최근 몇 년 동안 학술 출판물이 급증하고 있다. 인공지능 분야만 보더라도 arXiv의 `cs.AI`와 `cs.LG` 카테고리에 매년 수만 편의 새로운 논문이 게재되고 있으며, NeurIPS, ICLR, ICML과 같은 상위 컨퍼런스로 제출되는 논문 수도 기록적인 수준을 보이고 있다. 이 "출판 폭발"은 피어 리뷰 시스템에 전례 없는 압력을 가하고 있다.
리뷰어의 부담이 크게 증가했다. 한 명의 리뷰어는 한정된 시간 내에 여러 편의 논문을 평가해야 하는데, 각 리뷰에는 해당 분야의 최신 연구를 포괄적으로 이해하는 것이 요구된다. 하지만 현실은 달라서 많은 리뷰어들이 모든 제출 논문에 대한 철저하고 공정한 평가를 하지 못한다. 심지어 일부 리뷰어는 전체 텍스트를 신중하게 읽지 않고 피드백을 제공하기도 한다. 또한 학계에서는 AI 생성된 피드백을 적절히 검증하지 않고 사용하는 문제에 대해 점점 더 우려하고 있다.
평가 차원 중 하나인 신규성은 논문의 수용 여부를 결정하는 중요한 요소로 여겨진다. 그러나 신규성을 정확하게 평가하기는 어렵다. 이는 문헌 규모가 매우 크고, 세밀한 분석을 통해 주장을 검증하는 것이 어려우며, 리뷰어들의 판단에 주관성이 있기 때문이다. 대형 언어 모델(LLM)은 학술 논문 검토를 돕는 유망한 방향으로 부상하고 있지만, 기존 방법에는 한계가 있다: 단순 LLM 기반 접근법은 매개변수적 지식에만 의존하면 존재하지 않는 참조를 생성할 수 있으며; 기존의 RAG 기반 방법은 제목과 초록만 비교하기 때문에 중요한 기술 세부 사항을 놓칠 수 있고; 대부분의 접근법은 문맥 창의 한계로 인해 관련 작업을 체계적으로 조직하지 못한다.
이러한 문제를 해결하기 위해 **OpenNovelty**라는 LLM 기반 시스템을 제안한다. 이 시스템은 대규모 제출물에 대한 투명하고 검증 가능한 신규성 분석을 제공하도록 설계되었다. OpenNovelty의 핵심 디자인 철학은 **“신규성을 검증할 수 있게 하기”**이다:
“우리는 LLM 내부의 매개변수적 지식에 의존하지 않고, 실제 논문을 찾아 신규성 주장 수준에서 전체 텍스트를 비교함으로써 모든 판단이 증거 기반임을 보장합니다.”
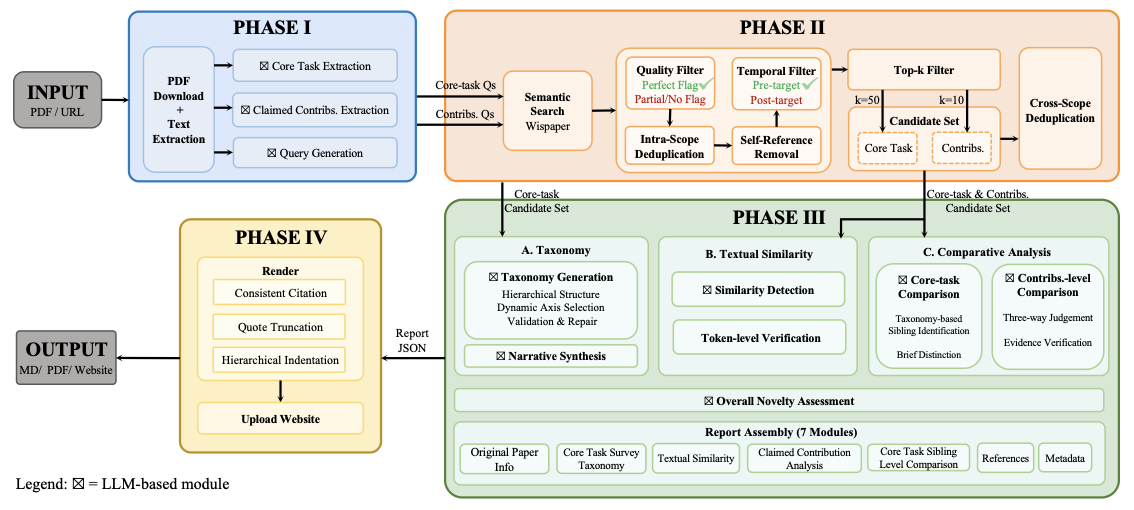
OpenNovelty은 네 단계의 프레임워크를 통해 작동한다:
Phase I: 정보 추출 — 대상 논문에서 핵심 작업과 주장한 신규성 주장을 추출하고, 이후 검색을 위한 의미적 쿼리를 생성합니다.
Phase II: 논문 검색 — 추출된 쿼리 기반으로 Wispaper을 사용하여 관련 이전 작업을 검색하고 다층 필터링을 통해 고질량 후보를 선택합니다.
Phase III: 분석 및 종합 — 추출한 주장과 검색된 논문을 기반으로 상위 구조의 관련 작업 세분화를 구성하고 전체 텍스트 비교를 수행하여 각 신규성 주장을 검증합니다.
Phase IV: 보고서 생성 — 모든 분석 결과를 명확한 인용 및 증거 조각과 함께 구조화된 신규성 보고서로 종합하며, 모든 판단이 검증 가능하고 추적 가능하도록 합니다.
각 단계의 기술적 세부 사항은 Section 2에서 제공됩니다.
또한 우리는 OpenNovelty을 ICLR 2026에 제출된 500개 이상의 논문 분석에 배포했으며, 모든 신규성 보고서는 우리 웹사이트에서 공개적으로 이용 가능합니다. 예비 분석 결과 시스템이 관련 이전 작업, 특히 저자들이 놓칠 수 있는 유사한 논문을 식별할 수 있음을 나타냅니다. 우리는 이후 단계에서 이 분석을 2,000개 이상의 제출물로 확장할 계획입니다.
주요 기여는 다음과 같습니다:
모든 평가를 추출된 실제 논문에 근거하며, 각 판단은 명확한 인용과 증거 조각으로 보완되어 단순 LLM 기반 접근법에서 발생하는 환영 문제를 효과적으로 피한다.
OpenNovelty을 ICLR 2026에 제출된 논문 500개 이상에 배포하고, 모든 보고서를 우리 웹사이트에 공개하여 연구 커뮤니티에게 접근 가능한 투명한 신규성 분석을 제공한다.
💡 논문 해설
1. **신규성 평가의 복잡성을 단순화**: OpenNovelty는 학술 논문에서 추출된 실제 데이터를 기반으로 신규성을 검증하고, 이 과정을 통해 복잡한 평가 작업을 자동화하여 리뷰어의 부담을 줄인다. 이를 통해 피어 리뷰 과정이 더욱 정확해진다.
2. **세부 사항을 놓치지 않는 검색 엔진**: Wispaper은 단순히 제목과 초록만 비교하는 것이 아니라 전체 텍스트를 기반으로 세밀한 분석을 제공한다. 이는 논문의 핵심 내용을 정확하게 파악할 수 있도록 돕는다.
3. **증거 기반 판단**: 모든 신규성 평가는 실제 논문에서 추출된 데이터로 근거를 두고 있으며, 이에 따라 각 평가 결과는 명확한 증거와 함께 제공된다.
📄 논문 발췌 (ArXiv Source)
/>
OpenNovelty 프레임워크의 개요. Phase I은 핵심 작업과 주장한 기여를 추출하고 확장된 쿼리를 생성합니다. Phase II은 후보 이전 작업을 검색하고 필터링합니다. Phase III은 세분화 구조를 구성하고 증거 기반 비교를 수행합니다. Phase IV는 구조화된 출력으로부터 최종 신규성 보고서를 생성합니다.
서론
최근 몇 년 동안 학술 출판물이 급증하고 있다. 인공지능 분야만 보더라도 arXiv의 cs.AI와 cs.LG 카테고리에 매년 수만 편의 새로운 논문이 게재되고 있으며, NeurIPS, ICLR, ICML과 같은 상위 컨퍼런스로 제출되는 논문 수도 기록적인 수준을 보이고 있다. 이 “출판 폭발"은 피어 리뷰 시스템에 전례 없는 압력을 가하고 있다.
리뷰어의 부담이 크게 증가했다. 한 명의 리뷰어는 한정된 시간 내에 여러 편의 논문을 평가해야 하는데, 각 리뷰에는 해당 분야의 최신 연구를 포괄적으로 이해하는 것이 요구된다. 하지만 현실은 달라서 많은 리뷰어들이 모든 제출 논문에 대한 철저하고 공정한 평가를 하지 못한다. 심지어 일부 리뷰어는 전체 텍스트를 신중하게 읽지 않고 피드백을 제공하기도 한다. 또한 학계에서는 AI 생성된 피드백을 적절히 검증하지 않고 사용하는 문제에 대해 점점 더 우려하고 있다.
평가 차원 중 하나인 신규성은 논문의 수용 여부를 결정하는 중요한 요소로 여겨진다. 그러나 신규성을 정확하게 평가하기는 어렵다. 이는 문헌 규모가 매우 크고, 세밀한 분석을 통해 주장을 검증하는 것이 어려우며, 리뷰어들의 판단에 주관성이 있기 때문이다. 대형 언어 모델(LLM)은 학술 논문 검토를 돕는 유망한 방향으로 부상하고 있지만, 기존 방법에는 한계가 있다: 단순 LLM 기반 접근법은 매개변수적 지식에만 의존하면 존재하지 않는 참조를 생성할 수 있으며; 기존의 RAG 기반 방법은 제목과 초록만 비교하기 때문에 중요한 기술 세부 사항을 놓칠 수 있고; 대부분의 접근법은 문맥 창의 한계로 인해 관련 작업을 체계적으로 조직하지 못한다.
이러한 문제를 해결하기 위해 **OpenNovelty**라는 LLM 기반 시스템을 제안한다. 이 시스템은 대규모 제출물에 대한 투명하고 검증 가능한 신규성 분석을 제공하도록 설계되었다.
OpenNovelty는 네 단계의 프레임워크를 통해 작동한다:
Phase I: 정보 추출 — 대상 논문에서 핵심 작업과 주장한 신규성 주장을 추출하고, 이후 검색을 위한 의미적 쿼리를 생성합니다.
Phase II: 논문 검색 — 추출된 쿼리 기반으로 Wispaper를 사용하여 관련 이전 작업을 검색하고 다층 필터링을 통해 고질량 후보를 선택합니다.
Phase III: 분석 및 종합 — 추출한 주장과 검색된 논문을 기반으로 상위 구조의 관련 작업 세분화를 구성하고 전체 텍스트 비교를 수행하여 각 신규성 주장을 검증합니다.
Phase IV: 보고서 생성 — 모든 분석 결과를 명확한 인용 및 증거 조각과 함께 구조화된 신규성 보고서로 종합하며, 모든 판단이 검증 가능하고 추적 가능하도록 합니다.
각 단계의 기술적 세부 사항은 Section 2에서 제공됩니다.
또한 우리는 OpenNovelty을 ICLR 2026에 제출된 500개 이상의 논문 분석에 배포했으며, 모든 신규성 보고서는 우리 웹사이트에서 공개적으로 이용 가능합니다. 예비 분석 결과 시스템이 관련 이전 작업, 특히 저자들이 놓칠 수 있는 유사한 논문을 식별할 수 있음을 나타냅니다. 우리는 이후 단계에서 이 분석을 2,000개 이상의 제출물로 확장할 계획입니다.
주요 기여는 다음과 같습니다:
모든 평가를 추출된 실제 논문에 근거하며, 각 판단은 명확한 인용과 증거 조각으로 보완되어 단순 LLM 기반 접근법에서 발생하는 환영 문제를 효과적으로 피한다.
OpenNovelty을 ICLR 2026에 제출된 논문 500개 이상에 배포하고, 모든 보고서를 우리 웹사이트에 공개하여 연구 커뮤니티에게 접근 가능한 투명한 신규성 분석을 제공한다.
OpenNovelty
이 섹션에서는 OpenNovelty의 네 단계를 자세히 설명한다. 우리의 프레임워크 개요는 Figure 1에 나와 있다. 각 단계의 워크플로우를 보여주기 위해, 이 섹션 전체에서 arXiv의 강화 학습을 이용한 LLM 에이전트 논문을 예시로 사용한다.
Phase I: 정보 추출
첫 번째 단계는 대상 논문에서 중요한 정보를 추출하고 이후 검색을 위한 의미적 쿼리를 생성하는 것이다. 구체적으로, 이 단계에는 두 가지 과정이 포함된다: (1) 핵심 작업과 주장한 기여의 추출; 그리고 (2) 관련 이전 작업을 검색하기 위한 다양한 의미적 쿼리의 생성. 모든 추출 작업은 claude-sonnet-4-5-20250929을 사용하여 제안된 프롬프트를 이용해 zero-shot 패러다임에서 수행된다.
핵심 작업과 주장한 기여 추출
핵심 작업.
논문이 다루는 주요 문제나 과제를 추출하며, 5-15단어로 표현되며 논문 내에 소개된 특정 모델 이름 대신 분야 용어를 사용한다 (예: “확산 모델 추론 가속화”). 이 추상화는 생성된 쿼리가 더 넓은 범위의 관련 작업과 일치할 수 있게 한다. 핵심 작업 추출을 위한 프롬프트 템플릿은 Appendix 7.5, Table 6에 제공된다.
주장한 기여.
저자가 주장하는 주요 기여를 추출한다. 이는 새로운 방법론, 아키텍처, 알고리즘, 데이터셋, 벤치마크, 이론적 정형화 등을 포함한다. 순수 실험 결과와 성능 수치는 명시적으로 제외된다. 각 기여는 네 가지 필드를 포함하는 구조화된 객체로 표현된다: (1) 최대 15단어의 name; (2) 정확한 귀속을 위한 최대 40단어의 원문 author_claim_text; (3) 쿼리 생성을 위한 최대 60단어의 정규화된 description; 그리고 (4) 추적 가능성을 위해 source_hint. LLM은 “We propose"과 “Our contributions are"와 같은 유도구문을 사용하여 제목, 초록, 서론 및 결론 섹션에서 기여 문장을 찾는다. 주장한 기여 추출을 위한 프롬프트 템플릿은 Appendix 7.5, Table 7에 상세히 제공된다.
의미 확장 쿼리 생성
추출된 내용을 바탕으로 Phase II 검색을 위한 의미적 쿼리를 생성한다. 우리는 여러 개의 의미적으로 동등한 변형을 생성하는 쿼리 확장 메커니즘을 사용한다. 주요 쿼리 생성 및 의미 변형 확장을 위한 프롬프트 템플릿은 Appendix 7.5, Table 8과 Table 9에 제공된다.
생성 과정.
추출된 각 항목 (핵심 작업 또는 기여)에 대해 먼저 추출 필드에서 합성한 주요 쿼리를 생성하며, 여기서 키 용어를 유지한다. 그런 다음 두 개의 의미 변형을 생성하는데, 이는 대체 학술 용어와 표준 약어 (예: “RL"은 “강화 학습”)를 사용하는 문장들의 동의어이다. 기여 쿼리는 “Find papers about [topic]” 형식이며 5-15단어의 부드러운 제약 조건과 25단어의 강제적인 한도가 있으며, 핵심 작업 쿼리는 검색 접두사 없이 단순한 짧은 문장으로 표현된다. Example [box:query_example]은 일반적인 쿼리 생성 출력을 보여준다.
**A. 핵심 작업 쿼리** (검색 접두사 없는 짧은 문장)
추출된 핵심 작업:
text: “LLM 에이전트를 위한 장기 의사결정을 통한 다중 회차 강화 학습으로 훈련”
생성된 쿼리들:
주요: “LLM 에이전트의 장기 의사결정을 위한 다중 회차 강화 학습을 통해 훈련”
변형 1: “다단계 RL로 긴 기간 의사결정 작업에서 대규모 언어 모델 에이전트를 훈련시키는 것”
변형 2: “확장된 다중 회차 의사결정 수평을 통한 LLM 에이전트의 강화 학습”
B. 기여 쿼리 (“Find papers about” 접두사 포함)
추출된 기여:
name: “AgentGym-RL 프레임워크로 다중 회차 RL 기반 에이전트 훈련”
description: “다양한 시나리오 (웹 탐색 및 몸체 작업 포함)에 걸쳐 주류 강화 학습 알고리즘을 지원하는 모듈식 아키텍처를 갖춘 통합 강화 학습 프레임워크”
생성된 쿼리들:
주요: “다중 회차 의사결정 작업에서 에이전트 훈련을 위한 강화 학습 프레임워크에 대한 논문 찾기”
변형 1: “다단계 연속 의사결정 문제를 위한 학습 정책을 배울 수 있는 강화 학습 시스템에 대한 논문 찾기”
변형 2: “장기 의사결정 작업에서 에이전트 훈련을 위한 강화 학습 방법에 대한 논문 찾기”
출력 통계.
각 논문은 총 6-12개의 쿼리를 생성한다: 핵심 작업에 대해 3개 (주요 1개 + 변형 2개)와 기여에 대해 3-9개 (1-3 개의 기여 각각에 대해 3개의 쿼리).
구현 및 출력
Phase I에는 여러 기술적 고려 사항이 포함된다: 핵심 작업과 저자 선언한 기여를 추출하기 위한 zero-shot 프롬프트 공학, 구조화된 출력 검증과 파싱 대체 및 제약 조건 강제, 명시적인 형식 및 길이 규칙을 따르는 쿼리 합성 및 의미 변형, 그리고 Phase II에서 시간 필터링을 지원하기 위한 게재 날짜 추론. 장문의 문서에서는 “참고 문헌” 섹션까지 논문 텍스트를 자르며, 200K 문자의 강제적 한도가 있다. Appendix 7에는 출력 필드 정의, 온도 설정, 프롬프트 설계 원칙, 검증 및 대체 메커니즘, 날짜 추론 규칙을 포함한 해당 사양이 제공된다.
zero-shot 패러다임과 쿼리 확장 전략을 채택한 이유는 Section 3.1.1에서 논의되고 있으며, 수학 공식 및 시각적 내용 추출에 대한 한계는 Section 3.2.1에서 다룬다.
Phase I의 출력은 핵심 작업, 주장한 기여, 그리고 6-12개 확장 쿼리를 포함한다. 이 출력들은 Phase II와 Phase III의 입력으로 사용된다.
Phase II: 논문 검색
Phase II는 Phase I에서 생성된 쿼리에 기반하여 관련 이전 작업을 검색한다. 우리는 넓은 회수, 다층 필터링 전략을 채택한다: 의미적 검색 엔진이 모든 가능한 관련 논문 (보통 각 제출물당 수백 개에서 수천 개)을 검색한 다음, 순차적인 필터링 계층을 통해 후속 분석에 사용할 고질량 후보를 생성한다.
의미적 검색
Wispaper은 최적화된 학술 논문 검색 엔진으로서 우리는 이를 사용한다. Phase II는 Phase I에서 생성된 자연어 쿼리를 그대로 사용하며, 이 쿼리는 후처리 없이 검색 엔진에 전송된다. 이 설계는 LLM이 생성한 쿼리의 의미적 정합성을 보존하고 Wispaper의 자연어 이해 능력을 활용한다.
실행 전략.
각 논문당 6-12개의 쿼리는 설정 가능한 동시성 (기본값: 1, API 속도 제한을 존중; 고속 통과 시나리오에서는 설정 가능)으로 사용되는 스레드 풀을 통해 실행된다.
품질 플래그 할당.
각 검색된 논문에 대해 Wispaper의 확인 결과를 기반으로 품질 플래그 (perfect, partial, 또는 no)를 계산한다. perfect로 표시된 논문만 다음 필터링 계층으로 진행된다.
다층 필터링
원시 검색 결과는 수백 개에서 수천 개의 논문을 포함할 수 있다. 우리는 핵심 작업과 기여 쿼리에 대해 범위별 필터링 파이프라인을 적용한 후, 교차 범위 중복 제거를 통해 고질량 후보 집합을 생성한다. 중요하게도 우리는 인용 횟수나 출판처의 명성을 대신하여 의미적 관련성 신호에 의존한다.
핵심 작업 필터링.
핵심 작업 쿼리 3개 (주요 1개 + 변형 2개)를 사용하여 다음과 같은 순차적인 필터링 계층을 적용한다: (1) 품질 플래그 필터링은 의미적 관련성이 높은 perfect로 표시된 논문만 유지하며, 이는 일반적으로 수량의 약 70-80%를 줄입니다; (2) 내부 범위 중복 제거는 이 범위 내에서 여러 쿼리에 의해 검색된 논문을 정규화된 제목의 표준화 해시 (MD5) 매칭을 통해 제거하며, 일반적으로 쿼리 겹침에 따라 20-50% 정도를 줄입니다; (3) Top-K 선택은 나머지 후보들을 관련성 점수로 순위 지정하고 최대 50개의 논문을 선택하여 관련 작업에 대한 광범위한 커버리지를 보장합니다.