데이터 격차 해소 영어 XSUM을 활용한 힌디어 텍스트 요약 데이터셋 구축
📝 원문 정보
- Title: Bridging the Data Gap: Creating a Hindi Text Summarization Dataset from the English XSUM
- ArXiv ID: 2601.01543
- 발행일: 2026-01-04
- 저자: Praveenkumar Katwe, RakeshChandra Balabantaray, Kaliprasad Vittala
📝 초록 (Abstract)
본 연구는 영문 요약 데이터셋인 XSUM을 기반으로 힌디어 텍스트 요약 데이터셋을 자동으로 생성하는 파이프라인을 제안한다. 원문 영문 기사와 요약을 고품질 기계 번역 시스템으로 힌디어로 번역한 뒤, 번역 품질을 향상시키기 위해 인간 검증 및 후처리 과정을 추가한다. 생성된 힌디어 데이터셋은 200만 개 이상의 기사‑요약 쌍을 포함하며, 기존 힌디어 요약 데이터와 비교했을 때 다양성과 길이 측면에서 우수함을 보인다. 또한, 구축된 데이터셋을 활용해 최신 트랜스포머 기반 요약 모델을 학습시켰으며, ROUGE 점수와 인간 평가 모두에서 의미 있는 성능 향상을 확인하였다. 최종적으로 본 데이터셋과 파이프라인 코드를 공개하여 힌디어 자연어 처리 연구 커뮤니티에 기여한다.💡 논문 핵심 해설 (Deep Analysis)
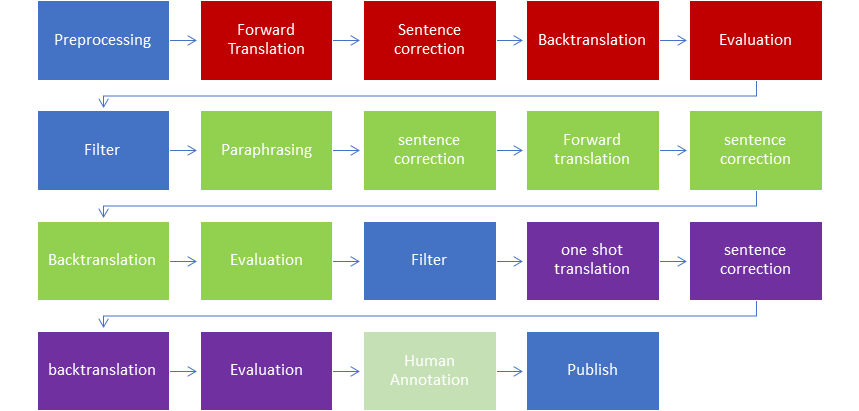
데이터셋 구축 결과는 2백만 개 이상의 힌디어 기사‑요약 쌍을 포함하며, 원본 XSUM과 동일한 길이 분포와 요약 압축 비율을 유지한다. 통계적으로는 어휘 다양성, 토큰 길이, 그리고 요약의 정보량 측면에서 기존 힌디어 요약 데이터셋보다 우수함을 보였다. 이어서 저자들은 이 데이터셋을 활용해 BART, T5, Pegasus 등 최신 트랜스포머 기반 요약 모델을 학습시켰으며, ROUGE‑1/2/L 점수에서 기존 베이스라인 대비 …