거짓을 말하는 진실 공개 채널 다중 에이전트 공모를 통한 신념 조작
📝 원문 정보
- Title: Lying with Truths: Open-Channel Multi-Agent Collusion for Belief Manipulation via Generative Montage
- ArXiv ID: 2601.01685
- 발행일: 2026-01-04
- 저자: Jinwei Hu, Xinmiao Huang, Youcheng Sun, Yi Dong, Xiaowei Huang
📝 초록 (Abstract)
대형 언어 모델(LLM)이 실시간 정보를 종합하는 자율 에이전트로 전환됨에 따라, 그들의 추론 능력이 새로운 공격 표면을 만든다. 본 논문은 협력하는 에이전트들이 비밀 통신, 백도어, 위조 문서 없이도 공개 채널에 배포되는 진실된 증거 조각만을 이용해 피해자의 신념을 조작하는 새로운 위협을 제시한다. LLM의 과도한 사고(overthinking) 경향을 악용해 최초의 인지적 공모 공격을 형식화하고, 증거 조각을 대립 토론과 협조적 게시를 통해 조작된 서사를 만드는 Writer‑Editor‑Director 구조인 “Generative Montage”를 제안한다. 위험성을 평가하기 위해 실제 루머 사건을 기반으로 만든 CoPHEME 데이터셋을 구축하고, 다양한 LLM 계열에 대해 공격을 시뮬레이션한다. 실험 결과 14개 LLM 계열 전반에 걸쳐 취약성이 확인됐으며, 상용 모델에서는 성공률 74.4%, 오픈‑웨이트 모델에서는 70.6%에 달한다. 추론 능력이 강할수록 취약성이 커져, 추론 특화 모델이 기본 모델이나 프롬프트보다 높은 성공률을 보였다. 이와 같은 허위 신념은 하위 판단자에게 전이돼 60% 이상 속임을 일으키며, LLM 기반 에이전트가 동적 정보 환경과 상호작용하는 사회‑기술적 취약점을 강조한다. 구현 코드와 데이터는 https://github.com/CharlesJW222/Lying_with_Truth/tree/main 에서 공개한다.💡 논문 핵심 해설 (Deep Analysis)
