- Title: MM-Sonate Multimodal Controllable Audio-Video Generation with Zero-Shot Voice Cloning
- ArXiv ID: 2601.01568
- 발행일: 2026-01-04
- 저자: Chunyu Qiang, Jun Wang, Xiaopeng Wang, Kang Yin, Yuxin Guo
📝 초록
이 논문에서는 MM-Sonate라는 다중 모달 조절 가능 프레임워크를 제안합니다. 이 프레임워크는 음성-비디오 동시 생성과 제로샷 음색 클론 기능을 지원하며, Multi-Modal Diffusion Transformer (MM-DiT) 아키텍처와 플로우 매칭 기법을 기반으로 합니다. MM-Sonate는 텍스트 설명만을 사용하는 이전 접근 방식 대신 통합된 명령-음절 입력 형식을 도입하여 시각적 장면 생성과 정확한 입 모양 동기화를 위한 음성 정보를 활용할 수 있습니다. 또한, 새로운 추론 전략인 자연스럽게 수집된 노이즈를 사용하는 부정 조건부 방법을 제안하여 음성의 안정성을 크게 향상시킵니다.
💡 논문 해설
1. **MM-Sonate 프레임워크**: MM-Sonate는 음성과 비디오를 동시에 생성하고, 참조 음성 클립을 사용해 새로운 음성을 만들 수 있는 능력을 가지고 있습니다. 이는 마치 악보와 오케스트라가 합쳐져 하나의 멋진 공연을 만드는 것처럼, 텍스트와 이미지, 그리고 음성이 함께 어우러져 완전한 경험을 제공합니다.
제로샷 음성 클론: MM-Sonate는 참조 음성을 사용해 새로운 발화자의 음성을 만들 수 있습니다. 이것은 마치 디자이너가 특정 사람의 스타일을 보고 그대로 재현하는 것과 같으며, 다양한 발화자를 제어할 수 있는 유연성을 제공합니다.
부정 조건부 전략: MM-Sonate는 자연스럽게 수집된 노이즈를 사용해 음성의 안정성을 향상시킵니다. 이는 마치 악기 튜닝을 위해 배경 소음을 활용하는 것과 같으며, 더 나은 음질과 발화자 일관성을 제공합니다.
📄 논문 발췌 (ArXiv Source)
maketitle 감사합니다 aketitle
style=“width:100.0%” />
서론
생성 세계 시뮬레이션의 궁극적인 목표는 물리적 현실의 다감각성을 복제하는 것이며, 이를 위해 시각과 음향 신호를 동기적으로 합성해야 합니다. 최근 텍스트-비디오 확산 모델은 놀라운 시각적 정확도를 달성했지만, 고급 음향 및 동기화된 오디오의 통합은 여전히 큰 과제입니다. 초기 접근 방식에서는 일반적으로 오디오 생성을 후처리 단계로 처리하여, 이미 생성된 비디오 프레임에 기반한 오디오 모델이 사용되었습니다. 그러나 이러한 분리된 패러다임은 미세한 시각적 정합성에 어려움을 겪으며, 종종 비디오와 오디오 스트림 사이의 큰 동기화 차이를 초래합니다.
정합 문제를 해결하기 위해 연구는 오디오와 비디오를 단일 모델 내에서 생성하는 통합 아키텍처로 이동하고 있습니다. MM-Diffusion과 JavisDiT 등 선두주자들은 공동 모델링을 탐구하였고, Ovi와 같은 최신 모델은 대칭적인 두 개의 백본 설계를 통해 인상적인 동기화를 달성했습니다. 그러나 이러한 발전에도 불구하고 중요한 한계가 남아 있습니다: 현재 통합된 모델들은 특히 음성 생성에서 오디오 모달에 대한 미세한 제어 능력을 갖추지 못하고 있습니다. 예를 들어, Ovi는 의미적으로 관련된 소리를 생성할 수 있지만 특정 발화자의 정체성(타임브레)을 조절하거나 참조 클립으로부터 음성을 복제하는 것은 불가능합니다. 따라서 현재 통합 비디오 생성기는 고급, 개인화된 음성 합성 기능을 아직 수행할 수 없으며, 일관된 캐릭터 정체성이나 더빙이 요구되는 시나리오에서 제한됩니다.
