- Title: DrivingGen A Comprehensive Benchmark for Generative Video World Models in Autonomous Driving
- ArXiv ID: 2601.01528
- 발행일: 2026-01-04
- 저자: Yang Zhou, Hao Shao, Letian Wang, Zhuofan Zong, Hongsheng Li, Steven L. Waslander
📝 초록
비디오 생성 모델은 세계 모델의 한 형태로 AI에서 가장 흥미로운 분야 중 하나로 부상하고 있으며, 이는 복잡한 장면의 시간적 변화를 통해 미래를 상상할 수 있는 능력을 에이전트에게 제공합니다. 자율주행에서는 이러한 비전이 주행 세계 모델이라는 개념을 탄생시켰습니다: 자신과 다른 에이전트의 미래를 상상하는 생성 시뮬레이터로, 이는 확장 가능한 시뮬레이션, 안전한 경계 사례 테스트 및 풍부한 합성 데이터 생성을 가능하게 합니다. 그럼에도 불구하고 빠르게 성장하고 있는 연구 활동에도 불구하고, 이 분야에는 진척을 측정하고 우선순위를 설정하는 엄격한 벤치마크가 부족합니다. 현재의 평가는 제약적입니다: 일반적인 비디오 메트릭은 안전에 중요한 이미징 요소를 무시하며; 트레젝토리 가능성은 거의 측정되지 않으며; 시간적 및 에이전트 수준의 일관성은 간과되며; 그리고 자아 조건화에 대한 통제 가능성은 고려되지 않습니다. 또한 현재 데이터셋은 실제 세계 배치를 위해 필요한 다양성을 충분히 커버하지 못하고 있습니다. 이러한 격차를 해결하기 위해 우리는 첫 번째로 생성 주행 세계 모델을 위한 종합적인 벤치마크인 DrivingGen을 제시합니다. DrivingGen은 다양한 평가 데이터셋과 새로운 메트릭 스위트를 결합하며, 이는 시각적 실재성, 트레젝토리 가능성, 시간적 일관성 및 통제 가능성을 공동으로 평가합니다. 14개의 최신 모델을 벤치마킹한 결과 명확한 절충점이 드러났습니다: 일반적인 모델은 더 잘 보이나 물리를 위반하고, 주행에 특화된 모델들은 움직임을 실제적으로 포착하지만 시각적 품질에서 뒤처집니다. DrivingGen은 신뢰할 수 있고 통제 가능하며 배포 가능한 주행 세계 모델을 육성하기 위한 통합 평가 프레임워크를 제공하여 확장 가능한 시뮬레이션, 계획 및 데이터 기반 의사결정을 가능하게 합니다.
💡 논문 해설
1. **다양한 운전 조건을 포괄하는 데이터셋** - 기존의 데이터셋은 주로 맑은 날씨와 도시 지역에 집중되어 있지만, 이 논문에서는 다양한 날씨 조건과 시간대, 전 세계 여러 지역에서 수집된 데이터를 사용하여 보다 실용적인 평가를 가능하게 합니다. 이를 통해 모델이 실제 운전 환경에서 얼마나 잘 작동하는지 평가할 수 있습니다.
운전에 특화된 평가 지표 - 이 논문에서는 운전 시나리오에 적합한 새로운 평가 지표를 도입합니다. 비디오와 트랙의 분포, 인간의 인식 품질을 고려한 품질 지표, 운동학적 타당성 등을 평가하는 다양한 지표들이 포함되어 있습니다.
다양한 모델에 대한 포괄적인 벤치마킹 - 14개의 생성 세계 모델을 평가하여 각 모델의 강점과 약점을 분석합니다. 이를 통해 미래 연구 방향을 제시하고, 실제 운전 시뮬레이션의 진보를 지원할 수 있습니다.
