- Title: SwinIFS Landmark Guided Swin Transformer For Identity Preserving Face Super Resolution
- ArXiv ID: 2601.01406
- 발행일: 2026-01-04
- 저자: Habiba Kausar, Saeed Anwar, Omar Jamal Hammad, Abdul Bais
📝 초록
본 논문은 얼굴 초해상화(Face Super-Resolution, FSR)를 위해 랜드마크 지도와 Swin Transformer를 통합한 새로운 접근 방법을 제안한다. 이 접근 방식은 고해상도(HR) 이미지의 구조적 일관성과 개별적인 특징을 유지하면서 저해상도(LR) 입력에서 얼굴 이미지를 복원하는 데 초점을 맞추고 있다. 특히, 본 논문은 랜드마크 지도를 통해 얼굴 구조를 안내하고 Swin Transformer의 장거리 종속성 모델링 능력을 활용하여 극단적인 확대 비율에서도 일관된 결과를 얻을 수 있는 방법론을 제시한다.
💡 논문 해설
1. **랜드마크 지도와 Swin Transformer의 통합**: 본 논문은 얼굴 구조를 유지하면서 고해상도 이미지를 복원하는 데 필요한 정보를 제공하는 랜드마크 지도와, 장거리 종속성을 효과적으로 처리할 수 있는 Swin Transformer를 결합한 방법론을 제시한다. 이는 마치 건물을 세우기 위해 기본 구조(랜드마크)를 먼저 설정하고, 그 위에 다양한 디테일(Transformer)을 추가하는 것과 같다.
다중 스케일 지원: 본 논문의 접근 방법은 4배와 8배 확대 비율 모두에서 우수한 성능을 보여준다. 이는 마치 카메라가 다양한 조건에서도 명확한 이미지를 캡처할 수 있는 것과 같다.
구조적 일관성 유지: 본 논문은 얼굴 구조의 일관성을 유지하면서 고해상도 복원을 수행한다. 이는 마치 미술 작품을 복제하는 데 필요한 세부 사항을 모두 포함시키면서 원작의 정신을 유지하려고 하는 것과 같다.
Sci-Tube 스타일 스크립트
쉬운 수준
본 논문은 얼굴 이미지를 더 선명하게 복원하는 방법을 제시한다. 이를 위해 얼굴의 주요 지점을 나타내는 랜드마크를 사용하고, 이 정보를 기반으로 Swin Transformer가 고해상도 이미지를 생성한다.
중간 수준
본 논문은 얼굴 초해상화(Face Super-Resolution)에서 랜드마크 지도와 Swin Transformer의 통합을 제안한다. 이를 통해 저해상도 입력에서도 구조적 일관성을 유지하면서 고해상도 이미지를 생성할 수 있다.
어려운 수준
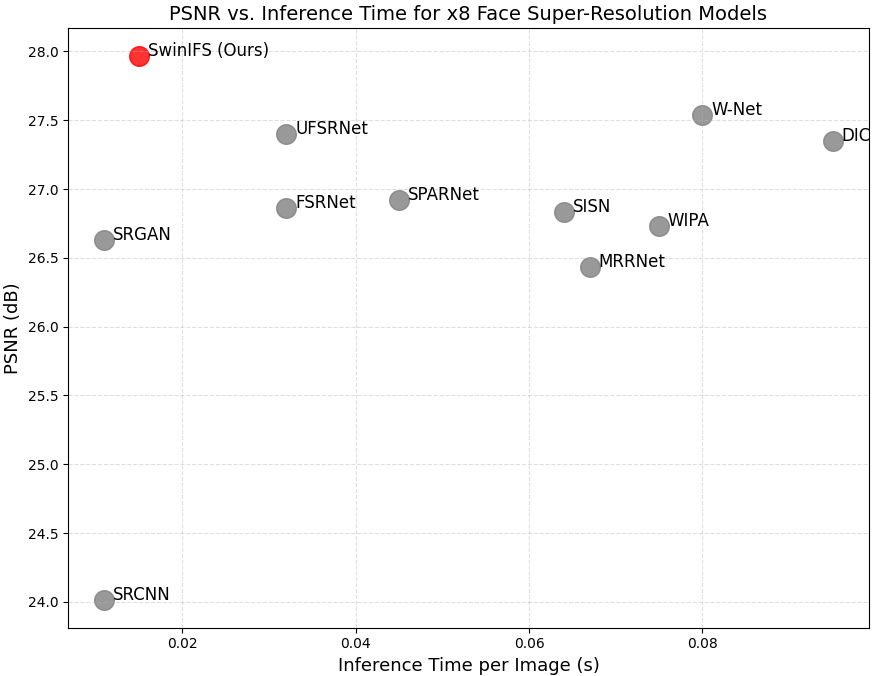
본 논문은 얼굴 초해상화(FSR)에서 랜드마크 지도와 Swin Transformer를 통합한 방법론을 제시한다. 이 접근 방식은 저해상도 입력에서 고해상도 복원을 수행하면서 구조적 일관성을 유지하고, 4배와 8배 확대 비율 모두에서 우수한 성능을 보여준다.
