- Title: Geometric and Dynamic Scaling in Deep Transformers
- ArXiv ID: 2601.01014
- 발행일: 2026-01-03
- 저자: Haoran Su, Chenyu You
📝 초록
본 논문에서는 깊은 신경망에서 발생하는 문제를 해결하기 위해 Manifold-Geometric Transformer(MGT)을 제안한다. MGT는 고차원 공간에 임베딩된 저차원 비선형 다양체 위에서 데이터가 흐르는 관점을 바탕으로 한다. 이를 통해 기존의 잔여 연결 문제인 "기억 격리" 메커니즘과 특징 쇄락을 해결한다.
💡 논문 해설
1. **Geometric Validity (via mHC)**:
- **쉬운 설명**: 데이터가 움직이는 공간은 복잡하고 낮은 차원의 구조를 가진다. 이 구조 안에서만 움직여야 한다고 생각하면 된다.
- **중간 설명**: 다양체라는 개념을 통해, 데이터는 고차원 공간에 있지만 실제로는 낮은 차원의 구조 위에 존재한다. 따라서 업데이트 벡터도 해당 구조 내에서만 움직일 수 있어야 한다.
- **어려운 설명**: mHC는 다양체의 접공간 $`T_{\mathbf{x}}\mathcal{M}`$ 안에서 업데이트를 수행하도록 데이터를 정규화한다. 이를 통해 데이터가 다양체 외부로 벗어나지 않도록 한다.
Dynamic Traversal (via DDL):
쉬운 설명: 모델은 정보를 “기억"하거나 “삭제"할 수 있어야 한다. 이를 통해 깊은 레이어에서도 안정적으로 작동한다.
중간 설명: DDL은 업데이트 크기를 동적으로 조절하는 게이트 $\beta$를 사용하여 모델이 정보를 “기억"하거나 “삭제"할 수 있도록 한다. 이를 통해 깊은 레이어에서도 특징의 쇄락을 방지한다.
어려운 설명: DDL은 Delta Operator를 통해 업데이트 크기를 동적으로 조절하며, 이는 다양한 기하학적 상태(Identity, Projection, Reflection)에서 작동할 수 있다. 이를 통해 깊은 레이어에서도 정보의 쇄락을 방지하고 안정적인 학습을 가능하게 한다.
Synergy between mHC and DDL:
쉬운 설명: mHC와 DDL은 각각 데이터가 움직이는 공간과 업데이트 크기를 제어한다. 이를 통해 데이터는 안전하게 움직일 수 있다.
중간 설명: mHC는 업데이트 방향을 다양체의 접공간에 맞추고, DDL은 업데이트 크기와 기울기를 제어한다. 이 두 가지 기능이 결합되어 깊은 레이어에서도 안정적인 학습을 가능하게 한다.
어려운 설명: mHC는 업데이트 벡터를 다양체의 접공간으로 정규화하고, DDL은 업데이트 크기를 동적으로 조절한다. 이를 통해 MGT는 깊이가 많은 신경망에서도 안정적인 학습을 가능하게 한다.
📄 논문 발췌 (ArXiv Source)
maketitle 감사합니다 aketitle
서론
잔여 연결은 현대 딥러닝의 기반이며, 수백 개의 레이어를 통해 그레디언트가 흐르게 한다. 그러나 표준적인 덧셈 업데이트 $`\mathbf{x}_{l+1} = \mathbf{x}_l + \mathcal{F}(\mathbf{x}_l)`$는 강한 가정을 한다: 최적의 업데이트가 항상 유클리드 공간에서 제약 없는 벡터 덧셈이라는 것이다. 최근 기하학적인 딥러닝 관점에 따르면, 데이터는 고차원 공간에 임베딩된 저차원 비선형 다양체 위를 흐른다. 이 제약 없는 업데이트 $`\mathcal{F}(\mathbf{x}_l)`$는 자주 “off-manifold"로 가는 방향을 가리키며, 깊은 레이어에서 특징의 쇄락과 순위의 붕괴를 일으킨다.
