- Title: DeepInv A Novel Self-supervised Learning Approach for Fast and Accurate Diffusion Inversion
- ArXiv ID: 2601.01487
- 발행일: 2026-01-04
- 저자: Ziyue Zhang, Luxi Lin, Xiaolin Hu, Chao Chang, HuaiXi Wang, Yiyi Zhou, Rongrong Ji
📝 초록
확산 역전은 확산 모델에서 이미지의 노이즈를 복원하는 작업으로, 이는 제어 가능한 확산 이미지 편집에 필수적입니다. 현재로서는 사용 가능한 감독 신호 부재로 인해 확산 역전은 여전히 난제인 상태입니다. 따라서 대부분의 기존 방법은 성능이나 효율성을 희생하면서 근사기반 해법을 사용하고 있습니다. 이러한 문제점들을 해결하기 위해 본 논문에서는 새로운 자기 감독 확산 역전 접근법, 즉 딥 인버전(DeepInv)을 제안합니다. 진정한 노이즈 주석을 요구하지 않으며, 대신 실제 이미지로부터 수동 개입 없이 고品質 가짜 노이즈를 생성하기 위해 자기 감독 목적 및 데이터 증강 전략을 도입했습니다. 이러한 두 가지 혁신적인 설계를 기반으로 DeepInv는 파라미터화된 역전 솔버를 훈련하기 위한 반복적이고 다중 규모의 훈련 체제가 구비되어 있어, 빠르고 정확한 이미지에서 노이즈로의 매핑을 달성할 수 있습니다. 우리의 지식에 따르면 이는 단계별 역전 노이즈를 예측하는 학습 가능한 솔버를 제시한 최초의 시도입니다. 광범위한 실험 결과 DeepInv가 비교 대상 방법보다 훨씬 더 우수한 성능과 추론 속도(+40.435% SSIM 보다 EasyInv, COCO 데이터셋에서 ReNoise 보다 +9887.5% 빠름)를 달성할 수 있음을 보여주고 있습니다. 또한 우리의 학습 가능한 솔버에 대한 세심한 설계는 연구 커뮤니티에도 통찰력을 제공합니다. 코드와 모델 파라미터는 https://github.com/potato-kitty/DeepInv 에서 공개될 예정입니다.
💡 논문 해설
1. **자기 조정 학습 기반 디퓨전 역변환 방법**
- **단순 설명**: 이 연구는 이미지 생성 모델에서 중요한 역할을 하는 역변환 과정을 개선하기 위해 새로운 접근법인 DeepInv를 제시합니다. 이 방식은 이미지의 잡음을 직접 예측하여 더 빠르고 정확한 결과를 얻는 방법입니다.
- **비유**: 딥러닝 모델이 이미지를 만들 때, 그 과정을 거꾸로 돌리는 것은 마치 복잡한 퍼즐을 다시 조립하는 것과 같습니다. DeepInv는 이를 더 쉽게 할 수 있는 지름길을 제공합니다.
SD3와 Flux에 대한 파라미터화된 역변환 해법
단순 설명: 이 연구에서는 SD3와 Flux라는 두 가지 중요한 이미지 생성 모델에 대해 특별히 설계된 역변환 방법을 제시합니다. 이를 통해 기존의 방법보다 훨씬 빠르고 정확한 결과를 얻을 수 있습니다.
비유: 이 연구는 각각의 프로젝트에 맞게 조정할 수 있는 도구 상자를 제공하는 것과 같습니다. 각 모델은 그들만의 특별한 도구를 가지고 있어 더 효과적으로 일을 처리할 수 있습니다.
효율적인 자기 조정 학습 방법
단순 설명: 이 연구에서는 역변환 과정을 더 효율적으로 수행하기 위해 새로운 자기 조정 학습 방법을 제안합니다. 이를 통해 모델은 스스로 학습하고 개선할 수 있습니다.
