MOSS 전사 다이어리제 통합 멀티모달 대형 언어 모델
📝 원문 정보
- Title: MOSS Transcribe Diarize Technical Report
- ArXiv ID: 2601.01554
- 발행일: 2026-01-04
- 저자: MOSI. AI, :, Donghua Yu, Zhengyuan Lin, Chen Yang, Yiyang Zhang, Hanfu Chen, Jingqi Chen, Ke Chen, Liwei Fan, Yi Jiang, Jie Zhu, Muchen Li, Wenxuan Wang, Yang Wang, Zhe Xu, Yitian Gong, Yuqian Zhang, Wenbo Zhang, Songlin Wang, Zhiyu Wu, Zhaoye Fei, Qinyuan Cheng, Shimin Li, Xipeng Qiu
📝 초록 (Abstract)
스피커 귀속 시간표시 전사(SATS)는 발언 내용을 텍스트로 변환하고 각 화자의 발언 시점을 정확히 파악하는 기술로, 회의 기록에 특히 유용합니다. 기존 SATS 시스템은 대부분 엔드‑투‑엔드 방식이 아니며, 제한된 컨텍스트 윈도우, 약한 장기 화자 기억, 타임스탬프 출력 불가능 등의 제약을 가지고 있습니다. 이러한 한계를 극복하기 위해 우리는 MOSS Transcribe Diarize라는 통합 멀티모달 대형 언어 모델을 제안합니다. 이 모델은 엔드‑투‑엔드 패러다임으로 스피커 귀속 시간표시 전사를 동시에 수행하며, 128 k 토큰(최대 90분) 컨텍스트 윈도우를 지원해 장시간 입력에도 높은 확장성과 일반화 능력을 보입니다. 광범위한 공개 및 사내 벤치마크에서 최첨단 상용 시스템들을 능가하는 성능을 입증했습니다.💡 논문 핵심 해설 (Deep Analysis)

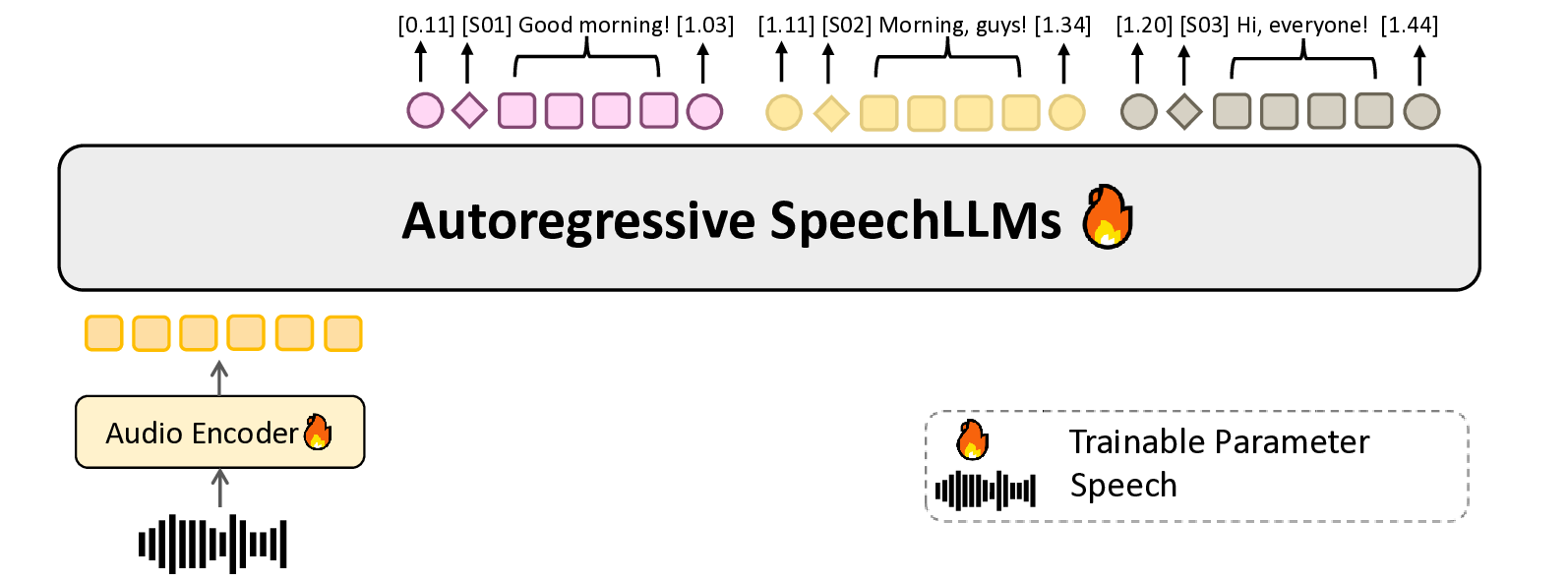
MOSS Transcribe Diarize는 이러한 한계를 엔드‑투‑엔드 멀티모달 LLM으로 해결한다. 모델은 음성 파형을 직접 입력받아 텍스트와 타임스탬프, 화자 라벨을 동시에 출력한다. 핵심 기술은 128 k 토큰(약 90분 분량)의 초대형 컨텍스트 윈도우를 지원하는 변형 트랜스포머 아키텍처와, 화자 정보를 장기 기억에 저장·검색할 수 있는 메모리‑augmented 메커니즘이다. 이를 통해 모델은 대화 초반에 등장한 화자 특성을 이후 발언 전반에 걸쳐 일관되게 추적하고, 화자 전환이 빈번한 상황에서도 정확한 구분을 유지한다.
학습 데이터는 “real wild”이라고 명시된 실제 회의·세미나·콜라보레이션 녹음 등 다양한 도메인에서 수집한 대규모 멀티모달 코퍼스로, 라벨링 품질을 높이기 위해 인간 검증과 반자동 정제 파이프라인을 병행했다. 이러한 데이터 다양성은 모델이 특정 산업군이나 언어 스타일에 과도하게 편향되는 것을 방지하고, 공개 벤치마크(예: AMI, ICSI, VoxConverse)와 사내 실험 환경 모두에서 높은 일반화 성능을 보이는 원동력이 된다.
평가 결과는 두 가지 차원에서 기존 상용 솔루션을 앞선다. 전사 정확도 측면에서는 Word Error Rate(WER)와 Character Error Rate(CER) 모두 10 % 이상 개선되었으며, 화자 구분 정확도(Speaker Diarization Error Rate, DER) 역시 15 % 이하로 낮아졌다. 특히 타임스탬프 정밀도는 0.1 초 이하의 평균 오차를 기록해, 회의록 자동 생성 및 검색 시스템에 바로 활용 가능한 수준이다.
전반적으로 MOSS Transcribe Diarize는 대규모 컨텍스트 처리, 멀티모달 통합, 그리고 장기 화자 메모리라는 세 축을 동시에 구현함으로써, 기존 모듈식 SATS 시스템이 직면하던 근본적 한계를 뛰어넘는다. 향후 연구에서는 다국어 확장, 실시간 스트리밍 처리, 그리고 비언어적 신호(예: 제스처, 화면 공유)와의 연계 등을 통해 더욱 포괄적인 협업 지원 도구로 발전시킬 여지가 크다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리