- Title: ScienceDB AI An LLM-Driven Agentic Recommender System for Large-Scale Scientific Data Sharing Services
- ArXiv ID: 2601.01118
- 발행일: 2026-01-03
- 저자: Qingqing Long, Haotian Chen, Chenyang Zhao, Xiaolei Du, Xuezhi Wang, Pengyao Wang, Chengzan Li, Yuanchun Zhou, Hengshu Zhu
📝 초록
과학기술용 AI(Science4AI)의 급속한 성장은 과학 데이터셋의 중요성을 부각시켰고, 그 결과 많은 국가적 수준의 과학 데이터 센터와 공유 플랫폼이 설립되었습니다. 그러나 이러한 발전에도 불구하고, 과학 연구를 위한 데이터셋의 효율적인 공유와 활용을 촉진하는 것은 여전히 어려운 문제입니다. 과학 데이터셋은 복잡한 도메인 특화된 지식과 맥락을 포함하고 있어, 기존의 협업 필터링 기반 추천 시스템이 적합하지 않습니다. 대형 언어 모델(LLMs)의 최근 발전은 깊은 의미 이해와 개인화된 추천이 가능한 대화형 에이전트 구축에 대한 전례 없는 기회를 제공합니다. 이에 따라 우리는 과학데이터뱅크(ScienceDB), 세계 최대 규모의 과학 데이터 공유 플랫폼 중 하나에서 개발한 새로운 LLM 기반 에이전트 추천 시스템인 ScienceDB AI를 소개합니다. ScienceDB AI는 자연어 대화와 깊은 추론을 활용하여 연구자의 과학적 의도와 변화하는 요구사항에 맞춘 데이터셋을 정확하게 추천합니다. 이 시스템은 다음과 같은 혁신들을 도입하고 있습니다: 복잡한 쿼리에서 구조화된 실험 요소를 추출하는 Scientific Intention Perceptor, 다중 회차 대화를 효과적으로 관리하는 Structured Memory Compressor, 신뢰성 있는 검색 강화 생성(Trustworthy RAG) 프레임워크입니다. Trustworthy RAG는 두 단계의 검색 메커니즘을 사용하고 Citable Scientific Task Record(CSTR) 식별자를 통해 인용 가능한 데이터셋 참조를 제공하여 추천의 신뢰성과 재현성을 향상시킵니다. 과학적 연구에 활용되는 1,000만 개 이상의 실제 데이터셋을 사용한 광범위한 오프라인 및 온라인 실험을 통해 ScienceDB AI는 중대한 효과를 입증했습니다. 우리의 지식으로는, ScienceDB AI가 대규모 과학적 데이터셋 공유 서비스에 특화된 첫 번째 LLM 기반 대화형 추천 시스템입니다. 이 플랫폼은 다음 링크에서 공개적으로 이용 가능합니다: https://ai.scidb.cn/en.
💡 논문 해설
**기여 1: 실험 의도 인식기 개발**
- **간단한 설명**: 실험 의도 인식기는 연구자의 복잡한 데이터셋 요구사항을 이해하고 이를 구조화된 형태로 추출합니다.
- **비유**: 이 시스템은 연구자가 원하는 케이크의 레시피를 정확히 이해하고, 필요한 재료와 조리 방법을 명시적으로 기록해주는 것과 같습니다.
기여 2: 구조화된 메모리 압축기 도입
간단한 설명: 이 컴포넌트는 사용자의 의도, 대화 컨텍스트, 그리고 도구 호출을 추적하고 이를 요약하여 LLM의 제한된 컨텍스트 윈도우 문제를 해결합니다.
비유: 구조화된 메모리 압축기는 연구자가 장기적으로 진행하는 프로젝트에서 중요한 이전 정보를 정리해두고 필요할 때마다 쉽게 찾아볼 수 있도록 해주는 도구입니다.
기여 3: 신뢰성 있는 추출 강화 생성(RAG) 프레임워크 제안
간단한 설명: 신뢰성 있는 RAG는 데이터셋 추천의 정확성을 높이면서, 연구자가 필요한 실제 존재하는 데이터셋을 찾을 수 있도록 합니다.
비유: 이 시스템은 도서관에서 원하는 책을 찾기 위해 구체적인 정보를 제공해주는 도우미와 같습니다. 이 도우미는 책의 제목과 저자를 알려주고, 해당 책이 실제로 도서관에 있는지 확인합니다.
📄 논문 발췌 (ArXiv Source)
# 소개
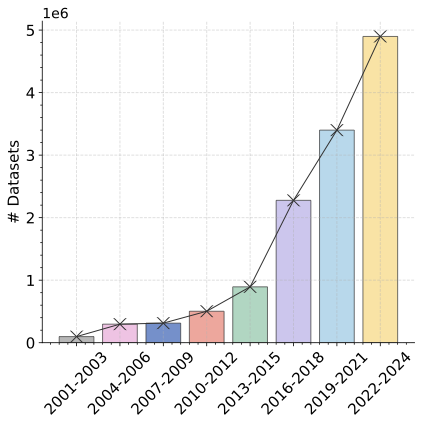
과학을 위한 인공지능(AI4S)의 급속한 발전은 생물학, 물리학, 화학 및 지구과학 등 다양한 분야에서 발견을 가속화하기 위해 고품질 과학 데이터의 중요성을 강조하고 있습니다. 이러한 반응으로, 전 세계 정부와 연구 기관들은 국가적인 과학 데이터 센터와 데이터셋 공유 플랫폼을 설립했습니다. NCBI, OpenAIRE 및 ScienceDB 등이 여기에 해당하며, 이들 초기단계는 개방형 접근을 촉진하고 공동 사용을 통해 과학 데이터의 재사용성을 향상시킵니다. 그 결과, 최근 몇 년 동안 새로 공개된 과학 데이터셋 수가 크게 증가하였습니다. 이를 Fig.1 (a)에서 확인할 수 있습니다.
데이터셋과 사용자 행동의 통계 결과.
과학 데이터셋의 빠른 성장에 따라 연구자가 관련 데이터셋을 효율적으로 찾는 것이 점점 더 중요해졌습니다. 효과적인 데이터셋 추천 시스템은 데이터 기반 과학적 발견을 촉진하는 데 필수적입니다. 전통적인 데이터셋 추천기는 대체로 두 가지 범주에 속합니다. 첫 번째는 사용자 상호작용 이력을 활용하는 행동 기반 추천기이며, 이를 위해 협업 필터링(CF)과 그래프 표현 학습(GRL) 같은 방법을 사용합니다. 두 번째는 질의 자체에 의존하는 내용 기반 추천기로, 키워드 기반 검색과 의미 임베딩 기반 일치를 포함합니다. 현재 Google Dataset Search, DataCite Commons, OpenAIRE 및 Dryad와 같은 데이터셋 공유 플랫폼은 여전히 키워드 기반 검색 엔진에 크게 의존하고 있습니다. 그들의 자세한 정보는 표 [tab:compare_product]에서 확인할 수 있습니다.
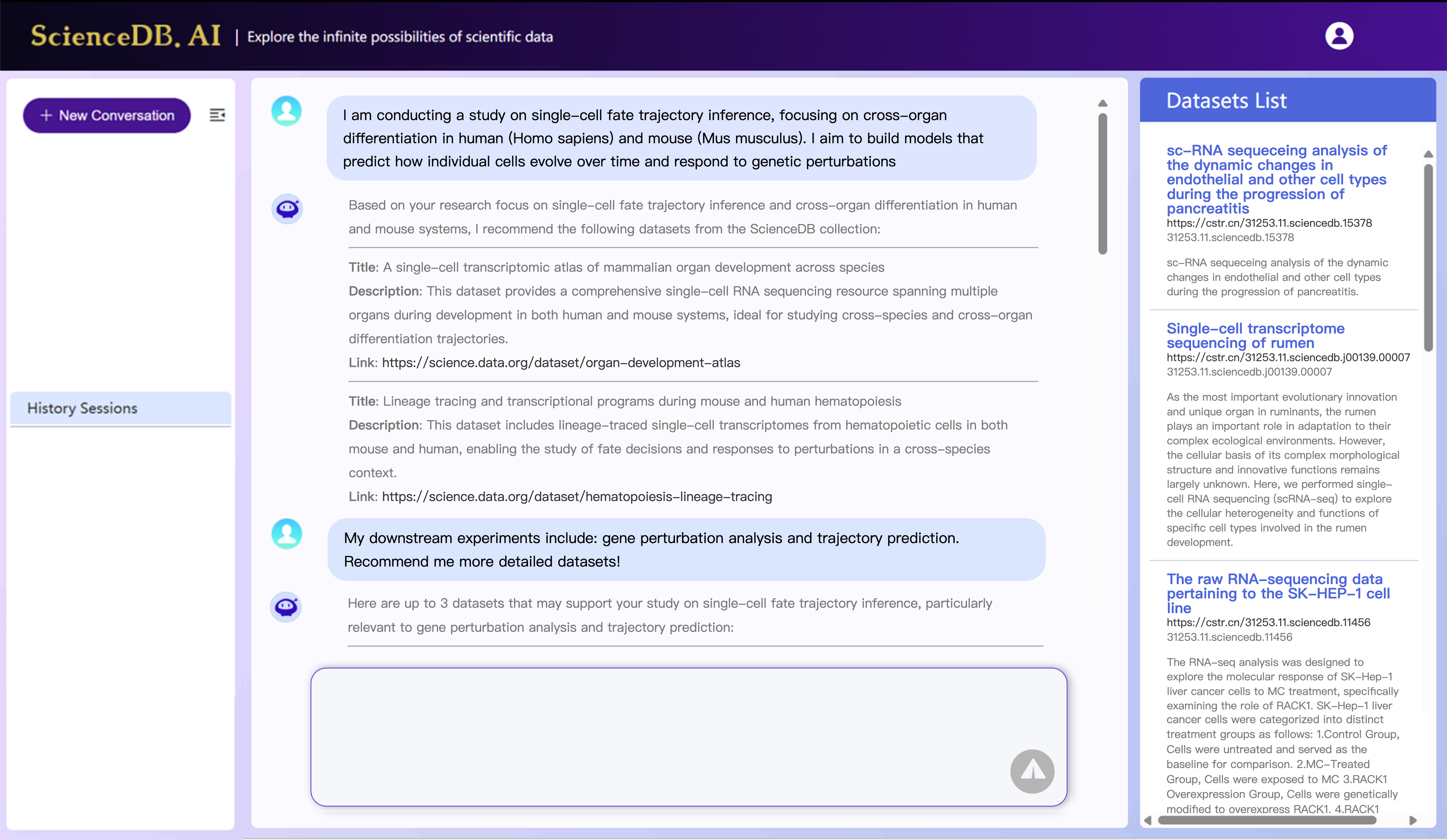
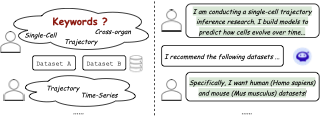
우리의 동기화를 설명한 그림. 왼쪽 그림은 현재 데이터셋 공유 플랫폼이 직면하고 있는 도전을 보여줍니다. 오른쪽 그림은 ScienceDB AI가 연구자의 실험적인 데이터셋 필요성을 깊이 이해할 수 있음을 설명합니다.
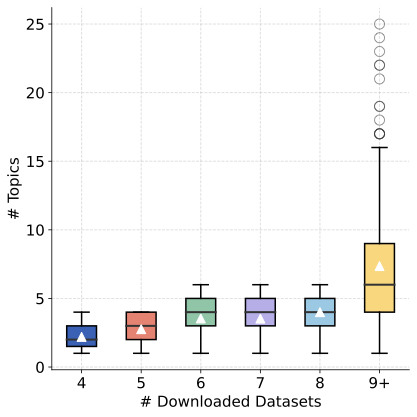
(1) 과학적 데이터셋 요구는 자주 특정 작업에 관련되어 있으며, 과거 행동과 무관입니다. Fig.1 (b)에서 보듯이 x축은 연구자가 ScienceDB에서 이전에 다운로드한 데이터셋의 수를 나타내며, y축은 다양한 주제의 개수를 나타냅니다. 9개 이상(총량의 약 10%)을 다운로드한 연구자들은 그룹화됩니다. 이 그림은 연구자의 다운로드 이력에 걸친 주제 일관성이 떨어진다는 것을 보여주며, 이는 데이터셋 요구가 지속적인 선호도보다 변화하는 연구 작업에 의해 더 많이 구동된다는 것을 암시합니다. 그러나 사용자 행동 기반 추천기는 우리의 상황에서 적합하지 않습니다.
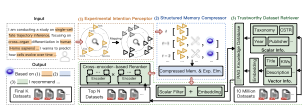
(2) 현재 컨텍스트 기반 추천기들은 실험 수준의 데이터셋 요구를 이해하는 데 부족함이 있습니다. 과학적 탐구는 풍부한 자연 언어 설명을 통해 표현되는 매우 특정적이고 변화하며 세밀한 데이터셋 요구사항을 포함합니다. 전통적인 키워드 검색이나 임베딩 기반 일치는 이러한 복잡한 요구사항을 이해하는 데 부족함이 있습니다. 예를 들어, Fig.2에서 보듯이 연구자가 다음과 같이 질의할 수 있습니다: “나는 인간(Homo sapiens)과 쥐(Mus musculus) 사이의 교차 장기 분화에 대한 단일 세포 운명 궤적 추론을 수행하는 연구를 진행하고 있습니다. 개인 세포가 시간에 따라 어떻게 진화하고 유전학적 변화에 반응하는지 예측하기 위한 모델을 구축하려고 합니다.” 이러한 자세한 및 도메인별 의도는 깊은 컨텍스트 이해가 필요하며, 현재의 컨텍스트 기반 추천기는 효과적으로 처리할 수 없습니다.
행운하게도, 최근 LLMs과 에이전트를 활용한 대화형 추천 시스템의 발전은 우리의 문제 해결에 희망적인 방향을 제시합니다. 그러나 이러한 모델들은 본질적으로 환상 생성 및 잊어버리기 문제가 있습니다. 존재하지 않거나 접근할 수 없는 데이터셋을 생성할 수 있다는 것입니다. 이는 신뢰성, 접근성, 그리고 인용 가능한 것이 기본 요구 사항인 과학적 상황에서 큰 도전이 됩니다.
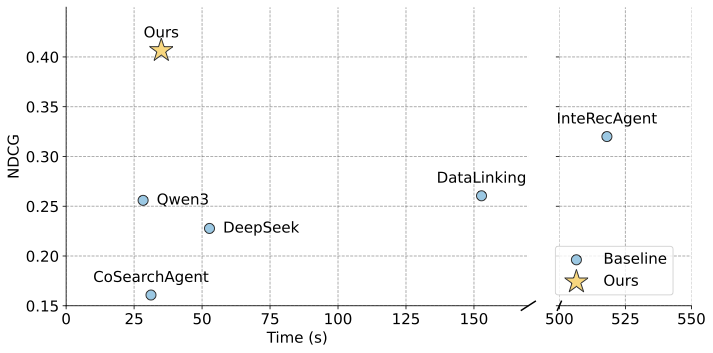
이에 대응하여 우리는 ScienceDB AI를 제안합니다. 이는 대규모 과학 데이터 공유 서비스를 위한 지능형 에이전트 추천 시스템입니다. 우리의 시스템은 1000만 개 이상의 사용 가능한 데이터셋 저장소에서 작동하고, 신뢰성, 접근성, 그리고 인용 가능성을 지원하기 위해 몇 가지 핵심 구성 요소를 도입합니다. 첫째, 우리는 연구자의 데이터, 주제, 제약 조건, 평가 기준을 구조화된 의도 템플릿으로 추출하는 실험 의도 감지기를 개발했습니다. 둘째로, 우리는 다중 회차 대화에서 사용자 의도, 대화 컨텍스트 및 도구 호출을 추적하고 관련 역사 정보를 요약하여 LLM의 제한된 컨텍스트 윈도우 문제를 해결하는 구조화된 메모리 압축기를 소개합니다. 셋째로, 환상 생성 문제를 해결하기 위해 신뢰성 있는 추출 강화 생성(Trustworthy RAG) 프레임워크를 제안합니다. 이는 대규모 설정에서 검색 효율과 효과성을 균형 있게 유지하는 두 단계의 검색기를 통합합니다. 데이터셋 흔적ability 및 인용 가능성 보장을 위해 각 데이터셋에 Citable Scientific Task Record (CSTR)을 연결하고 시스템 응답에 직접적인 링크를 포함시킵니다. 우리는 ScienceDB 플랫폼에서 1000만 개 이상의 실제 과학 데이터셋에 대한 광범위한 오프라인 및 온라인 평가를 수행했습니다. ScienceDB AI는 기존 에이전트 기반 추천기보다 오프라인 지표에서 30% 이상 향상되었습니다. 또한 온라인 A/B 테스트에서는 전통적인 키워드 검색 시스템에 비해 클릭률(CTR)이 200% 이상 증가하였습니다.