타일 간 충돌이 일반화 성능을 저하시키는 원인으로 생각됩니다.
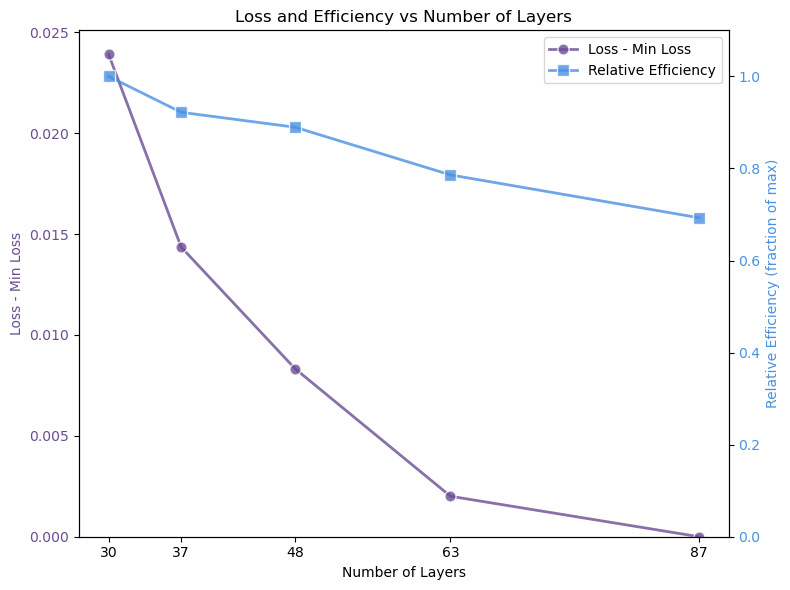
도메인별 실험 및 난이도 인식 가중치: 각 도메인에서 최적의 학습률과 롤아웃 수량을 찾아내기 위해 다양한 실험을 진행하였습니다. 특히, 어려운 문제에서는 복잡한 추론 경로를 노출시키는 것이 중요함을 확인하였습니다.