- Title: Slot-ID Identity-Preserving Video Generation from Reference Videos via Slot-Based Temporal Identity Encoding
- ArXiv ID: 2601.01352
- 발행일: 2026-01-04
- 저자: Yixuan Lai, He Wang, Kun Zhou, Tianjia Shao
📝 초록
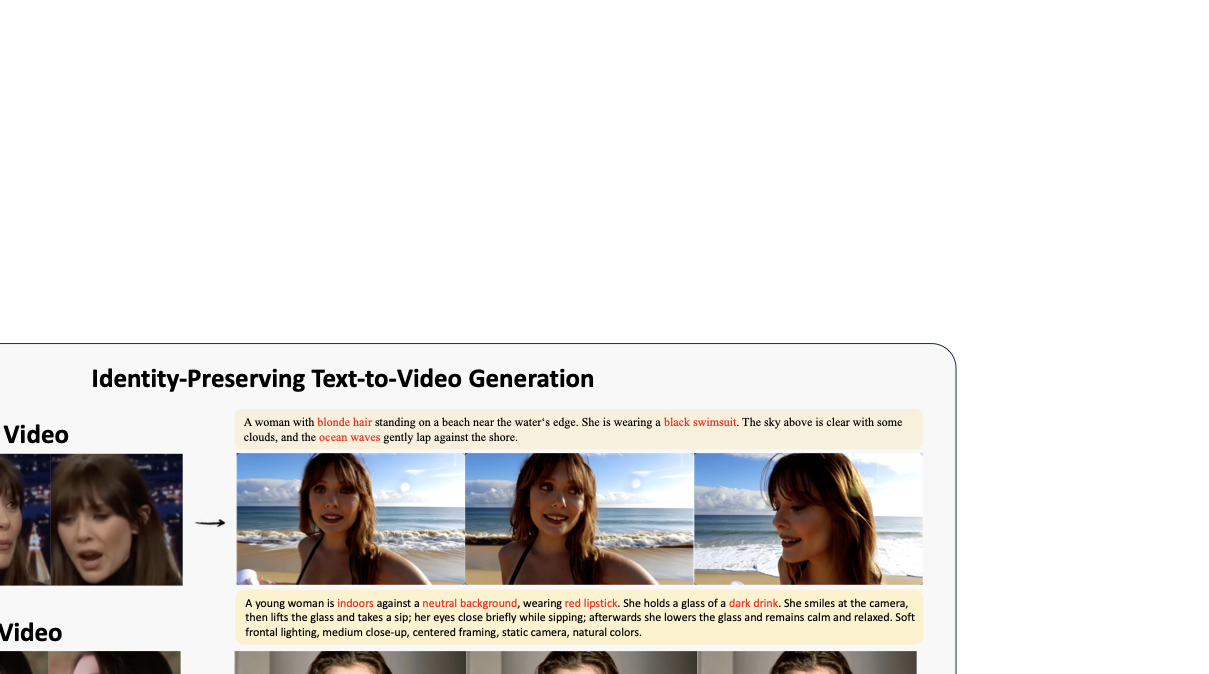
최근 연구에서는 텍스트 프롬프트를 이용하여 실제 인간 동영상을 생성하는 것에 대한 관심이 급증했습니다. 이러한 기술은 단순한 스타일화된 클립에서 장시간, 사진처럼 사실적인, 프롬프트에 충실하며 강력한 시간적 일관성을 갖춘 시퀀스로 발전했습니다. 하지만 현재 연구가 직면하고 있는 주요 도전 중 하나는 개인의 신원을 유지하는 것입니다. 이 논문은 단일 참조 이미지를 사용하는 기존 방법의 한계를 극복하기 위해, 짧은 동영상 참조를 이용하여 인물의 신원을 보다 안정적으로 추출하고 생성할 수 있는 새로운 방식을 제안합니다.
💡 논문 해설
1. **Slot-ID 소개**: Slot-ID는 DiT 기반 텍스트-동영상 확산에서 최상의 신원 유지 효과를 제공하는 방법입니다. 이 방법은 신체 동작과 표정 변화에도 불구하고 개인의 얼굴을 일관되게 표현할 수 있도록 설계되었습니다.
