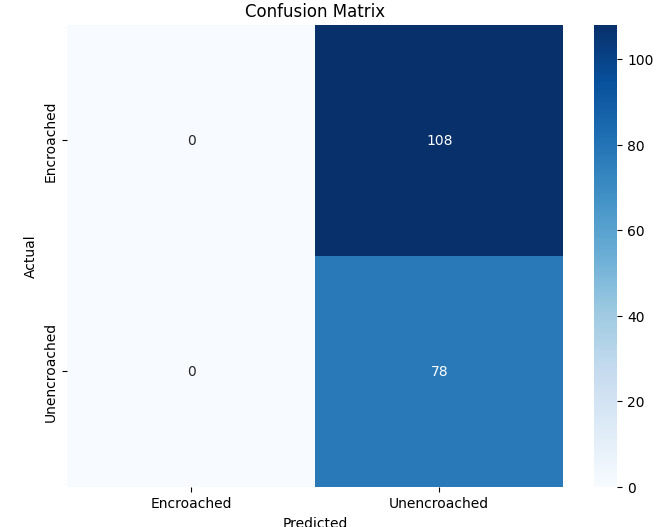
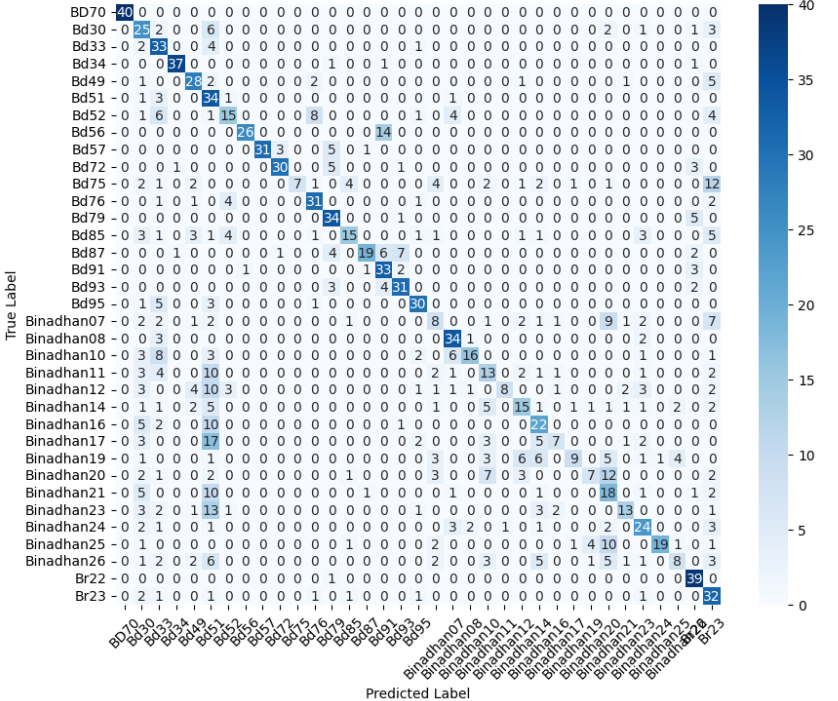
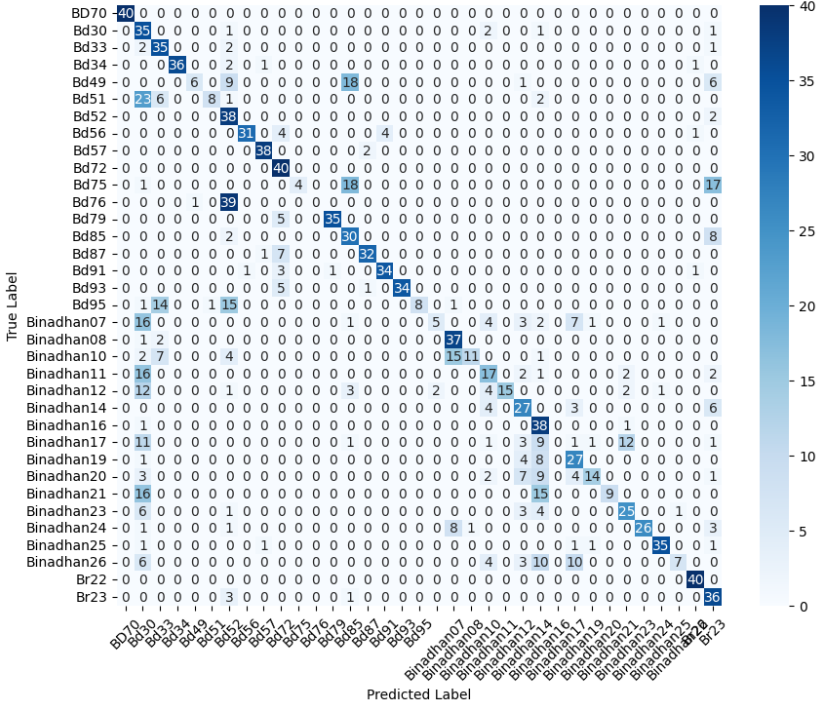
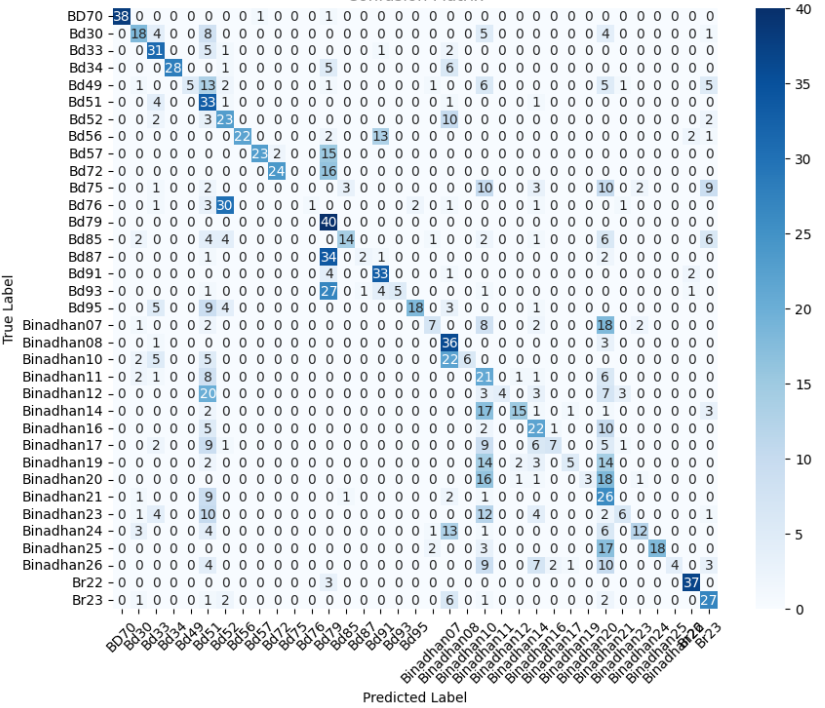
- Title: Evolving CNN Architectures From Custom Designs to Deep Residual Models for Diverse Image Classification and Detection Tasks
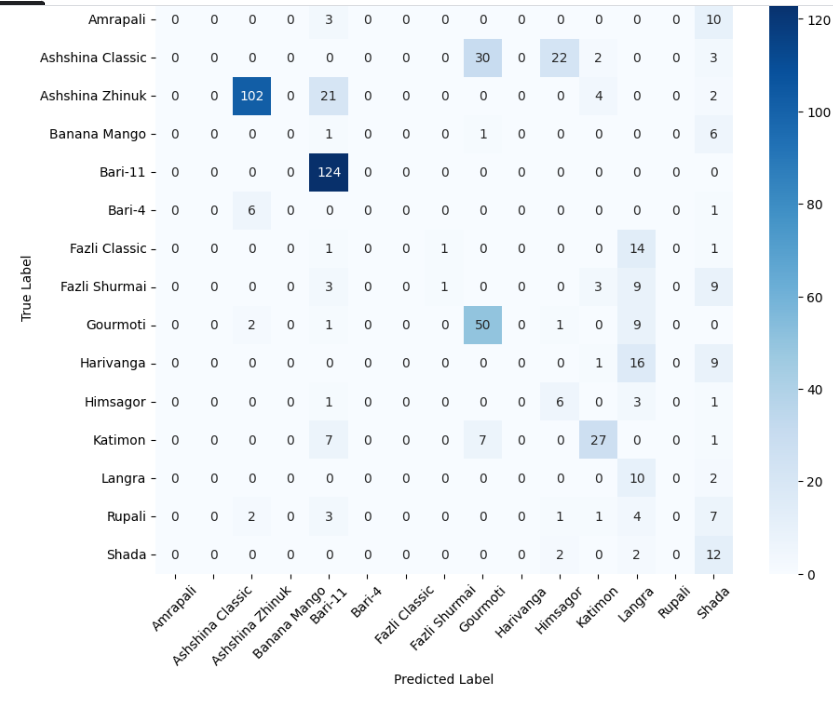
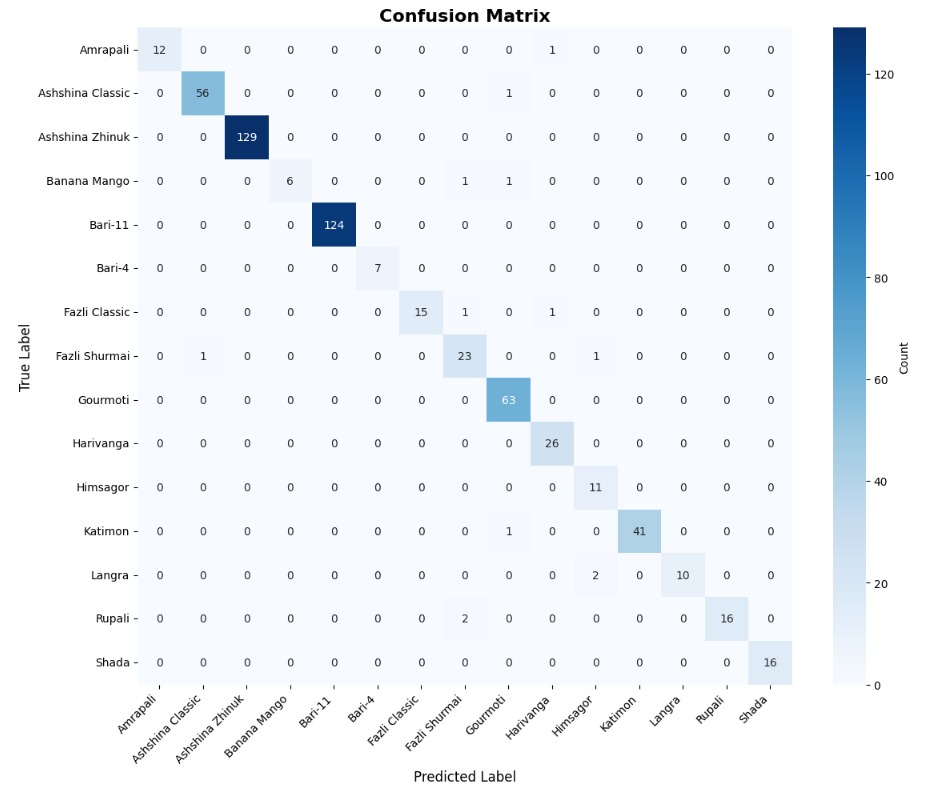
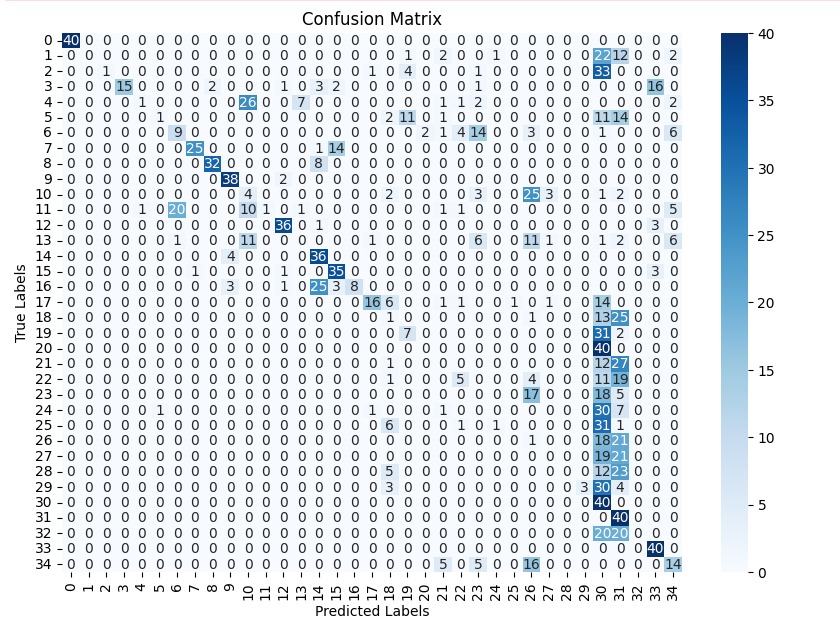
이 연구에서는 다섯 가지 다양한 이미지 데이터셋을 사용하여 CNN 기반 모델의 성능을 평가한다. 이 데이터셋들은 도로 상태 분석, 보도 침범 감지, 과일 종류 인식 및 벼 종류 분류와 같은 실용적인 실제 세계 문제를 다룬다. 우리는 고유한 커스텀 CNN 아키텍처와 기존 모델들인 MobileNet과 EfficientNet을 비교하며, 다양한 이미지 분류 작업에서의 성능 차이를 살펴본다.
1. **고유한 커스텀 CNN 아키텍처 개발**: 이 연구에서는 여러 이미지 분류 작업에 효율적으로 적용할 수 있는 고유한 커스텀 CNN 아키텍처를 설계했다. 이를 통해 모델의 복잡도와 표현력 사이에서 균형을 맞추고, 다양한 시각적 특성과 환경 조건에 대해 견고한 인식 성능을 제공할 수 있다.
# 서론
이미지 분류는 도시 감시, 농업, 환경 평가 및 자동 품질 관리와 같은 실제 시스템을 구동하는 딥러닝의 가장 널리 채택된 응용 분야 중 하나로 자리잡았다. 컨볼루셔널 신경망(CNN)은 원시 이미지에서 계층적인 시각적 특징을 직접 학습할 수 있는 능력 덕분에 이러한 발전의 중심적인 역할을 해왔다. 잘 알려진 아키텍처의 강한 성능에도 불구하고, 데이터셋이 규모, 도메인 복잡성 및 시각 분포 측면에서 크게 다르기 때문에 특정 작업에 맞는 컴팩트하고 특화된 CNN 모델을 설계하는 것이 여전히 중요하다.
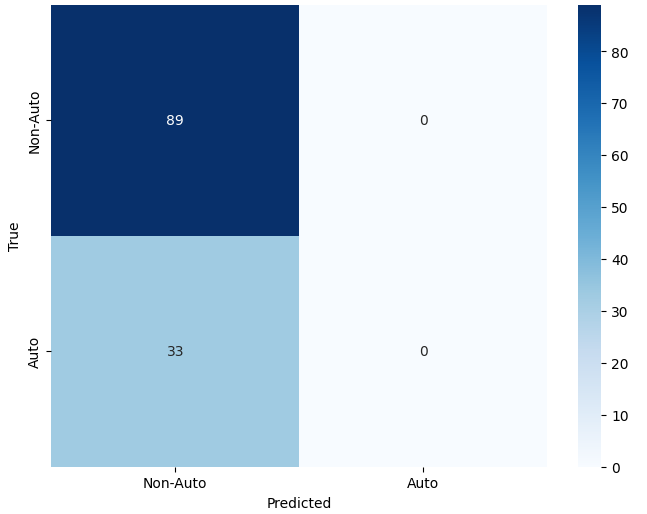
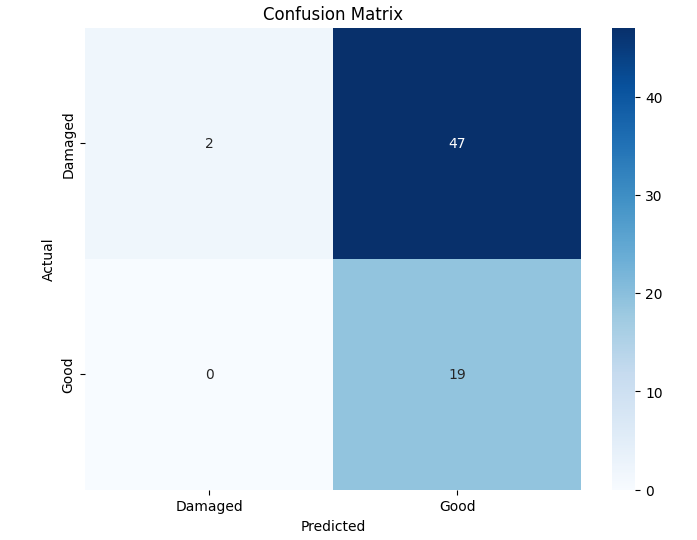
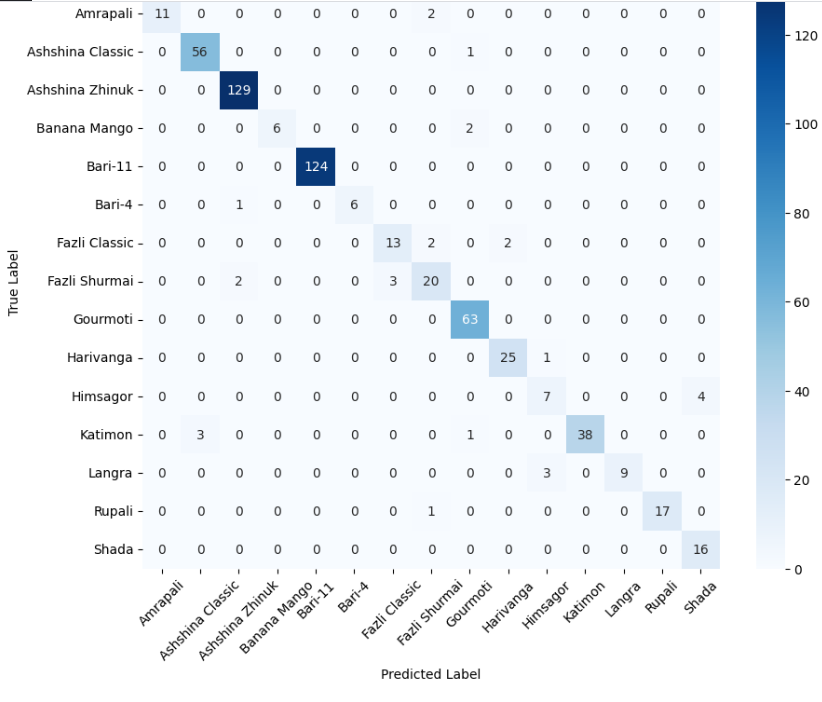
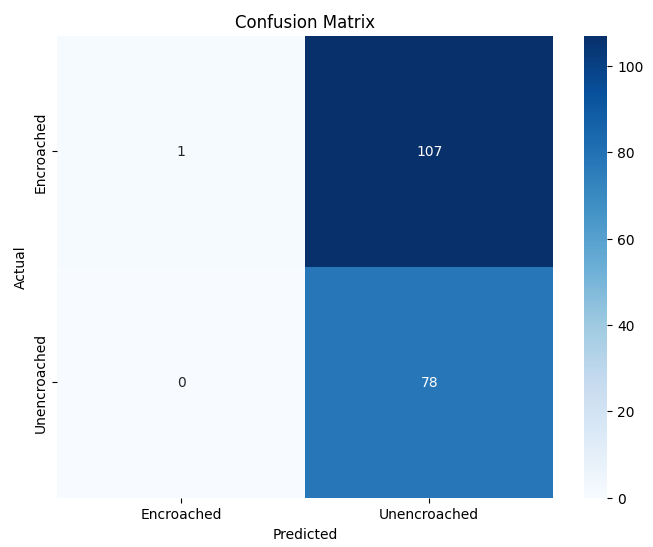
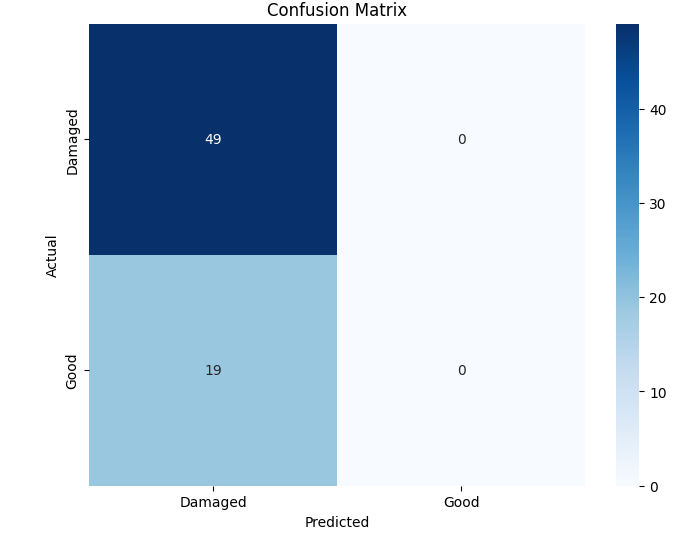
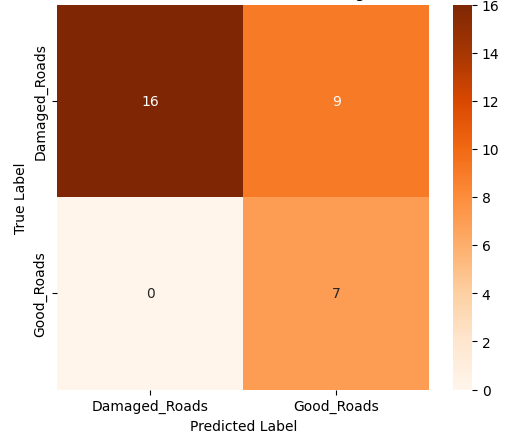
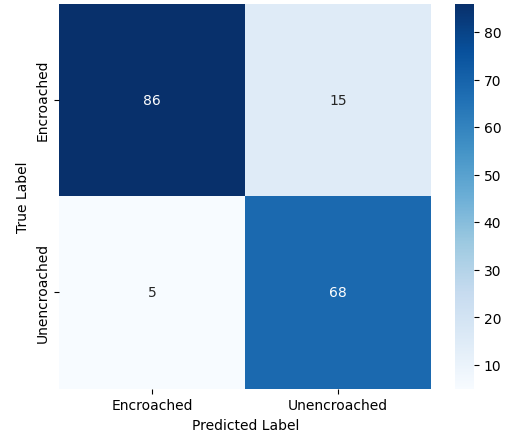
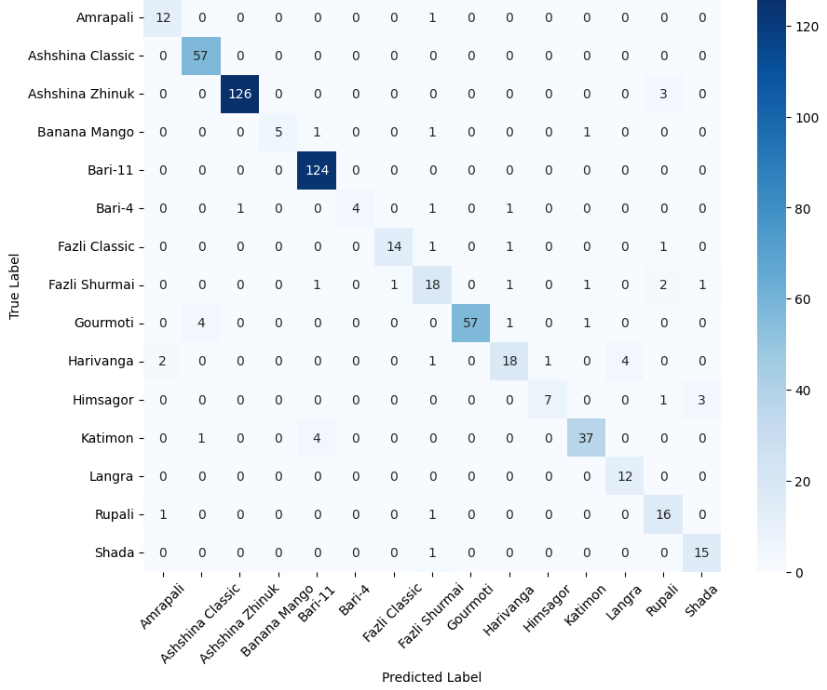
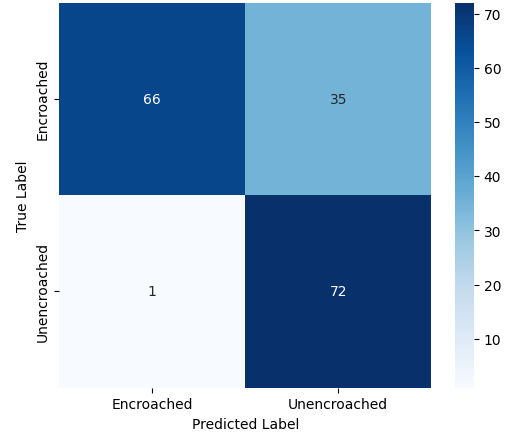
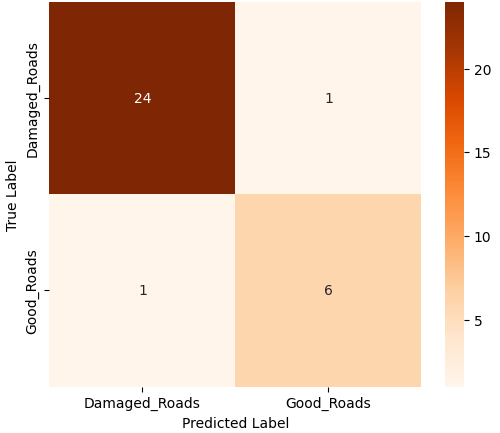
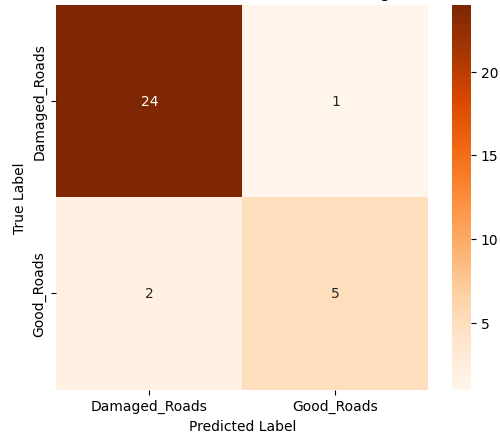
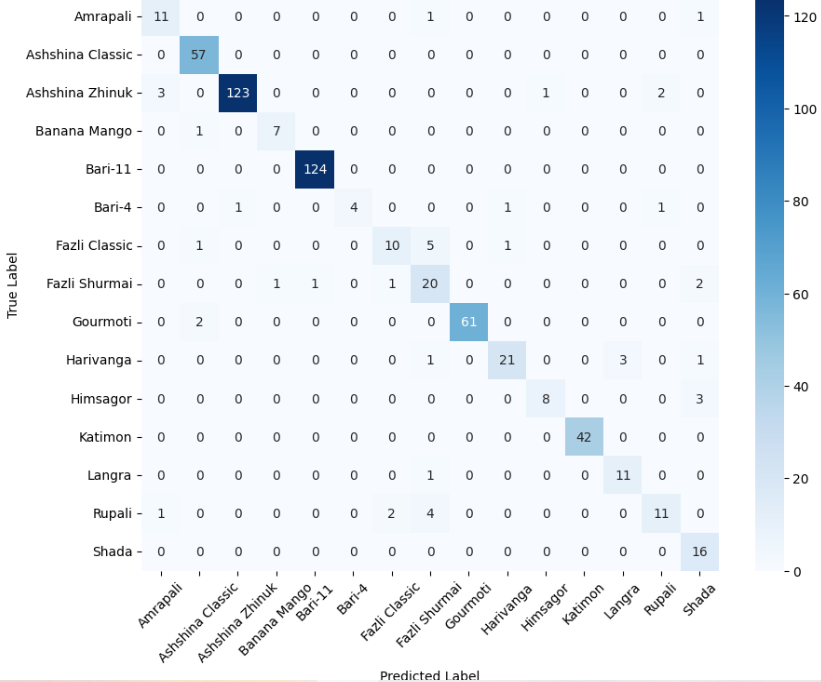
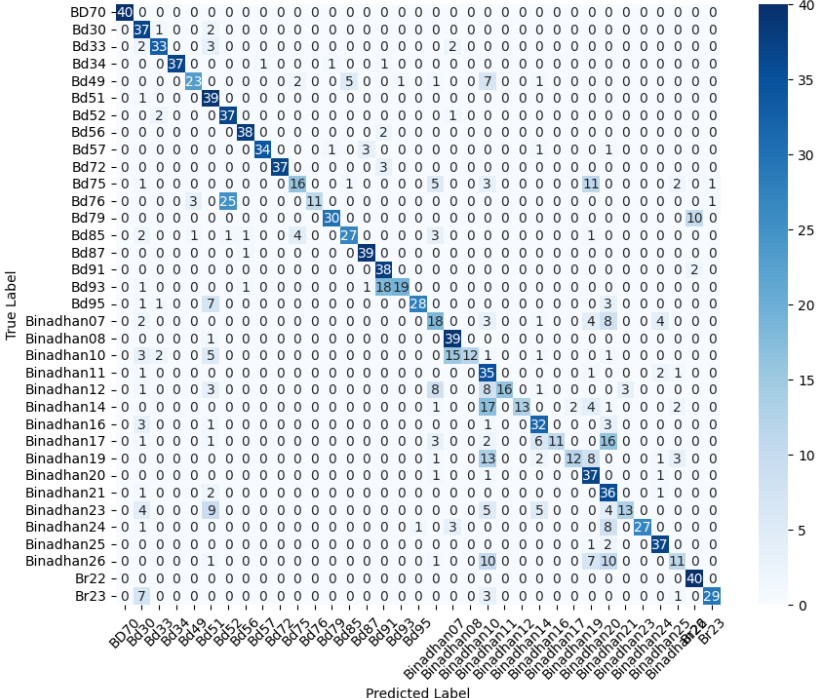
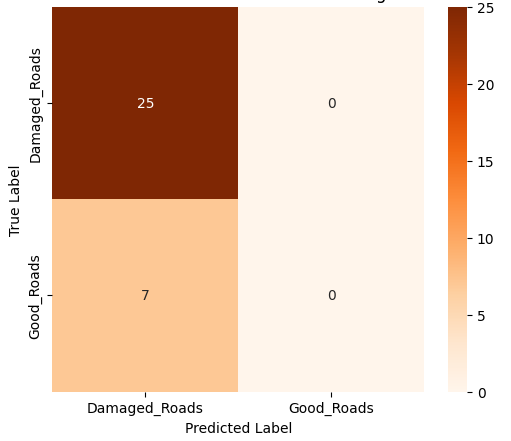
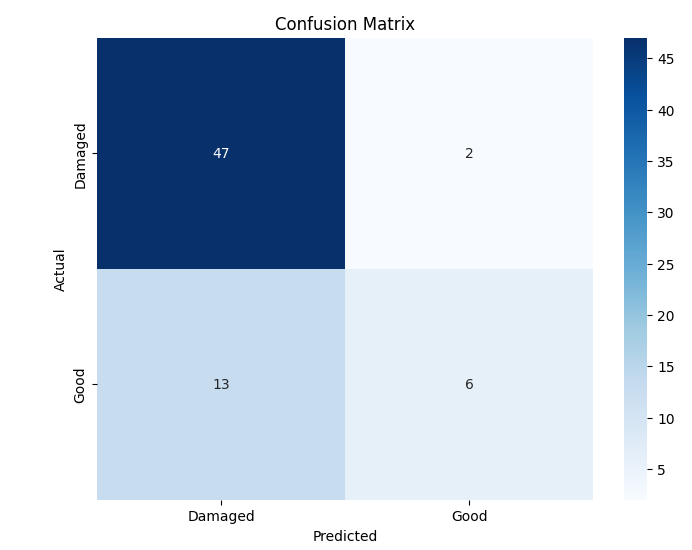
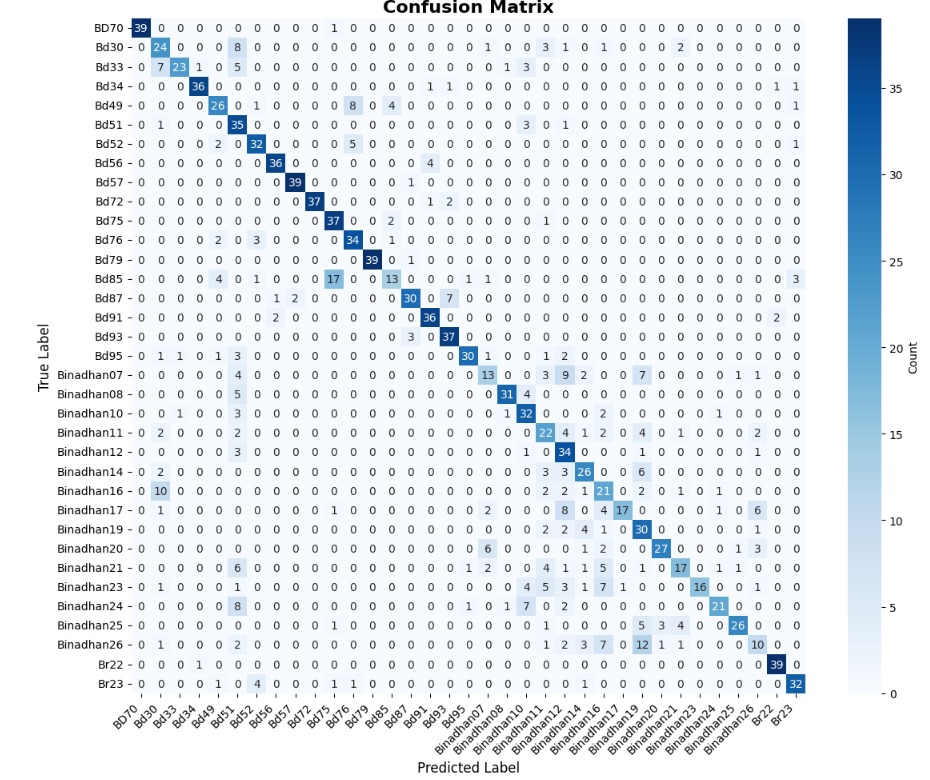
본 연구에서는 다섯 가지 다양한 이미지 데이터셋을 사용하여 CNN 기반 모델의 성능을 평가한다. 이 데이터셋들은 도로 표면 분석, 보도 침범 감지, 과일 종류 인식 및 벼 종류 분류와 같은 실용적인 실제 세계 문제를 다룬다. Road Damage 와 FootpathVision 데이터셋은 도시 인프라 모니터링에 중점을 둔 이진 분류 작업을 나타낸다. 이미지는 손상된 도로와 무손상 도로, 침범된 보도와 비침범된 보도의 상태를 포착한다. 반면 MangoImageBD 와 PaddyVarietyBD 데이터셋은 여러 가지 망고 종류 및 미세한 벼 씨앗을 식별하는 대규모 다중 클래스 문제를 제시한다.
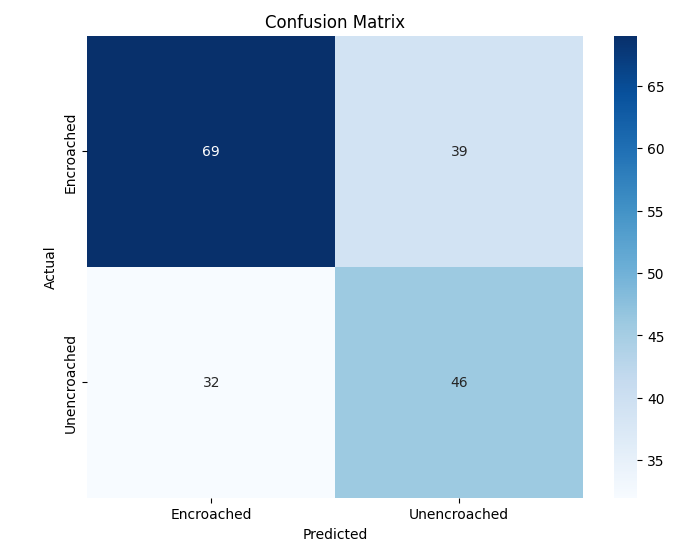
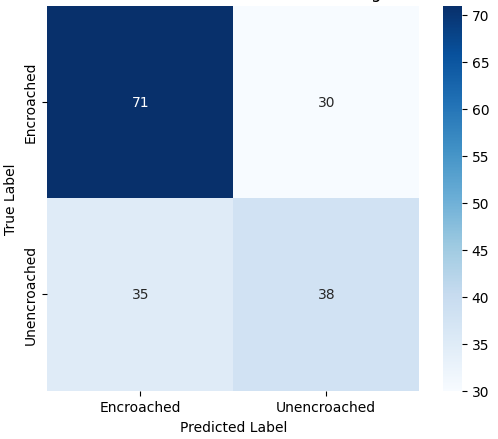
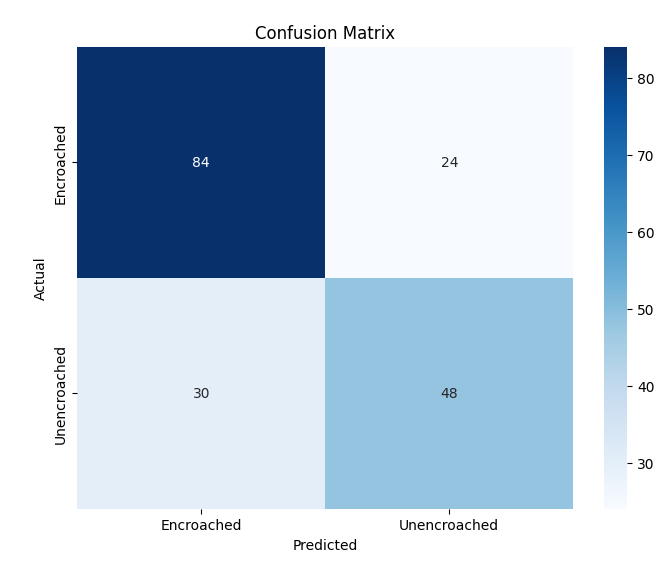
추가적으로, 복잡한 교통 장면에서 시각적으로 유사한 비동력 릭shaw와 구분되는 동력 릭shaw를 감지하기 위한 Auto-Rickshaw Detection 데이터셋을 포함한다. 이 데이터셋은 분류에 초점을 맞춘 CNN 아키텍처가 여러 개의 겹치는 객체를 포함하는 이미지에 어떻게 적응하는지를 보여준다. 이러한 데이터셋들은 변화하는 이미지 해상도, 시각적 특성 및 클래스 분포로 인해 종합적인 평가 환경을 제공한다.
이 다양성 때문에 표준 딥 아키텍처만으로 모든 작업에서 최적의 성능과 적응성을 얻는 것은 어렵다. 이는 특정 기능 패턴과 데이터셋 특성에 맞춰 설계된 커스텀 CNN 디자인을 탐색하는 동기를 부여한다. 본 연구에서는 고유한 컨볼루셔널 아키텍처를 조사하고, 점진적으로 단순화된 변형 및 진화된 기본 모델과 비교하여 다양한 도메인에서 다른 아키텍처 선택이 어떻게 성능에 영향을 미치는지 이해한다. 우리의 목표는 컨볼루션 구조, 잔차 연결 및 기능 추출 깊이의 수정이 이질적인 실제 세계 데이터셋에서 분류 정확도를 어떻게 영향시키는지를 체계적으로 분석하는 것이다. 이를 보완하기 위해, MobileNet과 EfficientNet이라는 널리 사용되는 사전 학습된 CNN 아키텍처에 대해 사전 학습 및 전이 학습 설정에서 성능을 평가하고, 이들 모델의 성능을 우리 커스텀 CNN의 최적 변형과 비교한다. 객체 인식 데이터셋에는 YOLO와 Faster R-CNN이라는 최신 감지 프레임워크를 채택하여 복잡한 교통 장면에서 로케이션 및 인식 성능을 평가한다.
제안된 커스텀 CNN 아키텍처
본 절에서는 다양한 이미지 분류 작업에 효율적으로 계층적인 시각적 특징을 추출하는 고유의 컨볼루셔널 신경망(CNN)을 소개한다. 우리의 목표는 모델 복잡도와 표현력 사이에서 균형을 맞추고, 다른 데이터셋에서 다양한 시각적 특성과 환경 조건에도 견고한 인식 성능을 제공하면서 실용적인 배포를 위한 파라미터 수를 관리하는 것이다.
아키텍처는 모듈식 구성 요소로 조직되어 원시 이미지 입력을 점진적으로 고수준의 의미 표현으로 변환한다. 우리는 간결한 컨볼루션 기능 추출기로 시작하여, 계산 효율성을 위해 깊이 분리형 컨벌루션(residual blocks)을 포함하고, 마지막으로 전역 정보를 집계하고 최종 예측을 생성하는 분류 헤드로 구성된다.
이 디자인은 네트워크가 다중 스케일 특징을 학습하고 복잡한 공간 의존성을 처리하며 다양한 객체 카테고리, 시각 도메인 및 환경 조건에 대해 견고함을 유지할 수 있도록 한다. 아키텍처의 각 구성 요소는 다음과 같이 상세하게 설명된다.
초기 기능 추출기: 3$`\times`$3 컨볼루션 계층 쌓기
특징 추출을 시작하기 위해, 우리의 커스텀 CNN은 세 개의 쌓인 3$`\times`$3 컨볼루션 계층으로 시작한다. 이 디자인은 VGG 네트워크가 작은 커널(예: 3$`\times`$3)을 더 효과적이고 파라미터 효율적으로 스택할 수 있다는 것을 보여준 것에서 영감을 받았다. 계층 사이에 여러 개의 비선형성을 사용하면 모델이 더 복잡한 로컬 패턴을 학습하는 데 도움이 된다.
초기 블록의 구성은 다음과 같다:
-
첫 번째 층은 필터 32개와 스트라이드 2를 갖는 3$`\times`$3 컨볼루션에 이어 Batch Normalization과 ReLU 활성화가 적용된다. 스트라이드는 공간 해상도를 줄이면서 중요한 저수준 특징을 유지한다.
-
두 번째 층은 필터 32개의 3$`\times`$3 컨볼루션에 이어 Batch Normalization과 ReLU 활성화가 적용된다. 스트라이드는 1이다.
-
세 번째 층은 필터 64개를 갖는 3$`\times`$3 컨볼루션에 이어 Batch Normalization과 ReLU 활성화가 적용된다.
-
마지막으로, 스트라이드 2와 풀 사이즈 3$`\times`$3을 가진 MaxPooling2D 계층이 적용되어 특징 맵을 추가로 다운샘플링하고 가장 중요한 특징만 유지한다.
이 초기 컨볼루션 스택은 모델이 네트워크의 초기 부분에서 국소적 공간 패턴을 캡처할 수 있는 효율적인 기능 추출기를 제공한다.
깊이 분리형 컨벌루션을 사용한 잔차 블록 디자인
우리 아키텍처의 핵심 구성 요소는 MobileNet에서 영감을 받은 고유의 잔차 블록이다. 이 설계는 전통적인 컨볼루션 계층 대신 DepthwiseConv2D와 Pointwise Conv2D(1$`\times`$1 컨볼루션)를 조합하여 파라미터 수와 계산 부하를 줄인다.
3$`\times`$3 컨볼루션이 모든 채널을 동시에 작동하는 반면, 깊이 분리형 컨볼루션은 각 입력 채널에 대해 독립적으로 하나의 필터를 적용한다. 이는 채널 혼합 없이 공간적 특징을 추출할 수 있게 한다. 이후 1$`\times`$1 포인트형 컨볼루션을 사용하여 채널 간에 출력을 재결합시켜, 채널 간 상호작용을 가능하게 한다.
잔차 블록의 구조는 다음과 같다:
-
DepthwiseConv2D 계층은 3$`\times`$3 커널과 선택 가능한 스트라이드를 갖는다. 이어 Batch Normalization이 적용된다.
-
Pointwise Conv2D(1$`\times`$1)을 사용하여 채널 정보를 섞고, 이어서 Batch Normalization과 ReLU 활성화가 적용된다.
-
두 번째 3$`\times`$3 컨볼루션 계층을 추가로 사용하여 특징 표현을 강화하고, 이어 Batch Normalization이 적용된다.
-
단축 연결(shortcut connection)은 입력 및 출력 차원이 다를 경우 1$`\times`$1 프로젝션을 사용한다.
-
마지막으로 요소별 덧셈과 ReLU 활성화가 수행되어 잔차 연결을 완료한다.
전체 아키텍처에서의 잔차 블록 쌓기
초기 3$`\times`$3 컨볼루션 계층 스택 이후, 나머지 아키텍처를 네 개의 연속적인 단계로 조직한다. 각 단계는 앞서 정의한 두 개의 고유 잔차 블록으로 구성된다. 필터 수는 단계별로 점진적으로 증가하여 모델이 점점 추상적이고 고차원적인 특징을 학습할 수 있도록 하고, 각 단계의 시작 부분에서 스트라이드 컨볼루션을 통해 공간 해상도를 줄인다.
전체 블록 구성은 다음과 같다:
-
단계 1: 필터 64개로 이루어진 두 개의 잔차 블록, 모두 스트라이드 1이다.
-
단계 2: 필터 128개로 이루어진 두 개의 잔차 블록. 첫 번째는 다운샘플링을 위해 스트라이드 2를 사용하고, 두 번째는 스트라이드 1을 사용한다.
-
단계 3: 필터 256개로 이루어진 두 개의 잔차 블록. 첫 번째는 스트라이드 2를 사용하고, 두 번째는 스트라이드 1을 사용한다.
-
단계 4: 필터 512개로 이루어진 두 개의 잔차 블록. 첫 번째는 스트라이드 2를 사용하고, 두 번째는 스트라이드 1을 사용한다.
이 계층적 쌓기 전략은 네트워크가 다양한 공간 해상도에서 특징을 추출하고 정제할 수 있게 하면서, 깊이 분리형 컨볼루션을 통해 효율성을 유지한다.
분류 헤드
최종 단계의 잔차 블록 이후, 네트워크는 공간적 특징 맵에서 분류에 적합한 간결한 표현으로 전환된다. 이를 위해 전역 평균 풀링(Global Average Pooling) 계층을 적용하여 각 특징 맵을 단일 값으로 집계한다. 이는 플래터닝보다 파라미터 수를 크게 줄이면서 가장 중요한 글로벌 특징을 유지하는 데 도움이 된다.
풀링 계층 이후, 128개 유닛과 ReLU 활성화를 갖는 완전 연결 계층을 추가한다. 이 계층은 추가 비선형성을 소개하고 컨볼루션 백본에서 추출된 고수준 특징을 결합할 수 있게 한다. 이 밀집 계층은 설계 변형을 통해 표현력 향상을 위해 의도적으로 추가되었다.
최종 출력 계층은 2개 유닛과 소프트맥스 활성화 함수를 갖는 Dense 계층으로, 이진 분류 작업에 적합하다. 전체 분류 헤드의 요약은 다음과 같다:
-
GlobalAveragePooling2D로 특징 맵을 글로벌 설명자로 변환한다.
-
**Dense(128)**과 ReLU 활성화를 사용하여 추가 학습된 특징 변환을 제공한다.
-
**Dense(2)**와 소프트맥스 활성화를 사용하여 이진 분류 출력을 생성한다.
중간 변형 및 진화
우리의 아키텍처 선택에 대한 이해와 탐구를 위해, 점진적으로 진화된 커스텀 CNN 아키텍처 변형을 조사한다. 각 변형은 원래 설계의 구성 요소에 특정 변화를 도입하여 개별적인 아키텍처 결정이 모델 성능에 어떤 영향을 미치는지 분석할 수 있다.
변형 A: 표준 잔차 블록
이 변형은 커스텀 모델에서 사용된 같은 초기 3$`\times`$3 컨볼루션 계층 스택과 완전 연결 분류 헤드를 유지한다. 그러나 잔차 블록을 전통적인 두 개의 층 구조로 대체한다.
모든 다른 아키텍처 구성 요소, 즉 필터 수, 네 단계 잔차 스택 전략 및 전역 평균 풀링은 변경되지 않는다.
변형 B: 초기 7$`\times`$7 컨볼루션
이 변형에서는 세 개의 쌓인 3$`\times`$3 컨볼루션 계층을 필터 수 2이고 스트라이드가 2인 단일 7$`\times`$7 컨볼루션 계층으로 대체한다. 이 구성은 첫 번째 층에서 더 넓은 수용장(field)을 제공하여 모델이 네트워크의 초기 부분에서 더 큰 공간 패턴을 캡처할 수 있게 한다.
나머지 아키텍처는 변형 A와 동일하며, 표준 컨볼루션 잔차 블록, 전역 평균 풀링 및 완전 연결 분류 헤드를 사용한다. 이 설계는 초기 계층의 깊이와 공간 추상화 사이의 트레이드오프를 탐색하고 초기 비선형성 감소 대신 더 큰 공간적 범위를 제공하는 효과를 이해하는 데 도움을 준다.
변형 C: 진화된 기본 모델
이 구성은 이진 분류 실험에서 모든 진화된 변형 중 가장 성능이 좋은 버전을 나타낸다. 이것은 변형 B에 추가적인 완전 연결 계층을 제거하여 분류 헤드를 단순화하는 방식으로 구축된다.
전체 구조는 다음과 같다:
-
초기 특징 추출을 위한 단일 7$`\times`$7 컨볼루션 계층.
-
네 개의 단계로 구성된 표준 컨볼루션 잔차 블록, 앞서 설명한 것과 동일하다.
-
전역 평균 풀링을 직접 적용하고 이진 분류를 위한 최종 Dense 계층에 소프트맥스 활성화를 사용한다.
이 모델은 균형잡힌 설계와 데이터셋 간의 우수한 성능으로 인해 진화된 기본 모델로 지칭된다. 이후 섹션에서 다른 변형을 평가하기 위한 참조점 역할을 한다.
병목 잔차 블록으로 확장
더 복잡한 다중 클래스 분류 작업을 처리하기 위해, 우리는 병목 잔차 블록을 도입하여 우리의 진화된 기본 모델을 확장한다. 이는 깊은 네트워크에서 계산 효율성과 기울기 흐름을 개선하는 것으로 알려진 설계로, 파라미터 수를 줄이면서 표현력을 유지함으로써 고해상도 이미지 인식에 적합하다.
각 병목 잔차 블록은 세 개의 컨볼루션 계층을 포함한다: 차원 축소를 위한 1$`\times`$1 컨볼루션, 공간적 특징 추출을 위한 3$`\times`$3 컨볼루션 및 채널 차원 복구를 위한 다른 1$`\times`$1 컨볼루션. 입력과 출력 차원이 일치하지 않을 때 단축 연결이 적용된다. 네트워크의 전체 구조는 각각 여러 개의 이러한 병목 블록으로 구성된 네 단계를 포함한다:
-
단계 1: 출력 차원 256을 가진 3개의 병목 잔차 블록. 첫 번째 블록에는 스트라이드가 1이더라도 프로젝션 단축 연결이 적용된다.
-
단계 2: 출력 차원 512를 가진 4개의 병목 잔차 블록. 첫 번째 블록은 공간 다운샘플링을 위해 스트라이드가 2이다.
-
단계 3: 출력 차원 1024를 가진 6개의 병목 잔차 블록. 다시 첫 번째 블록에서 스트라이드 2로 다운샘플링이 수행된다.
-
단계 4: 출력 차원 2048을 가진 3개의 병목 잔차 블록으로 시작하는 단축 블록.
이 더 깊은 아키텍처는 다양한 데이터셋에서 큰 수의 클래스를 구분하기 위해 필요한 계층적 특징을 더 잘 캡처할 수 있도록 한다. 모든 단계는 전역 평균 풀링 계층과 적절한 출력 클래스 수에 대한 밀집 분류 헤드로 끝난다.
객체 수준 감지용 적응
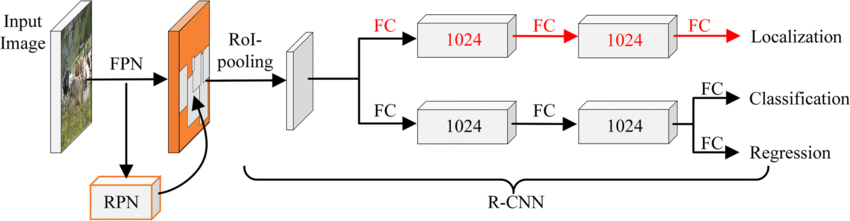
교통 장면에서 오토릭샤를 감지하기 위한 객체 수준 감지 작업에서는 YOLO와 같은 단계별 감지기의 핵심 원칙을 기반으로 하면서 우리의 데이터셋 및 실험 범위에 맞게 간소화된 형태로 설계된 가벼운 커스텀 감지 모델을 채택한다. 이 모델은 분류에 초점을 맞춘 CNN 아키텍처와 달리, 통합된 프레임워크 내에서 객체 카테고리 레이블과 바운딩 박스 좌표를 동시에 예측하도록 설계되었다.
제안된 감지 네트워크인 MiniYOLO는 간결한 컨볼루션 백본을 포함하고 통합 예측 헤드로 구성된다. 백본은 점진적으로 증가하는 채널 깊이(16, 32, 64 및 128 필터)를 갖는 $`3\times3`$ 커널을 사용한 볼루션 계층 시퀀스로 구성되며, LeakyReLU 활성화가 적용된다. 초기 컨볼루션 블록 후에는 Max-pooling 계층이 적용되어 점진적으로 공간 해상도를 줄이며 중요한 시각적 특징을 유지한다. 특징 추출기의 마지막에는 고정된 차원 표현을 생성하기 위해 적응형 평균 풀링 계층이 사용된다.