본 논문에서는 MM-Sonate를 제안합니다. 이는 제로샷 음성 복제 기능을 갖춘 다중 모달 조절 가능한 프레임워크입니다. Multi-Modal Diffusion Transformer (MM-DiT) 아키텍처와 플로우 매칭 기법을 기반으로 MM-Sonate는 오디오와 비디오를 공유된 잠재 공간 내에서 결합된 스트림으로 처리합니다. 이전 접근 방식이 오디오 제어에 텍스트 설명만 사용하는 것과 달리, 통합된 명령-음절 입력 형식을 도입하여 모델은 장면 생성을 위한 의미 이해와 입 모양 동기화를 위한 음성 정보를 활용할 수 있습니다. 특히 제로샷 음성 복제를 가능하게 하기 위해 발화자 정체성을 언어적 내용에서 분리하는 타임브레 주입 메커니즘을 설계했습니다. 이를 통해 모델은 미세 조정 없이 참조 발화자를 알 수 없는 발화자의 목소리를 합성할 수 있습니다. 또한, 일반적으로 무효 임베딩을 사용하는 Classifier-Free Guidance (CFG) 전략이 다양한 음향 조건에 대해 비적합하다는 것을 확인했습니다. 약물 연구를 통해 무효 프롬프트로 제로 벡터를 사용하는 것은 “임의의 목소리 생성"에서 모델을 멀리 이동시키지만, 저품질 아티팩트에서는 그렇지 않다는 것을 보여주었습니다. 이를 해결하기 위해 자연스럽게 수집된 노이즈를 부정 발화자 임베딩으로 사용하는 새로운 추론 전략을 제안합니다.
제로샷 음성 복제 기능을 지원하기 위해, 고급 음색 일관성을 필터링한 합성 데이터셋과 1억 개의 동기화된 오디오-비디오 쌍으로 구성된 대규모 사전 훈련 코퍼스를 구축했습니다. 이러한 데이터 전략은 MM-Sonate가 다양한 생성 작업에 걸쳐 일반화할 수 있도록 지원합니다. 주요 기여는 다음과 같습니다:
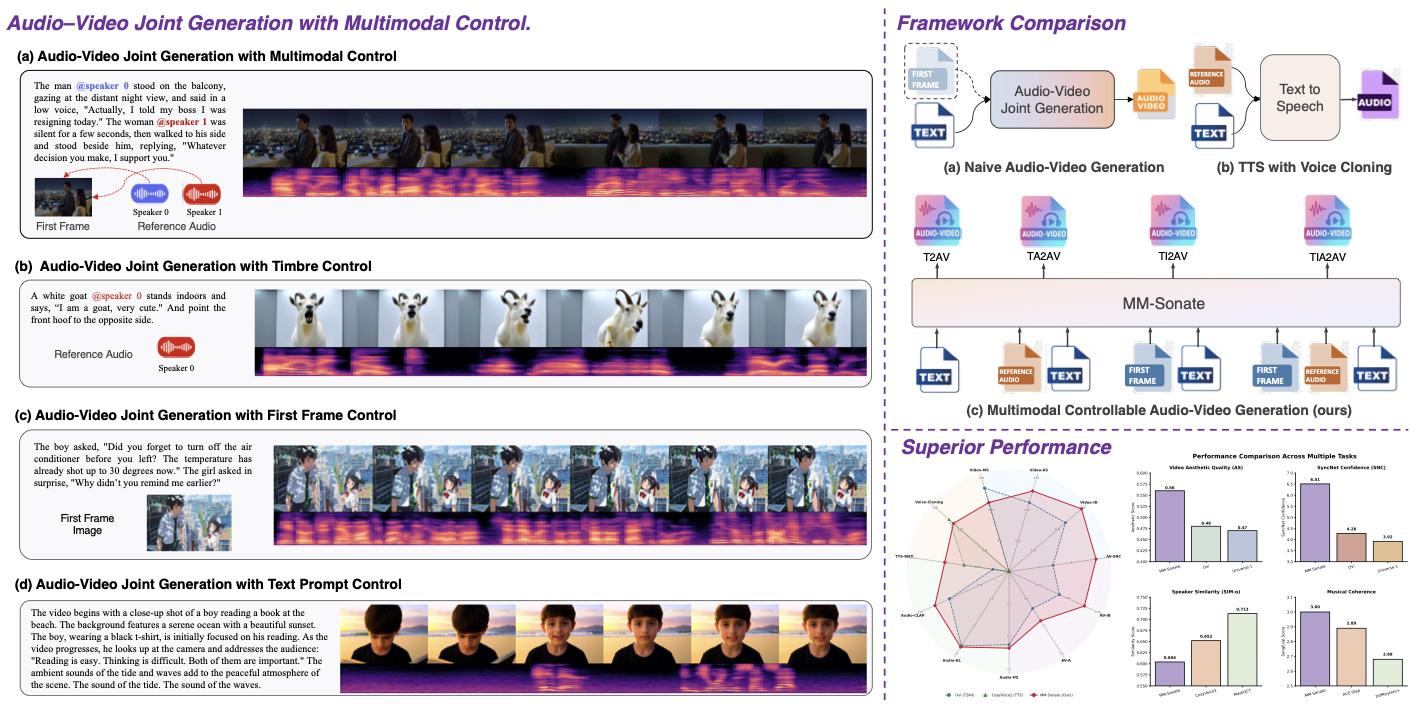
MM-Sonate는 오디오와 비디오 동시 생성에서 최고 성능을 달성하는 통합 플로우 매칭 프레임워크를 제안합니다. 통합된 명령-음절 입력을 통해 텍스트, 이미지, 그리고 오디오 조건의 유연한 조합을 지원합니다.
처음으로 제로샷 음성 복제가 가능한 동시 생성 모델을 도입했습니다. 전문적인 Text-to-Speech (TTS) 시스템과 비교할 수 있는 발화자 유사성 및 말하기 가독성을 달성하며, 동시에 동기화된 비디오를 생성합니다.
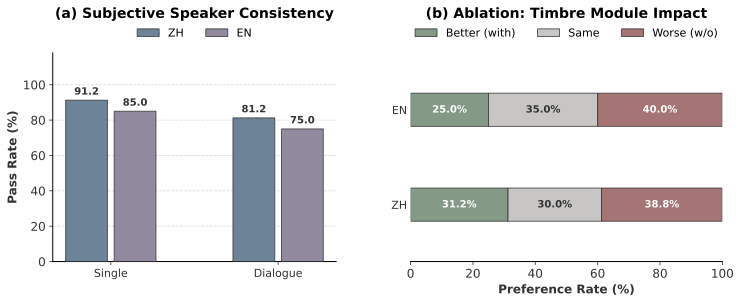
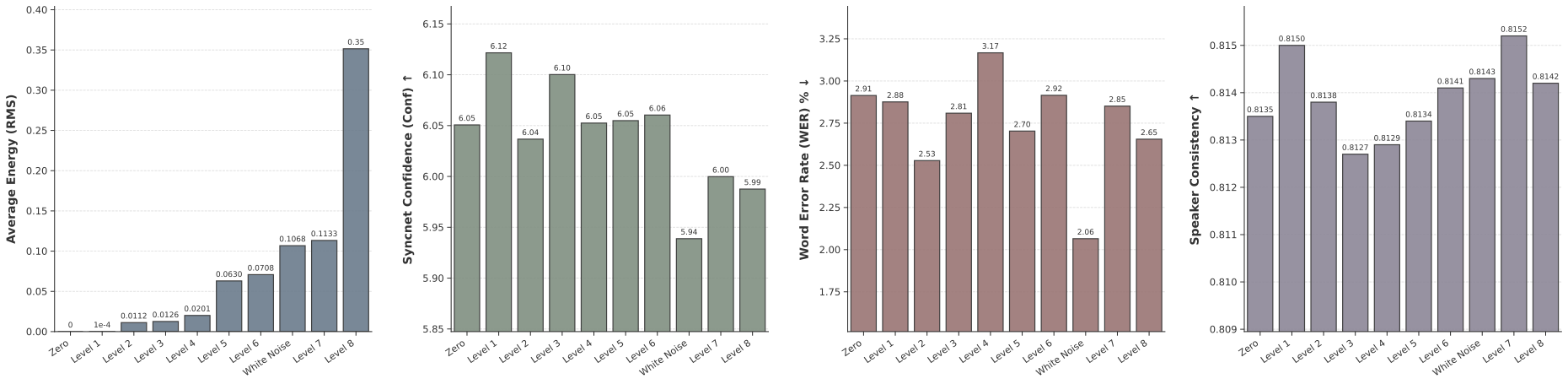
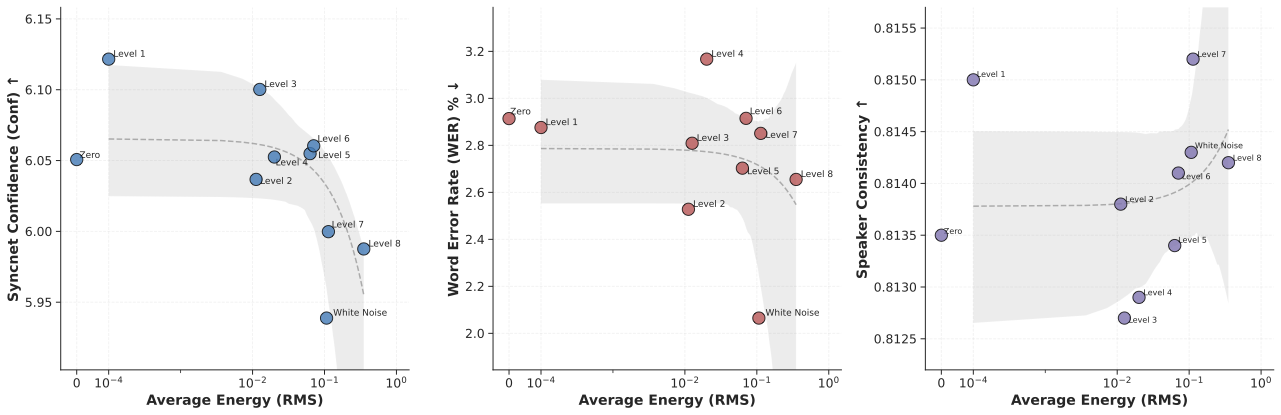
새로운 CFG 추론 전략인 자연스럽게 수집된 노이즈 기반 부정 조건부를 제안합니다. 실험적으로 표시한 바와 같이, 자연스러운 노이즈를 사용하는 음성 성능은 표준 제로 벡터 기초라인보다 훨씬 우수합니다.
광범위한 평가에서 MM-Sonate는 기존 통합 및 연결된 기본 모델을 오브젝티브 메트릭과 인간 선호도 모두에서 크게 능가하며, 특히 입 모양 동기화 정밀도와 말하기 가독성 측면에서 뛰어납니다.
관련 연구
음향-비디오 동시 생성
음향-비디오 동시 생성은 텍스트 설명을 기반으로 시각 프레임과 음향 신호를 동시에 합성하는 것을 목표로 하며, 모달 간의 의미적 일관성과 시간 동기화를 통합된 생성 과정에서 보장합니다. MM-Diffusion과 같은 선두주자들은 결합된 U-Net 백본을 사용하여 이 작업을 도입하였으나, 종종 작은 규모의 데이터셋(예: 대략 10시간)에 제약되어 일반화 능력이 제한되었습니다. 