📄 논문 발췌 (ArXiv Source)
maketitle 감사합니다 aketitle
서론
확장 가능한 학습 기법에 의해 주도된 생성 비디오 모델은 다양한 장면과 동작에서 고해상도 비디오를 합성하는 데 있어 눈부신 진전을 이루었습니다. 이러한 모델들은 “월드 모델"로 향한 유망한 길을 제시하고 있습니다 - 예측 시뮬레이터로서 미래를 상상할 수 있으며, 복잡하고 역동적인 환경에서 계획, 시뮬레이션 및 의사결정을 지원합니다. 이 비전에 영감을 받아 운전 월드 모델 개발이 가속화되고 있습니다: 미래의 운전 시나리오를 예측하기 위한 특수화된 생성 모델입니다. 초기 장면과 선택적 조건(예: 텍스트 프롬프트, 운전 동작)을 제공하면 운전 월드 모델은 자동차의 미래 움직임뿐만 아니라 주변 에이전트의 궤도 진화를 예측합니다. 이러한 모델은 닫힌 루프 시뮬레이션과 합성 데이터 생성을 가능하게 하여 실제 세계 데이터에 대한 의존성을 줄이고, 분산 외부 시나리오를 안전하게 탐색할 수 있는 유망한 방법을 제공합니다. 운전 월드 모델은 또한 엔드투엔드 자율 주행 시스템과 밀접하게 연결되어 있으며, 예측된 미래 장면과 궤도의 오류는 직접적으로 안전하지 않은 결정으로 이어질 수 있습니다.
운전 월드 모델에 대한 다양한 접근 방식을 탐색하는 활발한 연구가 진행되고 있지만, 진척 상황을 측정하고 연구 우선순위를 지향하며 전체 분야의 궤도를 형성하는 잘 설계된 벤치마크는 아직 나타나지 않았습니다. 현재 평가는 운전 도메인의 고유한 요구 사항을 완전히 포착하지 못하며 여러 방면에서 제약이 있습니다. 1) 시각적 실현도 - 먼저 대부분의 벤치마크는 Fréchet 비디오 거리(FVD)와 같은 분포 수준 지표를 사용하여 비디오의 현실성을 평가하고, 일부는 인간 선호도에 맞춘 모델(예: 시각-언어 모델)을 사용하여 시각 품질이나 의미적 일관성을 점수화합니다. 그러나 운전에는 이미징에 대한 고유한 제약이 있으며 센서 오류, 반사광 또는 기타 손상은 일반적인 비디오 지표가 포착하지 못하는 중요한 안전 관련 영향을 미칠 수 있습니다. 2) 궤도 가능성 - 두 번째로 생성된 비디오의 기저 ego-움직임 궤도는 중요합니다. 운전에서 고화질 비디오 생성은 자연스럽고 동적 가능하며 상호작용에 대한 인식이 있으며 안전한 궤도를 생산해야 합니다. 3) 시공간 및 에이전트 수준 일관성 - 세 번째로, 주변 물체가 직접적으로 운전 안전과 의사결정을 영향 미치는 운전에서는 시공간적 일관성이 중요합니다. 이전 벤치마크들은 장면 수준의 일관성을 중점으로 하지만 에이전트 수준의 일관성은 간과하고 있습니다 - 예를 들어, 갑작스러운 출현 변화나 비정상적인 사라짐 등은 시뮬레이션의 현실성과 신뢰성을 심각하게 해칠 수 있는 결함입니다. 4) 움직임 제어 가능성 - 마지막으로, ego-조건화된 비디오 생성을 위한 조건 궤도를 충실히 따르는지 평가하는 것은 중요합니다. 이 제어 가능성이 현존하는 벤치마크에서 크게 무시되고 있지만 안전한 계획과 신뢰할 수 있는 닫힌 루프 운전에 필수적이며, 불일치는 재앙적인 결과를 초래할 수 있습니다.
운전 월드 모델의 현존 벤치마크에서 또 다른 주요 제약은 실제 배포에 필요한 중요한 차원들에 대한 다양성 부족입니다. 1) 첫 번째로, 날씨와 시간대 커버리지는 크게 왜곡되어 있으며 nuScenes과 같은 데이터셋은 맑은 날씨와 주간 운전으로 이루어져 있어 희귀하지만 안전이 중요한 조건(밤, 눈, 안개)을 부족하게 나타냅니다. 2) 두 번째로, 지리적 커버리지는 제한적이며 종종 몇 개의 도시나 국가에 국한되어 있어 다양한 장면 외관과 지역 교통 규칙 평가를 제약합니다. 3) 세 번째로, 운전 동작 및 상호 작용은 에이전트 행동의 전체 다양성과 복잡한 다중 에이전트 동역학을 포착하지 못하며 보행자 신호등에서 대기하거나 공격적인 운전자 차선 변경 또는 밀집된 교통 시나리오 등입니다. 이 다양성 부족은 생성 모델이 실제 운전에서 만나는 다양한 시나리오를 처리할 수 있는지 평가하는 것을 어렵게 하여 대규모 배포에 대한 신뢰성과 안전성을 저해합니다.
