- Title: UltraEval-Audio A Unified Framework for Comprehensive Evaluation of Audio Foundation Models
- ArXiv ID: 2601.01373
- 발행일: 2026-01-04
- 저자: Qundong Shi, Jie Zhou, Biyuan Lin, Junbo Cui, Guoyang Zeng, Yixuan Zhou, Ziyang Wang, Xin Liu, Zhen Luo, Yudong Wang, Zhiyuan Liu
📝 초록
오디오 기반 모델의 폭발적인 발전과 함께, 오디오 모델을 객관적이고 체계적으로 평가하기 위한 통합 평가 프레임워크인 **UltraEval-Audio**를 제안합니다. 이 프레임워크는 데이터 로딩부터 추론 파라미터 조정까지 다양한 과정을 분리하여 연구자들이 실험의 재현성을 높이고, 빠르게 적응하고 확장할 수 있도록 설계되었습니다.
💡 논문 해설
1. **통합 평가 프레임워크**: UltraEval-Audio는 오디오 모델을 평가하기 위한 첫 번째 통합 프레임워크로, 다양한 언어와 작업 유형을 지원합니다. 이는 여러 모델과 벤치마크를 한 곳에 통합하여 비교 가능한 평가 환경을 제공합니다.
2. **오디오 코덱의 다차원 평가 방안**: 오디오 코덱의 정확성, 음색 일炤
📄 논문 발췌 (ArXiv Source)
# 서론
대형 언어 모델(LLMs)의 혁신적인 성공을 바탕으로, 다중모드 대형 모델의 빠른 발전이 이어졌습니다. 특히 OpenAI의 GPT-4o의 출시는 원래 오디오 상호작용 시대를 열었으며, 이를 통해 오디오 기반 모델(AFMs)의 폭발적인 발전을 촉진했습니다. 그 결과 복잡한 이해와 생성 능력을 갖춘 여러 모델들이 등장했고, 이는 인간과 컴퓨터 간 상호작용의 경계를 크게 확장했습니다. Qwen2.5-Omni, Moshi, GLM-4-Voice, Step-Audio, Kimi-Audio, MiniCPM-o 2.6와 같은 모델들이 포함되어 있습니다. 