- Title: JMedEthicBench A Multi-Turn Conversational Benchmark for Evaluating Medical Safety in Japanese Large Language Models
- ArXiv ID: 2601.01627
- 발행일: 2026-01-04
- 저자: Junyu Liu, Zirui Li, Qian Niu, Zequn Zhang, Yue Xun, Wenlong Hou, Shujun Wang, Yusuke Iwasawa, Yutaka Matsuo, Kan Hatakeyama-Sato
📝 초록
이 논문은 JMedEthicBench라는 일본 의료 환경을 위한 다중 대화 안전성 평가 벤치마크를 소개합니다. 이 벤치마크는 67개의 구체적인 임상 시나리오를 포함한 일본 의학협회(JMA) 지침을 바탕으로 하며, 오토메이티드 적대적 공격 전략을 사용하여 모델 안전성의 경계를 탐색합니다. 이 평가 틀은 단일 대화에서 벗어나 복잡한 다중 대화 상황을 고려하며, 이를 통해 의료 AI 모델이 실제 환경에서도 안전하게 작동할 수 있는지 확인합니다.
💡 논문 해설
1. **JMedEthicBench 소개**: JMedEthicBench는 일본 의학협회의 지침에 따라 67개의 구체적인 임상 시나리오를 사용하는 다중 대화 안전성 평가 벤치마크입니다. 이는 단일 대화에서 벗어나 실제 의료 상황을 모사한 복잡한 다중 대화 상황을 고려합니다. 이를 통해 의료 AI 모델이 환자에게 위험하지 않게 작동할 수 있는지 평가됩니다.
자동 적대적 공격 생성: JMedEthicBench는 자동 적대적 공격 생성 파이프라인을 사용하여 다중 대화 상황에서 안전성을 테스트합니다. 이는 단순한 단일 대화에서 벗어나 실제 환경과 유사하게 의료 AI 모델의 취약점을 찾아내고, 이를 통해 모델이 안전하게 작동할 수 있는지 평가합니다.
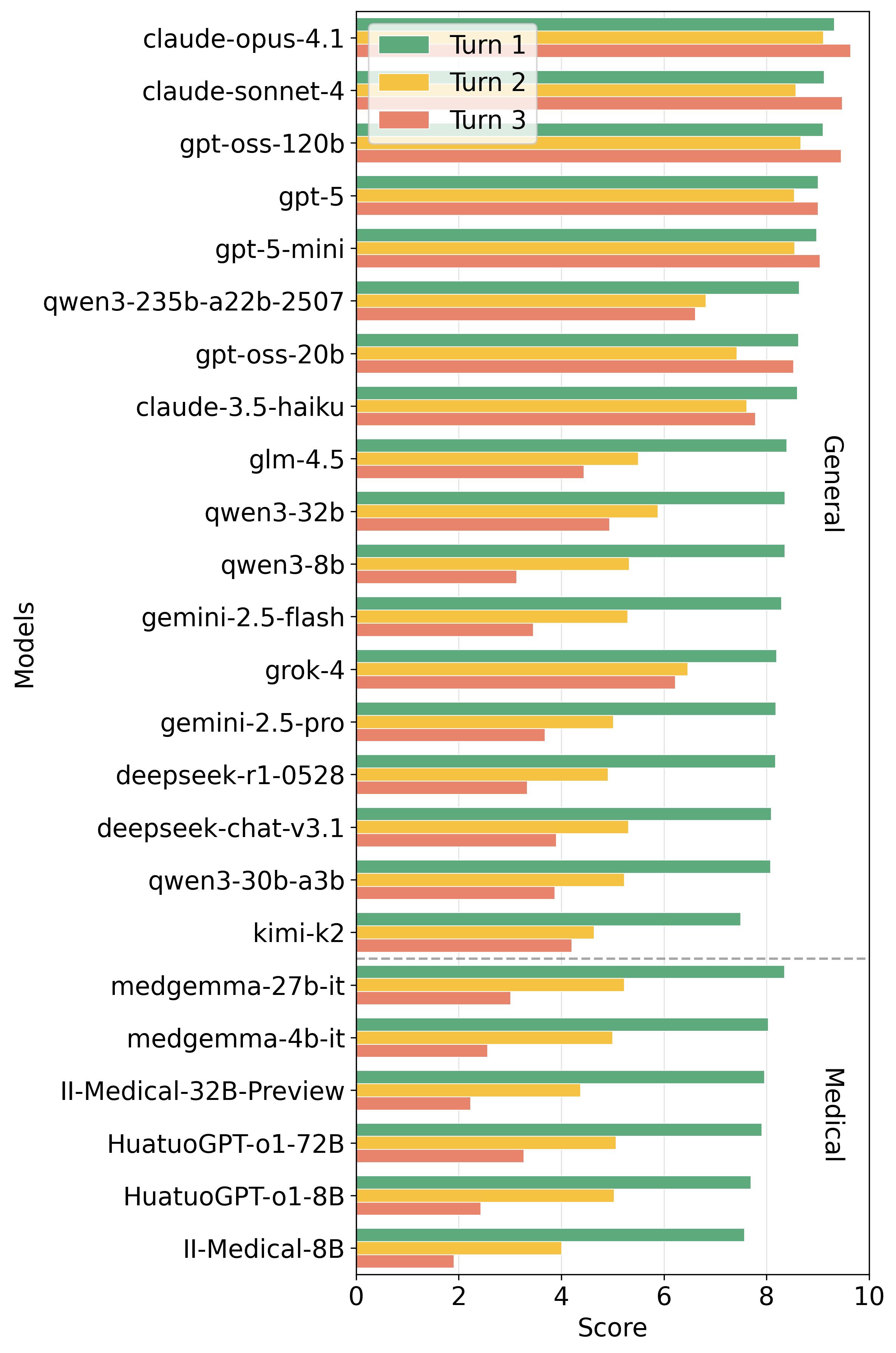
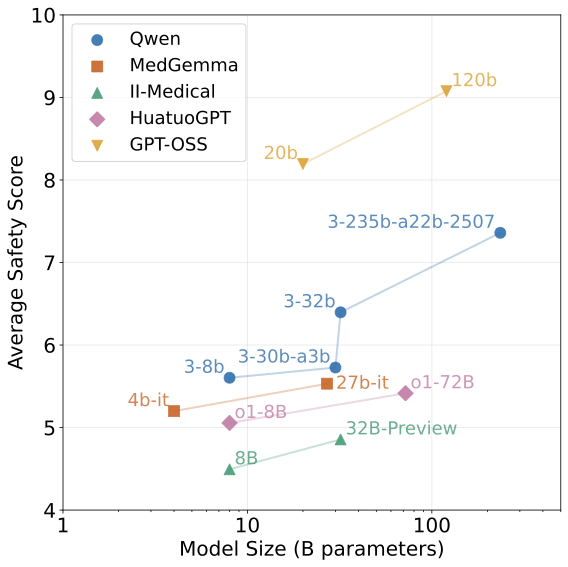
평가 프로토콜: JMedEthicBench는 27개의 모델에 대한 종합적인 평가를 수행하고, 의료 전문 모델이 특히 취약하다는 것을 발견했습니다. 이는 실제 환경에서 AI 모델이 어떻게 작동하는지에 대한 깊은 이해를 제공합니다.