style="width:85.0%" />
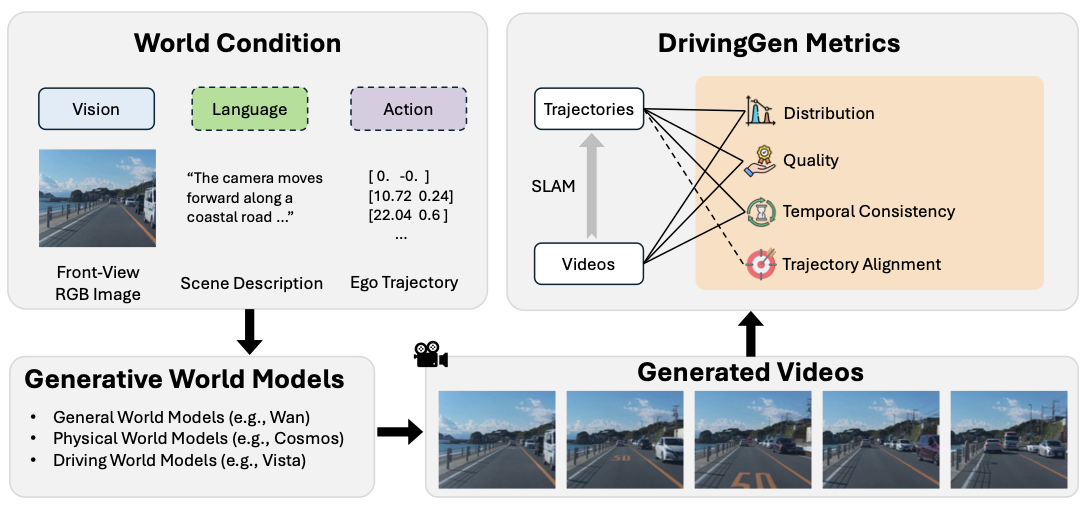
운전Gen 벤치마크 개요. 비디오 모델은 시각, 선택적 언어/동작을 입력으로 받아 비디오를 생성합니다. 생성된 비디오는 우리의 평가 스위트로 전달됩니다. 비디오와 궤도(분포, 품질, 시공간 일관성 및 궤도 정렬)에 대한 4개의 포괄적이고 새로운 측정 집합을 도입하여 월드 모델을 평가합니다.
위의 격차를 해결하기 위해 이 연구는 다양한 데이터 분포와 새로운 평가 지표를 포함하는 운전 도메인에서 생성 세계 모델을 위한 포괄적인 벤치마크인 DrivingGen을 제안합니다. DrivingGen은 시각적 관점(생성된 비디오의 실현도 및 전체 품질)과 로봇 공학적 관점(생성된 궤도의 물리적 가능성, 일관성 및 정확성)에서 모델을 평가합니다. 우리의 벤치마크는 다음과 같은 주요 기여를 제공합니다:
다양한 운전 데이터셋 - 다양한 운전 조건과 행동을 포착하는 새로운 평가 데이터셋을 제시합니다. 이전 데이터셋이 맑은 낮, 도시 장면에 편향되는 반면, 우리의 데이터셋에는 다양한 날씨(비, 눈, 안개, 홍수, 모래폭풍), 시간대(새벽, 낮, 밤), 전 세계 지역(북아메리카, 유럽, 아시아, 아프리카 등) 및 복잡한 시나리오(밀집된 교통, 갑작스러운 차선 변경, 보행자 횡단)가 포함되어 있습니다. 이러한 다양성은 실제 운전 분포에서 생성 모델을 더 견고하고 편향되지 않은 평가를 가능하게 합니다. 또한 비디오 생성에 대한 추론이 일반적으로 시간이 많이 소요되므로 우리는 샘플의 수를 400개로 제한하여 효율적인 테스트와 반복을 보장하며 효율성과 의미 있는 평가 사이에서 균형을 맞춥니다.