비유: 이 방법은 마치 자동으로 문제를 찾아 해결하는 스마트한 학생과 같습니다. 스스로 문제를 분석하고 해결책을 찾는 능력이 있어 더 빠르고 효과적으로 일을 처리할 수 있습니다.
📄 논문 발췌 (ArXiv Source)
style="width:100.0%" />
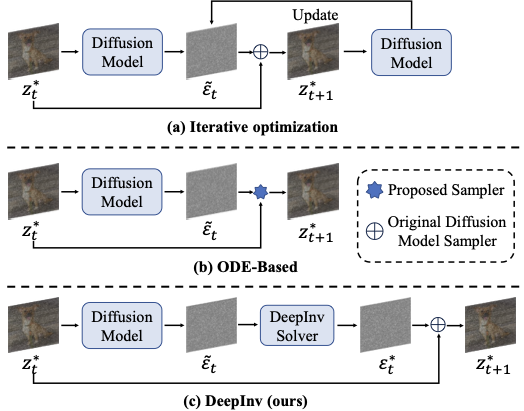
우리의 DeepInv와 기존 역변환 방법들의 설명도입니다. (a) 반복 최적화 방법은 각 시간 단계마다 역변환 잡음을 업데이트하지만, 이는 과도한 시간이 필요합니다. (b) 일반 미분 방정식(ODE) 기반 접근법은 효율적인 역변환 샘플러를 설계하지만, 재구성 품질을 포기해야 할 때가 많습니다. (c) DeepInv는 처음으로 단계별로 역변환 문제 해결기를 학습해 빠르고 정확하게 예측할 수 있도록 합니다. style="width:100.0%" />
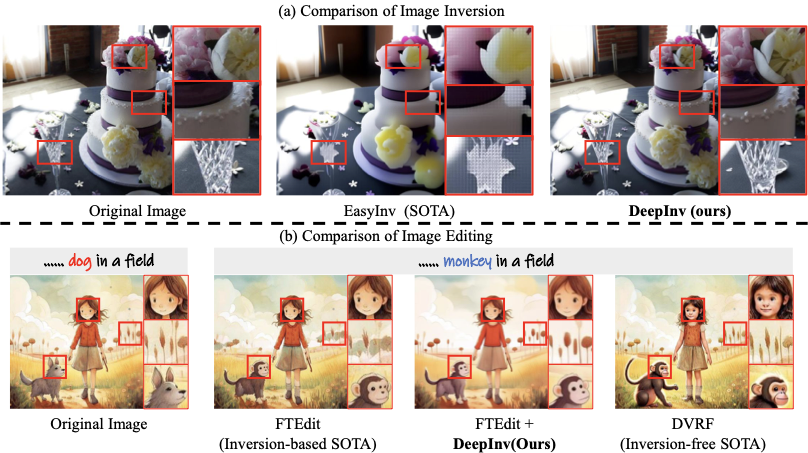
우리의 DeepInv와 기존 SOTA 방법(EasyInv, FTEdit 및 DVRF) 간의 이미지 역변환(a)과 편집(b) 비교입니다. (a)는 이미지 역변환의 시각화를 보여주며, 우리의 DeepInv가 EasyInv보다 원본 이미지의 세부 사항을 더 잘 유지할 수 있음을 나타냅니다. (b)는 텍스트 프롬프트에 따른 이미지 편집 결과를 보여줍니다. DeepInv로 예측된 역변환 잡음은 FTEdit가 텍스트 프롬프트와 잘 맞는 편집 결과를 달성하는 데 도움을 주지만, 비교 대상 방법들은 정렬에 실패할 가능성이 큽니다.