그러나 이러한 모델들의 능력이 급속도로 발전함에 따라 이들을 객관적이고 체계적으로 평가하는 것이 학술적인 관심사의 초점이 되었습니다. 현재 오디오 평가는 통일된 프레임워크가 부족하며, 데이터셋과 코드가 다양한 출처에 흩어져 있어 공정하고 효율적인 모델 간 비교를 크게 방해합니다.
평가 프레임워크의 분산화 문제 외에도 기존 평가 시스템은 평가 깊이와 언어 커버리지 면에서 많은 제한을 가지고 있습니다. 전통적인 평가 도구는 특정 작업, 예를 들어 자동 음성 인식(ASR)이나 자동 음성 번역(AST)을 위해 설계되었기 때문에 일반적인 상호작용 능력을 갖춘 오디오 기반 모델(AFMs)에 쉽게 적용할 수 없습니다. 특히 프롬프트 관리와 추론 파라미터 조정과 같은 부분은 AFMs의 종합적인 평가에 중요한 역할을 합니다. 이러한 모델의 능력이 급속도로 발전함에 따라, ASR 및 AST 작업 외에도 사용자 중심 음성 벤치마크가 등장하고 있습니다. 그러나 이들 벤치마크는 여전히 다음과 같은 핵심적인 도전 과제를 마주하고 있습니다:
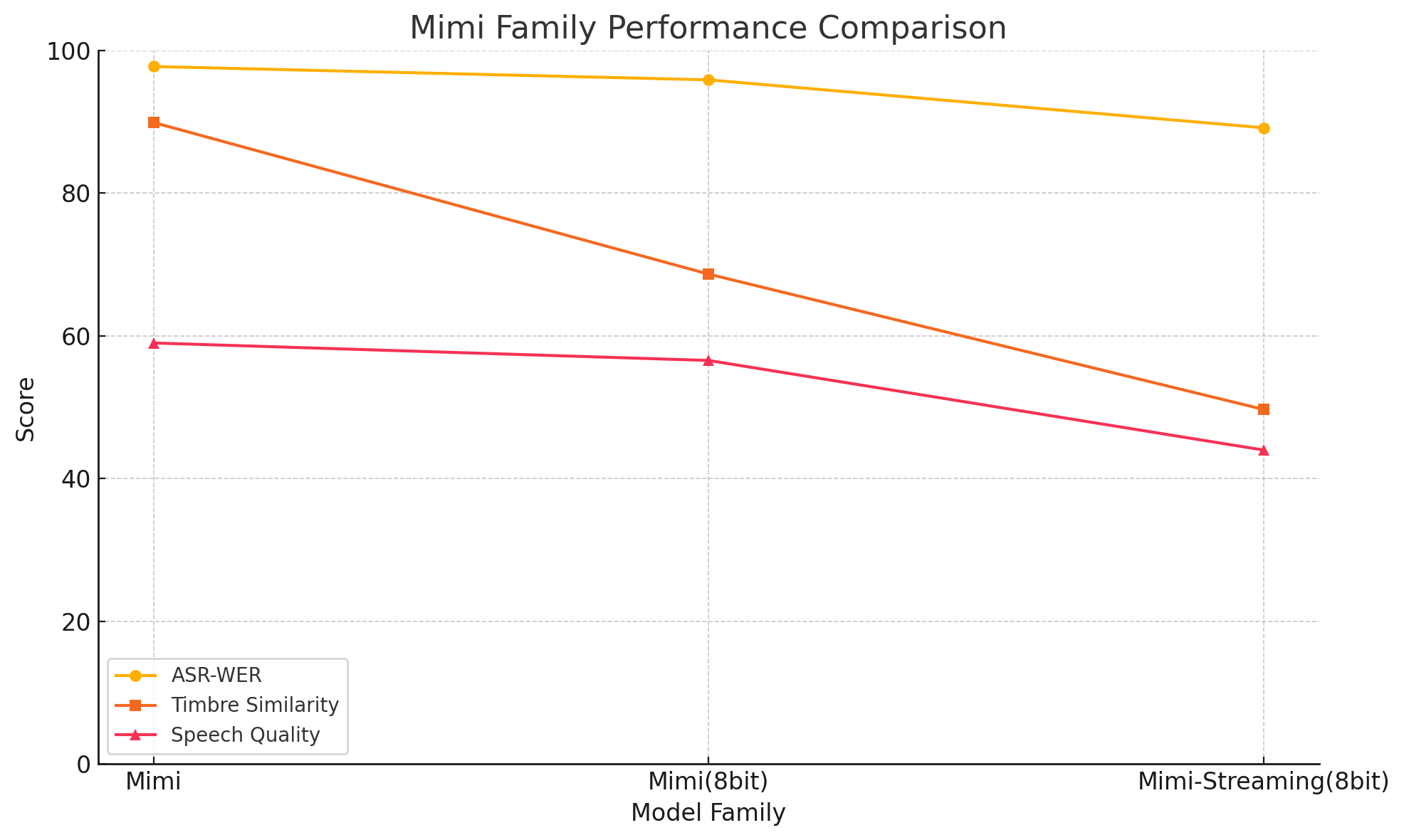
(1) 오디오 코덱은 AFMs의 주축 역할을 하는데, 체계적인 성능 지표가 부족합니다. 오디오 코덱은 오디오 토크나이저(오디오를 이산화된 토큰으로 변환)와 보코더(생성된 토큰에서 오디오를 재구성)로 구성됩니다. 이러한 디자인이 오디오 표현의 정확도와 효율성을 직접적으로 결정하며, AFMs의 전반적인 성능에 크게 영향을 미칩니다. 현재 방법은 광범위하지만 특정 성능 차원에서 제한된 통찰력을 제공합니다.
(2) 기존 벤치마크는 주로 영어에 의존하고 있어 중국어 환경에서 모델의 성능을 객관적으로 평가하는 것이 어렵습니다. SpeechTriviaQA, SpeechWebQuestions 및 SpeechAlpacaEval과 같은 주류 벤치마크는 대부분 영어 중심으로 이루어져 있어 중국어 맥락에서의 지식과 언어 능력을 충분히 측정하지 못합니다.
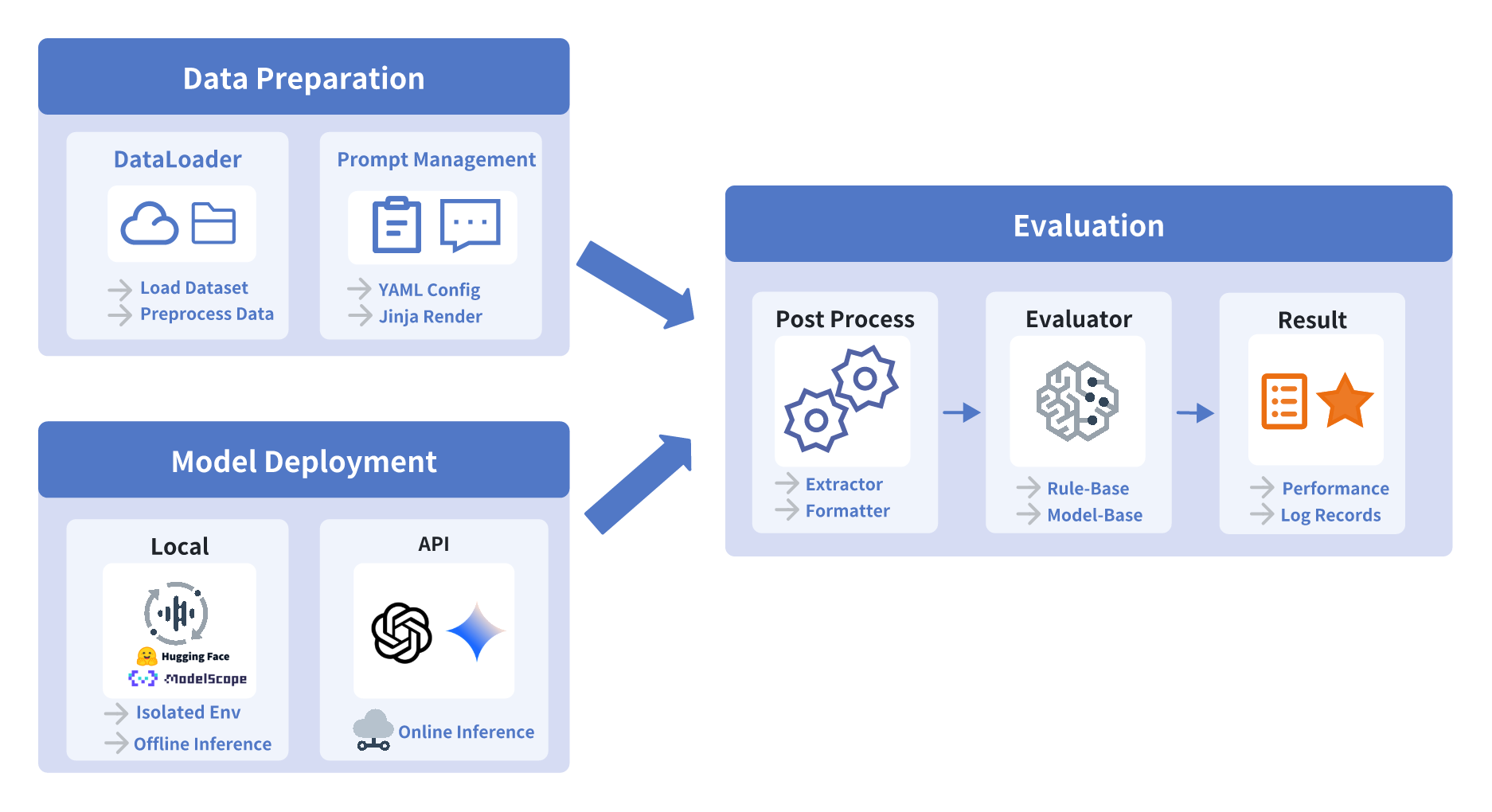
이러한 도전 과제를 해결하기 위해 UltraEval-Audio라는 오디오 기반 모델을 위한 통합 평가 프레임워크를 제안합니다. 데이터 로딩부터 프롬프트 관리, 추론 파라미터 조정 그리고 다양한 후처리와 집계 방법까지 분리하여 이 프레임워크는 연구자들에게 통일되고 유연한 평가 환경을 제공합니다. 사용자는 간단한 “클릭 한 번” 자동 스크립트를 통해 평가 과정을 빠르게 시작할 수 있습니다. 이 분리된 프레임워크 설계는 실험의 재현성을 향상시키며, 연구자들의 신속한 적응과 유연한 확장을 용이하게 합니다. 또한 UltraEval-Audio는 혁신적으로 오디오 코덱 평가 방안과 여러 중국어 평가 벤치마크를 도입하여 모델 구성 요소와 평가 벤치마크의 부족을 보완합니다. 이러한 통합을 통해 UltraEval-Audio는 평가 과정 전체를 표준화하고 투명성을 높이려고 합니다. 실시간 공개 오디오 리더보드를 제공함으로써, 이 프레임워크는 오디오 기반 모델 분야의 해석 가능성과 공정성 증진에 기여합니다. 우리의 기여는 다음과 같습니다:
첫 번째 통합 오디오 평가 프레임워크: UltraEval-Audio는 “텍스트 → 오디오”, “텍스트 + 오디오 → 텍스트”, “오디오 → 텍스트” 및 “텍스트 + 오디오 → 오디오"와 같은 다양한 입력-출력 모달리를 지원합니다. 이 프레임워크는 10개 언어, 14개 핵심 작업 카테고리 그리고 24개 주류 모델과 36개 권위 있는 벤치마크를 깊게 통합하여 음성, 환경음, 음악 세 가지 주요 영역을 커버합니다. 사용자 친화적인 설계 덕분에 이 프레임워크는 “클릭 한 번” 평가 기능과 투명한 비교를 위한 공개 리더보드를 제공합니다.