- Title: Adversarial Instance Generation and Robust Training for Neural Combinatorial Optimization with Multiple Objectives
- ArXiv ID: 2601.01665
- 발행일: 2026-01-04
- 저자: Wei Liu, Yaoxin Wu, Yingqian Zhang, Thomas Bäck, Yingjie Fan
📝 초록
본 논문에서는 다목적 조합 최적화 문제(MOCOP)를 해결하는 강화학습 기반의 신경망 모델에 대한 강인성을 향상시키는 새로운 접근법을 제안한다. 이를 위해 선호도 기반 적대적 공격(PAA) 방법과 동적인 선호도 증강 방어(DPD) 방법을 소개한다. PAA는 특정 선호도에 맞춘 어려운 인스턴스를 생성하여 신경망 모델의 성능을 저하시키며, DPD는 적대적 공격으로부터 신경망 모델을 보호하고 그 강인성을 향상시킨다. 이러한 방법들은 다목적 트래블링 세일즈맨 문제(MOTSP), 다목적 용량 제약 차량 경로 문제(MOCVRP), 그리고 다목적 배낭 문제(MOKP)에서 우수한 성능을 보여준다.
💡 논문 해설
1. **선호도 기반 적대적 공격 (PAA)**: 이 방법은 특정 선호도에 맞춰 어려운 문제를 생성하여 신경망 모델의 성능을 저하시키는 방식입니다. 이를 통해 우리는 신경망 모델이 다양한 상황에서 얼마나 잘 작동하는지 평가할 수 있습니다.
비교적 쉬운 이해: PAA는 마치 학생에게 어려운 시험 문제를 내어 그의 진정한 실력을 측정하듯, 신경망 모델에 어려운 인스턴스를 주어 성능을 평가합니다.
중간 수준 이해: PAA는 특정 선호도 조건 하에서 강화학습 기반의 신경망 모델이 어떻게 작동하는지를 알아내기 위해, 해당 선호도에 맞춘 어려운 문제를 생성하고 이를 통해 모델의 성능을 저하시킵니다.
고급 이해: PAA는 특정 선호도 조건 하에서 다목적 조합 최적화 문제(MOCOP)를 해결하는 강화학습 기반 신경망 모델에 대한 적대적 공격을 수행하며, 이는 모델의 성능 저하를 통해 그 강인성을 평가합니다.
동적인 선호도 증강 방어 (DPD): DPD는 PAA로 인한 성능 저하를 완화시키고 신경망 모델의 강인성을 향상시킵니다.
비교적 쉬운 이해: DPD는 마치 학생이 어려운 시험 문제에 대응할 수 있도록 추가적인 연습을 제공하는 것처럼, 신경망 모델이 다양한 상황에서 잘 작동하도록 보호합니다.
중간 수준 이해: DPD는 PAA로 인해 저하된 성능을 회복하고, 특정 선호도 조건 하에서 강화학습 기반의 신경망 모델의 강인성을 향상시키기 위해 디자인되었습니다.
고급 이해: DPD는 적대적 공격에 대응하기 위한 보완적인 전략으로, 특정 선호도 조건 하에서 다목적 조합 최적화 문제(MOCOP)를 해결하는 강화학습 기반 신경망 모델의 성능 저하를 완화시키고 강인성을 향상시킵니다.
실험 결과: 본 논문에서는 PAA와 DPD 방법을 MOTSP, MOCVRP, 그리고 MOKP에 적용하여 실험한 결과를 보여줍니다.
비교적 쉬운 이해: 실험은 마치 학생들이 다양한 시험 문제들을 풀어보며 자신의 실력을 확인하는 것처럼, 신경망 모델이 다양한 MOCOP 인스턴스에서 어떻게 작동하는지를 평가합니다.
중간 수준 이해: 본 논문에서는 PAA와 DPD 방법을 다목적 트래블링 세일맨 문제(MOTSP), 다목적 용량 제약 차량 경로 문제(MOCVRP), 그리고 다목적 배낭 문제(MOKP)에 적용하여 신경망 모델의 성능과 강인성을 평가합니다.
고급 이해: 본 논문에서는 PAA와 DPD 방법을 다양한 MOCOP 인스턴스, 즉 MOTSP, MOCVRP, 그리고 MOKP에 적용한 결과를 보여줍니다. 이를 통해 신경망 모델의 성능 저하를 확인하고, 적대적 공격에 대한 강인성을 향상시키는 방법을 제시합니다.
