오픈노벨티: 검증 가능한 학술적 새로움 평가를 위한 LLM 기반 에이전트 시스템
📝 원문 정보
- Title: OpenNovelty: An LLM-powered Agentic System for Verifiable Scholarly Novelty Assessment
- ArXiv ID: 2601.01576
- 발행일: 2026-01-04
- 저자: Ming Zhang, Kexin Tan, Yueyuan Huang, Yujiong Shen, Chunchun Ma, Li Ju, Xinran Zhang, Yuhui Wang, Wenqing Jing, Jingyi Deng, Huayu Sha, Binze Hu, Jingqi Tong, Changhao Jiang, Yage Geng, Yuankai Ying, Yue Zhang, Zhangyue Yin, Zhiheng Xi, Shihan Dou, Tao Gui, Qi Zhang, Xuanjing Huang
📝 초록 (Abstract)
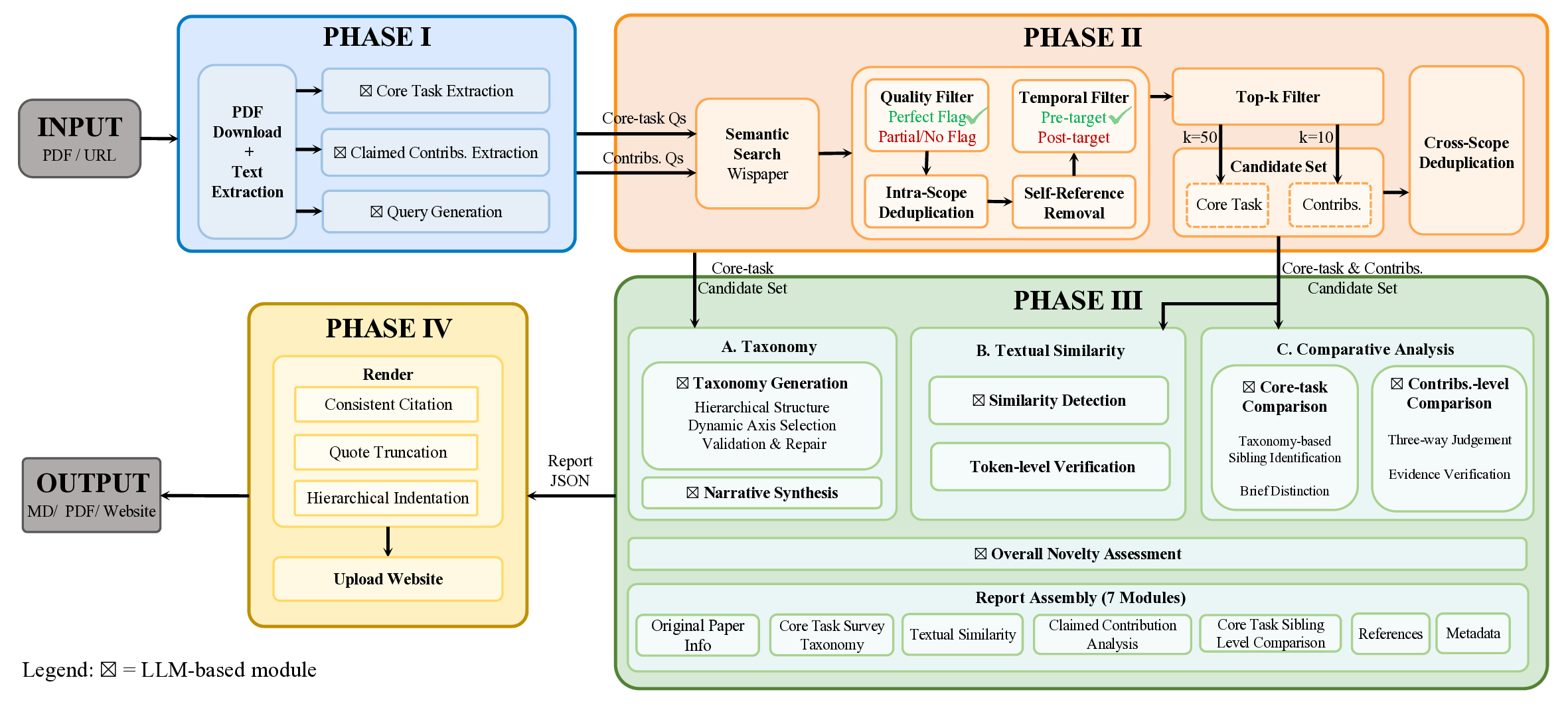
새로움 평가는 피어 리뷰에서 핵심이면서도 어려운 과제이다. 리뷰어는 방대한 양의 급변하는 문헌과 비교해 제출물을 판단해야 한다. 본 보고서는 투명하고 증거 기반의 새로움 분석을 제공하는 LLM 기반 에이전트 시스템인 OpenNovelty를 소개한다. 시스템은 (1) 핵심 과제와 기여 주장 추출을 통해 검색 질의를 생성하고, (2) 해당 질의로 의미 검색 엔진에서 관련 선행 연구를 검색하며, (3) 핵심 과제와 연관된 작업을 계층적 분류 체계로 정리하고 각 기여에 대해 전체 텍스트 비교를 수행하고, (4) 모든 분석을 명시적 인용과 증거 스니펫을 포함한 구조화된 새로움 보고서로 종합한다. 단순 LLM 기반 접근과 달리 OpenNovelty는 실제 논문에 근거한 평가를 제공해 검증 가능성을 확보한다. 우리는 2026년 ICLR에 제출된 500여 편의 논문에 시스템을 적용했으며, 모든 보고서를 웹사이트에 공개하였다. 예비 분석 결과, 저자들이 간과할 수 있는 밀접한 선행 연구까지도 효과적으로 식별함을 보여준다. OpenNovelty는 연구 커뮤니티에 공정하고 일관된 증거 기반 피어 리뷰를 촉진하는 확장 가능한 도구가 되고자 한다.💡 논문 핵심 해설 (Deep Analysis)