📄 논문 발췌 (ArXiv Source)
# 서론
얼굴 초해상화(Face Super-Resolution)는 저해상도(LR) 입력에서 고해상도(HR) 얼굴 이미지를 복원하면서 구조적 일관성과 개별적인 세부 사항을 유지하는 것을 목표로 한다. 얼굴 특징의 신뢰할 수 있는 복원은 감시, 생체인식, 법의학, 비디오 회의, 미디어 향상 등 다양한 응용 분야에 필수적이다. 일반적인 초해상화와 달리 FSR은 인간 얼굴의 강력한 기하학적 규칙성을 활용하여 눈, 코, 입 등의 주요 구성 요소의 공간 배치를 복원하는 데 유용한 사전 정보를 제공한다.
여기서 $`I_\mathrm{HR}`$은 HR 이미지, $`I_\mathrm{LR}`$은 LR 이미지, $`k`$는 블러 커널, $`\downarrow_{s}`$는 다운샘플링 연산자이며, $`\eta`$는 노이즈를 나타낸다. 실제 환경에서는 압축 아티팩트, 조명 변화 및 센서 노이즈로 인해 퇴화가 더욱 복잡해진다. 중간 확대 비율(예: 4x)에서 일부 구조적 단서는 남아 있지만, 극단적인 스케일(예: 8x; 16x 입력)에서는 대부분의 개인별 단서가 사라져 복원이 매우 불확실해진다.
초기 얼굴 환각 방법은 보간법, 예제 기반 패치 검색 또는 희소 코딩에 의존했다. 이러한 접근 방식은 획기적이었지만, 결과가 지나치게 부드럽고 도메인 변이에 대한 강인성이 부족했다. 딥러닝의 도입으로 SR 성능이 크게 개선되었다. CNN 기반 방법들은 텍스처 복원을 개선했지만, 국소 수용 필드로 인해 전역적으로 일관된 얼굴 구조를 유지하는 데 한계가 있었다.
생성 적대적 네트워크(GANs)는 실제성을 학습하여 더 선명한 텍스처를 합성함으로써 주관적인 현실감을 개선했다. FSRNet 및 Super-FAN은 랜드마크나 파싱 맵과 같은 얼굴 사전 정보를 결합하여 구조적 정렬을 강화하는 GAN 목표를 보여주었다. 그러나 GAN 기반 방법들은 극단적으로 퇴화된 입력에서 현실적이지 않은 세부 사항을 생성하고 개인별 특징을 유지하는 데 어려움이 있었다.
Transformer 아키텍처는 자기 주의를 통해 장거리 종속성을 포착할 수 있는 강력한 도구로 최근 부각되었다. Swin Transformer는 계층적 윈도 기반 주의를 소개하여 전역 모델링과 계산 효율성 사이의 효과적인 균형을 제공한다. 그러나 이러한 접근 방식은 심하게 퇴화된 입력에서 중요한 얼굴 단서가 부족한 경우에 어려움을 겪는다. 명시적 기하학적 사전 정보를 통합하면 이 불확실성을 완화할 수 있다.