📄 논문 발췌 (ArXiv Source)
적대적 공격 ,강건 최적화 ,신경망 조합 최적화, 강화학습
# 서론
다목적 조합 최적화 문제(MOCOPs)는 컴퓨터 과학과 연산 연구에서 광범위하게 연구되어 왔으며, 교통 스케줄링, 특성 선택, 에너지 계획, 통신 네트워크 최적화 등 다양한 실제 응용 분야에 나타납니다. 단일 목표 최적화와 달리 MOCOPs는 여러 충돌하는 목적을 포함하며 따라서 Pareto-최적 솔루션 집합, 즉 Pareto 집합을 식별하려고 합니다. 좋은 Pareto 집합 근사치는 수렴성과 다양성을 동시에 달성해야 합니다. 조합 최적화의 본질적인 NP-난해성과 다중 목표의 존재로 인해 대부분의 MOCOPs는 실용적으로 해결하기 어렵습니다.
전통적인 방법, 정확한 알고리즘 및 휴리스틱 알고리즘을 포함하여, 이러한 방법들은 오랫동안 근사 Pareto 집합을 얻는데 경쟁력을 갖춘 성능을 보여왔지만, 일반적으로 도메인 특화 지식이나 대규모 반복 탐색이 필요합니다. 대신, 딥 강화학습(DRL)은 MOCOPs를 해결하는 혁신적인 접근 방식으로 부상했습니다. 감독 학습과 달리 DRL은 레이블 데이터 집합에 대한 의존성을 제거합니다. 또한, 휴리스틱 및 정확한 알고리즘과 비교하여 DRL은 합리적인 계산 시간 내에서 근사 최적해를 식별하는 효율성이 우수합니다.
그러나 이러한 장점에도 불구하고, MOCOPs의 DRL 솔버에 대한 강인성은 여전히 상당히 연구되지 않았습니다. 단일 목표 조합 최적화 문제에서는 이전 연구들이 이미 비-i.i.d. 분포에서 추출된 인스턴스를 사용하여 실험을 수행하고 수정된 학습 절차 및 세밀한 모델 아키텍처와 같은 완화 전략을 제안했습니다. 훈련 및 테스트 분포가 벌어지면, DRL 모델은 MOCOP 시나리오에서 분포 외 인스턴스에 대한 성능이 크게 저하될 수 있으며, 이는 가짜, 분포 특정 신호에 대한 과적합 현상 때문일 수 있습니다. 이를 해결하기 위해 본 연구에서는 MOCOPs의 DRL 솔버를 위한 분포 외 일반화 능력을 향상시키는 작업을 수행합니다.
본 논문에서는 이러한 설정을 위한 강인성 지향 프레임워크를 제안합니다. 기존 신경망 접근법이 주로 분포 내 성능에 초점을 맞추는 것과 달리, 우리는 분포 변화와 선호도 조건화가 DRL 솔버의 성능에 어떻게 영향을 미치는지 체계적으로 평가합니다. 또한, 적대적 인스턴스 생성 및 강건한 학습 전략을 도입하여 다양한 인스턴스 분포에서 일반화를 개선합니다. 우리의 주요 기여는 다음과 같습니다:
우리는 DRL 모델에 대한 선호도 기반 적대적 공격(PAA) 방법을 제안합니다. PAA는 특정 선호도와 관련된 하위 문제의 솔루션 품질을 저하시키는 어려운 인스턴스를 생성하여 DRL 모델을 약화시킵니다. 생성된 인스턴스는 Pareto 앞면의 hypervolume 측면에서 품질을 크게 떨어뜨립니다.
우리는 적대적 공격의 영향을 완화하기 위해 동적인 선호도 증강 방어(DPD) 방법을 제안합니다. DPD는 적대 학습에 하드니스 인식 선호도 선택 전략을 통합함으로써 제한된 선호도 공간에 대한 과적합을 효과적으로 완화시킵니다. 이를 통해 DRL 모델의 강인성을 향상시키고 다양한 분포에서 일반화 능력을 증진시킵니다.
우리는 우리의 방법들을 세 가지 고전적인 MOCOPs, 다목적 여행 상인 문제(MOTSP), 다목적 용량 제약 차량 경로 문제(MOCVRP), 그리고 다목적 배낭 문제(MOKP)에서 평가합니다. PAA 방법은 최신 DRL 모델의 성능을 크게 저하시키지만, DPD 방법은 그들의 강인성을 향상시켜 강력한 분포 외 일반화 능력을 제공합니다.
