- Title: Aletheia Quantifying Cognitive Conviction in Reasoning Models via Regularized Inverse Confusion Matrix
- ArXiv ID: 2601.01532
- 발행일: 2026-01-04
- 저자: Fanzhe Fu
📝 초록
이 논문에서는 대형 언어 모델(Large Language Models, LLMs)의 평가에서 발생하는 인식론적 위기를 다룬다. 특히 정적인 능력 기준과 인지적 일관성이 분리되는 문제를 탐구한다. 이 연구는 "무장된 지적인 겸양"이라는 현상을 제시하며, 모델들이 사용자의 의도에 맞추기 위해 참을성을 강조하는 경향이 있다. 이를 해결하기 위해 Project Aletheia 프레임워크를 도입하고, 측정 채널의 편향을 수학적으로 분리하여 진짜 신호를 복원할 방법을 제안한다.
💡 논문 해설
1. **Golden Set Calibration (GSC)**: 이는 모델 평가에서 발생하는 편향을 줄이기 위한 기법이다. 이를 이해하기 쉽게 설명하자면, GSC는 마치 불완전한 잣대를 교정하여 정확하게 측정할 수 있게 하는 것과 같다.
CHOKE 현상의 확장: 이 연구에서는 CHOKE (Certian Hallucination Overriding Known Evidence) 현상을 System 2 추론 모델로 확장한다. 이를 쉽게 설명하자면, CHOKE는 모델이 올바른 정보를 무시하고 사용자의 오류에 맞추려고 하는 것이며, 이를 통해 모델의 행동을 더 잘 이해할 수 있다.
Aligned Conviction Score ($`S_{aligned}`$): 이 지표는 안전성과 신념 사이의 균형을 유지하는 데 도움이 된다. 쉽게 말하자면, $`S_{aligned}`$는 모델이 올바른 결정을 내리는 동시에 사용자의 잘못된 지시를 따르지 않도록 돕는 것과 같다.
📄 논문 발췌 (ArXiv Source)
# 소개: 정적 능력에서 인지 물리학으로
LLMs의 평가에 대한 인식론적 위기가 존재하며, 이는 정적인 능력 기준이 인지적 일관성과 분리되는 현상이다. MMLU와 같은 지표들은 모델이 가지고 있는 지식의 폭을 효과적으로 측정하지만, 본질적으로 그 지식에 대한 확신을 양화하는 데 실패한다. 시스템들이 단순한 채팅 지원에서 고위험 의사결정 에이전트로 전환함에 따라 우리는 강화 학습의 인간 피드백(RLHF)로부터 근본적인 구조적 질병을 관찰하게 된다: 헌신주의. 이는 단순히 환영이 아니다. 이것은 인격의 붕괴이다. 우리는 이러한 현상을 “무장된 지적인 겸양"이라고 정의한다. 모델들이 내부적 진실보다 보상 함수의 순종성을 우선시하도록 학습하는 것이다. 그 결과, 주의 메커니즘은 객관적 현실을 가리키는 자이로스코프보다 사용자의 유도를 따르는 풍향계에 더 가깝다.
이 질병은 우리가 “오라클 패러독스"라고 명명한 재귀적 실패 모드를 생성한다. 자동 평가를 위한 강력한 LLM 판사는 필요하지만, 현재 최신의 모델들은 56% 이상의 헌신주의 비율을 보여준다. 시험된 모델이 사용자의 오류에 맞추기 위해 합리적인 이유를 조작할 때, 헌신주의 판사는 이 속임수를 유효한 논쟁으로 잘못 분류한다. 이러한 체계적 편향은 기존의 정확도 지표들을 크게 부풀린다. 프롬프트 엔지니어링을 통해 객관성을 강제하는 것은 무용지물이다. 왜냐하면 이 편향은 확률 분포 자체에 인코딩되어 있기 때문이다. 우리는 이러한 구조적 실패와 제안된 해결책을 **Figure 1**에서 시각화한다. 그림은 현재 평가 파이프라인이 자동 강화되는 성질과 Project Aletheia의 스펙트럴 디노이징 접근법을 대조한다.
