대규모 언어 모델을 활용한 범주형 데이터 클러스터링의 의미 격차 해소
📝 원문 정보
- Title: Bridging the Semantic Gap for Categorical Data Clustering via Large Language Models
- ArXiv ID: 2601.01162
- 발행일: 2026-01-03
- 저자: Zihua Yang, Xin Liao, Yiqun Zhang, Yiu-ming Cheung
📝 초록 (Abstract)
범주형 데이터는 의료, 마케팅, 바이오인포매틱스 등 다양한 분야에서 흔히 나타나며, 클러스터링은 패턴 탐색의 핵심 도구이다. 그러나 범주형 속성값은 자연스러운 순서나 거리 개념이 없어 기존 방법은 값들을 동일 거리로 취급하게 되고, 이는 의미적 차이를 반영하지 못하는 ‘의미 격차’를 만든다. 기존 연구는 데이터 내 동시 출현 빈도로 값 간 관계를 추정하지만, 표본이 부족할 경우 신뢰도가 떨어진다. 본 논문은 외부 지식원인 대규모 언어 모델(LLM)을 이용해 속성값을 서술형으로 변환하고, 이를 임베딩화하여 원본 데이터와 결합함으로써 의미‑인식 표현을 만든다. 제안 기법 ARISE(Attention‑weighted Representation with Integrated Semantic Embeddings)는 LLM‑강화 임베딩과 원본 카테고리 데이터를 통합해 의미적으로 두드러진 클러스터를 탐색한다. 8개의 벤치마크 데이터셋에서 7개의 기존 방법과 비교했을 때 19~27%의 성능 향상을 기록하였다.💡 논문 핵심 해설 (Deep Analysis)
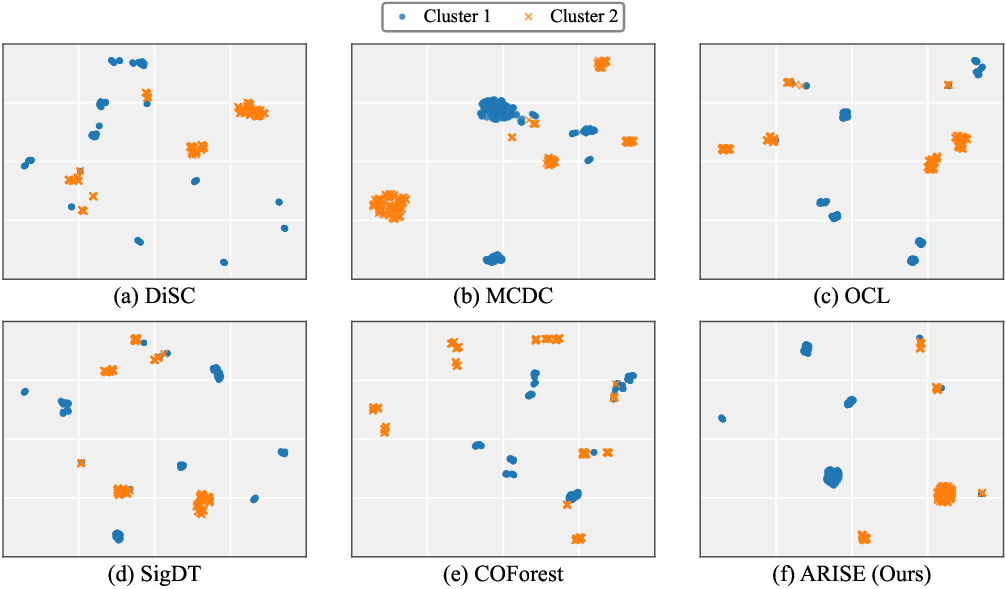
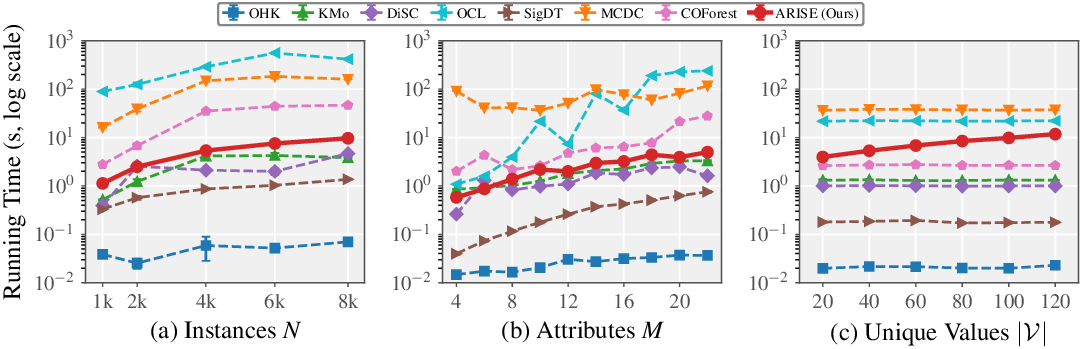
실험 결과는 8개의 다양한 도메인(의료 기록, 마케팅 설문, 유전형 데이터 등)에서 일관된 성능 향상을 보여준다. 특히 표본 수가 제한된 상황에서 기존 방법이 과도하게 균등 거리를 가정해 군집을 왜곡하는 반면, ARISE는 외부 지식 덕분에 의미적 구조를 보존한다는 점이 눈에 띈다. 그러나 몇 가지 한계도 존재한다. 첫째, LLM 호출 비용과 응답 지연이 실시간 혹은 대규모 배치 처리에 부담이 될 수 있다. 둘째, LLM이 제공하는 설명이 데이터 도메인에 특화되지 않을 경우, 의미 임베딩이 오히려 잡음이 될 위험이 있다. 셋째, 현재는 사전 학습된 일반 LLM(GPT‑3.5 등)을 사용했는데, 도메인‑특화 LLM이나 프롬프트 엔지니어링을 통해 더 정교한 의미 추출이 가능할 것으로 보인다. 향후 연구 방향으로는 (1) 비용 효율적인 임베딩 추출을 위한 모델 경량화, (2) 도메인 적응형 프롬프트 설계, (3) 의미 임베딩과 전통적 거리 측정의 다중‑목표 최적화, (4) 클러스터링 결과에 대한 해석 가능성 강화 등을 제시한다. 전반적으로 ARISE는 외부 의미 지식을 클러스터링 파이프라인에 자연스럽게 통합함으로써, 범주형 데이터 분석의 새로운 패러다임을 제시한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리