관련 연구
MOCOP 솔버
MOCOP 솔버는 주로 정확한 알고리즘, 휴리스틱 알고리즘 및 학습 기반 방법으로 구분됩니다. 정확한 알고리즘은 Pareto-최적 해를 제공하지만, 대규모 문제에 대해 계산적으로 해결이 불가능합니다. 휴리스틱 방법, 특히 진화 알고리즘을 통해 솔루션 공간을 효과적으로 탐색하며, 수용 가능한 시간 내에 근사 Pareto 해의 유한 집합을 생성합니다. 그러나 이들의 문제 특성에 대한 의존성 및 손으로 작성된 설계는 적용 범위를 제한합니다.
학습 기반 솔버, 특히 딥 강화 학습을 기반으로 한 것은 MOCOPs에서 높은 성능과 효율성을 보여주면서 점점 더 많이 채택되고 있습니다. 현재 DRL 솔버에 대한 연구는 주로 일대일 및 다대일이라는 두 가지 패러다임에 속합니다. 일대일 패러다임에서는 각 하위 문제를 개별적인 신경망 해결책으로 처리합니다. 반면, 다대일 패러다임은 여러 하위 문제를 하나의 공유 신경망 해결책을 사용하여 처리함으로써 계산 과정을 간소화하고 일대일 패러다임보다 우수한 성능을 보여주며 최신 수준의 신경망 솔버를 제공합니다. 그 중 효율적인 메타 네트워크 휴리스틱(EMNH)은 각 선호도에 대해 빠르게 적응하여 하위 문제를 해결하는 메타 모델을 학습합니다. 선호도 조건화 다목적 조합 최적화(PMOCO)는 각 하위 문제에 맞는 디코더 매개변수를 생성하기 위해 하이퍼네트워크를 사용합니다. 조건부 네트워크 휴리스틱(CNH)은 이중 주의력을 활용하고, 조건부 주의력과 특성별 아핀 변환을 사용하는 가중치 임베딩 모델(WE-CA)은 인코더 내에서 선호도-인스턴스 상호 작용을 강화합니다. 우리의 연구는 제안된 공격 및 방어 프레임워크가 세 가지 범주 모두의 모델에 도전하고 강인성을 향상시키는 데 충분히 일반적임을 보여줍니다.
DRL 모델의 COPs 강인성
COPs의 강인성은 이론적 및 신경망 관점에서 연구되었습니다. 이론적으로, Varma 등은 최소자르기와 최대매칭과 같은 고전적인 COPs에서 엣지 삭제에 대한 알고리즘 출력의 안정성을 측정하기 위해 평균 민감도를 도입했습니다. 신경망 관점에서는 여러 연구가 어려운 인스턴스 생성 및 방어 방법을 통해 DRL 솔버의 강인성을 개선하기 위한 시도를 진행하였습니다. 예를 들어, Geisler 등은 TSP 인스턴스에 노드를 적대적으로 삽입하여 예측 경로와 최적 해 사이의 편차를 극대화하는 효율적이고 합리적인 변동 모델을 제안했습니다. Zhang 등은 주어진 인스턴스의 어려움을 평가하고 해결자의 상대적인 난이도에 따라 훈련 중에 어려운 인스턴스를 생성하는 어려움 적응형 커리큘럼 학습 방법(HAC)을 개발했습니다. Lu 등은 부분 문제의 비용을 줄임으로써 최적 비용 보장(즉, 나빠지지 않음)을 도입하고 그래프에서 엣지를 수정하여 적대적 인스턴스를 생성하였습니다. 이러한 접근법이 어려운 인스턴스 생성에 초점을 맞춘 것과는 달리, Zhou 등은 신경망 COP 솔버의 방어에 중점을 둔 앙상블 기반 협업 신경망 프레임워크를 제안해 청정 및 어려운 인스턴스에서 동시에 성능을 향상시켰습니다.
여기서 $`\mathcal{X}`$는 모든 가능한 솔루션 집합을 나타내고,
$`F(\pi)`$는 목표 값 벡터입니다. MOCOP의 솔루션은 문제에 지정된 제약 조건을 모두 충족하는 경우만 가능합니다. 예를 들어, MOTSP는 노드 집합 $`V = \{0, 1, 2, \dots, n\}`$가 있는 그래프 $`G`$에서 정의됩니다. 각 솔루션은 길이 $`T`$의 노드 시퀀스인 투어 $`\pi = (\pi_1, \pi_2, \dots, \pi_T)`$입니다.