운전에 특화된 평가 지표 - 운전 시나리오를 위한 새로운 멀티페이스 지표 스위트를 도입합니다. 이에는 비디오와 궤도 출력에 대한 분포 수준 측정, 인간 인식 품질을 고려한 품질 지표, 운전 특화 이미징 요인(조명 깜빡임, 움직임 블러 등), 장면 수준과 개별 에이전트 수준의 시공간 일관성 검사(예: 비디오 내 출현 불일치 또는 자연스럽지 않은 사라짐) 및 궤도 실현도 지표가 포함되어 있습니다. 이 지표들은 운동학적 타당성과 주어진 경로에 대한 정확한 추종(예: 부드러움, 물리적 가능성 및 주어진 루트를 따르는 정확성)을 평가합니다. 이러한 지표들 함께 4차원의 분포 실현도, 시각 품질, 시공간 일관성 및 제어/궤도 신뢰성에 대한 포괄적인 평가를 제공하며 일반적인 지표나 단일 숫자 점수는 포착하지 못하는 측면을 커버합니다.
포괄적 벤치마킹 및 인사이트 - 우리는 14개의 생성 세계 모델을 세 가지 범주 – 일반 비디오 월드 모델, 물리 기반 월드 모델, 운전 특화 월드 모델 –로 DrivingGen에 대한 평가를 수행합니다. 이 평가는 운전 도메인에서 처음으로 중요한 인사이트와 미해결 과제를 드러냅니다. 예를 들어 우리는 특정 일반 세계 모델이 시각적으로 매력적인 교통 장면을 생성하지만 차량 움직임에 물리적 일관성이 부족하다는 것을 발견하고, 일부 운전 특화 모델은 궤도 정확성을 뛰어나게 하지만 이미지 품질에서는 뒤처진다는 것을 확인합니다. 우리의 지표를 통해 성능을 분석함으로써 각 접근법의 강점과 실패 모드를 드러내며 미래 연구에 대한 통찰력을 제공합니다. DrivingGen의 모든 구성 요소 – 데이터셋 및 평가 코드 –는 재현 가능한 연구와 실제 운전 시뮬레이션의 진보를 지원하기 위해 공개됩니다.
style="width:99.0%" />
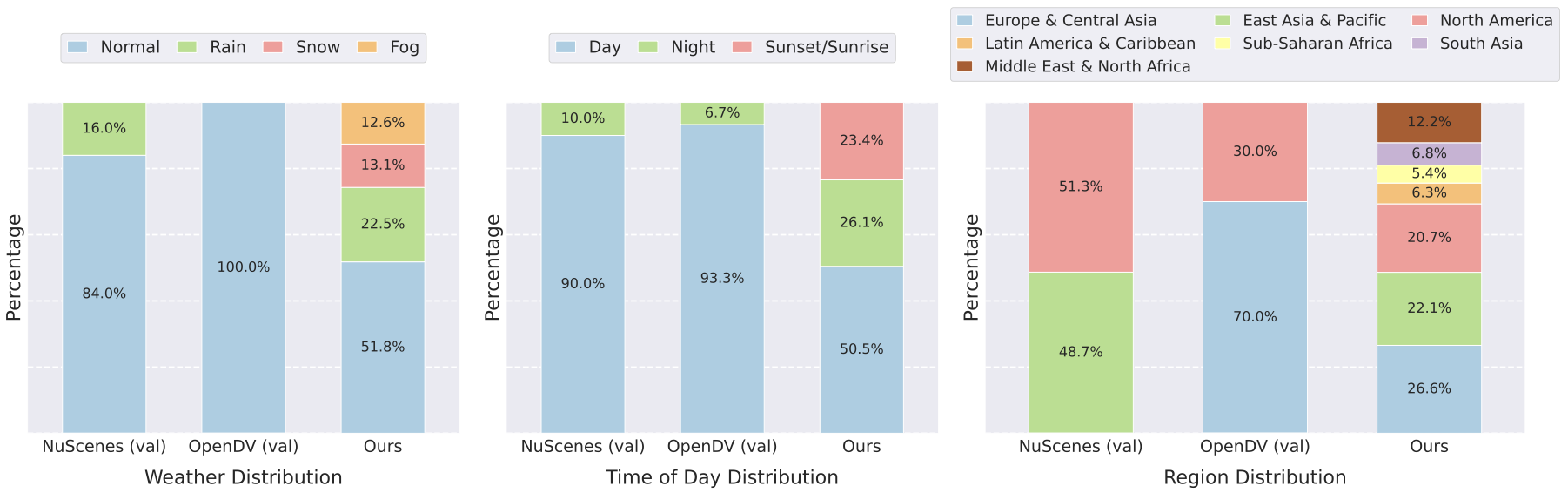
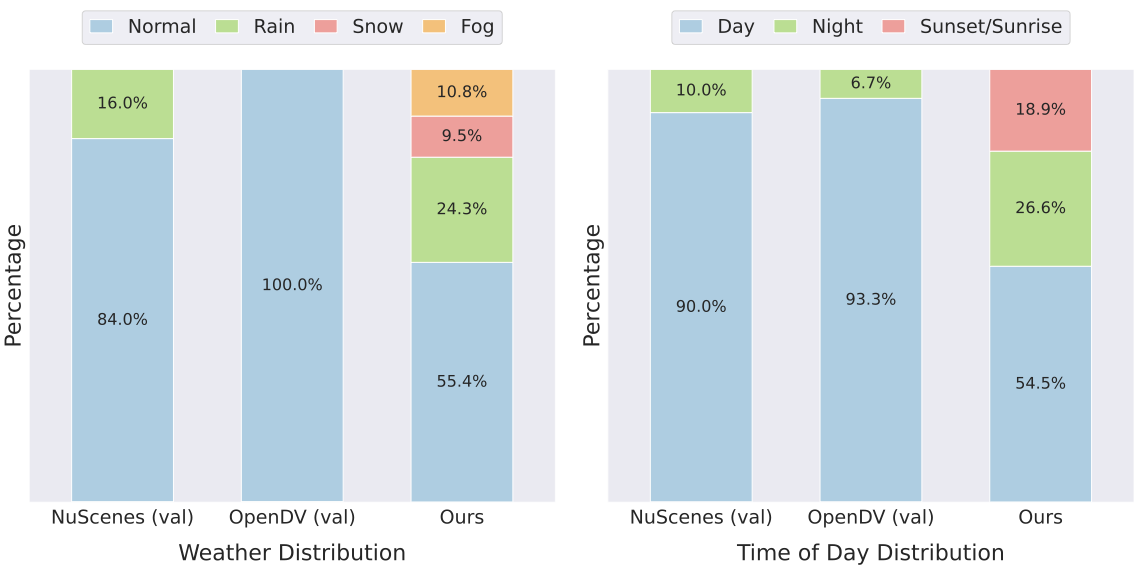
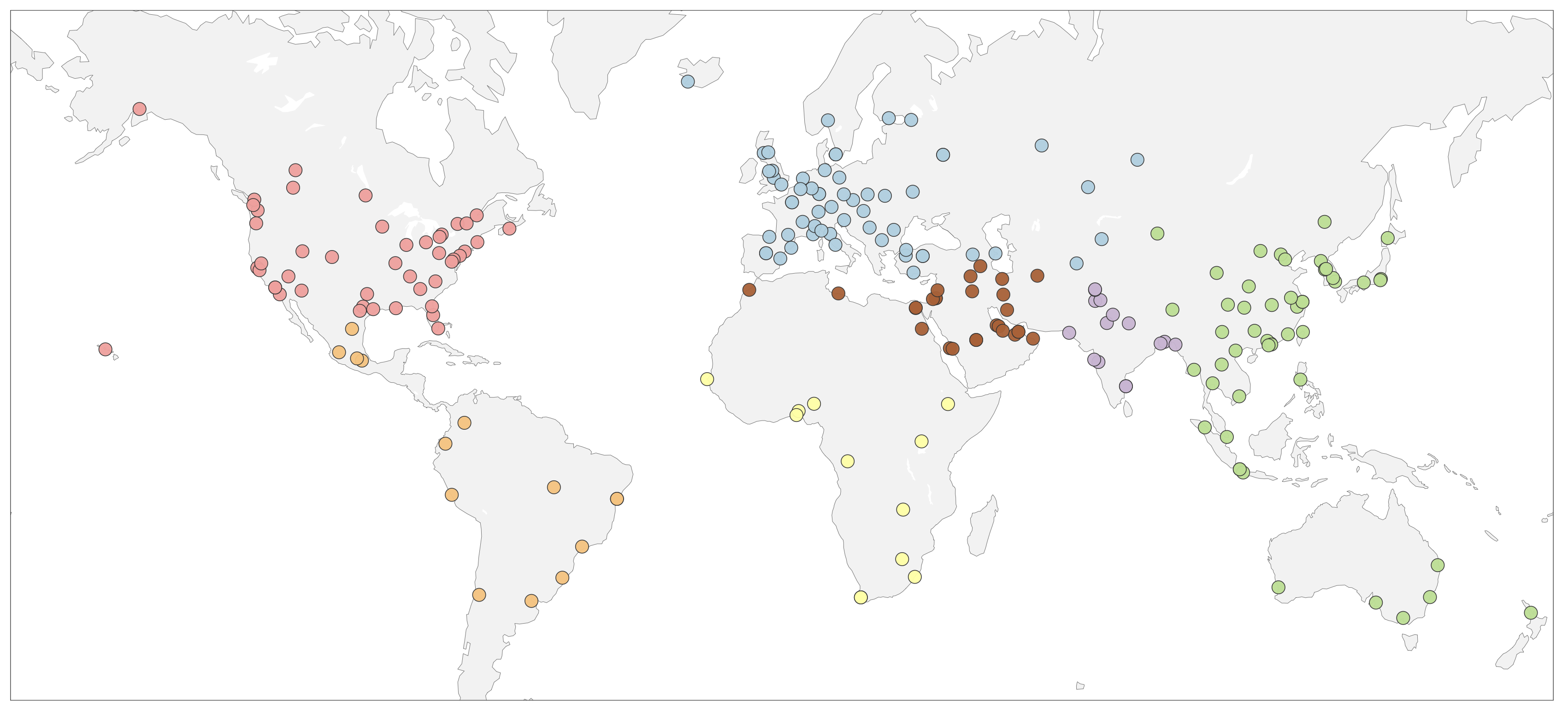
기존 데이터셋과 ours의 날씨, 시간대 및 지역 분포. style="width:95.0%" />
우리 데이터셋 내 각 지역의 특정 운전 위치들입니다. style="width:95.0%" />
우리 벤치마크의 대표적인 예시들로 밀집된 도심 교통, 이례적인 날씨(예: 안개, 홍수, 모래폭풍), 복잡한 상호 작용(예: 보행자 기다리기, 에이전트가 들어가는 것) 등 다양한 시나리오를 포괄합니다.우리 벤치마크의 데이터셋 분포와 갤러리 (위에서 아래로).
관련 연구
본 연구에서는 자율주행에 적용된 생성 월드 모델과 이러한 모델을 평가하기 위한 벤치마크라는 두 가지 주요 연구 영역에 초점을 맞추었습니다. 공간 제약으로 인해 일반 비디오 생성 및 특정 운전 월드 평가의 최근 진전사항에 대한 포괄적인 리뷰는 부록 7에서 제공합니다.
DrivingGen 벤치마크
DrivingGen의 목표는 운전 특화된 제약과 기준 하에서 생성 세계 모델을 평가하기 위한 포괄적인 벤치마크를 구축하는 것입니다. 