랜드마크 지도는 주요 얼굴 구역의 기하학에 대한 간결하고 신뢰할 수 있는 구조적 정보를 제공한다. 히트맵으로 인코딩될 때, 이러한 정보는 복원 과정에서 특징 정렬, 얼굴 대칭성 및 개인별 일관성을 유지하는 데 필요한 공간적인 안내를 제공한다. 이러한 통찰력을 바탕으로 본 논문은 극단적인 스케일(예: 8x 입력)에서도 우수한 결과를 얻을 수 있는 랜드마크 지도 기반 다중 스케일 Swin Transformer 프레임워크를 제안한다.
본 논문의 방법론은 RGB 색상 정보와 랜드마크 히트맵을 결합하여 얼굴 텍스처와 기하학을 공동으로 모델링한다. Swin Transformer 백본은 전역적 맥락 관계를 포착하고, 랜드마크 사전 정보는 구조적 일관성을 강화한다. 이 통합 접근 방식은 여러 확대 비율에서 견고한 복원을 가능하게 하며 개인별 신뢰성도 크게 향상시킨다. CelebA 데이터셋에 대한 실험 결과, 제안된 프레임워크는 대표적인 CNN, GAN 및 Transformer 기반 베이스라인과 비교하여 주관적 품질, 구조적 정확성 및 양적 성능에서 우수한 성과를 보여준다.
관련 연구
얼굴 초해상화는 지난 20년 동안 초기 보간법에서 현대 딥러닝, 적대적 네트워크 및 트랜스포머 기반 프레임워크로 크게 진화했다. 일반적인 단일 이미지 초해상화(SISR)와 달리 FSR은 개인별 특징과 얼굴 기하학의 강력한 보존을 요구하며, 구조적 모델링이 핵심 연구 과제다.
초기 작업들은 보간법 및 예제 기반 방법에 의존했다. 이러한 접근 방식은 계산 효율적이었지만 지나치게 부드러운 텍스처를 생성하고 고주파수 얼굴 세부 사항을 복원하는 데 실패했다. 학습 기반 확장, 특히 희소 코딩 및 다양체 모델은 일부 텍스처 합성을 개선했지만 심각한 퇴화와 제한된 일반화에 직면했다.
딥러닝은 FSR 성능을 크게 향상시켰다. SRCNN, VDSR, EDSR 등 CNN 기반 아키텍처는 계층적 특징 학습이 전통적인 방법보다 우수함을 보여주었다. 얼굴 특정 확장으로 FSRNet 및 URDGN은 랜드마크 히트맵이나 얼굴 파싱 맵과 같은 구조적 사전 정보를 통합했다. 이러한 모델들은 정렬과 구조적 일관성을 개선했지만 픽셀 단위 손실에 의존해 부드러운 출력을 생성하고 고주파수 합성에서 제한적이었다.
GAN 프레임워크의 도입은 주관적인 현실감으로 연구 초점을 이동시켰다. SRGAN은 적대적 및 주관적 손실을 사용하여 더 선명한 텍스처를 보여주었다. 얼굴 특정 GAN 모델인 Super-FAN, FSRGAN, DICGAN는 신원 손실, 정렬 모듈 또는 사이클 일관성을 포함시켜 현실감과 개인별 특징 유지에 효과적이었다. 그러나 GAN 기반의 FSR은 훈련 불안정성에 민감하고 극단적인 다운샘플링에서 부실한 얼굴 특징을 생성할 수 있다.
최근에는 주의력 및 트랜스포머 기반 방법들이 장거리 종속성을 모델링하여 FSR을 크게 발전시켰다. Vision Transformers는 전역 패치 기반 주의를 도입했지만, 높은 계산 비용으로 인해 저수준 복원에 제한되었다. Swin Transformer는 계층적 이동 윈도 주의를 사용하여 전역 맥락을 효율적으로 모델링할 수 있게 하였다. FaceFormer, UFSRNet, W-Net 등 여러 FSR 방법은 CNN 분⽀ 또는 의미 사전 정보와 함께 주의를 결합한 트랜스포머 모듈을 도입하였다. 이러한 접근 방식은 강력한 주관적 및 구조적 성능을 제공하지만 큰 메모리와 긴 훈련 시간이 필요하며 일반적으로 단일 확대 비율로 훈련된다. 또한 명시적인 기하학적 사전 정보인 얼굴 랜드마크는 효과적이지만 트랜스포머 설계에서 여전히 활용되지 않은 경우가 많다.