동시에 덧셈적인 성질은 “쓰기 전용” 메모리 메커니즘을 의미한다. 컨텍스트가 바뀌었을 때 정보를 “지우는 것”(즉, $`\mathcal{F}(\mathbf{x}) \approx -\mathbf{x}`$를 학습하는 것)을 배울 수 없어 어렵다. 이로 인해 “잔여 누적” 문제가 발생하는데, 깊이에 따라 노이즈가 쌓이는 것이다.
이러한 두 가지 문제를 해결하기 위해 **Manifold-Geometric Transformer (MGT)**을 제안한다. 이상적인 레이어 업데이트는 다음 두 조건을 만족해야 한다:
기하학적 유효성 (via mHC): 업데이트 벡터는 현재 다양체 상태의 접공간 $`T_{\mathbf{x}}\mathcal{M}`$에 있어야 한다. 이는 이론적으로 특징이 퇴화된 부분 공간으로 붕괴되는 것을 방지한다.
동적 순회 (via DDL): 이 접방향을 따라의 단계 크기는 동적이어야 하고, 모델은 “지우기"나 “항상” 작업을 명시적으로 수행할 수 있어야 한다.
저희의 기여는 다음과 같습니다:
**Manifold-Constrained Hyper-Connections (mHC)**를 제안한다. 이는 주목적을 정규화하는 가벼운 프로젝션 메커니즘이다.
**Deep Delta Learning (DDL)**과 동적인 게이트 $`\beta`$를 통합하여 기하학적인 Householder 업데이트를 가능하게 한다.
mHC와 DDL 간의 이론적 근거를 제공한다. 이들은 신호 정확성에 대한 승수 역할을 한다고 주장한다.
기하학적 제약이 현재 깊이 한계 이상으로 트랜스포머를 확장하는 데 필수적인지 부정하는 실험 프레임워크를 제안한다.
관련 연구
깊은 네트워크의 순위 붕괴. 순수한 self-attention 레이어가 깊이에 따라 이중 지수적으로 순위를 잃는다는 초기 이론적 분석을 제공했다. 이것은 현대 정규화 기법조차도 근본적인 표현 능력의 제약을 해결하지 못함을 시사한다. 최근 깊이 확장 노력은 100개 이상의 레이어를 학습할 수 있는 특수한 초기화와 정규화 방식을 제안했지만, 이러한 접근법들은 증상을 치료하는 것이지 기하학적 근본 원인을 해결하지는 않는다.
잔여 연결과 깊이. ResNets 이후로, 잔여 연결은 그래디언트 고속도로를 제공함으로써 깊은 네트워크의 학습을 가능하게 했다. 그러나 표준적인 $`\mathbf{x}_{l+1} = \mathbf{x}_l + \mathcal{F}(\mathbf{x}_l)`$ 형식은 유클리드 공간에서 덧셈 업데이트가 항상 유익하다는 가정을 함축한다. 관찰된 것처럼 이러한 단조적인 누적은 매우 깊은 네트워크에서 특징의 중복을 초래할 수 있다. 저희 연구는 명시적인 지우기 메커니즘을 통해 이 문제를 해결한다.
Manifold-Constrained Hyper-Connections (mHC). 최근 제안된 mHC 프레임워크는 기하학적 다양체에 하이퍼 연결을 제약함으로써 넓이 확장의 안정성을 개선한다. 이를 통해 ResNets의 항등 매핑 속성을 유지할 수 있다. 저희는 이 관점을 “공간 정규화”로 채택하여 업데이트를 데이터 다양체의 접공간 $`T_{\mathbf{x}}\mathcal{M}`$으로 프로젝션한다. 연결에 대한 기하학적 제약은 특징 중복을 해결하기 위한 보완적인 메커니즘이 필요하다는 것을 주장한다.