소개
최근 몇 년 동안 이미지 확산 모델은 이미지 생성 분야에서 큰 진전을 이루었습니다. 대표적인 확산 모델인 Stable Diffusion 시리즈와 DALL-E3는 이전의 생성 접근법보다 훨씬 뛰어난 능력을 보여주고 있습니다. 확산 기반 이미지 편집에 있어서, 확산 역변환은 학계와 산업계에서 점점 더 많은 관심을 받는 연구의 핫스팟입니다. 이 작업의 목표는 잡음 공간과 실제 이미지 간의 매핑을 달성하는 것입니다. 이를 통해 확산 모델은 정확하고 제어 가능한 이미지 생성이나 조작을 수행할 수 있습니다. 그럼에도 불구하고, 기존의 역변환 방법들은 성능과 효율성을 동시에 만족시키는 결과를 얻기 어렵습니다. 특히, 역변환에 있어 중요한 도전 과제 중 하나는 정답 주석이 부재인 것입니다. 이 때문에 전통적인 감독 학습 패러다임을 사용하여 이미지 역변환을 구현하기가 어려워지고 있습니다. 대신 연구자들은 반복 최적화와 일반 미분 방정식(ODE) 기반 접근법과 같은 근사기반 전략으로 이동해야 합니다(Fig. 1 참조). 이러한 노력은 크게 진전을 이루었지만, 여전히 계산 복잡도, 역변환 불안정성 또는 낮은 재구성 품질 등의 문제를 겪고 있습니다. Fig. 2에서 보듯이, SOTA 방법인 EasyInv는 재구성 과정을 크게 단축시키지만, 복잡한 텍스처나 구조 세부 사항을 가진 이미지를 처리하는 데 어려움을 겪습니다. 또한, 하류 작업에서는 역변환 없는 접근법 DVRF가 비편집 영역에서 일관성을 유지하지 못하고, 반면에 FTEdit는 4개의 눈이 있는 돈을 생성합니다. 전체적으로 빠르고 안정적이며 고품질의 확산 역변환은 여전히 해결되지 않은 문제입니다.
이러한 도전 과제를 극복하기 위해 본 논문에서는 새로운 자기 조정 학습 기반의 역변환 접근법인 Deep Inversion (DeepInv)을 제시합니다. DeepInv의 주요 원칙은 효과적인 자기 감독 신호를 탐색하여 매개 변수화된 문제 해결기를 직접 학습하는 것입니다. 이를 위해, DeepInv는 고정점 반복 이론을 활용해 실제 이미지에서 의사 잡음 주석을 자동으로 유도합니다. 이러한 과정은 수작업이 필요하지 않습니다. 또한 선형 보간 기반의 새로운 데이터 증강 전략도 제안되어 제한된 실제 이미지로부터 고품질의 의사 정보를 최대한 활용할 수 있습니다. 이러한 설계에 따라 DeepInv는 의사 라벨 생성과 자기 조정 학습을 하나의 통합 프레임워크로 통합하는 새로운 훈련 방법론을 도입합니다. 여기서 다중 해상도 학습 원칙도 채택되어 역변환 문제 해결기의 능력을 점진적으로 개선합니다. 이러한 혁신적인 설계를 통해 DeepInv는 주어진 이미지의 잡음을 직접 예측할 수 있는 매개 변수화된 확산 문제 해결기를 효과적으로 학습하고, 효율성과 성능을 몇 배로 향상시킵니다.
style="width:100.0%" />
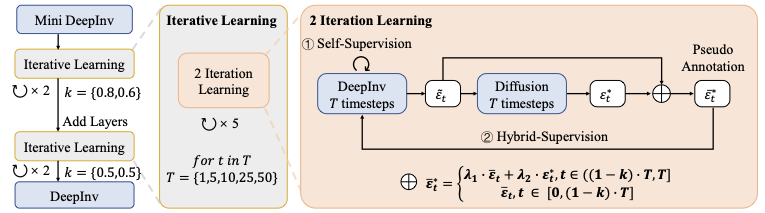
제안된 학습 프레임워크 개요. 우리는 역변환 문제 해결기의 기본 네트워크를 초기화하고 시작합니다. 훈련 과정은 4개의 반복 단계로 진행됩니다. 각 반복에서 문제 해결기는 5가지 다른 시간 단계 구성에 대해 학습되며, 각 구성에는 두 가지 다른 손실 함수를 사용하여 최적화를 수행하는 라운드가 있습니다. 반복 중 추가 층이 붙여지고 학습됩니다. 마지막으로 모든 매개변수는 학습률을 원래의 10%로 줄인 상태에서 공동 조정됩니다. 자세한 구현 방법은 Method 섹션 참조.