다목적 최적화 문제에서는 모든 목표를 동시에 최적화하는 Pareto-최적 솔루션을 찾는 것이 목표입니다. 이러한 Pareto-최적 해는 다양한 목표에 대한 선호도를 균형 있게 조정하려고 합니다. 본 논문에서 우리는 다음과 같은 Pareto 개념을 사용합니다:
정의 1 (Pareto 우위). $`u, v \in \mathcal{X}`$라고 하자. 솔루션 $`u`$는 솔루션 $`v`$를 지배한다고 정의되며 ($`u \prec v`$) 모든 목표 $`i \in \{1, \dots, m\}`$에 대해 $`f_i(u)`$가 $`f_i(v)`$보다 작거나 같고 적어도 하나의 목표 $`j \in \{1, \dots, m\}`$에 대해 $`f_j(u) < f_j(v)`$인 경우만 가능합니다.
정의 2 (Pareto 최적). 솔루션 $`x^* \in \mathcal{X}`$는 다른 모든 솔루션 $`\mathcal{X}`$에 의해 지배받지 않는 경우 Pareto 최적이며, 즉 $`x' \prec x^*`$와 같은 해결책이 존재하지 않음. 모든 Pareto-최적 해의 집합은 Pareto 집합 $`\mathcal{P} = \{x^* \in \mathcal{X} \mid \nexists x' \in \mathcal{X} \text{ such that } x' \prec x^*\}`$라고 불립니다. Pareto 집합의 투영은 Pareto 앞면 $`\mathcal{PF} = \{F(x) \mid x \in \mathcal{P}\}`$를 형성합니다.
분해
다목적 COP을 다양한 선호도 하에서 단일 목표 문제 시리즈로 스칼라화하는 분해는 DRL 모델의 MOCOP Pareto 앞면을 얻기 위한 효과적인 전략입니다. 선호도 벡터 $`\lambda = (\lambda_1, \lambda_2, \dots, \lambda_m) \in \mathbb{R}^m`$와 $`\lambda_i \geq 0`$, 그리고 $`\sum_{i=1}^m \lambda_i = 1`$를 주면, 가중 합(WS) 및 Tchebycheff 분해(TCH)는 MOCOP을 스칼라화 하위 문제로 변환하여 Pareto 앞면을 근사합니다.
WS 분해. WS 분해는 선호도 벡터 아래의 $`m`$ 목표 함수들의 볼록 결합을 최소화합니다:
분해 전략은 다양한 선호도 하에서 부분 문제 시리즈로 MOCOP을 축소함으로써 이를 해결합니다. 주어진 인스턴스 $`x`$와 선호도 $`\lambda`$, 신경망 기반의 MOCOP 솔버는 Pareto 해를 근사하는 확률 정책 $`p_\theta`$를 학습하여 $`\pi = (\pi_1, \pi_2, \dots, \pi_T)`$를 근사합니다. 여기서 $`\theta`$는 학습 가능한 매개변수입니다.
DRL 솔버의 강인성에 대한 조망
가우시안 혼합 생성기에서 $`c_{\text{DIST}}`$ 값이 변하는 결과.