Deep Delta Learning (DDL). 저희의 동적 업데이트 법칙은 최근 제안된 Deep Delta Learning 프레임워크를 기반으로 한다. 이 프레임워크는 항등 행렬에 대한 학습 가능한 Delta Operator(rank-1 펨터)를 통해 잔여 연결을 일반화한다. Delta Operator는 다음과 같이 정의된다:
여기서 $`\mathbf{k}(\mathbf{X}) \in \mathbb{R}^d`$는 단위 정규화된 반사 방향 벡터이고 $`\beta(\mathbf{X}) \in [0, 2]`$는 데이터 의존적 게이트 스칼라이다. 스펙트럼 분석(Theorem 3.1 in )은 $`\mathbf{A}`$가 $`(d-1)`$ 개의 $`1`$ 고유값을 가진 $`\mathbf{k}^\perp`$를 포함하고 하나의 $`(1-\beta)`$ 고유값을 가진 $`\mathbf{k}`$를 가지며, $`\det(\mathbf{A}) = 1 - \beta`$임을 밝혀준다. 이는 세 가지 기본적인 기하학적 상태로 나아갈 수 있음을 가능하게 한다: 항등성 보존($`\beta \to 0`$), 직교 투사 또는 잊기($`\beta \to 1`$, $`\det \to 0`$) 및 Householder 반사($`\beta \to 2`$, $`\det \to -1`$). 완전한 Delta Residual Block은 이 연산자와 rank-1 값 주입을 결합한다:
이 덧셈 형태는 동기화된 “지우고 쓰기” 의미를 드러낸다: $`\mathbf{k}_l^\top\mathbf{X}_l`$은 지워야 할 오래된 메모리를 나타내며, $`\mathbf{v}_l^\top`$는 새로운 정보를 주입하며, 둘 다 동일한 게이트 $`\beta_l`$에 의해 조정된다. 이는 고전적인 Delta Rule을 재해석하고 네트워크의 깊이는 반복적인 메모리 정제로 해석할 수 있다.
기하학과 역학 통합. DDL은 지우기 기능을 제공하지만, 무제약 유클리드 공간에서 이를 적용하면 최적화 난관에 빠질 위험이 있다. 반면 mHC는 다양체 제약을 제공하지만, 다양체를 따라 후진(지우기)하는 능력이 부족하다. 저희 MGT 아키텍처는 이러한 직교적인 기여를 통합한다: mHC는 유효한 방향을 정의하고 DDL은 크기와 부호를 제어하여 극도로 깊게 확장할 수 있는 안정적인 “지우고 쓰기” 역학을 달성한다.
방법론
저희는 제안된 Manifold-Geometric Transformer (MGT) 블록을 구성하는 방법을 설명한다. 저희는 딥 네트워크에서 특징 전파의 기하학적 전제부터 시작하여, 두 가지 핵심 구성 요소에 대한 자세한 유도를 제공한다.
아키텍처 개요
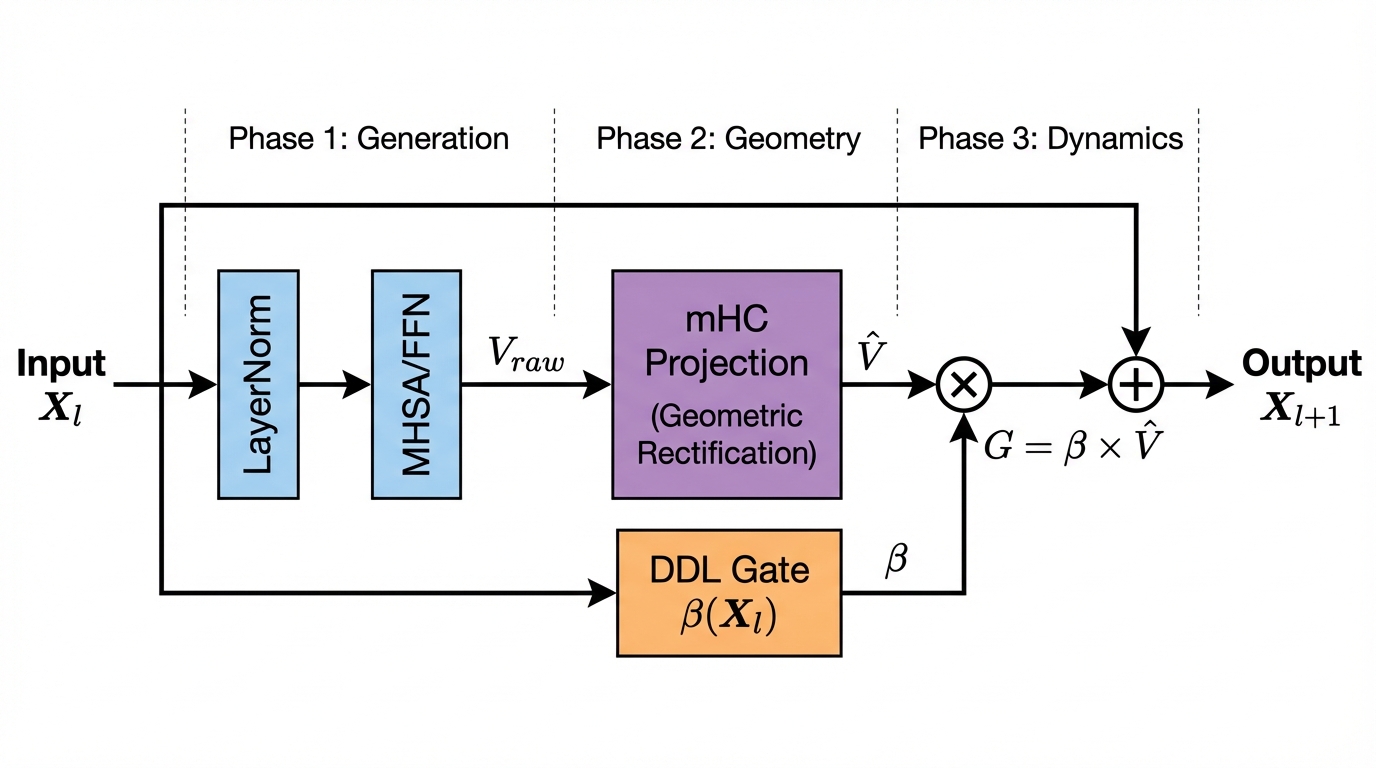
저희는 Transformer의 기본 빌딩 블록을 특징 생성과 전파를 명시적으로 분리하도록 재설계한다. Figure 1에 보여진 것처럼, 제안된 Manifold-Geometric Transformer (MGT) Block은 표준 Post-LayerNorm (Post-LN) 구조에서 기하학적 처리 단계를 도입하여 잔차 추가 전에 변환한다.
레이어 $`l`$의 정방향 패스는 세 가지 다른 단계로 분해된다:
원시 특징 생성: 먼저 입력 상태 $`\mathbf{X}_l`$은 표준 혼합 모듈(Multi-Head Self-Attention 또는 Feed-Forward Network)에 의해 처리되어 후보 업데이트 벡터 $`\mathbf{V}_{raw}`$를 생성한다.
기하학적 교정 (via mHC): 직접적인 덧셈 대신, $`\mathbf{V}_{raw}`$는 Manifold-Constrained Hyper-Connection (mHC) 모듈을 통과한다. 이 모듈은 공간 필터로 작용하여 원시 업데이트를 추정된 데이터 다양체의 접공간으로 프로젝션한다.
델타 역학 (via DDL): 마지막으로, Deep Delta Learning (DDL) 컨트롤러는 입력 컨텍스트 $`\mathbf{X}_l`$에 기반하여 동적 게이트 스칼라 $`\boldsymbol{\beta}`$를 계산한다. 이 스칼라는 교정된 벡터를 조절한다. 특히, 진정한 “지우기” 메커니즘을 가능하게 하기 위해 현재 상태 프로젝션에 비례하는 뺄셈 항을 포함한다.
Manifold-Geometric Transformer (MGT) Block의 아키텍처. 이 파이프라인은 세 가지 단계를 명시적으로 분리한다: (1) LayerNorm과 MHSA/FFN을 통한 생성, (2) mHC 프로젝션 $`\Psi`$를 통해 업데이트를 제약하는 기하학적 교정, 그리고 (3) DDL 게이트 $`\boldsymbol{\beta}(\mathbf{X}_l)`$을 통한 역학. 스킵 연결은 항등 매핑을 유지하고, 선택적으로 지우고 누적할 수 있는 게이트된 출력 $`\boldsymbol{G} = \boldsymbol{\beta} \odot \mathbf{V}_{mHC}`$를 가능하게 한다.