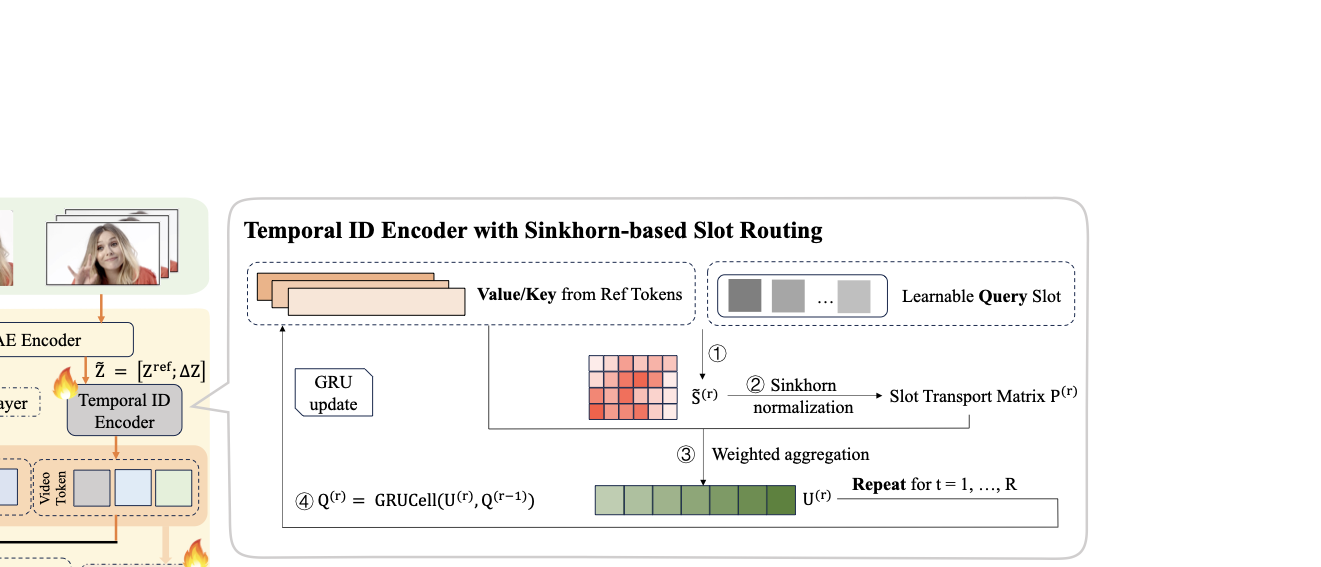
학습 가능한 신원 슬롯: Slot-ID는 학습 가능한 신원 슬롯이라는 개념을 도입하여, 얼굴이 움직이는 방식과 시각적 특징을 캡처하는 데 중점을 두고 있습니다. 이 슬롯은 Sinkhorn 매칭과 가벼운 GRU를 통해 반복적으로 정제되어, 동작, 자세, 조명 변화에도 불구하고 신원을 유지합니다.
동영상 참조의 중요성: 기존 방법은 단일 이미지를 사용하여 신원을 추출하는 데 한계가 있지만, Slot-ID는 짧은 동영상 참조를 통해 다양한 조건에서 개인의 얼굴을 더 정확하게 표현할 수 있습니다. 이를 통해 신원 유지와 사실적인 표현 사이에 균형을 맞추며, 다양한 데이터셋과 프롬프트에서도 일관된 성능을 보여줍니다.