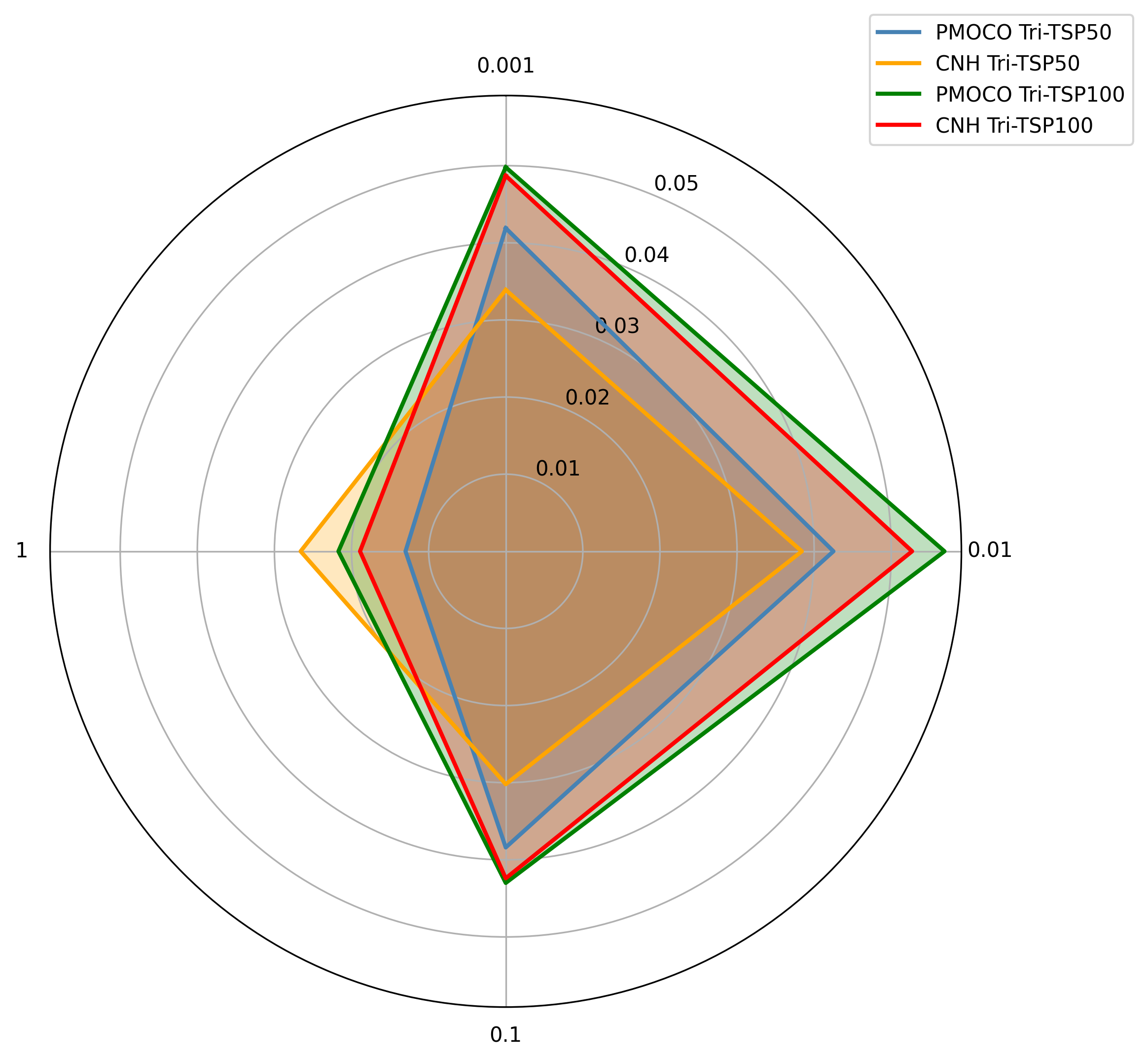
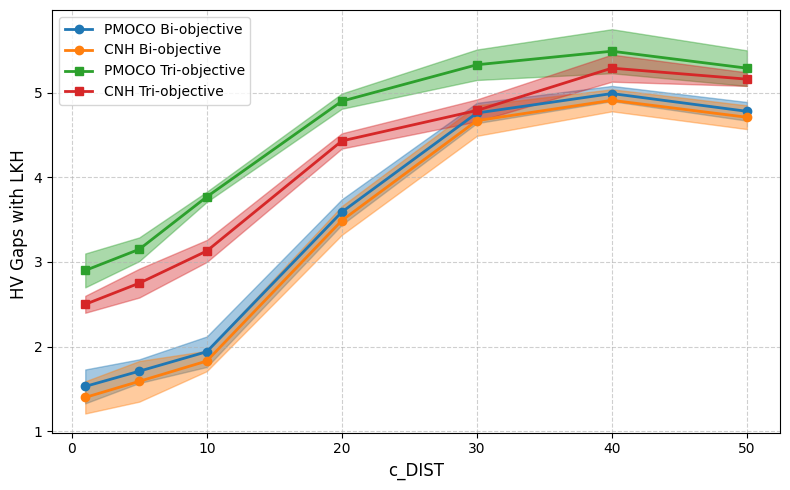
DRL 모델에 대한 MOCOP의 강인성이 아직 연구되지 않은 상태인 것을 고려해, 우리는 두 가지 대표적인 신경망 솔버인 PMOCO와 CNH를 MOTSP에 대해 평가했습니다. 이들 솔버는 50 노드의 단일/다중 목표 TSP 인스턴스(원래 논문과 동일한 설정)에서 사전 훈련되었습니다.