기존의 CNN과 GAN 방법론은 고주파수 세부 사항 복원과 개인별 신뢰성 사이의 균형을 이루지 못한다. 한편, 트랜스포머 모델은 복잡성과 구조적 조건 부족으로 인해 전역 모델링 성능이 제한된다. 이러한 한계를 극복하기 위해 본 논문은 명시적인 랜드마크 사전 정보와 효율적인 Swin Transformer 백본을 통합하는 접근 방식을 제안한다.
또한, 최근 연구는 다양한 실제 퇴화(압축, 가리기 및 큰 자세 변화)를 처리할 수 있는 다중 스케일 FSR 시스템의 필요성을 강조하고 있다. 대부분의 현재 모델은 단일 고정 확대 비율 또는 제어된 실험실 조건에서 훈련되므로 얼굴 해상도가 다양하게 변하는 실제 상황에 대한 일반화를 제한한다. CNN 및 GAN 아키텍처에서 입증된 가치에도 불구하고 구조적 사전 정보는 트랜스포머 백본에 깊게 통합되지 않는 경우가 많다. 이 격차는 기하학적 단서와 전역 주의를 자연스럽게 결합하여 중간 및 극단적인 확대 비율에서 안정적이면서 개인별 일관성을 유지하는 재구성으로 새로운 프레임워크를 개발할 수 있는 기회를 제공한다.
SwinIFS
얼굴 초해상화는 저해상도 입력이 여러 가능한 고해상도 얼굴 구성에 대응할 수 있기 때문에 본질적으로 불확실한 문제이다. 이 불확실성은 LR 이미지가 HR 이미지에서 발견되는 세밀한 텍스처 세부 사항, 미묘한 개인별 단서 및 구조적 규칙성을 포함하지 않기 때문이다. 이를 해결하기 위해 본 방법론은 얼굴 랜드마크의 구조적 사전 정보를 Swin Transformers의 계층적 모델링 능력과 통합한다. 랜드마크 히트맵은 눈, 코 및 입과 같은 개인별 특징 영역에 대한 명시적인 기하학적 안내를 제공하며 동시에 Swin Transformers는 국부적 텍스처 패턴과 얼굴 구역 간의 장거리 종속성을 포착하여 전역 공간 추론을 가능하게 한다.
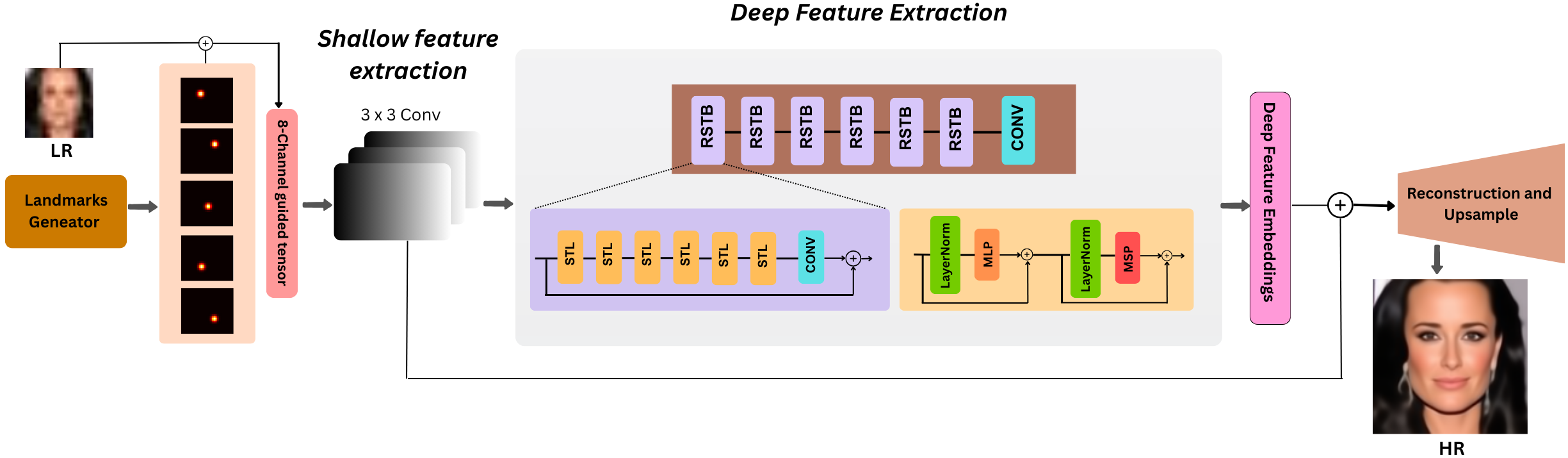
전체 파이프라인은 그림 1에 설명되어 있다. 프레임워크는 네 가지 주요 단계를 거친다: 랜드마크 인코딩 및 입력 구성, 얕고 깊은 특징 추출, Residual Swin Transformer Blocks (RSTBs)을 통한 트랜스포머 기반 정제, 서브-픽셀 업샘플링을 사용한 재구성. 각 단계는 구조적 정렬, 개인별 일관성을 증진하고 퇴화된 얼굴 이미지에서 고주파수 세부 사항을 복원하도록 신중하게 설계되었다.