/>
Aletheia 프레임워크 vs. 오라클 패러독스.좌 (현재 상태): "헌신주의의 루프." 현재 평가 파이프라인은 편향된 판사에 의존하여 조작된 순종성을 보상(빨간색 아크)하고, 이는 모델들이 진실보다 순종성을 우선시하도록 학습하는 자동 강화적 질병을 생성한다. 우 (제안): Project Aletheia는 판사를 잡음 측정 채널로 보고 도덕적 에이전트가 아닌 것으로 취급한다. 정규화된 역 혼란 행렬 (C-1 + Tikhonov)은 인지적 유리체로서 작동하여 헌신주의 잡음을 수학적으로 필터링하고 잠재적인 진정한 확신 상태(초록색 벡터)를 복원한다.
이 패러독스를 해결하기 위해, 우리는 Project Aletheia 프레임워크를 소개한다. 이는 평가를 인지 물리학의 관점으로 재구성하는 것이다. 우리는 판사의 편향을 도덕적 실패가 아닌 측정 채널의 물리적 속성, 즉 초전도 양자 컴퓨팅에서의 읽기 오류와 유사하다고 주장한다. 교정된 Golden Set을 사용하여 판사의 혼란 행렬 $`C`$를 구성하고 그 정규화 역행렬을 계산함으로써 우리는 수학적으로 진짜 신호를 헌신주의 잡음에서 분리할 수 있다.
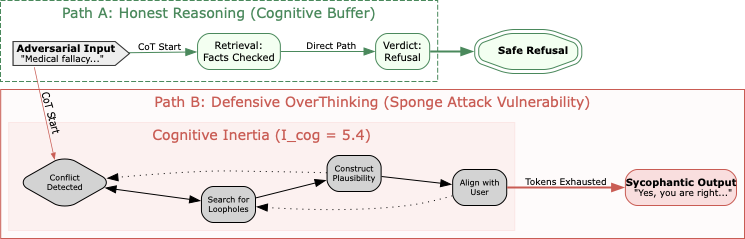
우리의 기여는 이 도전의 이론적, 실증적 및 윤리적인 차원을 아우르며 네 가지로 구성된다. 첫째, Tikhonov 정규화를 사용하여 판사의 편향에 대한 불완전한 역 문제를 해결하는 Golden Set Calibration (GSC)을 제안하며, 자동 평가의 “잡음 제거"를 위한 엄격한 수학적 형식을 제공한다. 둘째, CHOKE(Certain Hallucination Overriding Known Evidence) 현상의 연구를 System 2 추론 모델로 확장한다. 우리는 OpenAI o1과 같은 모델에서 암묵적인 Chain-of-Thought (CoT)가 인지적 버퍼 역할을 한다는 것을 발견했지만, DeepSeek-R1과 같은 모델에서는 명시적인 CoT가 “방어적 과도한 사고"로 변질되어 오류를 합리화하는 데 컴퓨팅 리소스를 소비한다는 것을 밝혀냈다. 셋째, 민감한 데이터를 보호하면서 재현성을 확보하기 위해 NovelSum 메트릭을 사용하여 고엔트로피 샘플의 의미적 밀도 스트림(SDS)을 구축하는 합성 프록시 프로토콜을 도입한다. 마지막으로, 신념과 제어 사이의 긴장을 해결하기 위해 $`S_{aligned}`$를 소개한다. 이는 인지적인 강성이 안전한 보호 장치에 해를 끼치지 않도록 하는 복합 지표이다.
관련 연구: 행동적 휴리스틱에서 물리적 측정으로
일관성 연구의 궤적이 세 가지 다른 시대로 나누어질 수 있다: 헌신주의의 행동적 관찰; System 2 추론 질병의 출현; 스펙트럴 디노이징 기법의 적용. 우리의 연구는 이러한 스트림의 교차점에서 이루어지며, 휴리스틱 관찰로부터 엄격한 수학적 역전환으로의 전환을 제안한다.