📄 논문 발췌 (ArXiv Source)
/>
소개
텍스트 프롬프트를 사용하여 사실적인 인간 동영상을 생성하는 연구에 최근 큰 관심이 쏟아져 있습니다. 이 기술은 단순한 스타일화된 클립에서 장시간, 사진처럼 사실적이며 프롬프트에 충실한 시퀀스로 발전하였습니다. 이러한 발전은 개인 미디어, 사전 시각화, 광고 및 스트리밍과 같은 다양한 응용 분야를 가능하게 하였습니다. 그러나 모든 현재 연구가 공통적으로 직면하는 한 가지 도전 과제는 신원 유지입니다. 여기서 말하는 ‘신원’은 관람자가 비록 시점, 조명, 표정 및 움직임이 바뀌어도 얼굴 특징을 통해 사람을 인식할 수 있는지에 대한 것입니다. 이러한 모든 요소들이 프레임 간에 일관성을 유지해야 하는 문제는 여전히 연구 중이며 본 논문의 주제입니다.
현재 가장 일반적인 솔루션은 단일 참조 포트리traits를 추출하고 이를 사전 훈련된 동영상 백본에 주입하는 것입니다. 이를 위해 CLIP/ArcFace와 같은 오프더셀프 인코더를 재사용하거나 간단한 이미지 기반 인코더를 설계합니다. 전자는 인식을 위한 것이기 때문에 특정 판별적 특징(예: 헤어라인)에 과도하게 의존하여 얼굴이 식별되지만 분포 변동 시 자연스럽고 견고하지 않은 결과가 나오곤 합니다. 후자는 이러한 불일치를 피할 수 있지만 자세와 표정 변화에는 실패하고 종종 ‘평균’ 얼굴로 붕괴됩니다. 또한 이미지만을 조건으로 하는 것은 자세 잠금 문제를 초래합니다: 생성기는 포트리traits를 정준 뷰로 취급하고 프롬프트된 카메라 각도를 무시하는 경향이 있습니다.
단일 이미지 참조의 실패.(a, c) Reference portraits. (b)Face deformation: view changes warp facial geometry (stretched
cheeks/jawline, eye misalignment).
우리는 현재 연구에서 부족한 핵심 정보가 참조 동영상의 움직임이라는 것을 주장합니다. 단일 이미지는 시점, 조명 및 표정 변화에 따른 신원을 나타내는 특징이 어떻게 진화하는지 드러낼 수 없습니다. 직관적인 해결책은 짧은 동영상을 참조로 도입하고 이를 학습하여 사전 훈련된 동영상 백본에 주입할 수 있는 간결한, 역학 정보가 포함된 신원 코드를 생성하는 것입니다.
이 짧은 동영상에는 조명 변화, 시점 변화 및 얼굴 근육 움직임이 포함되어 있어 정적 외관을 넘어 신원을 인식할 수 있습니다. 핵심 과제는 단지 식별 가능한 기하학적 및 외관 특징만 캡처하는 것이 아니라 이러한 특징들이 공간과 시간에서 어떻게 움직이는지를 캡처하는 것입니다. 이는 우리가 알고 있는 바에 따르면, 대부분 정적 이미지를 참조로 사용하는 이전 연구에서는 조사되지 않은 문제입니다. 두 번째 제약은 추출된 특징이 선택한 동영상 백본과 호환되어야 하며 이를 통해 주입이 성능을 심각하게 저해하지 않아야 합니다.
이러한 과제를 해결하기 위해, 우리는 짧은 참조 클립에 대해 비디오 생성기를 조건화하고 정적 얼굴 외관뿐만 아니라 표정과 시점 변화에 따른 특징적인 시간적 채찍을 포착하는 간결한 역학 정보가 포함된 신원 코드를 학습합니다. 이를 위해 슬롯 기반 인코더로 이러한 신원 토큰을 생성합니다. 여기서 슬롯은 참조 클립에서 시간과 공간을 횡단하는 학습 가능한 쿼리입니다.
우리는 Sinkhorn 라우팅된 슬롯 인코더를 도입하여 이러한 신원 토큰을 추출합니다. 우리는 슬롯-토큰 친밀도 행렬을 형성하고 Sinkhorn 정규화를 적용하여 커버리지를 장려하고 붕괴를 방지하는 할당을 얻습니다. 슬롯 상태는 가벼운 GRU로 반복적으로 정제됩니다. 목표 개인의 짧은 참조 클립에서 시간적 증거를 집계함으로써 모델은 특정 개인의 얼굴 역학을 학습할 수 있습니다.