기초: 깊은 레이어의 다양체 가설
$`\{\mathbf{X}_l\}_{l=0}^L`$을 Transformer의 은닉 상태 시퀀스로 표시하고, $`\mathbf{X}_l \in \mathbb{R}^{S \times D}`$는 $`S`$ 토큰과 $`D`$차원 특징을 나타내자. 우리는 유클리드 공간 $`\mathbb{R}^D`$ 전체에 아닌, 저차원 리만 다양체 $`\mathcal{M} \subset \mathbb{R}^D`$ 위에 유효한 의미 표현이 위치한다고 주장한다. 단순한 스텝 $`\mathbf{X}_l + \mathbf{V}_l`$은 종종 표현을 다양체 외부로 강제한다($`\mathbf{X}_{l+1} \notin \mathcal{M}`$). 구조적 정합성을 유지하기 위해 업데이트 벡터는 로컬 접공간 $`T_{\mathbf{X}_l}\mathcal{M}`$에 제약되어야 한다.
델타 연산자
Deep Delta Learning의 주요 혁신은 고전적인 Householder 반사를 (Appendix 6)로 일반화하는 것이다. 여기서 상수 $`2`$는 학습 가능한, 데이터에 의존적인 스칼라 게이트 $`\beta(\mathbf{X})`$로 대체된다.
Definition 1 (Delta Operator). *단위 벡터 $`\mathbf{k} \in \mathbb{R}^d`$와 스칼라 $`\beta \in \mathbb{R}`$에 대해, 델타 연산자는 다음과 같다:
덧셈 형태는 “지우고 쓰기” 의미를 드러낸다: $`\mathbf{k}_l^\top\mathbf{X}_l`$은 지워지고 $`\mathbf{v}_l^\top`$는 써진다, 둘 다 $`\beta_l`$에 의해 조정된다. 이는 고전적인 Delta Rule을 회복한다(증명은 Appendix 6 참조).
Manifold-Constrained Hyper-Connections (mHC)
mHC의 목표는 서브 레이어(MHSA 또는 FFN)에 의해 생성된 원시 업데이트 $`\mathbf{V}_{raw}`$를 교정하는 것이다. 정확한 접공간을 계산하기 위한 고유값 분해는 계산적으로 비용이 많이 들기 때문에, 효율적인 Soft Subspace Approximation을 사용한다.
여기서 $`\mathbf{W}_{gate} \in \mathbb{R}^{D \times D}`$는 입력을 의미적 중요도 점수로 투영한다. 선형 대수에서 엄격한 직교 프로젝션이 아니지만, 이는 мягкое 다양체 제약으로 작용하여 $`\mathbf{X}_l`$에 의해 정의된 현재 의미 트레일에서 벗어나는 특징 차원(노이즈 하위 공간)을 억제한다.
MGT 통합: mHC와 DDL 결합
MGT가 어떻게 DDL과 mHC를 결합하여 안정적인 기하학적 업데이트를 달성하는지 설명한다.
MGT 델타 컨트롤러
MGT에서는 mHC 교정 출력 $`\mathbf{V}_{mHC}`$를 델타 잔차 블록(Eq. [eq:delta_block])의 값 분기로 취급한다. 델타 컨트롤러 $`\boldsymbol{\beta}(\mathbf{X}_l)`$을 도입한다:
여기서 $`\mathbf{W}_{\beta} \in \mathbb{R}^{D \times D}`$와 $`\mathbf{b}_{\beta} \in \mathbb{R}^D`$는 학습 가능한 매개변수이고, $`\lambda`$는 출력 범위를 조정하고, $`\epsilon`$은 수치 안정성을 제공한다.
Remark 4 (범위 확장). 원래의 DDL은 시그모이드를 통해 $`\beta \in [0, 2]`$(즉, $\beta = 2\sigma(\cdot)$)을 사용한다. 우리의 탄젠트 매개변수화와 오프셋 $`\epsilon`$은 범위 $`\beta \in [-\lambda + \epsilon, \lambda + \epsilon]`$를 제공하여 부호 업데이트에 더 적극적인 능력을 포함한다. $`\epsilon = 0`$과 $`\lambda = 1`$을 설정하면 표준 범위 $`[-1, 1]`$가 회복된다.
MGT 업데이트 규칙
덧셈 형태(Eq. [eq:delta_block])를 따르면, MGT 업데이트는 동기화된 “지우고 쓰기” 의미를 구현한다: