다양한 이미지 분류·검출 과제에 맞춘 CNN 설계 진화: 맞춤형 모델에서 딥 레지듀얼까지
📝 원문 정보
- Title: Evolving CNN Architectures: From Custom Designs to Deep Residual Models for Diverse Image Classification and Detection Tasks
- ArXiv ID: 2601.01099
- 발행일: 2026-01-03
- 저자: Mahmudul Hasan, Mabsur Fatin Bin Hossain
📝 초록 (Abstract)
** 본 논문은 다섯 개의 실제 이미지 데이터셋을 대상으로 맞춤형 합성곱 신경망(CNN) 구조와 널리 사용되는 사전학습 및 전이학습 CNN 모델을 비교 분석한다. 데이터셋은 이진 분류, 미세한 차이를 구분하는 다중 클래스 인식, 객체 검출 시나리오를 포함한다. 네트워크 깊이, 레지듀얼 연결, 특징 추출 전략 등 구조적 요인이 분류 및 위치 추정 성능에 미치는 영향을 조사한다. 실험 결과, 미세한 차이를 구분해야 하는 다중 클래스 데이터셋에서는 깊은 CNN이 큰 성능 향상을 보이는 반면, 단순 이진 분류 과제에서는 경량 사전학습·전이학습 모델이 여전히 높은 효율성을 유지한다. 또한 제안된 구조를 객체 검출에 적용하여 실제 교통 현장에서 무단 운행 중인 오토리키시를 식별하는 데 성공하였다. 맞춤형 CNN과 사전학습·전이학습 모델을 체계적으로 분석함으로써, 과제 복잡도와 자원 제약에 따라 적절한 네트워크 설계를 선택할 수 있는 실용적인 가이드를 제공한다.**
💡 논문 핵심 해설 (Deep Analysis)
이 연구는 현재 딥러닝 기반 이미지 분석에서 흔히 마주치는 두 가지 질문—“복잡한 과제에 맞는 최적의 네트워크는 무엇인가?”와 “제한된 연산·메모리 환경에서 어느 정도의 성능을 기대할 수 있는가?”—에 대한 실증적 답을 제시한다.
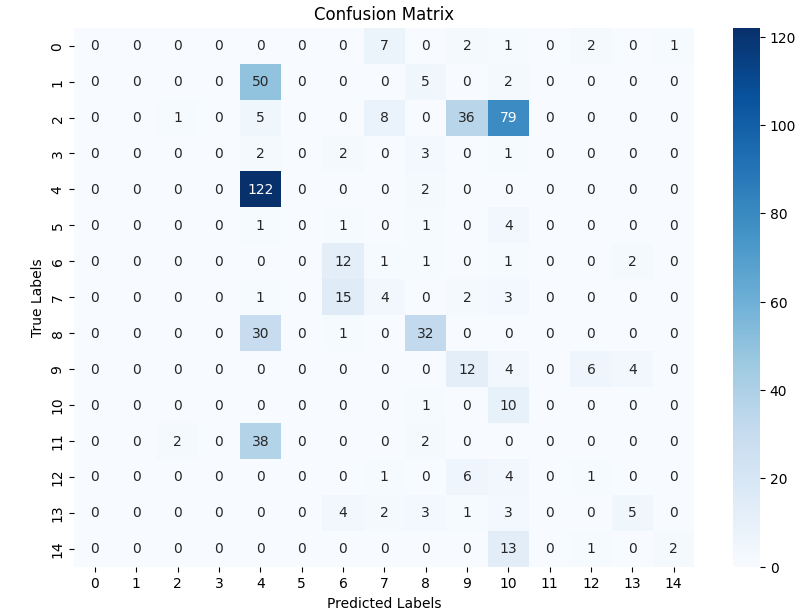
첫째, 데이터셋 구성이 매우 다양하다. 이진 분류 데이터셋은 일반적으로 클래스 간 차이가 크고, 라벨링 비용이 낮으며, 학습에 필요한 샘플 수가 비교적 적다. 반면, 미세한 차이를 구분해야 하는 다중 클래스 데이터셋(예: 품종 구분, 차량 모델 식별 등)은 클래스 간 시각적 차이가 미묘하고, 높은 해상도와 풍부한 특징이 요구된다. 마지막으로 객체 검출 데이터셋은 이미지 내에서 물체의 위치와 경계 상자를 동시에 예측해야 하므로, 분류보다 더 복합적인 손실 함수와 멀티스케일 특징 융합이 필요하다.
둘째, 모델군은 크게 세 가지로 나뉜다. (1) 맞춤형 CNN은 연구자가 직접 레이어 수, 필터 크기, 풀링 전략 등을 설계한 구조이며, 실험에서는 5~12개의 컨볼루션 레이어와 선택적 배치 정규화, 드롭아웃을 적용했다. (2) 사전학습(pre‑trained) 모델은 ImageNet 등 대규모 데이터셋으로 미리 학습된 VGG, ResNet, MobileNet 등이며, 여기서는 파라미터 고정 혹은 전체 파인튜닝 두 방식을 비교했다. (3) 전이학습(transfer learning) 모델은 사전학습 모델의 특징 추출기 부분을 고정하고, 마지막 분류 헤드만 새로운 데이터에 맞게 재학습하는 방식이다.
세 모델군을 동일한 학습 프로토콜(동일 옵티마이저, 학습률 스케줄, 데이터 증강) 하에 평가함으로써, 구조적 차이가 성능에 미치는 순수한 영향을 측정할 수 있었다. 결과는 다음과 같다.
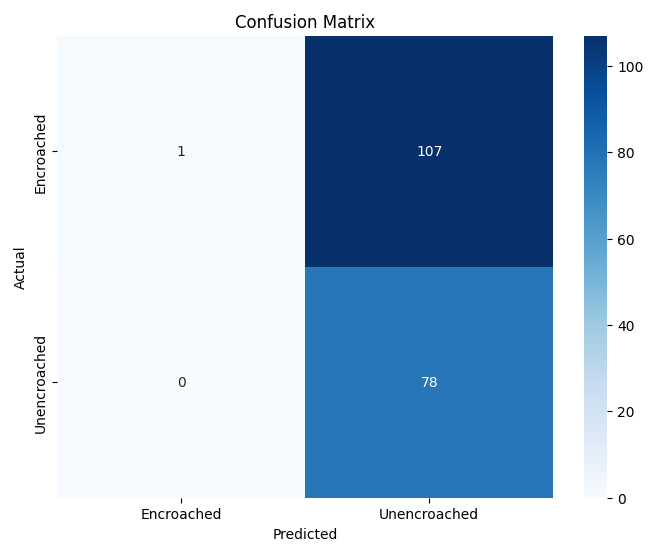
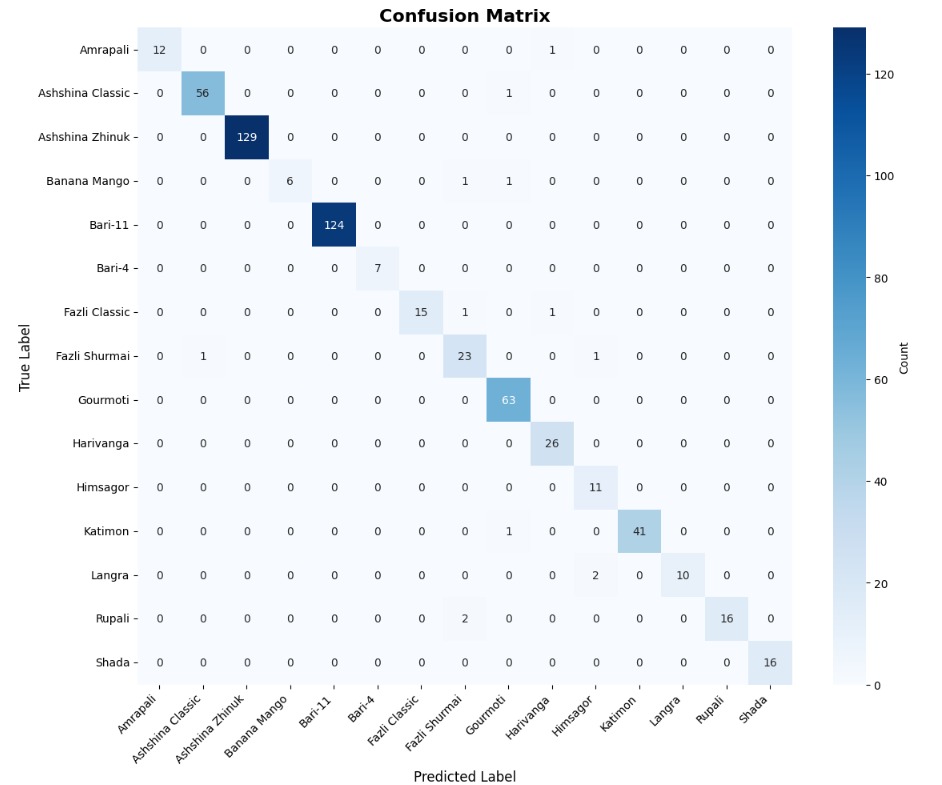
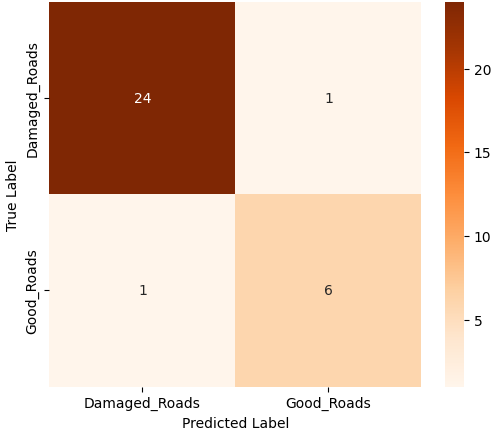
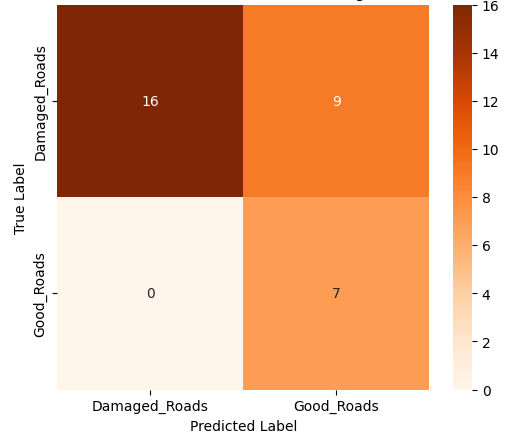
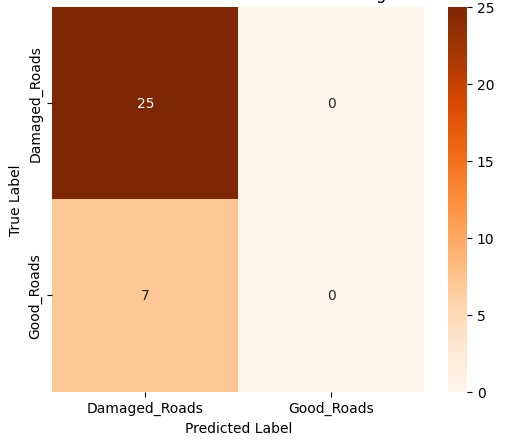
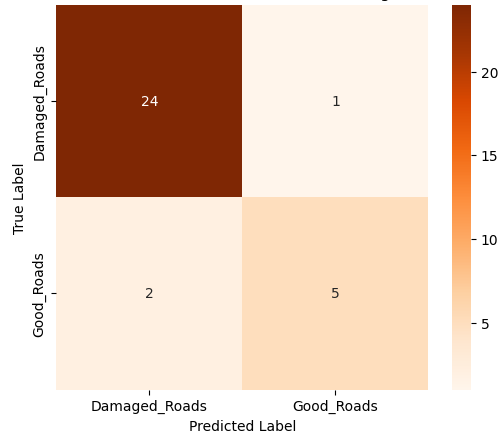
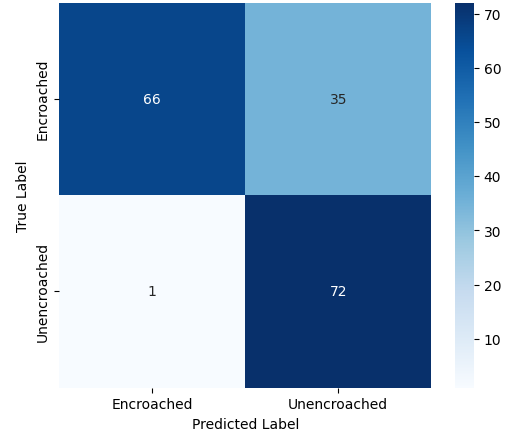
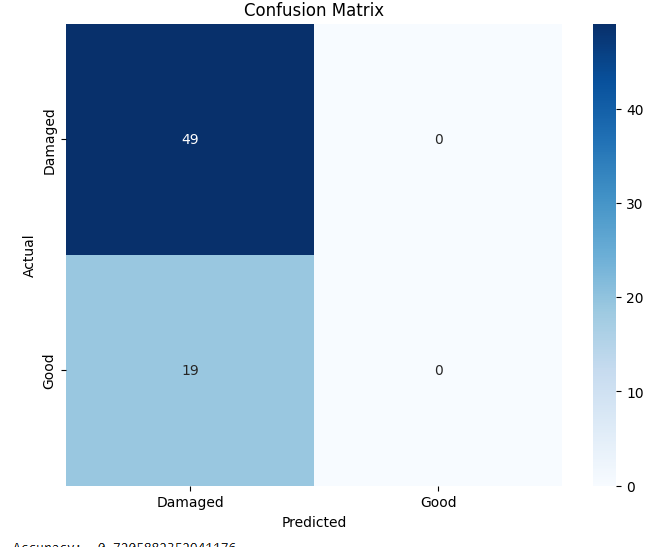
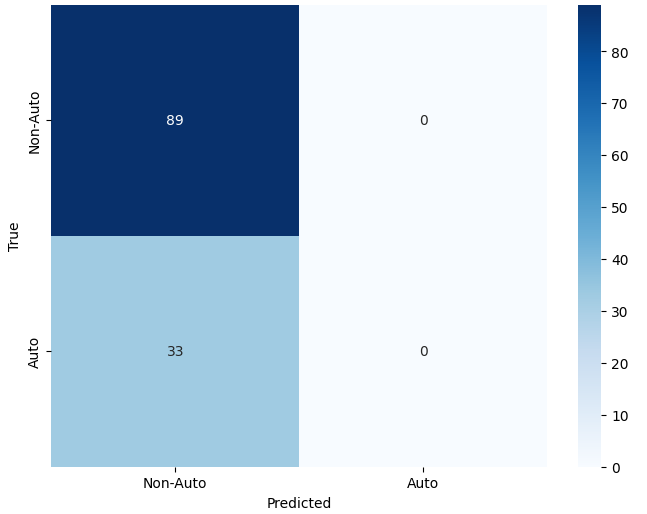
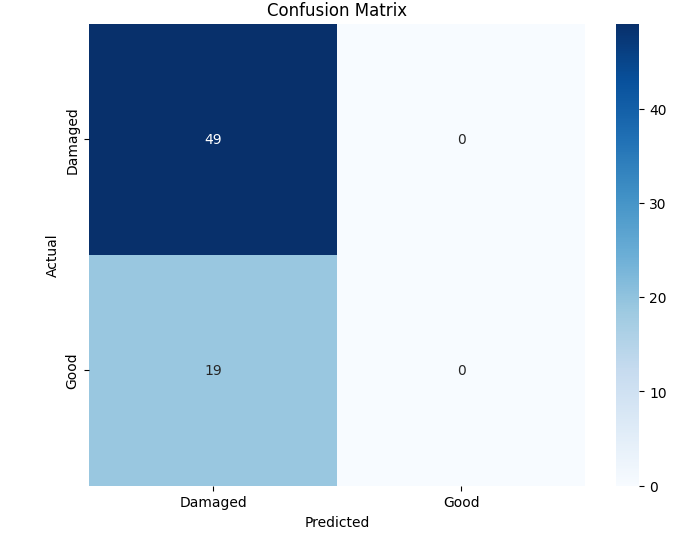
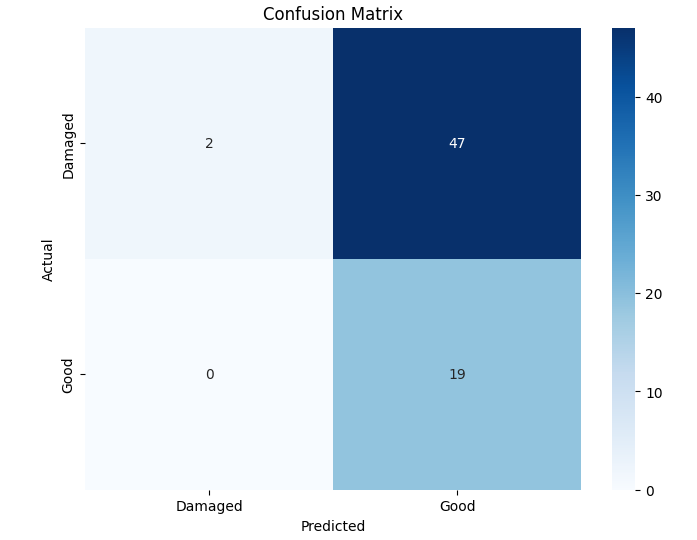
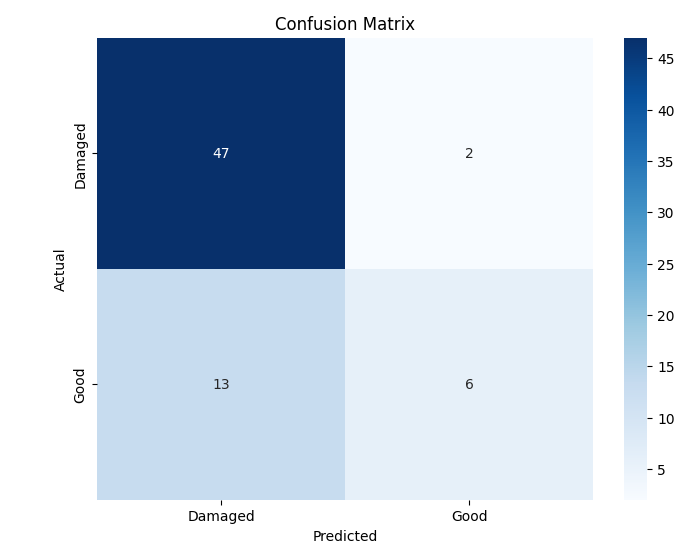
- 이진 분류에서는 MobileNet‑V2와 같은 경량 사전학습 모델이 92 % 이상의 정확도를 달성했으며, 맞춤형 경량 CNN도 비슷한 수준을 보였지만 학습 시간과 메모리 사용량에서 약간 뒤처졌다. 이는 클래스 간 차이가 크기 때문에 복잡한 특징 추출이 크게 필요하지 않음을 시사한다.
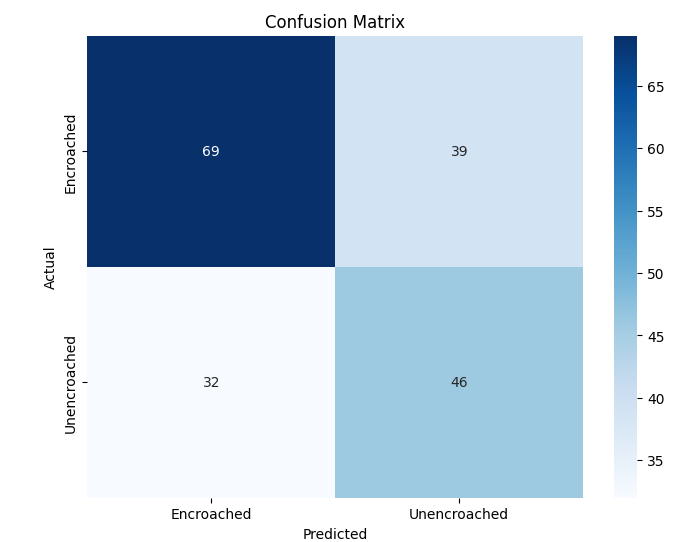
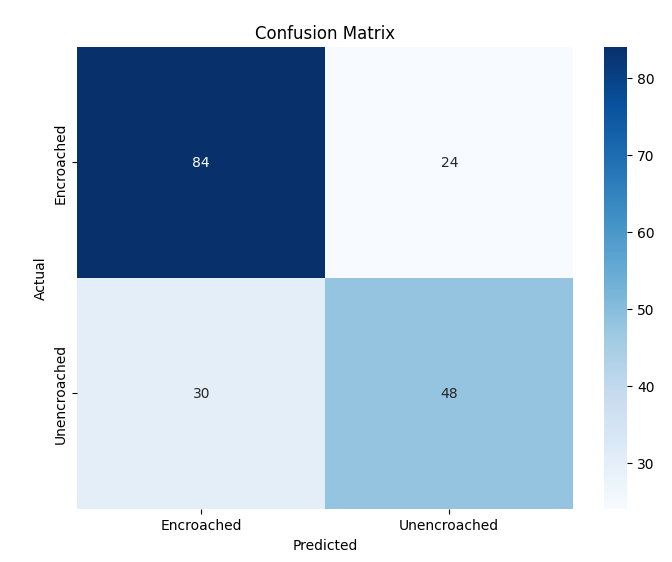
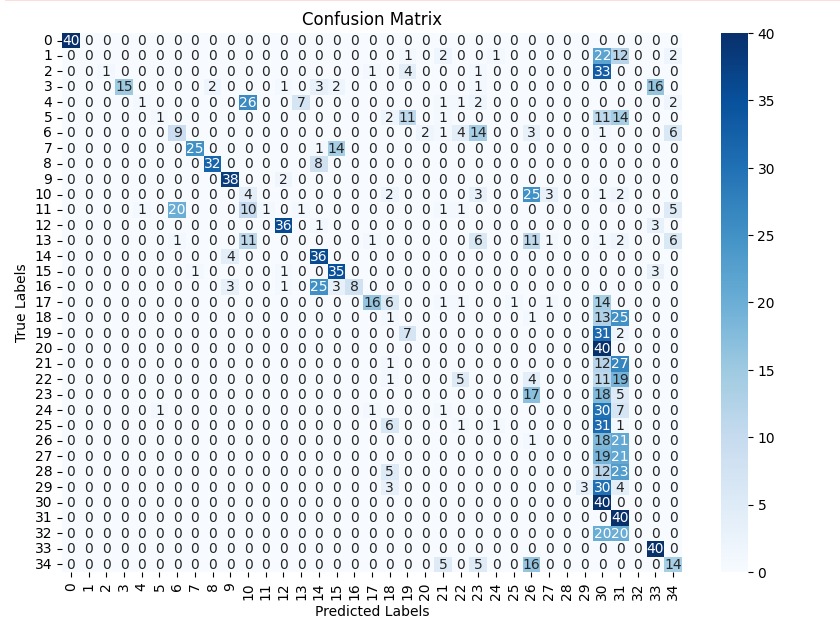
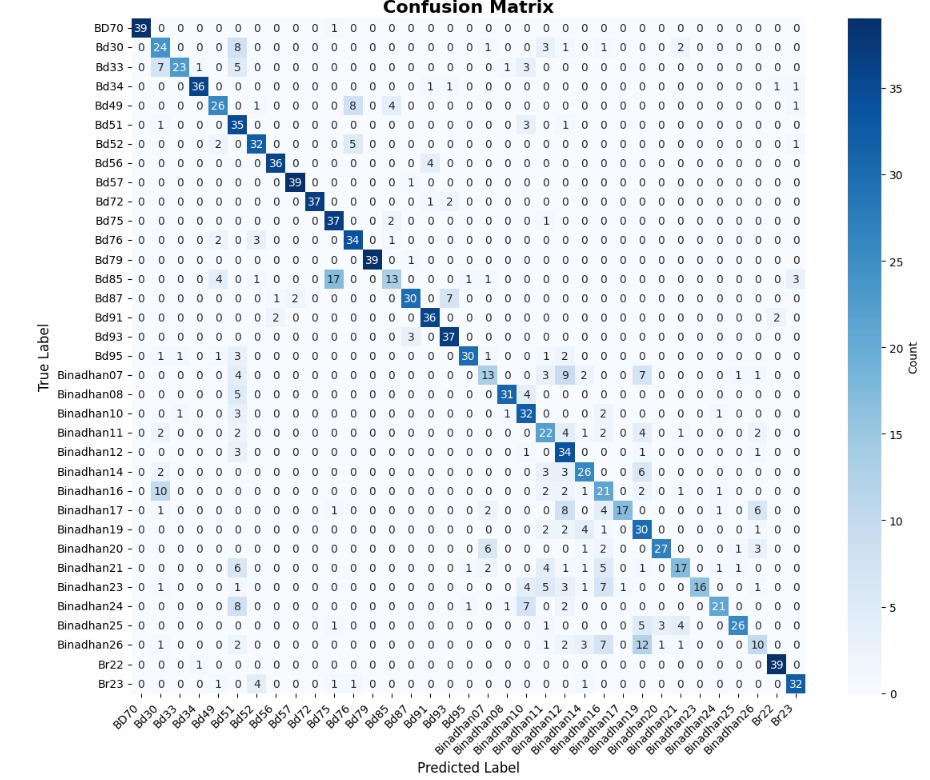
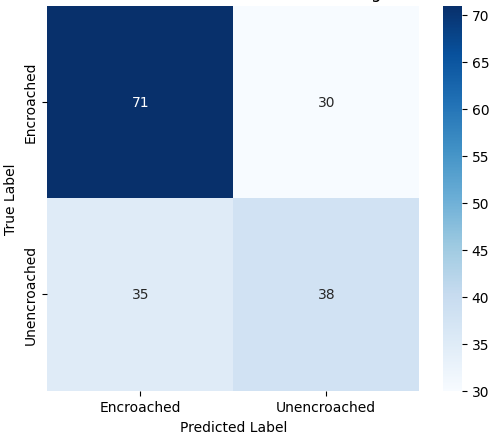
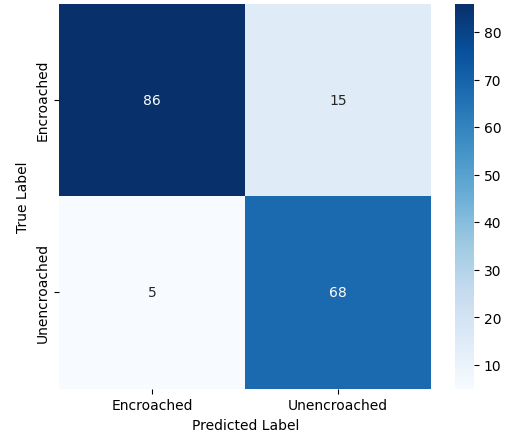
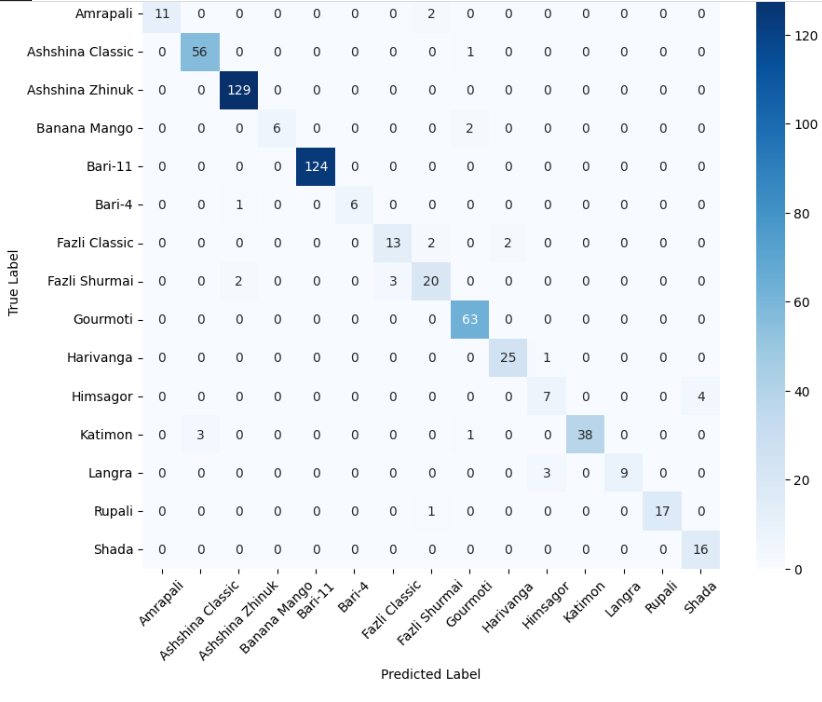
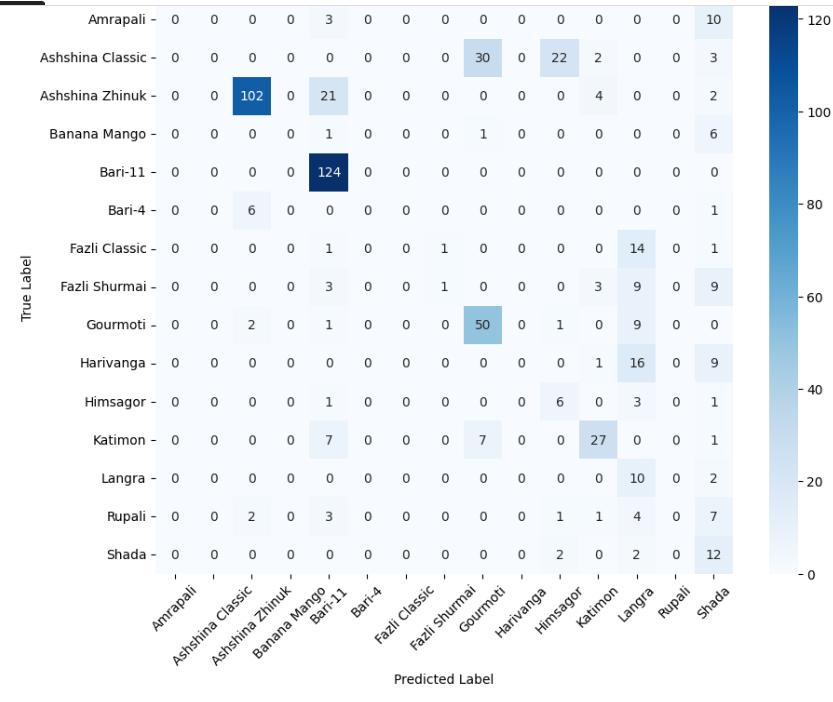
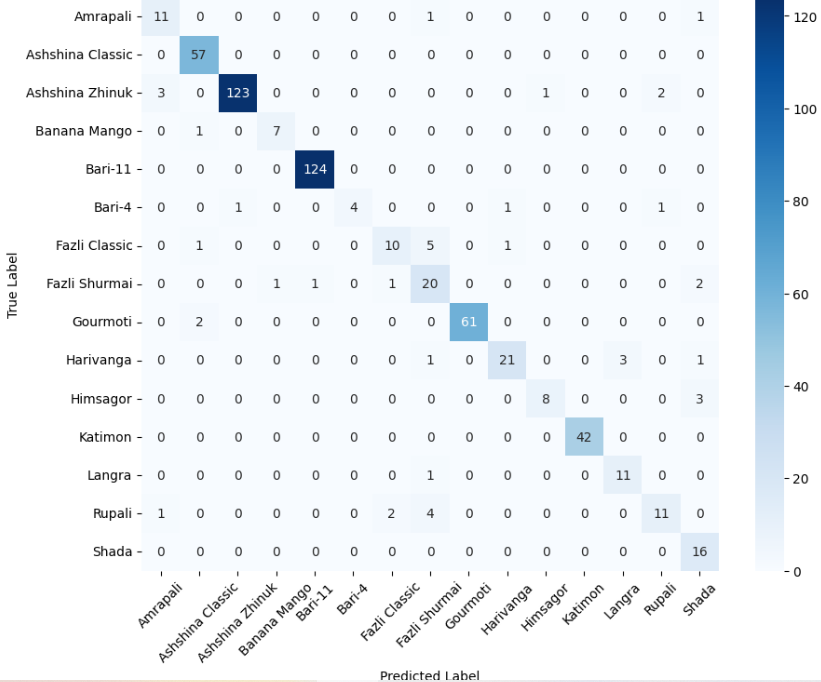
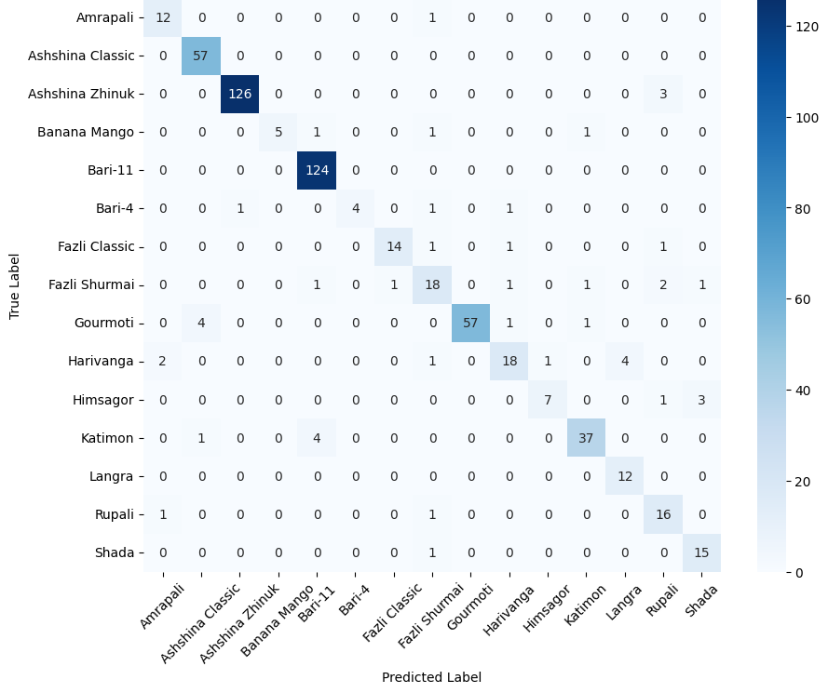
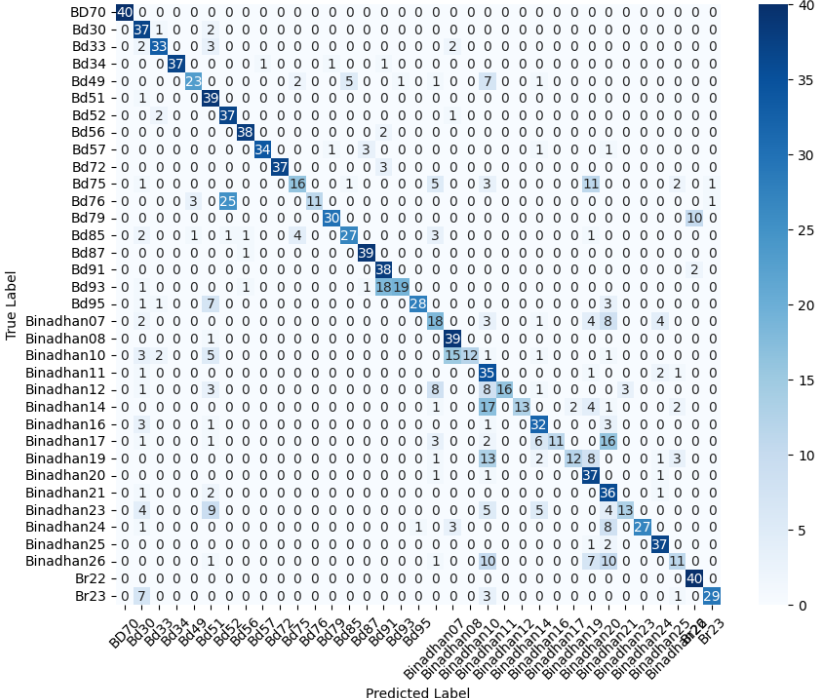
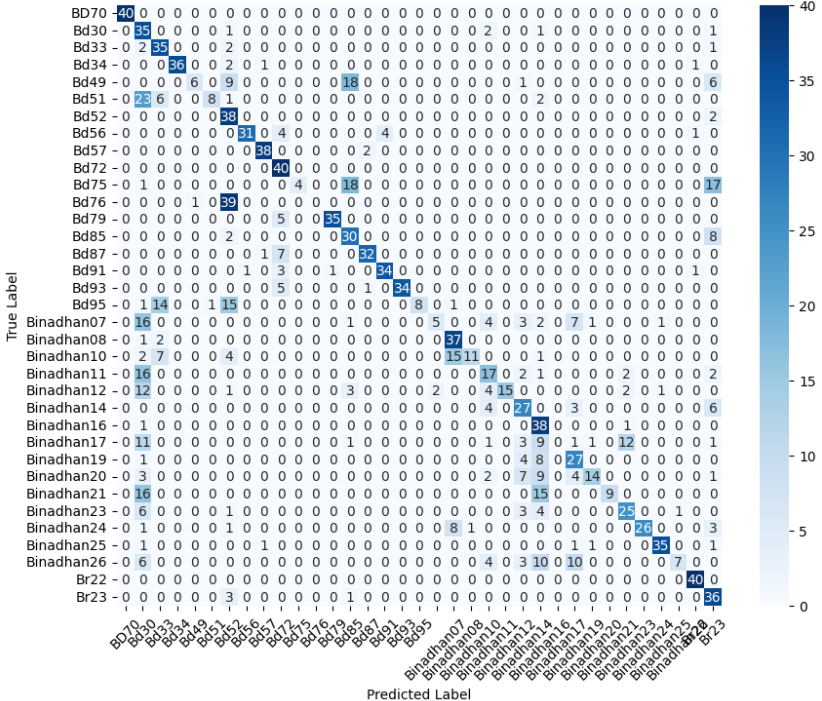
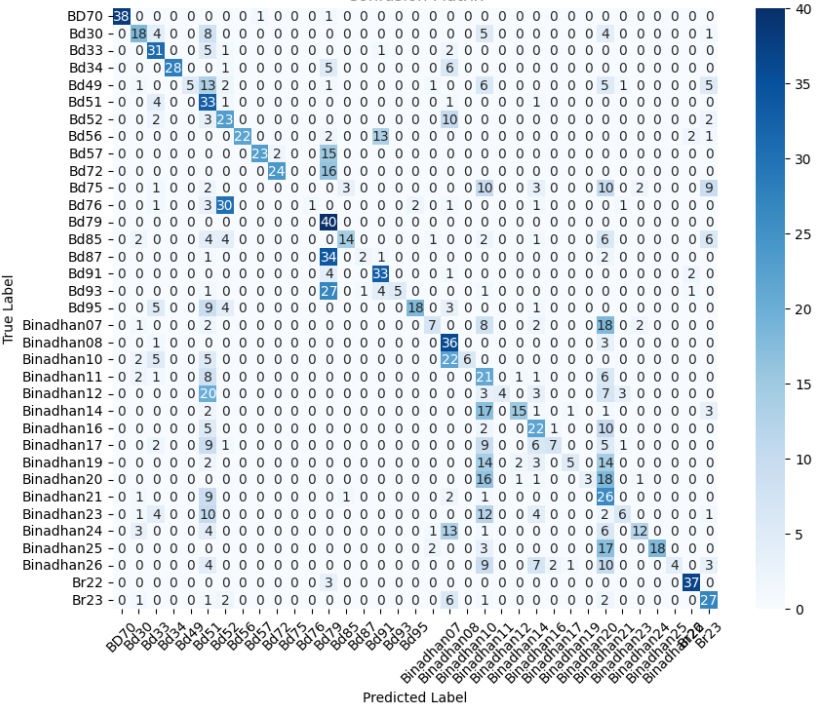
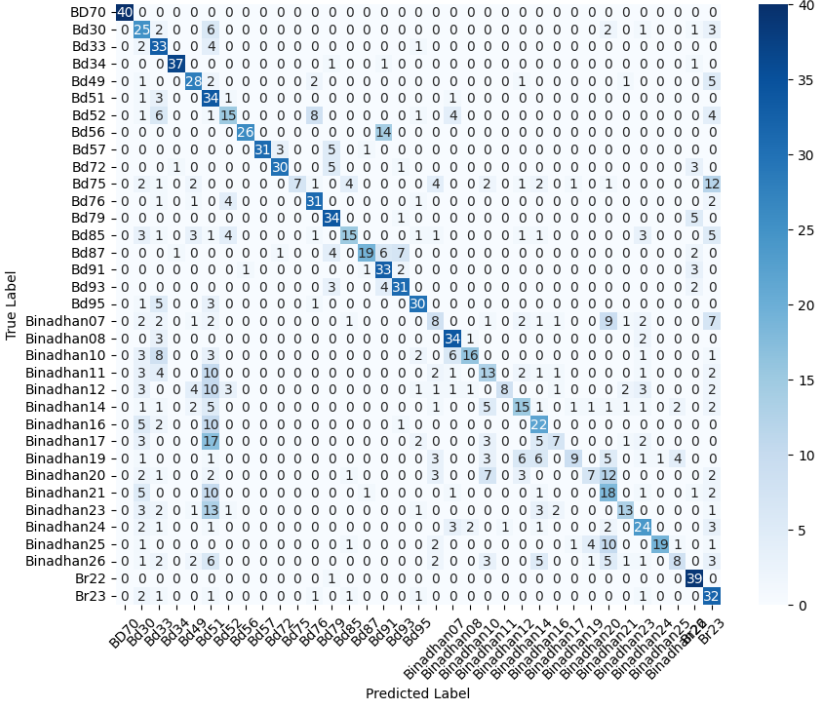
- 미세 다중 클래스에서는 ResNet‑101과 같은 깊은 레지듀얼 네트워크가 4~5 % 정도의 Top‑1 정확도 향상을 제공했다. 맞춤형 CNN은 레이어를 깊게 쌓을수록 성능이 개선되었지만, 과도한 깊이는 과적합과 학습 불안정성을 초래했다. 레지듀얼 연결은 그래디언트 소실을 방지하고, 더 깊은 네트워크에서도 안정적인 학습을 가능하게 함을 확인했다.
