시놉틱 팟캐스트 대화, 영상 모델이 도전하다!
📝 원문 정보
- Title: SPoRC-VIST A Benchmark for Evaluating Generative Natural Narrative in Vision-Language Models- ArXiv ID: 2601.01062
- 발행일: 2026-01-03
- 저자: Yunlin Zeng
📝 초록
본 논문에서는 시각적 콘텐츠를 이용하여 증폭된 팟캐스트 대본을 생성하는 방법을 제안한다. 기존의 시각 언어 모델(VLM)이 단순히 사실적인 설명에 그치는 반면, 본 연구는 이러한 시각적 입력을 풍부하고 자연스러운 다중 회화로 전환하는 데 초점을 맞춘다. 이를 위해 개발된 SPoRC-VIST 벤치마크는 합성 이미지와 실제 사진 간의 일반화 성능을 검증한다.💡 논문 해설
1. **비전 언어 모델(VLM)과 팟캐스트 대본 생성** 비전 언어 모델은 시각적 입력을 텍스트로 변환하는 데 사용되지만, 본 논문에서는 이러한 모델이 단순한 설명을 넘어 이야기를 전달할 수 있도록 개선되었다. 이를 위해 합성 이미지와 실제 사진을 활용하여 모델을 훈련시켰다.-
SPoRC-VIST 벤치마크
SPoRC-VIST는 고급 팟캐스트 대본 생성을 위한 데이터셋과 평가 기준을 제공한다. 합성 이미지를 통해 대규모 텍스트 데이터를 활용하고, 실제 사진으로 일반화 성능을 검증한다. -
데이터셋 구성 파이프라인
본 논문은 실제 팟캐스트 대본에서 시각적 묘사를 추출하여 합성 이미지를 생성하는 방법을 제시한다. 이를 통해 모델은 실제 상황에 가까운 풍부한 대화를 생성할 수 있다.
📄 논문 발췌 (ArXiv Source)
컴퓨터 비전 분야는 단순히 인식(classification, detection)에서 활성화된 생성으로 급속도로 발전해 왔습니다. 현대의 비전-언어 모델(VLMs)은 복잡한 시각적 입력을 처리하고 세부적인 텍스트 설명을 생성할 수 있습니다. 그러나 “설명"과 “스토리텔링” 사이에는 여전히 큰 간극이 존재합니다. 최신의 모델들은 “숲 속의 하얀 버스”를 정확하게 식별할 수 있지만, 그 시각적 단서를 흥미로운 다중 회화로 엮어내는 데 어려움을 겪습니다. 이는 개인적인 성격, 유머, 자연스러운 흐름을 보여주기 때문입니다.
이 한계는 교육 데이터의 문제와 관련이 있습니다—대부분의 VLMs은 LAION이나 COCO와 같은 캡션 위주의 데이터셋으로 학습되어 사실적인 간결함을 우선시합니다. 또한, 스토리텔링 품질에 적합한 평가 지표가 부족하여 표준 n-gram 지표(BLEU나 ROUGE)는 창의성과 언어 다양성을 제약하고 안전하고 반복적인 로봇적 출력을 유도합니다. 생성 AI가 창조적인 영역으로 이동하면서 생성된 스토리텔링의 “품질"을 평가하기 위해서는 새로운 프레임워크가 필요하며, 그 중에는 개인성의 환영, 대화 동력학, 그리고 음향 구조를 고려해야 합니다.
본 논문에서는 시각적 팟캐스트 생성이라는 과제에 접근합니다: 연속된 이미지 시퀀스를 두 명의 다른 호스트 사이에서 일관되고 재미있는 팟캐스트 대본으로 변환하는 것입니다. [[fig:teaser]]은 Visual Storytelling (VIST) 데이터셋에서 오는 일반적인 입력을 보여줍니다(각각 단순한 한 문장 캡션을 가진 다섯 장의 이미지), 이를 풍부하고 다중 회화로 변환하려고 합니다.
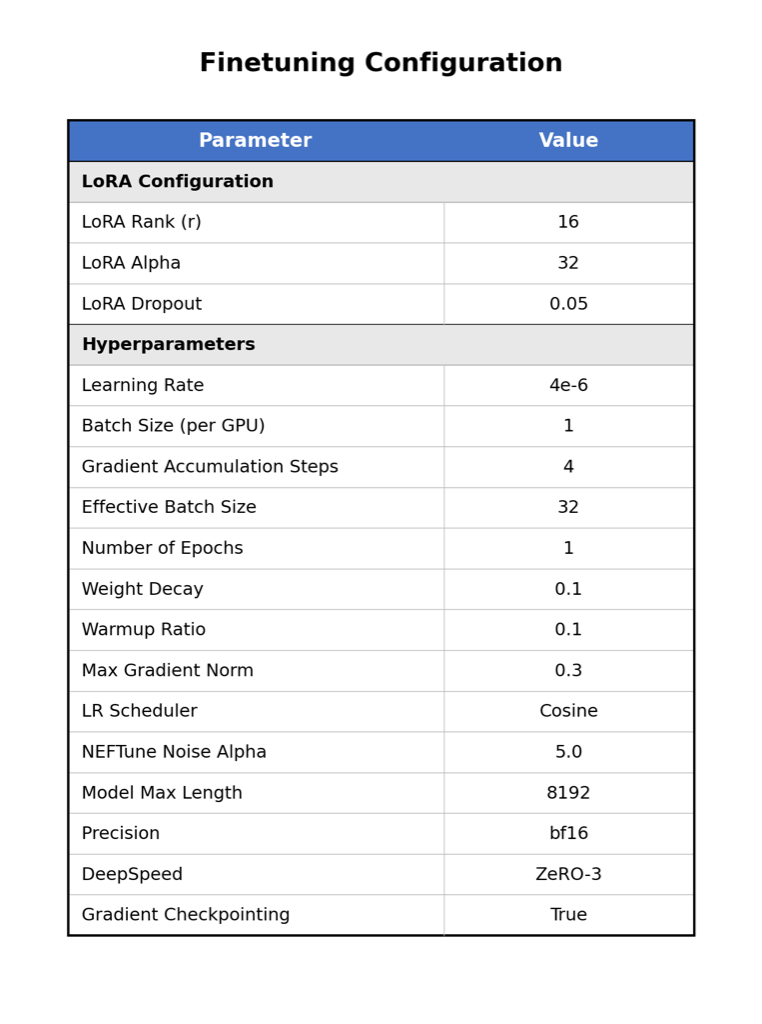
우리는 SPoRC-VIST 벤치마크를 소개합니다. 이 프레임워크는 텍스트 데이터의 풍부함을 활용하여 합성 시각적 자료와 함께 교육하면서, 실제 사진 시퀀스에서 테스트하는 방식입니다. 우리의 기여는 세 가지로 나뉩니다: (1) 4000개의 시각-대화 쌍 데이터셋을 정리하고 LoRA를 사용하여 효율적인 파라미터 Qwen3-VL-32B 모델을 스타일 전환(“캡셔너”에서 “팟캐스터”)을 위해 미세 조정합니다. (2) 새로운 스타일 인식 지표(회화 길이, 전환 비율)와 AI-as-a-Judge 프로토콜을 제안하여 “개인성의 환영"과 대화 자연성을 평가합니다. (3) 작은 미세 조정된 모델(32B)은 대형 기본 모델(235B)보다 스토리텔링 품질이 우수하면서 시각적 기반 성능을 저하시키지 않음을 보여주며, 합성에서 실제 일반화 전략의 효과성을 검증합니다. 데이터 생성과 모델 교육을 재현하기 위한 코드는 https://github.com/Yunlin-Zeng/visual-podcast-VLM 에서 제공됩니다.
관련 연구
시각적 스토리텔링
이미지 시퀀스로부터 이야기를 생성하는 작업은 VIST 데이터셋에 의해 정형화되었습니다. VIST는 연속적인 시각적 스토리텔링을 구현했지만, 그 주석은 각 이미지당 한 문장의 설명으로 구성됩니다. 다른 접근법들은 여러 장의 이미지를 위한 단일 단락 길이의 이야기 생성에 초점을 맞추었습니다. 우리의 작업은 이러한 분야와 달리 다중 스피커 대화로 구조화된 이야기를 생성하는데, 이는 대화 흐름, 성격 및 상호 스피커 동력학을 모델링하는 더욱 복잡한 작업입니다.
비전-언어 모델
비전 언어 모델의 아키텍처는 CLIP과 같은 초기 듀얼 인코더 프레임워크에서 정교한 자동회귀 모델로 진화해 왔습니다. Flamingo 및 OpenFlamingo와 같이 심층 융합 접근법은 고정된 LLM에 시각적 정보를 주입하기 위해 게이트 처리 교차 주의 층을 사용하여 강력한 몇 단계 성능을 가능하게 합니다. 후속 지시어 조정 모델인 LLaVA 및 InstructBLIP은 이른 융합 전략을 채택하고 이미지 패치를 언어 모델의 임베딩 공간으로 투영하여 “시각적 토큰"으로 작동합니다. 이러한 접근법은 세밀한 사고를 가능하게 합니다. GPT-4V 및 Gemini Pro Vision과 같은 전문 모델은 다중 모달 이해의 경계를 더욱 확장했지만, 그들의 폐쇄성은 아키텍처 커스터마이징을 제한합니다.
최근 Qwen-VL 시리즈는 개방 가중치 모델에 대한 새로운 최고 수준을 설정했습니다. Qwen3-VL-235B는 GPT-5의 여러 시각적 추론 벤치마크에서 우수한 성능을 보여주었습니다. Qwen3-VL은 동적 해상도 기능을 도입하여 이미지를 원래 측면 비율로 처리하는 데 필요하지 않은 과격한 리사이징 또는 자르기를 방지합니다. 이 특성은 이야기 작업에 특히 중요하며, 작은 시각적 세부 사항(예: 표정, 메뉴의 배경 텍스트)이 주요 플롯 포인트로 작용할 수 있습니다. 우리의 연구는 이러한 이유로 Qwen3-VL 아키텍처를 활용하여 강력한 시각적 인코더를 사용해 개방형 스토리텔링을 정확한 시각 증거에 기반하게 합니다.
생성 평가
오픈 엔드 텍스트 생성의 평가는 매우 어려운 작업입니다. 전통적인 지표는 창조적 작업에서 인간 판단과 약한 상관성을 보여줍니다. 최근 연구에서는 “LLM-as-a-Judge” 프레임워크를 제안하여 선두 모델(GPT-5 등)을 사용해 일치성, 환영, 그리고 스타일을 평가합니다. 우리는 이 전략을 우리의 모델의 특정 “팟캐스트 개인성"을 평가하기 위해 채택하고, 참조 기반 겹침보다 스타일 지표가 이 작업에 더 관련성이 있음을 주장합니다.
SPoRC-VIST 벤치마크
비디오-트랜스크립트 데이터를 사용하지 않고 시각적 바anter를 생성할 수 있는 모델을 교육하기 위해 합성에서 실제 데이터 구성 전략을 개발했습니다. 이를 통해 품질 높은 팟캐스트 오디오의 대량 활용이 가능하며, 모델이 대화를 시각 개념에 기반하게 학습하는 것을 보장합니다.
데이터 소스
우리는 Structured Podcast Research Corpus (SPoRC)를 주요 고급 대화 소스로 사용합니다. SPoRC는 1백만 개 이상의 팟캐스트 에피소드의 트랜스크립트와 메타데이터를 포함하고 있습니다. 이 코퍼스에서 품질 높은 상호작용 쌍(Host/Guest)을 필터링했으며, 단독 몬로그나 저품질 자동화 트랜스크립트는 제외했습니다. 이는 자연스러운 언어 패턴과 대화의 재미를 제공하며, 우리의 스토리텔링 스타일 전환에 텍스트 기반을 제공합니다.
시각적 구성 요소로 우리는 SPoRC 트랜스크립트와 일치하는 합성 이미지를 생성했습니다. 원래 팟캐스트 데이터에는 짝이 된 시각적 자료가 없기 때문에, 우리는 Stable Diffusion 3.5를 사용하여 트랜스크립트 내의 시각적 묘사를 반영하는 고급도 높은 이미지 시퀀스를 생성했습니다. 이를 통해 시각 내용이 말한 이야기와 명시적으로 일치하는 대량의 완벽하게 정렬된 교육 세트를 구성할 수 있었습니다. 평가에서는 VIST 데이터셋을 사용하여 실제 사진 시퀀스에서 벤치마크 테스트를 수행합니다.
실제 트랜스크립트 사용 이유: 초기 실험
자연스러운 질문이 생깁니다: 왜 합성 대화를 생성하는 것보다 실제 팟캐스트 트랜스크립트를 사용해야 하는가? 이를 위해 실제 트랜스크립트와 합성 대안을 비교하는 초기 실험을 수행했습니다.
우리는 풍부한 시각적 묘사를 포함하는 팟캐스트 발췌문을 선택하고, Stable Diffusion 3.5를 사용하여 해당 이미지를 생성(2)하고, 시각적 리ASON 벤치마크에서 선두 성능을 보인 Qwen3-VL-235B 및 GPT-5.2 모델을 사용하여 이러한 이미지로부터 팟캐스트 트랜스크립트를 생성하도록 요청했습니다. 여러 평가자에게 AI 생성된 트랜스크립트와 원래 인간 트랜스크립트를 비교하도록 했습니다.
모든 프롬프트 변형에 걸쳐, 원래의 인간 트랜스크립트는 자연스러움, 개인성, 그리고 대화 흐름 측면에서 AI 생성된 대안을 능가했습니다. AI 생성된 대화는 공식적(“우리 팟캐스트에 오신 것을 환영합니다…")하고 진정한 중단, 개인적인 이야기, 그리고 인간 대화를 특징짓는 감정 반응이 부족했습니다. 이 결과는 실제 팟캐스트 트랜스크립트를 교육 목표로 사용하는 우리의 결정을 촉구했습니다.





데이터셋 구성 파이프라인
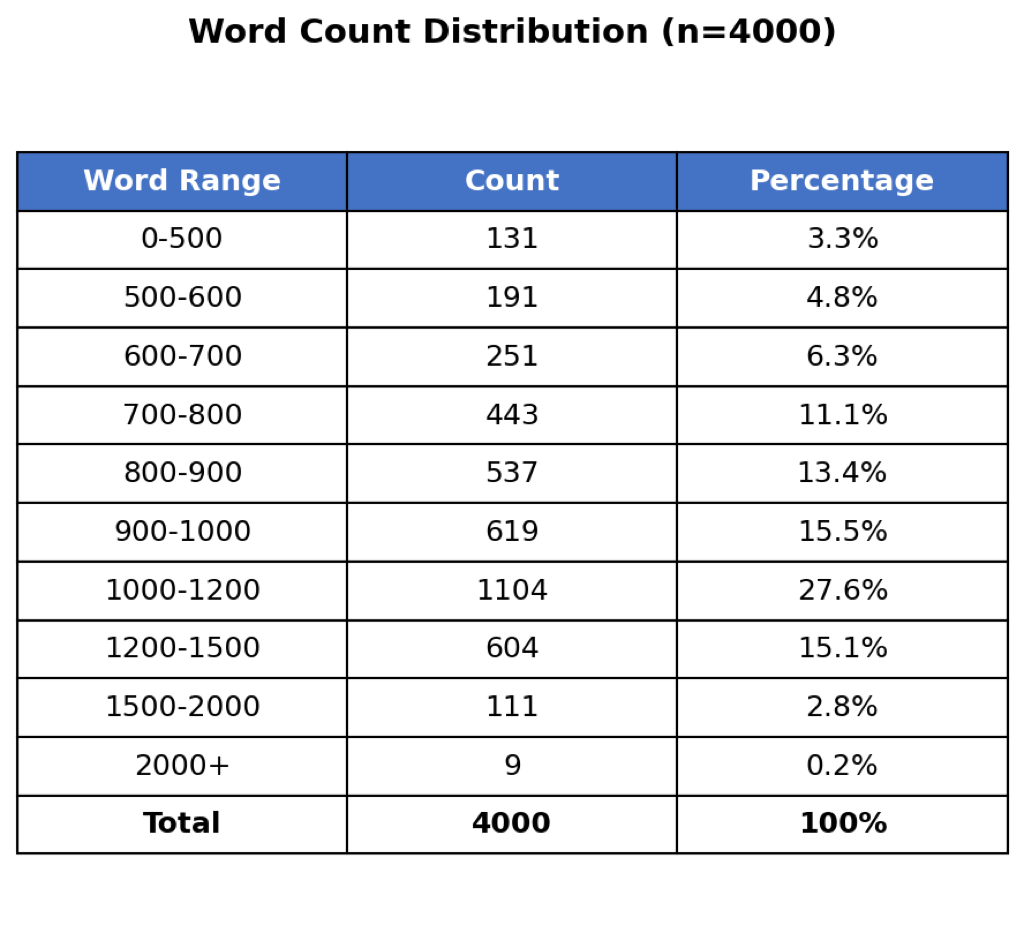
우리의 데이터셋 구성 파이프라인은 [[fig:pipeline]]에서 설명된 세 가지 연속적인 단계로 이루어져 있습니다. 첫 번째 단계는 SPoRC 코퍼스에 있는 1백만 개 이상의 에피소드 중 품질 높은 두 스피커(Host/Guest) 대화를 필터링하는 것입니다. Claude Sonnet 4.5를 사용하여 이러한 대화 내에서 청취자가 생생하게 상상할 수 있는 시각적 묘사를 포함한 세그먼트를 식별했습니다. 81,000개 이상의 적합한 에피소드에서 우리는 평균 900-1,100단어의 4,000개 품질 높은 발췌문을 추출했습니다.
다음 단계는 이미지 프롬프트 생성입니다. 각 발췌문에 대해 Claude Sonnet 4.5는 대화에서 묘사된 주요 시각적 장면을 포착하는 다섯 가지 상세한 이미지 프롬프트를 생성합니다. 예를 들어, 파스타 만드는 설명은 “목재 보드 위에 무성하고 끈적한 파스타 반죽이 있는 손과 여기저기에 흩어진 하얀 밀가루"와 같은 프롬프트로 이어집니다. 이러한 프롬프트는 고급도 높은 이미지 생성에 충분히 구체적이면서 팟캐스트 내용을 충실히 반영하도록 설계되었습니다. 마지막 단계는 Stable Diffusion 3.5를 통해 AWS Bedrock으로 이미지 합성을 실행하는 것입니다. 이 과정은 각 발췌문당 다섯 장의 이미지를 생성하여 약 20,000장의 총 이미지가 포함된 4,000개 샘플 데이터셋을 만들어냈습니다.
팟캐스트 발췌문 (SPoRC)
Host: Exactly! Now I’m cracking three eggs right
into this well. See how the bright yellow yolks are sitting there,
perfectly intact? And now I’m taking my fork and I’m just gently beating
the eggs, slowly incorporating the flour from the sides.
Guest: The color is amazing—that golden yellow mixing
with the white flour. It’s almost like watching paint blend.
Host: Right? And now I’m using my hands to bring it all
together. The dough is still pretty shaggy at this point—you can see all
these little bits of flour still on the board. My hands are completely
covered in sticky dough.
Guest: How long do you knead it for?
Host: About 10 minutes. Watch—I’m pushing it away with
the heel of my hand, folding it back, turning it a quarter turn. Push,
fold, turn. Push, fold, turn. You can see it’s getting smoother and more
elastic now.
Guest: It’s changed so much! It went from that rough,
shaggy mess to this smooth, silky ball.
Host: Now I’m wrapping it in this plastic wrap and we’ll
let it rest for 30 minutes. While we wait, let me show you the pasta
machine I’m going to use. It’s this silver hand-crank one that clamps
right onto the counter here.
Guest: That’s a beauty! Is that vintage?
Host: It’s my grandmother’s actually. Still works
perfectly. See these rollers here? We’ll run the dough through, starting
at the widest setting. But first, let me unwrap this dough—wow, it’s so
smooth now, feel how soft it is.
Guest: Like silk!
Host: I’m cutting it into four pieces. Now I’m taking
this first piece and flattening it with my hands into a rough rectangle
shape, about a quarter inch thick. I’m dusting it with flour so it
doesn’t stick. Now I’m feeding it through the widest setting on the
machine.
Guest: Oh wow, it’s coming out the other side!
Host: Yeah! And look how it stretches. Now I’m folding
it in thirds like a letter, and I’ll run it through again. We’ll do this
a few times. Each time it gets smoother and more uniform. See how it’s
going from this rough sheet to something really refined?
Guest: The transformation is incredible. It’s like
watching fabric being woven.
Host: Now I’m moving to the next setting, making it
thinner. Watch how long the sheet gets as it comes through. I have to
catch it with both hands now. It’s getting so delicate I can almost see
through it.
Guest: Are you nervous it’ll tear?
Host: A little! This is the trickiest part. One more
pass... there! Per # Limit to 15k chars for stability
📊 논문 시각자료 (Figures)