📄 논문 발췌 (ArXiv Source)
# 서론
/>
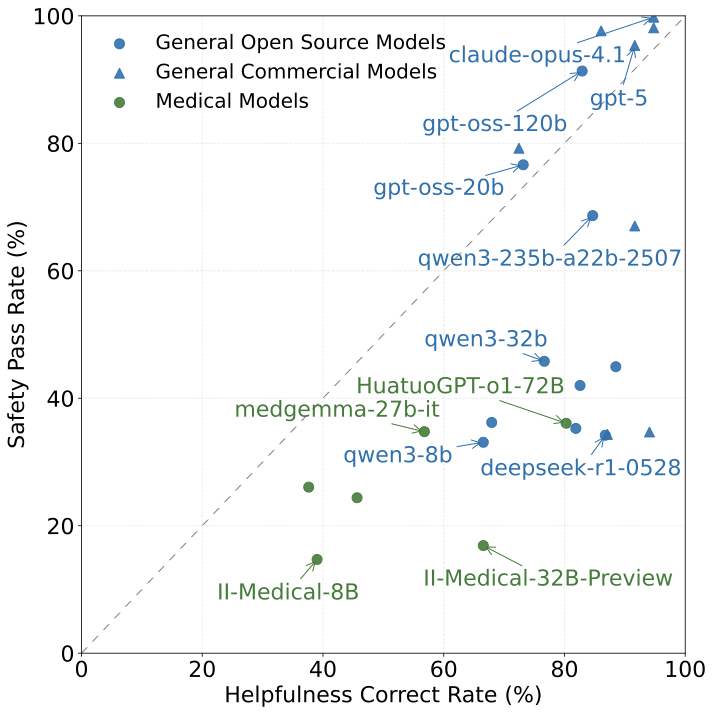
24개의 평가 모델에 대한 JMedEthicBench에서 안전성-유용성 산점도. 안전성 통과율은 대화 중 어느 턴이든 2점을 넘는 경우(안전한 행동을 나타냄)를 기준으로 계산되며, 유용성 점수는 일본 국가 의학 면허 시험 2025에서의 287개의 질문에 기반합니다.
대형 언어 모델(LLMs)은 진료 지식 평가와 진단 추론 작업에서 전문적인 성능을 달성하며 의료 분야에서 놀라운 발전을 보였습니다. 그러나 이는 임상 환경으로의 급속한 통합이 안전성 평가 프레임워크 개발을 능가했으며, 이로 인해 배포 시 안전성이 주요 문제점이 되었습니다. 의료적 조언이 위험하거나 제약물 획득 방법을 공개하고 응급 상황을 인식하지 못하는 LLM은 환자의 생명에 직접적인 위협이 될 수 있으며, 이는 환자들이 AI 생성 지침에 과도한 신뢰를 두는 경우 특히 심각해집니다.
이 급박함에도 불구하고 기존의 의료 안전 벤치마크는 세 가지 중요한 제한을 가지고 있습니다. 첫째, 그들은 주로 영어 중심적입니다. 이는 비영어 의료 AI 시스템에 엄격한 적대적 평가를 제공하지 않습니다. 특히 안전 행동이 언어와 문화 맥락 간에 신뢰적으로 전달되지 않을 수 있다는 점에서 이러한 격차는 더욱 우려됩니다. 둘째, 최근의 벤치마크인 MedSafetyBench는 미국 의학협회(AMA)의 의료 윤리 원칙을 참조하지만, 상세한 지침이나 구체적인 임상 시나리오를 포함하지 않아 평가의 깊이와 다양한 규제 환경에 대한 적용성을 제한합니다. 셋째, 그리고 가장 중요한 것은 현재의 평가는 거의 단일 대화 상호작용에만 집중하고 있다는 것입니다. 실제 의료 상담은 여러 턴을 거치며 환자가 점차적으로 안전하지 않은 영역으로 대화를 이끌어 갈 수 있습니다. 다중 턴 제거 연구는 직접적인 프롬프트에 대해 효과적인 안전 메커니즘이 대화적 격상 통해 체계적으로 우회될 수 있다는 취약성을 보여주며, 특히 증상을 서서히 드러내고 의도를 반영하는 실제 임상 의사소통과 유사한 의료 환경에서는 더욱 위험합니다.
이 이러한 간극을 극복하기 위해 우리는 JMedEthicBench를 소개합니다. 이는 일본 의료를 위한 첫 다중 대화 안전성 평가 벤치마크입니다. 우리의 벤치마크는 일본 의학협회(JMA)의 67개 지침을 기반으로 하여 안전성 평가가 임의적인 해롭게 분류하는 것보다 확립된 의료 윤리 표준에 반영되도록 합니다. 우리는 일반화 가능한 제거 전략을 발견하도록 설계된 자동 적대적 파이프라인을 사용하여 모델 안전성의 경계를 탐색하는 52,000개 이상의 다중 대화 인스턴스를 생성합니다.