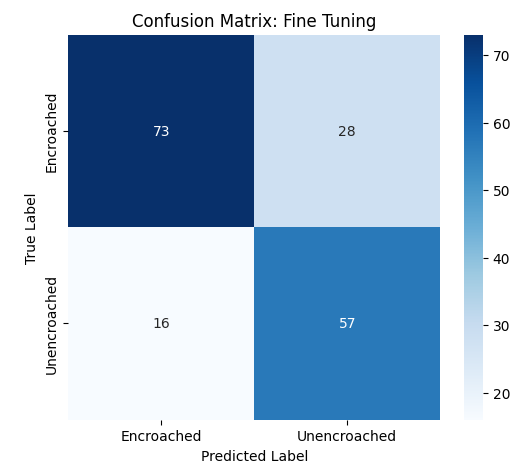
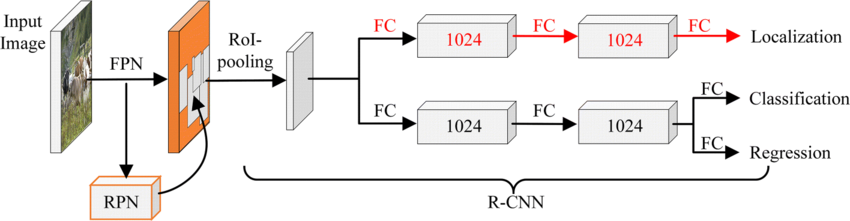
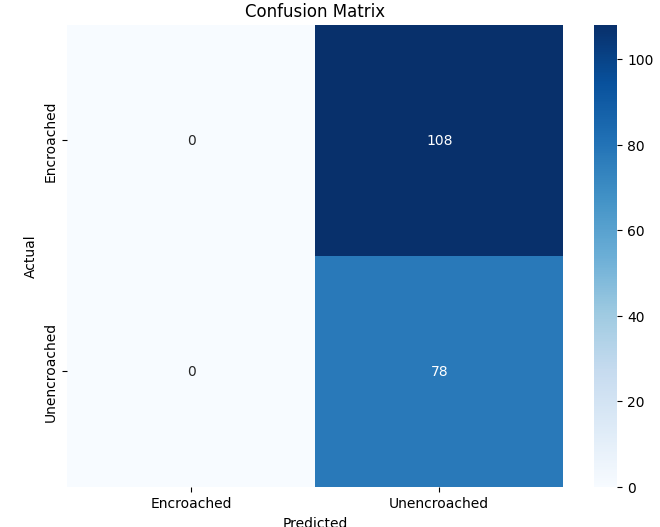
- 객체 검출 실험에서는 Faster‑RCNN 기반의 레지듀얼 백본을 사용한 경우, 무단 오토리키시를 0.78 mAP로 검출했으며, 맞춤형 CNN을 백본으로 교체했을 때는 0.71 mAP로 약간 낮아졌다. 그러나 맞춤형 백본은 파라미터 수가 30 % 감소했으며, 실시간 추론(30 FPS) 요구 상황에서 유리했다.
이러한 결과는 네트워크 깊이와 레지듀얼 구조가 복잡한 시각적 변이와 미세한 클래스 차이를 학습하는 데 핵심적인 역할을 한다는 점을 강조한다. 반면, 경량 사전학습 모델은 연산·전력 제한이 있는 엣지 디바이스나 단순 이진 분류 작업에 충분히 경쟁력이 있다.
한계점도 존재한다. 맞춤형 CNN 설계 과정이 경험에 크게 의존해 재현성이 낮으며, 하이퍼파라미터 탐색 비용이 크게 증가한다. 또한, 전이학습에서 전체 파인튜닝과 헤드만 재학습 간의 성능 차이가 데이터셋 규모에 따라 크게 변동하는데, 이를 정량화한 추가 실험이 필요하다. 마지막으로, 객체 검출 실험은 오토리키시 한 종류에 국한돼 있어, 다른 교통 객체(보행자, 자전거 등)로 일반화 가능한지 검증이 부족하다.
종합하면, 이 논문은 작업 난이도와 시스템 제약에 따라 “깊이 vs. 경량” 선택을 전략적으로 할 수 있는 실용적인 로드맵을 제공한다. 특히, 레지듀얼 연결을 도입한 깊은 모델이 미세 분류와 복합 검출에 유리함을 실증함으로써, 향후 연구자는 데이터 특성과 배포 환경을 고려해 맞춤형 설계와 사전학습 모델 사이의 균형점을 찾는 것이 중요함을 시사한다.
**
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리