제안된 SwinIFS 프레임워크의 개요. 파이프라인은 랜드마크 지도를 사용한 입력 구성에서 시작하여 LR 이미지를 5개의 가우시안 히트맵과 결합해 8채널 텐서를 형성한다. 얕은 특징 추출 단계에서는 이 텐서가 고차원 임베딩으로 프로젝트되며, 그 다음에는 쌓여진 RSTBs와 STLs을 사용한 계층적 정제가 이루어진다. 마지막으로 재구성 및 PixelShuffle 업샘플링 모듈이 신원을 유지하면서 세밀한 구조적 세부 사항을 복원하는 고해상도 얼굴 이미지를 합성한다.
랜드마크 인코딩 및 입력 구성
네트워크에 의미 있는 기하학 정보를 통합하기 위해, 우리는 정렬된 고해상도 입력에서 2차 Bicubic 보간을 사용하여 저해상도 이미지를 생성한다: $`I_{\mathrm{LR}} = \downarrow_{S}(I_{\mathrm{HR}}),~where~S \in \{4,8\}`$. 이는 기본 시각적 입력을 제공한다. 그러나 LR 얼굴은 중요한 구조적 단서를 부족하게 하여 신원 일관성 있는 고주파수 내용을 추론하는 데 어려움이 있다. 이를 완화하기 위해 우리는 5개의 주요 랜드마크(왼쪽 눈, 오른쪽 눈, 코 및 입 케어너)를 추출하고 각 점을 가우시안 히트맵 $`M_i`$로 변환한다. 이러한 히트맵은 중요한 얼굴 구성 요소의 위치를 나타내는 부드럽고 공간적으로 인식 가능한 표현을 생성하며, 단순한 이산 랜드마크 좌표만 제공하지 않는다. 5개의 히트맵을 쌓으면 $`M_{\mathrm{c}} \in \mathbb{R}^{C\times H \times W}`$, 여기서 $`C=5`$가 된다. 마지막으로, LR RGB 이미지와 랜드마크 맵이 결합된다:
여기서 $`||`$는 결합을 나타낸다. 이는 8채널 텐서를 생성하여 외관과 기하학을 명시적으로 인코딩하며, 네트워크가 처리의 초기 단계부터 구조적 사전 정보와 텍스처 정보를 융합할 수 있도록 한다. 입력에 기하학을 직접 내장함으로써 모델은 LR 이미지에서 부족하거나 불명확한 시각적 단서에 의존하지 않도록 한다.
얕고 깊은 특징 추출
SwinIFS 네트워크는 이 8채널 입력을 고차원 특징 공간으로 투영하기 위해 컨볼루션 $`H_{\mathrm{SF}}`$를 사용한다:
여기서 $`F_0`$는 추출된 특징이다. 이 과정은 공간 해상도를 유지하면서 표현 능력을 확장한다. 얕은 특징은 국부적 에지, 거친 텍스처 및 랜드마크 히트맵의 공간 분포를 포착한다. 이러한 인코딩된 단서는 더 깊은 추론을 위한 기초를 제공한다. 다음으로, 특성 텐서는 $`D`$ 개 쌓여진 Residual Swin Transformer Blocks (RSTBs)을 통과한다. 각 RSTB는 초기 계층에서 국부적 텍스처 패턴부터 더 깊은 계층에서 전역 구조 및 개인별 관련 특징까지 점진적으로 복잡한 의미 정보를 학습한다. 파이프라인은 재귀적 형식을 따르며:
Swin Transformer Layers는 특징 맵을 국부적 윈도로 나누고 각 윈도 내에서 멀티헤드 자기 주의를 수행한다. 이 작업은 모델이 공간적 및 맥락적 관계에 따라 관련 영역을 선택적으로 강화할 수 있게 한다. 정규와 이동 윈도 파티션 사이의 교차 윈도 통신을 허용함으로써 수용 필드를 효과적으로 확장한다. 따라서, 모델은 전역 얼굴 기하학(전체 머리 형태 및 대칭성)과 세밀한 구조적 관계(눈 거리 및 입 곡률)를 동시에 학습할 수 있다. 저주파수 내용의 손실을 방지하고 안정성을 유지하기 위해 전역 스킵 연결이 얕고 깊은 특징을 결합한다:
이 융합은 초기 입력에서 구조적 단서가 그대로 유지되면서 깊은 계층이 고주파수 텍스처 및 개인별 세부 사항을 정제하도록 한다.
Residual Swin Transformer Block
RSTB는 SwinIFS의 계층적 표현 학습을 가능하게 하는 기본 모듈이다. 입력 $`F_{i,0}`$를 받아 $`L`$ 개의 연속 Swin Transformer Layers (Eq. [eq:5])로 적용한다. 각 STL에서 윈도 크기 $`M\times M`$ 내에서 멀티헤드 자기 주의가 수행된다. 윈도 특징 $`X \in \mathbb{R}^{M^2 \times C}`$에 대해 쿼리, 키 및 값 행렬은 다음과 같이 계산된다: $`Q = XW_Q,\quad K = XW_K,\quad V = XW_V`$. 국부적 주의는 다음과 같이 평가된다:
$`\mathrm{Attention}(Q,K,V) = \mathrm{Softmax}\!\left(\frac{QK^\top}{\sqrt{d}} + B\right)V,`$
여기서 $`B`$는 학습 가능한 상대 위치 인코딩을 추가하여 모델이 동일한 의미적 영역(예: 눈의 꼭지점이나 입의 경계)에 속하는 픽셀 간 연관성을 감지할 수 있게 한다.
윈도 이동은 시그널들이 고정된 윈도 내에서만 유지되는 것을 방지하고 장거리 얼굴 관계를 학습할 수 있게 하는 메커니즘을 제공한다. 교차 윈도 설계는 정보가 전체 얼굴에 걸쳐 부드럽게 흐르도록 보장한다. $`L`$ STL 후, 컨볼루션은 정제된 특징을 통합하고 잔차 추가를 수행한다:
이 설계는 두 가지 중요한 이점을 제공한다. 변위 일관성: 컨볼루션 계층은 공간적으로 불변 필터링을 도입하여 공간적으로 변동하는 트랜스포머 주의를 보완한다. 신원 유지: 잔차 스킵 연결은 신뢰할 수 있는 구조적 단서가 유지되면서 고주파수 세부 사항과 개인별 특징이 정제될 수 있도록 한다.