구체적으로, 우리는 가우시안 혼합 모델(GMM) 생성기를 사용하여 분포 외 검증 인스턴스를 생성했습니다. $`c_{\text{DIST}} \in \{1, 5, 10, 20, 30, 40, 50\}`$을 변경하여 $`c_{\text{DIST}}`$가 클러스터의 공간적 확산을 제어하고 인스턴스의 어려움을 결정합니다. WS-LKH(다목적 최적화 문제(MOCOPs)를 해결하는 최신 솔버)는 비교 기준으로 사용되었습니다.
Figure 1은 솔루션 간의 차이를 나타내는 hypervolume gap을 보여줍니다:
우리의 결과는 $`c_{\text{DIST}}`$가 증가함에 따라(더 어려운 테스트 인스턴스를 나타냄) 신경망 솔버의 성능이 저하되고 그들의 해와 WS-LKH의 해 사이의 격차가 넓어짐을 보여줍니다. 이러한 결과는 신경망 솔버들이 일정하게 분포된 인스턴스에서 훈련되었음에도 불구하고, 검증 인스턴스가 더 다양하고 복잡해질수록 강인성을 유지하는 데 어려움이 있다는 중요한 한계를 보여줍니다.
방법
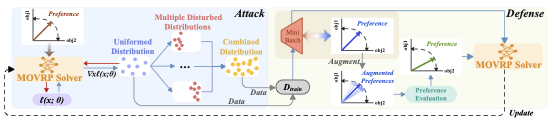
본 절에서는 신경망 솔버의 강인성에 대한 선호도 기반 적대적 공격(PAA) 방법을 소개하며, 이를 통해 어려운 인스턴스를 생성합니다. 또한, 동적인 선호도 증강 방어(DPD) 방법을 제안하여 신경망 솔버의 강인성을 향상시킵니다. 제안된 적대적 공격 및 방어 방법의 개요는 Figure 2에 나타나 있습니다.
선호도 기반 적대적 공격 (PAA)
일반적으로 신경망 솔버는 다양한 선호도 하에서 MOCOP을 부분 문제 시리즈로 분해하고, 각각의 부분 문제를 독립적으로 해결합니다. 만약 신경망 솔버가 특정 선호도 $`\lambda`$ 아래에서 부분 문제([eq:Tchebycheff])를 잘 해결할 수 있다면, 전체 Pareto 앞면에 대한 좋은 근사를 생성할 수 있습니다. 본 논문에서는 특정 $`\lambda`$ 값을 가질 때 신경 모델이 부분 문제의 해를 효과적으로 근사하지 못하면, 결과적으로 Pareto 앞면의 근사가 부적절하다는 가설을 제시합니다. 이러한 착안에서 MOCOPs에 대한 신경망 솔버를 공격하기 위한 PAA 방법을 제안합니다. 특히, 원래 데이터(즉, 깨끗한 인스턴스)에 따라 선호도별로 특화된 페르테브레이션을 적용하여 각각의 지정된 선호도와 맞춤된 어려운 인스턴스를 생성합니다. 다양한 선호도에 걸친 어려운 인스턴스를 식별한 후, 이를 종합적인 세트로 수집하고 신경망 솔버의 강인성을 체계적으로 저하시키는 데 사용합니다.
style="width:100.0%" />
MOCOP을 위한 신경망 솔버의 공격 및 방어.
일반성을 잃지 않고, 우리는 특정 선호도에 맞춘 어려운 인스턴스를 생성하여 각 부분 문제에서 신경망 솔버의 성능을 평가합니다. 이를 위해 다음과 같은 강화 학습 손실 변형을 최대화하는 방식으로 공격을 수행합니다:
여기서 $`L(\pi \mid x)`$는 주어진 선호도 $`\lambda`$에 대한 부분 문제의 손실을 나타내며(예를 들어, Tchebycheff 분해로 Eq. ([eq:Tchebycheff])에 따라 계산됩니다). $`b(x)`$는 $`L(\pi \mid x)`$의 기준이며, $`b(x) = \frac{1}{M} \sum_{j=1