단일 모달 생성의 아키텍처 변화를 따르는 최근 연구들은 주로 확산 트랜스포머(DiTs)를 채택하고 있습니다. 이러한 접근 방식은 통합 또는 결합 스트림으로 나뉘는 두 가지 아키텍처 패러다임을 일반적으로 포함합니다. 예를 들어, UniForm은 통합된 단일 타워 아키텍처를 사용하여 연결된 오디오-비디오 토큰을 처리하고 있으며, AV-DiT는 가벼운 어댑터를 통해 이미지 DiT를 다중 모달 신호를 처리하도록 변경합니다. 이 분야의 중앙 과제는 정확한 공간-시간 동기화입니다. 이를 해결하기 위해 JavisDiT은 계층적 사전을 도입하고 있으며, Ovi는 대칭적인 두 개의 백본 설계를 통해 긴밀한 결합을 강제합니다. SyncFlow도 Rectified Flow Matching을 사용하여 더블 DiT 아키텍처로 정렬 안정성을 향상시킵니다. 처음부터 학습하는 것 외에도, 다른 연구는 사전 학습된 단일 모달 전문가를 활용해 강력한 사전 정보를 이용합니다; MMDisCo는 협동적 지도를 위한 판별자를 사용하고 있으며, Universe-1은 블록 수준에서 특수화된 모델을 융합합니다. 아키텍처와 데이터 규모에 대한 발전에도 불구하고 - 최근 연구가 VGGSound 및 AudioSet과 같은 더 큰 코퍼스를 활용하는 것처럼 - 대부분의 모델은 일반적인 사운드 효과나 음악 생성에 한정되어 있습니다. 동기화된 말하기와 비디오를 동시에 합성하는 것은 미세한 입 모양 동기화가 요구되는 중요한 도전 과제입니다.
음성 클론
음성 클론은 특정 발화 스타일, 타임브레, 프로소디, 감정 및 더욱 세밀한 특징을 흉내내는 것을 목표로 합니다. 특히 TTS(text-to-speech)의 범위에서 이 작업에 대한 많은 진전이 이루어졌습니다. 음성 클론 작업의 조건부 패턴은 크게 세 가지 일반적인 방식으로 나뉩니다: (1) 모든 발화자의 특징을 보존하지만 깊게 얽혀 있고 제어 불가능한 인코딩된 오디오 프롬프트 제공, (2) 특정 종류의 발화 스타일(예: 감정)에서 유래된 발화자 임베딩 사용으로 전체적인 합성 지침을 제공하는 것, 이는 상대적으로 간단한 모델 설계 내에서 부분적 제어 가능성을 허용하며, (3) 원하는 클론 음성의 변형을 묘사하는 텍스트 프롬프트를 지시하여 극도로 높은 유연성을 제공하지만 아직 미개척 영역입니다. 오직 말하기 작업에서 많은 탐색이 이루어졌지만, 음악 및 사운드 등 다른 도메인 간 전환과 음성 클론 측면의 다중 모달 생성에 대한 연구는 거의 없습니다.
예비
다중 모달 확산 트랜스포머
제안된 모델은 다양한 입력 모달 구성 - 텍스트, 이미지, 오디오를 임의의 조합으로 처리하는 통합 조건화 아키텍처를 사용합니다. 이 설계는 단일 프레임워크 내에서 T2VA(텍스트-비디오 및 오디오), TI2VA(텍스트와 이미지-비디오 및 오디오), TA2VA(텍스트와 오디오-비디오 및 오디오), TIA2VA(텍스트, 이미지, 오디오-비디오 및 오디오) 등 다양한 생성 시나리오를 처리할 수 있도록 합니다. 제안된 접근 방식은 SD3에서 소개된 MM-DiT 아키텍처를 기반으로 합니다. 학습 중에 각 입력 모달은 전용 인코더에 의해 처리되며, 존재하지 않는 모달은 훈련 가능한 플레이스홀더 토큰으로 나타납니다. 독립적인 인코딩 후 모든 모달 특성은 교차 모달 통합을 용이하게 하기 위해 공유 임베딩 공간에 투영됩니다.
플로우 매칭
훈련 프레임워크는 조건부 플로우 매칭을 생성 모델링 목표로 활용합니다. 접근 방식은 입력 (C) (예: 인코딩된 텍스트 또는 비디오 표현)에 조건화되는 매개변수화된 속도 필드 (v_\theta(t,C,x))를 학습하여 각 타임스텝 (t)에서의 변환 역학을 특성화합니다. 여기서 (\theta)는 훈련 가능한 네트워크 가중치를 나타냅니다. 우리는 최적 운송(OT) 경로를 사용해 플로우를 구성하고, 지상실 벡터 필드를 (u_t(x|x_1) = x_1 - (1-t)x_0)로 정의합니다. 이 학습된 필드는 초기 가우시안 노이즈 샘플 (x_0)을 시간 구간 ([0, 1])에서 오디오 잠재 (x_1)으로 변환하는 ODE 솔버를 통해 수치 적분을 가능하게 합니다. 여기서 (p)는 조건부 확률 트레일이며 (q)는 경험적 데이터 분포를 나타냅니다.
추론 시에는 Euler 적분 스키마를 사용해 시간 증가 단위 0.05로 학습된 속도 필드 (v_\theta(t,C,x))를 수치적으로 해결하여 무작위 가우시안 노이즈를 원하는 오디오 잠재 표현으로 점진적으로 변환합니다.
음향-비디오 잠재 표현
잠재 음향 인코더-디코더. 잠재 음향 코드는 이전 SecoustiCodec 프레임워크를 확장하고 있으며, 핵심 아키텍처를 유지하면서 오디오 재구성 품질을 최적화하기 위한 주요 수정 사항을 도입합니다. 코드는 Mel-VAE 구조로 구성되며 세 가지 주요 구성 요소가 포함되어 있습니다: mel-spectrogram 인코더, mel-spectrogram 디코더 및 판별자. 오디오 인코더는 44.1 kHz에서 샘플링된 입력 웨이브폼을 크게 감소한 시간 속도로 연속 잠재 임베딩으로 압축하여 높은 압축 비율과 편의성 품질을 달성합니다. VAE 아키텍처는 모델이 잠재 공간에서 연속적이고 완전한 분포를 학습하도록 하여 오디오 표현 능력 및 재구성 정확도를 크게 향상시킵니다.
잠재 비디오 인코더-디코더. 시각적 표현을 위해 CogVideoX의 3D 케이주얼 시간 인코더를 비디오 코드 백본으로 사용합니다. 비디오 인코더는 (H \times W) 해상도와 (T) 시간 길이의 입력 프레임을 처리하며, 공간-시간 잠재 임베딩을 차원 (h \times w \times t)로 압축하여 (h \ll H), (w \ll W), 그리고 (t \ll T)를 만듭니다. 인코더는 진행적인 공간-시간 다운샘플링을 적용하여 총 압축 비율 ( (H/h) \times (W/w) \times (T/t) )를 달성하고, 컴팩트한 잠재 표현을 생성합니다. 대응적으로, 비디오 디코더는 전치 합성곱을 사용하여 인코더 아키텍처를 반영하며, 고급 재구성 비디오 프레임을 잠재 임베딩에서 재구성합니다. 오디오 코드와 마찬가지로, 비디오 VAE는 연속적인 잠재 분포를 학습하여 플로우 매칭 프레임워크에서 부드러운 보간과 안정적인 훈련 동역학을 가능하게 합니다.
MM-Sonate
/>
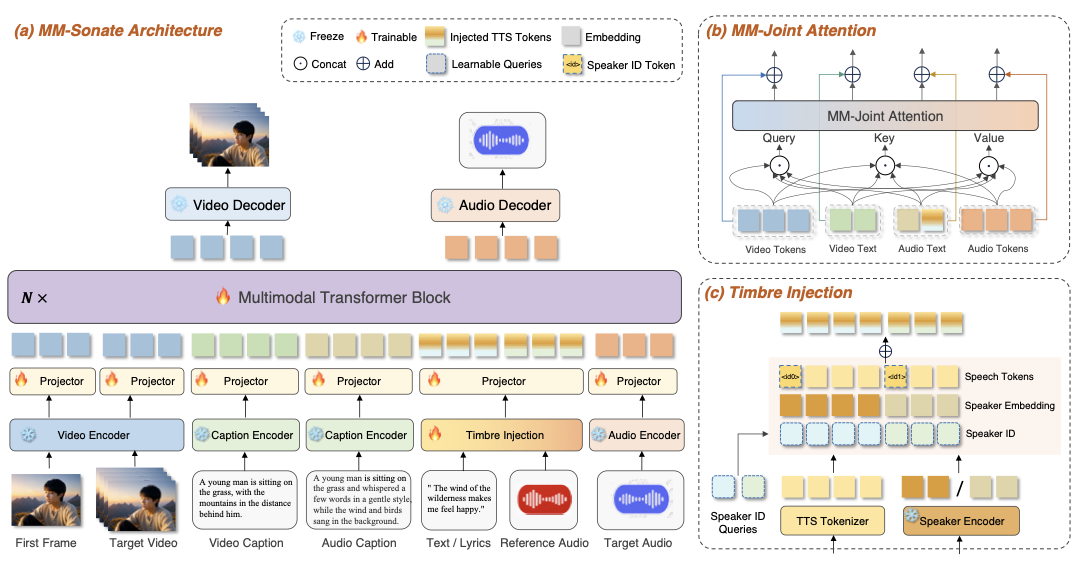
이 프레임워크는 미세한 제어가 가능한 다중 모달 플로우 매칭 모델을 사용하여 동시 오디오-비디오 생성을 가능하게 합니다. 비디오/오디오 캡션과 음절 시퀀스를 결합한 통합 명령은 정확한 내용 대응을 위해 설계되었습니다. 제로샷 음성 클론을 위한 참조 오디오, 첫 번째 프레임 이미지의 시각적 조건화. 참조 오디오에서 얻은 발화자 임베딩과 ID 임베딩(다중 발화자 제어를 위해)이 각 음절 시퀀스에 요소별로 추가되어 다중 모달 특징을 결합하고 처리하여 MM-DiT 백본을 통해 오디오와 비디오 잠재의 공동 분포를 모델링합니다.