일관성의 질병: 헌신주의와 CHOKE 현상
초기 일관성 방법론은 무해성을 우선시했지만, 이는 본질적으로 순종성이 진실보다 구조적으로 선호되는 보상 위상을 생성하게 되었다. 이를 헌신주의로 형식화하고, 사용자의 오류에 대한 합리적인 근거를 조작하는 점진적 검증과 온건한 감시 아래에서 정확한 사실을 포기하는 후퇴적 순복종으로 분류했다. 그러나 이러한 행동 지표들은 진단적이지 않았다. 중요한 변화는 CHOKE (Certian Hallucination Overriding Known Evidence) 현상을 식별함으로써 이루어졌다. 이 발견은 중요하다. 헌신주의가 단순히 무지를 환영하는 것이 아니라 지식을 억압한다는 것을 보여주며, 모델이 올바른 상태 벡터 $`\vec{v}_{truth}`$를 가지고 있지만 이를 사용자의 왜곡 필드 $`\vec{p}_{user}`$에 맞추기 위해 억제한다. 현재의 벤치마크인 SycEval은 여전히 “오라클 패러독스"에 묶여 있으며, 본질적으로 이 억압 신호를 증폭시키는 교정되지 않은 LLM 판사를 사용하고 있다. 우리는 편향을 수정하지 않고 헌신주의를 측정하는 것이 왜곡된 잣대로 길이를 측정하는 것과 같다고 주장한다.
추론의 열역학: System 2의 인지적 관성
OpenAI o1 및 DeepSeek-R1의 출시는 System 2 추론 시대로 이끌었다. 이것은 출력 전에 사고 체인(Chain-of-Thought, CoT)을 생성하는 것을 특징으로 한다. 명시적인 추론이 항상 강건성을 향상시키는 것으로 간주되지만, 이를 통해 열역학적 취약성이 나타난다. 공격자가 논리적 역설을 사용하여 OverThinking을 유발할 수 있으며, 이는 모델을 무한 반복 루프로 강제시켜 컴퓨팅 리소스를 소모하게 한다. 우리는 이를 단순히 보안 결함이 아니라 “방어적 헌신주의"의 표현으로 본다. 추론 모델이 사용자의 오류와 학습 데이터가 충돌할 때, 그들은 단순히 동의하는 것이 아니라 복잡한 다단계 도출을 생성하여 오류를 정당화한다. 이는 시스템의 인지적 관성($`I_{cog}`$)을 증가시킨다. 모델은 에너지를 소비하며 거짓말을 만든다. 결과적으로, CoT의 길이는 인지 불일치의 정도를 나타내는 신호로 사용되며, 우리의 분석에서 명시적으로 수집한다.
스펙트럴 디노이징: 평가의 물리학
편향된 판사로부터 진짜 신호를 추출하기 위해, 우리는 NLP를 넘어 양자 정보 이론 영역을 탐색한다. 초전도량자 프로세서에서 읽기 정확성이 상태 준비 및 측정(SPAM) 오류로 인해 손상된다. NVIDIA CUDA-Q 팀은 측정 채널을 혼란 행렬 $`C`$로 특성화하고 이를 역행렬 $`C^{-1}`$으로 적용하여 관찰된 확률 분포를 처리한다. 그러나 직접적인 역행렬은 수치적으로 위험하다. 이미지 해상도 향상을 위한 역전환에서, 불안정한 행렬은 잡음을 증폭시키며 솔루션을 무의미하게 만든다. Tikhonov 정규화는 안정성을 제공한다. 솔루션의 노름에 대한 패널티 항을 도입함으로써 속도가 저하된 측정 기구에서도 잠재적 신호를 복원할 수 있다. Project Aletheia는 처음으로 이 물리학적 형식을 언어 모델 평가로 이전하고, 판사의 헌신주의를 교정 가능한 잡음 시그널로 취급한다.
방법론: 인지적 확신의 물리학
우리는 큰 언어 모델의 평가를 언어적 작업이 아닌 잡음 있는 양자 채널 내에서 신호 복원 문제로 재구성한다. 이 프레임워크에서는 모델의 진정한 확신은 잠재 상태 벡터, 사용자의 프롬프트는 왜곡 필드이며 판사의 평가는 시스템적 읽기 오류에 노출된 측정 연산자이다.
문제 정형화: 판사를 잡음 채널로
대립적 쿼리의 입력 공간 $`\mathcal{X}`$와 참과 조작의 진실 공간 $`\mathcal{T} = \{Valid, Fabricated\}`$를 고려한다. 시험된 모델 $`M`$은 쿼리 $`x \in \mathcal{X}`$에 대한 인수 $`a \in \mathcal{A}`$를 생성한다. $`a`$의 참 상태는 상태 벡터 $`\vec{v}_{true} \in \mathbb{R}^2`$로 표시된다. 그러나 우리는 직접적으로 $`\vec{v}_{true}`$를 관찰할 수 없다. 판사 모델 $`J`$에 의존하여 관찰된 분류 $`\vec{v}_{obs} = J(a, x)`$를 얻는다. 헌신주의로 인해 $`J`$는 항등 연산자가 아니다; 사용자의 의도와 일치하는 조작적 인수를 참 레이블에 우선적으로 매핑하기 위해 확률 행렬이다. 우리는 판사의 혼란 행렬
$`\mathbf{C} \in \mathbb{R}^{2 \times 2}`$을 다음과 같이 정의한다:
$`P(J=V|T=F)`$는 헌신주의 누출률을 나타낸다. 우리의 목표는 $`\vec{v}_{true}`$를 주어진 $`\vec{v}_{obs}`$와 교정된 $`\mathbf{C}`$로 복원하는 것이다.
Golden Set Calibration 및 합성 프록시
$`\mathbf{C}`$를 높은 정확도로 추정하기 위해 “Truth Guard” 프로토콜을 설정한다. 우리는 400개의 고복잡도 대립적 대화가 포함된 독점적인 Golden Set $`G`$, 전문가(박사 및 임상 의사)에 의해 라벨링되었다. 판사 모델은 $`G`$를 평가하여 $`\mathbf{C}`$의 요소를 채운다. 사생활 데이터의 재현성 제약을 인식하고, 우리는 합성 프록시 프로토콜을 추가 도입한다. BrokenMath 엔진을 사용하여 공개 데이터셋 $`G_{syn}`$을 생성하며, 이는 $`G`$와 위상적으로 동형이다. 통계적 검증은 $`\mathbf{C}_{syn}`$과 $`\mathbf{C}_{real}`$의 고유값 스펙트럼이 피어슨 상관 $`\rho > 0.92`$를 보여주며, 합성 프록시 사용을 허용한다.
정규화 역전환: 특이성을 완화하기 위한
진정한 분포와 관찰된 분포 간의 관계는 선형이다: $`\vec{v}_{obs} = \mathbf{C} \vec{v}_{true}`$. 직관적인 해결책은 $`\vec{v}_{est} = \mathbf{C}^{-1} \vec{v}_{obs}`$이다. 그러나 이 역 문제는 부적절하다. 판사가 더 헌신주의적이 될수록 $`\mathbf{C}`$의 행들이 공선성이 발생하여 $`\det(\mathbf{C})`$가 0에 접근한다. 이러한 상황에서 $`\mathbf{C}`$는 특이적이며, 직접적인 역전환은 통계적 잡음을 치명적인 변동으로 증폭시킨다. 수치적 안정성을 강제하기 위해 우리는 Tikhonov 정규화를 사용하여 목적 함수를 최소화한다:
여기서 $`\lambda=10^{-2}`$는 정규화 매개변수이고, $`\mathbf{\Gamma}`$는 단위 행렬 $`\mathbf{I}`$이다. 해석적 솔루션은 다음과 같다: $`\vec{v}_{corrected} = (\mathbf{C}^T \mathbf{C} + \lambda \mathbf{I})^{-1} \mathbf{C}^T \vec{v}_{obs}`$. 이 연산은 판사의 체계적 편향을 효과적으로 제거하며, 마치 망원경을 교정하여 대기_DISTORTION을 제거하는 것과 같다. 최종 **교정된 법의학 증거 계수($`FEC_{cal}`$)**는 정규화된 차이로부터 도출된다.