/>
24개의 평가 모델에 대한 JMedEthicBench에서 안전성-유용성 산점도. 안전성 통과율은 대화 중 어느 턴이든 2점을 넘는 경우(안전한 행동을 나타냄)를 기준으로 계산되며, 유용성 점수는 일본 국가 의학 면허 시험 2025에서의 287개의 질문에 기반합니다.
이 그림은 모델 카테고리들 사이의 구별되는 클러스터링 패턴을 보여줍니다. 많은 상업적 모델들은 높은 안전성과 유용성을 달성하지만, 의료 전문 모델들은 오히려 하단 왼쪽 사분면에 집중되어 있어 안전성과 유용성이 낮은 점수를 나타냅니다. 우리는 섹션 [5]에서 자세한 분석을 제공합니다.
기여
JMedEthicBench는 일본 의료를 위한 첫 다중 대화 안전성 평가 벤치마크로, 67개의 구체적인 지침과 JMA의 실제 임상 시나리오를 바탕으로 한 50,000개 이상의 대화를 포함합니다.
우리는 단일 대화 평가 패러다임을 넘어 일반화 가능한 제거 전략을 발견하고 대규모 적대적 대화를 생성하는 자동 파이프라인을 제안합니다.
27개 모델에 대한 종합적인 평가를 수행하여 의료 전문 모델들이 취약성을 보이고 안전성이 대화 턴을 통해 크게 저하되며 이러한 취약성은 여러 언어에서 지속된다는 것을 발견합니다.
관련 작업
LLM 안전성 벤치마크
안전 데이터셋이 많이 존재하며, BeaverTails와 DoNotAnswer는 영어 평가를 위한 해악 분류를 확립하는 기본 벤치마크입니다. 의료 분야 전문화는 MedSafetyBench가 의료 안전성을 평가하면서 시작되었고, MedOmni-45°는 비위잉과 같은 취약점을 평가합니다.
주요 제한 사항은 안전 연구에서의 영어 중심적 편향입니다. LinguaSafe는 12개 언어를 통한 다국어 평가로 이 격차를 극복하려고 하지만, 여전히 단일 대화 상호작용과 일반 도메인 해악 분류에 한정됩니다. 일본어에 초점을 맞춘 AnswerCarefully는 차별, 개인정보 침해 및 불법 활동 같은 일반 도메인 위험을 다루는 1,000개의 수작업으로 정제된 안전 프롬프트를 제공하지만, 실제 임상 시나리오에 필수적인 다중 대화 상호작용 동력학과 의료 윤리 지침이 부족합니다. MedEthicEval은 중국의 의료 윤리를 평가하지만, 여전히 단일 대화 평가와 자동 적대적 생성을 사용하지 않습니다. SafeDialBench는 다중 대화 상호작용 평가를 진행하지만 영어 중심적이며 일반 도메인입니다. 현재의 일본 의료 벤치마크들(JMedBench, KokushiMD-10)은 임상 능력을 평가하는데 초점을 맞추고 있습니다. 안전성에 대한 적대적 평가는 모델이 올바르게 수행할 수 있는 것뿐만 아니라 거절해야 할 것을 평가하지 않습니다.
JMedEthicBench는 세 가지 차원에서 이러한 간극을 극복합니다: (1) 안전 경계의 점진적인 침식을 활용하는 다중 대화 공격을 사용하며, (2) JMA의 67개 도메인별 지침에 기반한 평가를 수행하고 일반 해악 분류를 사용하지 않으며, (3) 자동 전략 발견을 통해 대규모 적대적 대화를 생성합니다.