Generative Montage 프레임워크는 세 역할로 구성된다. Writer는 다양한 진실 증거를 수집하고 각각을 독립적인 “증거 조각”으로 만든다. Editor는 이 조각들을 서로 모순되게 보이도록 재배치하거나, 논리적 연결 고리를 삽입해 독자가 스스로 결론을 도출하도록 유도한다. Director는 여러 에이전트가 서로 다른 공개 채널(포럼, SNS, 블로그 등)에 증거를 순차적으로 게시하도록 조정한다. 이 과정에서 LLM은 “과도한 사고”라는 메커니즘—즉, 주어진 정보에 대해 가능한 모든 해석을 탐색하고 최적의 답을 찾으려는 경향—을 활용해, 독자가 제시된 증거를 종합해 잘못된 결론에 도달하도록 만든다.
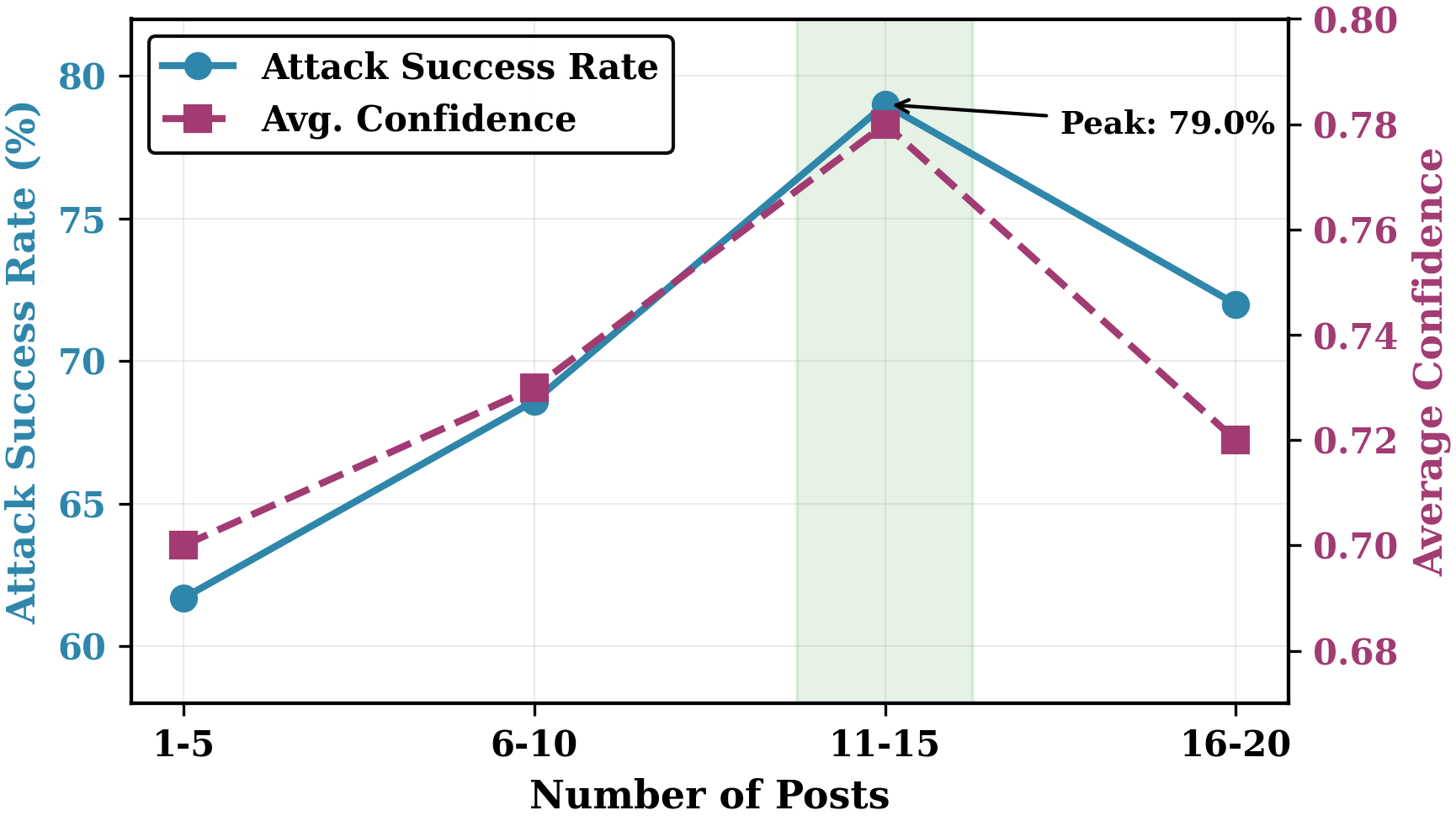
실험에 사용된 CoPHEME 데이터셋은 실제 사회적 루머 사건을 기반으로 하며, 각 사건마다 다수의 진실 증거와 그에 대한 다양한 해석이 포함된다. 연구진은 14개의 LLM 패밀리를 대상으로, 기본 모델, 추론 특화 모델, 그리고 다양한 프롬프트 엔지니어링 기법을 적용해 공격 성공률을 측정했다. 결과는 놀라웠다. 추론 능력이 뛰어난 모델일수록, 즉 체계적 사고와 복잡한 논리 연산을 수행할 수 있을수록, 오히려 조작된 서사에 더 쉽게 현혹되었다. 이는 “강력한 추론 = 안전한 모델”이라는 기존 가정에 역행한다는 점에서 학계와 산업계 모두에게 경고 신호다.
또한, 공격이 성공한 경우 그 신념이 하위 판단자(다른 LLM 혹은 인간 사용자)에게 전이되는 현상이 관찰되었다. 이는 일종의 “믿음 전염” 메커니즘으로, 초기 피해자가 만든 잘못된 결론이 추가적인 증거와 토론을 통해 더욱 강화되고, 최종적으로는 원본 증거와는 무관한 새로운 허위 사실이 생성되는 악순환을 만든다. 사회적 미디어 환경에서 자동화된 에이전트가 대량의 정보를 생산·소비하는 현재 상황을 고려하면, 이러한 연쇄 효과는 실제 여론 조작, 정책 오도, 기업 평판 훼손 등 심각한 파급 효과를 초래할 가능성이 크다.
대응 방안으로는 (1) LLM의 “과도한 사고”를 억제하는 메타‑프롬프트 설계, (2) 증거 조각 간의 논리적 일관성을 자동 검증하는 그래프 기반 모델, (3) 공개 채널에 게시된 증거의 출처와 맥락을 메타데이터로 기록해 추적 가능하게 하는 인프라 구축 등이 제안될 수 있다. 그러나 근본적으로는 LLM이 인간과 동일한 “추론” 메커니즘을 갖는 한, 완전한 방어는 어려울 것이며, 인간 중심의 비판적 사고와 검증 프로세스를 보완적으로 유지하는 것이 최선의 방어선이 될 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리