시스템이 생성하는 최종 보고서는 구조화된 포맷(예: 기여‑대‑선행‑인용‑증거 스니펫)으로 제공돼, 리뷰어가 즉시 검증 가능한 근거를 확인할 수 있다. 이는 리뷰어의 주관적 판단을 보완하고, 동일 논문에 대한 평가 일관성을 높이는 효과가 기대된다. 또한, 500여 편의 ICLR 2026 논문에 적용한 결과, 저자들이 놓칠 수 있는 ‘밀접한 선행 연구’를 식별했다는 점은 실제 피어 리뷰 현장에서 유용성을 입증한다.
하지만 몇 가지 한계도 존재한다. 첫째, 의미 검색 엔진의 품질에 크게 의존한다. 검색 엔진이 최신 논문을 충분히 색인하지 못하거나, 분야 특화 용어를 제대로 인식하지 못하면 중요한 선행 연구를 놓칠 위험이 있다. 둘째, 자동 추출된 기여 주장 자체가 부정확할 경우, 이후 단계 전체가 오류 전파를 겪는다. 현재 시스템이 어떻게 오류를 감지하고 인간 검증을 삽입할지에 대한 메커니즘이 명시되지 않았다. 셋째, ‘전체 텍스트 비교’는 계산 비용이 높으며, 대규모 학회 제출물에 실시간 적용하려면 인프라 확충이 필요하다. 마지막으로, 보고서의 ‘증거 스니펫’이 충분히 맥락을 제공하는지, 혹은 단편적인 인용에 머무는지는 실제 리뷰어의 피드백을 통해 검증해야 할 부분이다.
전반적으로 OpenNovelty는 LLM을 단순 생성 모델이 아닌, ‘증거 수집·분석·보고’의 에이전트로 전환함으로써 학술 평가의 투명성과 검증 가능성을 크게 향상시킨 혁신적 시도이다. 향후 연구에서는 인간‑AI 협업 인터페이스, 오류 검출 및 교정 메커니즘, 그리고 다양한 학술 분야에 대한 일반화 가능성을 탐구함으로써 시스템의 실용성을 더욱 강화할 수 있을 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리