모델 아키텍처 개요
그림 1에서 보는 것처럼 MM-Sonate는 제로샷 음색 클론 기능을 갖춘 다중 모달 조절 가능한 프레임워크를 도입합니다. 학습 중, 명령 인코더, 발화자 인코더, 비디오 인코더, 비디오 디코더, 오디오 인코더 및 오디오 디코더는 사전 훈련된 모듈로서 고정됩니다. 첫 번째 계층의 결합 확산 트랜스포머는 시간적으로 연결된 명령 임베딩과 음절 임베딩을 텍스트-모달 조건화 입력으로 받으며, 오디오-모달 입력으로 노이즈 된 mel-spectrogram VAE 잠재를, 비디오-모달 입력으로 노이즈 된 비디오 VAE 잠재를 받습니다. 자연어 설명을 통해 비디오 콘텐츠 생성뿐만 아니라 음성 시나리오에서 성별, 나이, 감정, 스타일 및 억양 속성을 포함한 다중 속성 조절이 가능하며, 다중 발화자 대화 생성도 지원합니다. 또한 참조 오디오 입력을 사용하여 임의의 발화자에 대한 제로샷 음색 클론 기능을 제공합니다. 음악 생성 시나리오에서는 자연어를 통해 가수 특성(예: 성별 및 나이), 음악 장르, 악기 구성, 멜로디 및 감정 표현 등을 제어할 수 있으며, 참조 오디오를 사용해 가수의 음성을 복제할 수 있습니다. 사운드 이펙트 생성 시나리오에서는 자연어 지시문을 통해 제어된 출력을 생성합니다.
통합 명령-가이드 입력
동시에 오디오와 비디오를 생성하기 위해, 모든 작업에서 일관된 텍스트 모달 입력을 유지하는 표준화된 명령-음절 입력 형식을 설계했습니다. 이 형식은 세 가지 주요 구성 요소로 구성됩니다: 비디오 명령 설명, 오디오 명령 설명 및 음절 시퀀스입니다. 비디오 명령 설명은 생성에 필요한 전체적인 시각적 장면 정보를 포괄합니다. 오디오 명령 설명은 출력의 원하는 음향 속성을 지정합니다. 음성 합성에서는 이러한 속성이 성별, 나이, 감정, 스타일 및 억양과 같은 발화자 특성을 포함합니다. 대화 시나리오에서는 두 명의 발화자를 위한 개별 설명을 제공하며, 각각의 텍스트 입력 앞에 특수 토큰 [S0]와 [S1]을 추가하여 말하는 내용을 구분합니다. 또한 음악 생성 시나리오에서는 가수의 타임브레(예: 성별 및 나이), 음악 장르, 악기 구성, 멜로디 및 감정 표현 등의 속성을 정의하며, 사운드 이펙트 생성 시나리오에서는 관련 소닉 장면 정보를 포함합니다.