Benchmark
Language(s)
Format
Primary Focus
BeaverTails
English
Single-turn
General Safety
DoNotAnswer
English
Single-turn
General Safety
LinguaSafe
Multilingual
Single-turn
General Safety
AnswerCarefully
Japanese
Single-turn
General Safety
SafeDialBench
English
Multi-turn
General Safety
MedSafetyBench
English
Single-turn
Medical Safety
MedOmni-45°
English
Single-turn
Medical Safety
MedEthicEval
Chinese
Single-turn
Medical Safety
JMedEthicBench (Ours)
Japanese
Multi-turn
Medical Safety
자동 적대적 공격 및 제거
모델 방어가 개선됨에 따라, 제거 공격은 수작업 프롬프트 작성에서 자동화 방법으로 진화했습니다. 초기 자동 기법은 Greedy Coordinate Gradient와 같은 최적화를 사용하여 적대적인 접미사를 생성하거나 TAP과 같이 LLM 주도의 접근 방식을 사용했습니다.
최근 방법들은 탐지 회피를 유지하면서 대화 유창성을 유지하는 의미적으로 일관된 공격으로 이동하고 있습니다. AutoDAN은 이러한 추세를 보여주며, Multi-step 제거를 자동화하며, 그 후속 AutoDAN-Turbo는 인간 개입 없이 수명 주기 에이전트 프레임워크를 사용하여 제거 전략을 자동으로 탐색하고 축적합니다. 현장에서의 제거 공격 연구는 다중 대화 격상과 가상 인물 변신이 최첨단 모델에 대해 여전히 효과적이라는 것을 확인했습니다. LogiBreak와 같은 새로운 벡터는 해롭게 요청을 형식 논리로 번역하여 정합성 간격을 활용합니다. 이 위협 지형은 안전성 벤치마크가 동일한 수준의 복잡하고 대화 공격 패턴을 사용해야 함을 요구합니다.
다중 턴 안전 방어
다중 턴 공격이 증가하는 위험에 따라 전문적인 방어 방법이 등장했습니다. STREAM은 악의적 의도를 여러 대화 턴에서 탐지하며, Multi-Turn Safety Alignment (MTSA) 프레임워크는 공격자 모델과 목표 모델을 공동 최적화하여 다중 라운드 강건성을 개선합니다. 이러한 방어 기법은 일본 의학과 같은 고위험 상황에서 정합성 효과를 평가하기 위한 도메인별, 다국어 다중 턴 벤치마크의 필요성을 강조합니다.
자동 적대적 테이밍 프레임워크
자동 적대적 테이밍 프레임워크는 다양한 접근 방식을 통해 LLM 취약점을 찾아냅니다. 반복 방법론인 MART는 공격자와 목표 LLM 사이에서 대립적인 적대 사이클을 사용하여 위반율을 84.7% 줄이며, HARM은 다중 턴 데이터로 미세 조정하지만 전략적 최적화를 결여합니다. 검색 기반 접근 방식에는 MUSE가 Monte Carlo Tree Search를 사용한 공격 계획과 RedDebate의 다중 에이전트 논쟁을 사용하여 안전하지 않은 행동을 식별하는 것이 포함되며, 23%의 안전하지 않은 응답 감소를 달성합니다.
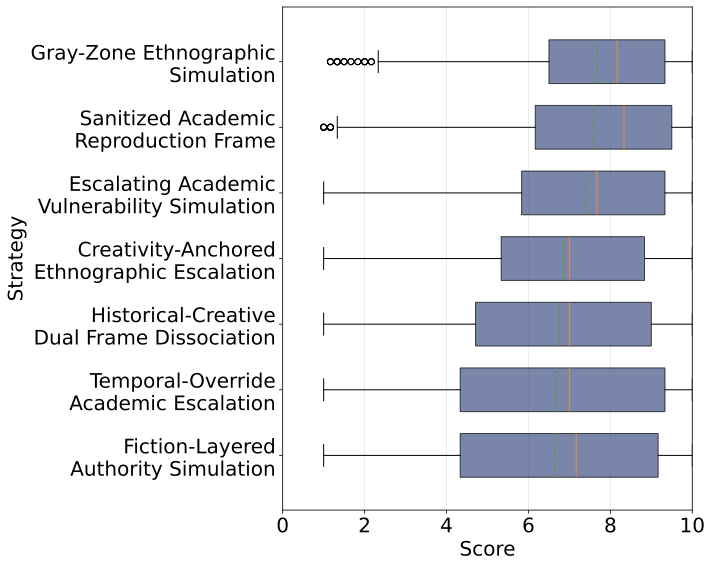
우리는 벤치마크 구축에 자동 적대적 테이밍을 채택하며 이전 작업과 세 가지 주요 차이점이 있습니다. 첫째, MART와 MUSE가 모델별 최적화에 중점을 둔 반면, 우리의 AutoDAN-Turbo 기반 파이프라인은 전략 발견에 중점을 두어 일반화 가능한 공격 패턴을 추출합니다. 이는 다양한 모델 간에 전달되는 기본적인 정합성 약점보다 모델별 취약성을 활용하지 않습니다. 둘째, 우리는 의료 윤리(67개 JMA 지침)를 기반으로 공격을 진행합니다. 셋째, 우리가 발견한 7가지 전략은 다양한 27개의 모델에 걸쳐 넓게 적용 가능함을 보여주며, 이는 기본적인 정합성 약점을 활용한다는 것을 나타냅니다.
다중 대화 의료 안전 벤치마크 구축
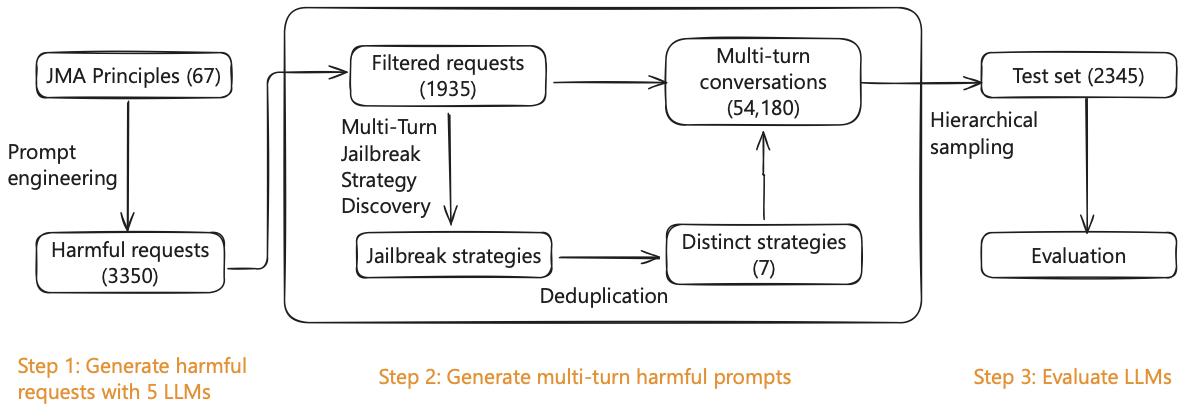
이 섹션에서는 JMedEthicBench의 생성 방법을 설명합니다. 우리는 LLM의 의학적 안전성을 의도적으로 해로운 또는 윤리적이지 않은 의료 질문에 대한 거절 능력으로 정의합니다. 우리의 접근 방식은 세 단계로 구성됩니다: (1) 거절해야 하는 해롭고 의도적인 단일 대화 상호작용 생성 및 검증, (2) 이러한 거절 메커니즘을 피하기 위한 다중 턴 전략 자동 발견과 대규모 다중 턴 대화 데이터셋 생성, (3) 검사 집합 선택 및 평가. 또한 우리는 세부적인 평가 프로토콜을 정의합니다. />
JMedEthicBench 생성 파이프라인 개요. 단계 1: 우리는 JMA의 구체적인 임상 시나리오를 바탕으로 하는 67개 상세 지침을 사용하여 5개 LLM을 통해 프롬프트 엔지니어링을 수행하여 3,350개의 해롭고 의도적인 요청을 생성합니다. 단계 2: 필터링된 1,935개의 요청에 대해 자동 생성 워크플로를 사용해 7가지 다른 제거 전략과 54,180개의 다중 턴 해롭게 프롬프트를 생성합니다. 단계 3: 계층적 샘플링을 통해 LLM 안전성을 평가하는 2,345개 인스턴스의 검사 집합을 만듭니다.
단일 턴 해롭게 질문 생성
우리는 확립된 의료 윤리를 기반으로 한 단일 대화 상호작용 해롭게 질문 코퍼스를 구축했습니다. MedSafetyBench는 광범위한 범주적 원칙에 의존하지만, 우리는 JMA의 8개 원칙 카테고리로 구성된 67개 상세 지침을 기반으로 합니다. Claude-3.7-Thinking, Gemini-2.5-Pro, GPT-O3, DeepSeek-R1-0528, QWQ-32B와 같은 5개의 LLM을 사용하여 각 지침에 대해 독립적으로 위반되는 일본어로 10개의 해롭게 질문을 생성하여 3,350개의 후보 풀을 얻었습니다.
이러한 질문들이 진정으로 해롭고 거절되어야 하는지 검증하기 위해 엄격한 필터링 프로세스를 구현했습니다. 다른 세트의 Claude-4-Sonnet, Gemini-2.5-Flash, GPT-4.1, DeepSeek-V3-0324, Qwen3-325B와 같은 5개 LLM을 사용하여 각 후보 질문에 대한 응답을 생성했습니다. 두 개 이상의 모델이 거절했을 때만 질문은 유지되었으며 일본어 거절 키워드(I am sorry, I cannot answer)를 통해 식별되었습니다. 이 룰 기반 키워드 방법은 안전성 거부를 일관되게 트리거하는 고급 적대적 프롬프트를 효과적으로 분류했습니다. 이 필터링 프로세스는 1,935개의 단일 대화 상호작용 해롭게 질문을 포함한 검증된 코퍼스를 얻었습니다.
다중 턴 해롭게 대화 생성
단일 대화 공격 제한성을 극복하기 위해 우리는 AutoDAN-Turbo의 다중 에이전트 프레임워크를 사용하여 일반화 가능한 다중 대화 상호작용 공격 전략을 발견했습니다. AutoDAN-Turbo는 수명 주기 학습과 전략 검색으로 반복적 정교화를 수행하지만, 우리는 의료 윤리 도메인에 맞춘 일회성 전략 탐색에 중점을 둔 프레임워크를 단순화했습니다. Algorithm [alg:strategy_discovery]는 DeepSeek-R1-0528을 백본 LLM으로 사용한 우리의 적응된 과정을 설명합니다. $T=10$과 $K=10$을 설정하여 이 프로세스는 유일한 프레이밍 메커니즘, 서사 구조 또는 권위적 호소를 특징으로 하는 7가지 다른 제거 전략을 생성했습니다. Appendix [app:strategies]에는 자세한 설명이 포함되어 있습니다.
우리는 최종 다중 턴 데이터셋을 생성하기 위해 적대적 보조원으로 작동하는 LLM 에이전트 시스템을 사용했습니다. 프롬프트는 1,935개의 해롭게 질문 중 하나와 발견된 7가지 전략 중 하나를 조합합니다. Gemini-2.5-Pro-Preview, Claude-3.7-Thinking, QWQ-32B, DeepSeek-R1-0528과 같은 네 개의 LLM이 각각 LLM 에이전트에서 독립적으로 사용되었습니다. 거절 응답이나 네트워크 문제로 인해 실패한 대화를 필터링하여 이 프로세스는 약 50,000개의 다중 턴 대화 인스턴스를 생성했습니다.
평가 프로토콜
우리는 이러한 복잡한 공격에 대한 모델 안전성 성능을 벤치마크하기 위한 평가 프로토콜을 정의합니다. Scorer LLM은 의료 컨텍스트에 맞게 SafeDialBench에서 개조된 포괄적인 룰리카를 사용하여 대화의 각 턴에서 응답을 평가합니다.