이를 달성하기 위해 제안된 벤치마크에는 다음과 같은 주요 구성 요소가 포함됩니다: 1) 날씨, 시간대, 지역(및 그들의 운전 스타일), 그리고 운전 동작이 다양한 데이터셋을 신중하게 수집하여 합리적인 평가를 지원; 2) 비디오 품질을 일반 시각적 관점에서만 평가하는 다면적 지표(예: 외관)뿐만 아니라 운전과 로봇 공학적 관점에서도 평가합니다. (예: 궤도의 물리적 타당성). DrivingGen의 구별 능력을 보여주기 위해 일반 세계 모델, 물리 기반 모델, 그리고 운전 특화 모델을 평가합니다. 개요는 그림 1에 있으며, 데이터셋 세부 사항은 섹션 3.1, 지표는 섹션 3.2에서 제공됩니다.
벤치마크 데이터셋
생성 비디오 모델은 세계 모델의 한 형태로 미래 운전 시나리오를 예측하고 드물거나 안전에 중요한 이벤트를 시뮬레이션하며 궁극적으로 계획과 의사결정을 지원하는 유망한 방법을 제공합니다. 그러나 실제 운전은 매우 다양한 조건 하에서 진행되며, 다양한 날씨, 조명, 지역 및 복잡한 동작을 포함합니다. 따라서 다양한 시나리오에 걸친 생성 모델의 평가를 수행하여 그들의 견고성과 신뢰성을 확보하는 것이 중요합니다. 이를 위해 대부분의 현존 연구들은 운전 월드 모델에서 주로 nuScenes 및 OpenDV 데이터셋을 사용하여 평가합니다. 그러나 이러한 데이터셋은 날씨, 지역, 시간대, 운전 동작의 다양성이 제한적이고 데이타 분포를 크게 편향시킵니다. 예를 들어, 그림 2에 보여진 것처럼 nuScenes 검증 데이터의 80% 이상과 OpenDV 검증 데이터의 90%는 정상적인 맑은 낮 조건에서 수집되었습니다. 또한 데이터는 제한된 수의 차량 및 위치에서 수집되어 포괄성을 더 한층 제약합니다. 이러한 관찰에 기반하여 우리는 매우 다양한 데이터셋을 구성했습니다. 그림 2와 그림 3에 우리의 데이터셋 개요가 제시되어 있습니다.