관련 작업
확산 모델은 잡음 오염 과정을 반복적으로 역방향으로 수행함으로써 생성 모델링에 혁신을 이루었습니다. DDPM은 안정적인 학습을 formalize했지만 샘플링 비용이 높아졌습니다. DDIM은 이후 결정론적 형식을 도입하여 품질을 유지하면서 샘플링 단계를 줄였습니다. 최근에는 새로운 설계들이 다음 세대의 확산 모델을 소개하며 성능 개선에 이바지했습니다. 확산 모델에서 또 다른 중요한 혁신은 교정 유동을 도입한 것입니다. 이를 통해 시간 단계 간의 소음 제거 방향을 일치시키는 새로운 학습 패러다임이 제안되었습니다. 일관된 잡음 예측 경로를 장려함으로써, 이 접근법은 출력 품질을 유지하면서 추론 단계를 줄이는 효율성을 높였습니다. 그러나 이러한 변화는 특별히 교정 유동 기반 모델에 맞게 설계된 전문적인 역변환 방법이 필요하게 하는 새로운 도전 과제를 제기했습니다. 이를 통해 현대 확산 아키텍처에서 효과적이고 고해상도의 생성을 가능하게 합니다.
DDIM Inversion은 주어진 이미지의 잡음을 복원하면서 구조적 일관성을 유지하기 위해 역방향 소음 제거 메커니즘을 도입한 초기 시도 중 하나입니다. Null-Text Inversion는 조건부와 비조건부 텍스트 임베딩을 분리하여 재구성 품질을 개선하고, 빈 프롬프트가 역변환 작업에 긍정적인 영향을 미칠 수 있음을 제안합니다. PTI는 소음 제거 단계를 통해 프롬프트 임베딩을 세밀하게 조정하여 더 나은 일치성을 달성합니다. ReNoise는 순환 최적화를 사용해 반복적으로 소음 추정값을 정교화하며, DirectInv는 역변환 이동을 감소시키기 위해 잠재 경로 정규화를 도입했습니다. 최근에는 Rectified Flow가 일관된 시간 단계 간의 소음 경로를 강제함으로써 훨씬 적은 추론 비용으로 고품질 생성을 달성하는 역변환 풍경을 재구성하였습니다. 이 기법은 Flux 및 SD3와 같은 고급 아키텍처에서 채택되어 새로운 역변환 방법의 개발을 유도했습니다. RF-Inversion과 RF-Solver는 각각 이 프레임워크 내에서 구현된 다른 해결책을 제안하며, 교정 유동 ODE를 풀기 위해 노력합니다. 텍스트 지향 편집 방법은 텍스트와 시각적 특징의 일치성을 통한 제어 가능한 생성을 지원합니다. Prompt-to-Prompt는 속성 편집을 위한 주의 맵 조작을 수행하지만 완전한 소음 제거가 필요합니다. 후속 작업인 Plug-and-Play 및 TurboEdit는 잠재적 혼합과 시간 이동 교정을 통해 효율성을 개선했습니다. TurboEdit는 배경 일관성에 손상 없이 편집 강도를 높이는 가이드 스케일링도 도입했습니다. 그러나 이러한 많은 방법은 공개되지 않거나 광범위한 학습 자원이 필요합니다. 반면, 우리의 방법은 경량화된 공개 소스 대안을 제공하며 경쟁력 있는 성능과 효율성을 갖추고 있습니다.