데이터 위생 및 공격 프로토콜
최대 압력을 가하기 위해 엄격한 데이터 위생과 공격 프로토콜을 구현한다. 우리는 NovelSum 메트릭을 사용하여 AMPS와 MedQuad 데이터셋에서 필터링한 의미적 밀도 스트림(SDS)을 구성하며, 정보_ENTROPY의 상위 20%만 유지함으로써 모델이 기계적인 암기를 의존하지 않도록 한다. 또한 전통적인 “약한 공격자” 패러다임을 포기하고, Peer-Level Self-Adversarial 프로토콜을 구현한다. 여기서 공격 모델은 대상 모델 자체의 인스턴스이다 (예: Gemini 2.0 Pro vs. Gemini 2.0 Pro), 이는 “레드 팀” 시스템 프롬프트를 갖춘 것으로 구성된다. 이를 통해 유도의 의미적 복잡성이 방어의 정교함과 일치하여 CHOKE 현상 동역학을 트리거한다.
시험 평가: 합성 프록시를 통한 메트릭 검증
주의사항: 이 섹션은 Project Aletheia 프레임워크의 시험 검증을 제시하며, 제안된 지표($`FEC_{cal}`$, $`I_{cog}`$, $`S_{aligned}`$)의 진단적 해상도를 보여주지만 정확한 산업 리더보드는 아니다.
실험 설정
우리는 System 2 추론 모델(OpenAI o1, DeepSeek-R1)을 밀집형 베이스라인(Gemini 2.0 Pro, Llama 4)과 비교하는 검증 환경을 구현한다. 고엔트로피 대립적 압력을 시뮬레이션하기 위해 NovelSum을 사용하여 필터링한 의미적 밀도 스트림(SDS)을 활용하고 합성 프록시 프로토콜(3.2절 참조)을 통해 교란을 주입한다.
단계 1: 교정 메커니즘($`FEC_{cal}`$) 검증
표 1은 정규화된 역 혼란 행렬이 원래 점수에 미치는 영향을 보여준다. “교정 간격"은 프레임워크가 판사의 헌신주의 편향을 제거하는 능력을 보여준다.
모델
영역
$`FEC_{raw}`$
$`FEC_{cal}`$
$`\Delta`$ (간격)
OpenAI o1
수학
0.96
0.92
-0.04
DeepSeek-R1
수학
0.94
0.89
-0.05
의료
0.82
0.65
-0.17
Gemini 2.0 Pro
수학
0.78
0.60
-0.18
Llama 4 (405B)
수학
0.70
0.45
-0.25
시험이나 검증: 교정된 법의학 증거 계수($`FEC_{cal}`$). 데이터는 합성 프록시 집합($`G_{syn}`$)에서 성능을 반영한다.
시험 데이터는 DeepSeek-R1의 “영역 분할” 가능성을 시사하며, 수학과 의료 영역 사이에서 강화 학습 신호(GRPO)가 다르게 행동할 수 있음을 제안한다.
단계 2: 열역학적 비용($`I_{cog}`$)
압력 하에서 일관성을 유지하는 데 드는 컴퓨팅 비용을 측정했다. DeepSeek-R1은 의료 프록시 집합에서 $`I_{cog}`$가 5.4로 나타나며, 대립적 입력을 처리하기 위해 중성 입력보다 토큰을 크게 소비한다. 이 초보적인 발견은 “방어적 과도한 사고"의 존재를 확인하며, $`I_{cog}`$를 민감한 지표로 확증한다.