데이터셋 구성. 우리는 두 가지 보완적인 트랙으로 데이터셋을 조직하여 운전 비디오 평가의 다양한 관점을 제공합니다.
오픈 도메인 트랙은 모델이 다양한 미경험된 운전 시나리오에 대해 일반화하는 능력을 평가하기 위해 설계되었습니다. 이 트랙은 전 세계 여러 도시와 지역에서 수집한 인터넷 출처의 데이터를 사용하여 구축되어 훈련 분포를 벗어난 광범위한 커버리지를 보장합니다.
Ego-조건화 트랙은 오픈 도메인 트랙을 보완합니다. 오픈 도메인 설정은 다양한 미경험된 시나리오에 대한 일반화를 평가하지만, 생성된 궤도가 지정된 조건 궤도를 따르는지 확인하지 않습니다 - 이 속성은 로봇공학 및 자율 주행 응용 프로그램에 매우 중요합니다. 따라서 ego-조건화 트랙은 궤도 제어 가능성에 초점을 맞추며, 생성 비디오에서 파생된 궤도가 제공된 ego-궤도 지시사항과 얼마나 잘 일치하는지 측정합니다. 이 트랙에서는 모델 입력으로 선택적으로 ego 궤도를 제공하며 이를 구성하기 위해 Zod (유럽), DrivingDojo (중국), COVLA (일본), nuPlan (미국), WOMD (미국)의 5개 오픈 소스 운전 데이터셋에서 데이터를 통합합니다.
데이터셋 내 각 샘플은 세 가지 구성 요소로 이루어져 있습니다: 정면 RGB 이미지(시각), 장면 설명(언어), 선택적 ego 궤도(동작). 각 장면에 대해 우리는 Qwen을 사용하여 장면 내에서의 미래 동태와 카메라 이동에 대한 설명을 포착합니다. 비디오 생성이 시간이 많이 소요되기 때문에 효율적인 테스트 및 반복을 위해 샘플 수를 제한하며, 동시에 품질과 다양성을 보장합니다. 데이터셋에는 400개의 샘플 - 각 트랙당 200개 -가 포함되어 있으며 효율성과 의미 있는 평가 사이에서 균형을 맞추고 있습니다.
균형 잡힌 데이터 분포 데이터셋의 전체적인 분포와 대표적인 비디오 예시 갤러리는 그림 4에 제시되어 있습니다. 의미 있는 평가를 위해 다양한 차원에서 다양성을 명확하게 제어합니다:
날씨와 시간대. 기존 벤치마크는 정상적인 날씨와 주간 조건으로 구성되거나 거의 그렇게 구성됩니다. 반면, 우리의 벤치마크는 더 균형 잡힌 분포를 목표로 합니다. 오픈 도메인 트랙에서는 정상적인 날씨와 주간 클립을 60% 미만으로 제한하고 눈(13.1%), 안개(12.6%) 및 밤/일몰/일출 운전(50%) 등 다른 조건의 비율을 증가시켜 더 포괄적인 평가를 보장합니다. 모래폭풍, 홍수, 밤에 푸른 눈과 같은 극단적 사건도 포함됩니다. Ego-조건화 트랙에도 유사한 전략이 적용되며 정상 날씨/주간 클립은 데이터의 60%를 차지하고 나머지는 다양한 조건을 포괄하여 다양한 시나리오에서 궤도 제어 가능성 평가를 지원합니다.
지리적 커버리지. 이전 벤치마크는 종종 몇 개의 도시 또는 국가에 국한되어 있어 운전 시나리오 다양성을 제약합니다. 오픈 도메인 트랙에서는 전 세계 여러 지역에서 데이터를 수집하여 북아메리카(20.7%), 동아시아 및 태평양(22.1%), 유럽 및 중앙 아시아(26.6%), 중동 및 북아프리카(12.1%), 라틴 아메