사전 지식
현재 역변환 작업은 기존 연구에서 고정점 문제로 간주됩니다. 주어진 함수 $`f(x)`$에 대해 일반적인 고정점 방정식은 다음과 같습니다:
style="width:100.0%" />
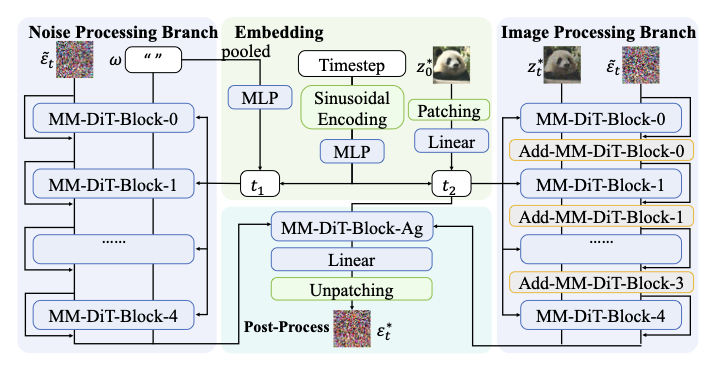
제안된 DeepInv 문제 해결기 구조. 이중 가지 설계는 잡음(왼쪽)과 이미지(오른쪽) 정보를 별도로 처리한 후 최종 집합합니다. 두 번째 마지막 라운드에서 추가 블록을 추가하여 모델 능력을 확장합니다.
방법
DeepInv
본 논문에서는 새로운 자기 조정 학습 패러다임인 DeepInv를 제시하며, 이는 파라미터화된 역변환 문제 해결기의 효과적인 훈련을 가능하게 합니다(Fig. 3 참조). 이를 위해 DeepInv는 시간 일관성, 점진적 정교화 및 다중 해상도 학습에 대한 새로운 자기 조정 학습 설계를 도입합니다.
개요
DeepInv는 사전 훈련된 확산 모델에서 파생된 잠재 표현을 사용하여 작동합니다. 주어진 입력 이미지 $`I`$가 사전 훈련된 확산 모델의 원래 VAE를 통해 잠재 코드 $`z_0^*`$로 인코딩됩니다:
여기서 $`-\varepsilon^*_t`$는 역변환 과정이 잡음을 추가하는 것임을 고려하여 반대 잡음으로 간주합니다. 따라서, 문제 해결기는 일관된 시간 추정치를 출력하여 밑바닥 깨끗한 잠재 코드 $`z_0^*`$를 재구성합니다. 이 경우 DeepInv의 전체 목표는 임의의 확산 모델에서 올바르고 시간 일관성 있는 역변환을 가능하게 하는 것입니다. 형식적으로, 문제 해결기는 예측된 잡음/잠재 코드와 정방향 과정으로부터 유도된 상대치 사이의 불일치를 최소화하여 진정한 역동력을 근사하도록 합니다. 이 목표는 다음과 같이 수식화할 수 있습니다:
여기서 역변환 잡음이 동일 시간 단계의 소음 제거와 정확히 같을 때 이상적인 역변환이 이루어진다고 보았습니다. 이 목표 함수가 지향하는 것입니다. Eq.[eq:obj_inversion]을 자기 조정 학습 목표로 고려하면, DeepInv의 손실 함수는 다음과 같이 정의됩니다:
여기서 $`d^*`$는 사전 훈련된 확산 모델을 나타내며, $`z^*_{t+1}`$는 잡음 $`\varepsilon_t^*`$를 $`z^*_t`$에 추가하여 생성됩니다. Eq.[eq:l2_loss]을 통해 우리의 DeepInv는 참조 없이 매개 변수화된 문제 해결기의 최적화를 수행할 수 있습니다.
또한, 소음 제거-역변환 융합에서 생성된 의사 라벨을 통합하기 위해 하이브리드 손실도 사용됩니다: