그래프 신경망(GNN)은 사회적 네트워크, 분자 화학 등 다양한 영역에서 뛰어난 성과를 보여주고 있다. GNN의 핵심 구성 요소 중 하나는 풀링 프로시저로, 모델에 의해 계산된 노드 특징을 조합하여 최종적으로 하류 작업에 사용될 정보가 풍부한 설명자 형태로 만들어내는 과정이다. 그러나 이전의 그래프 풀링 방식은 풀링이나 분류기 층에 GNN 마지막 계층의 특징을 입력으로 사용하므로, 모델의 전방 패스 중 생성된 이전 계층의 중요한 활성화를 충분히 활용하지 못하는 경우가 있다. 이를 우리는 역사적 그래프 활성화라고 부른다. 특히 많은 그래프 신경망 계층을 통과하면서 노드 표현이 크게 변화할 수 있는 경우, 또는 깊은 아키텍처에서 과도한 평활화와 같은 그래프 특수 도전 과제로 인해 이러한 간극이 더욱 두드러진다. 이 간극을 해소하기 위해 우리는 HISTOGRAPH라는 새로운 단계별 주의 기반 최종 통합 층을 제안한다. HISTOGRAPH는 중간 활성화에 대해 일관된 계층별 주의를 적용한 후 노드별 주의를 사용한다. 노드 표현의 계층 간 진화를 모델링함으로써, 우리의 HISTOGRAPH는 노드의 활성화 기록과 그래프 구조 모두를 활용하여 최종 예측에 사용되는 특징을 정교하게 세분화한다. 여러 그래프 분류 벤치마크에서의 실증적 결과는 HISTOGRAPH가 전통적인 방법보다 일관되게 우수한 성능을 제공하며, 특히 깊은 GNN에서 강력한 견고성을 보여준다는 것을 입증하고 있다.
💡 논문 해설
1. **기여 1: 자기 반성적 아키텍처 패러다임**
그래프 신경망(GNN)은 노드 특징을 여러 계층에서 추적하고 이를 통합하여 더 정확한 예측을 가능하게 합니다. 이는 마치 학생이 과거 시험 결과를 분석해 다음 시험 준비를 잘하는 것과 같습니다.
기여 2: HistoGraph 메커니즘
HistoGraph는 계층별 노드 임베딩의 변화와 공간적 상호작용을 분리하고 모델링합니다. 이는 마치 사진에 여러 필터를 적용해 더 많은 정보를 얻는 것과 같습니다.
기여 3: 다양한 태스크에서의 성능 향상
HistoGraph는 그래프 수준 분류, 노드 분류, 링크 예측 등 다양한 태스크에서 기존 모델을 능가하는 성능을 보입니다. 이는 마치 여러 종류의 문제를 해결할 때마다 항상 최고 점수를 얻는 학생과 같습니다.
📄 논문 발췌 (ArXiv Source)
maketitle 감사 aketitle
소개
그래프 신경망(GNNs)은 분자 속성 예측 및 추천과 같은 그래프 구조 태스크에서 강력한 성능을 보여왔습니다. 최근의 발전 사항에는 표현력이 높은 계층, 위치 및 구조적 인코딩, 그리고 풀링 등이 포함됩니다. 그러나 현재까지의 풀링 계층은 메시지 패싱 과정에서 생성된 중간 활성화를 충분히 활용하지 못하고 있어 장거리 종속성과 계층적인 패턴을 포착하는 데 제약이 있습니다.
GNNs에서는 계층들이 여러 스케일의 정보를 포착합니다: 초기 계층은 지역 네트워크와 모티프를, 더 깊은 계층은 전역 패턴(커뮤니티, 장거리 종속성, 위상적 역할)을 모델링하며, 이는 CNNs에서 얕은 계층이 에지/텍스처를 감지하고 깊은 계층이 객체 의미론을 포착하는 것과 유사합니다. 더 큰 깊이는 초기 정보를 덮어쓰고 과도한 스무딩으로 인해 노드 표현을 구분하기 어려워질 수 있습니다. 이를 해결하기 위해 역사적 그래프 활성화, 즉 모든 계층에서 생성된 표현들을 통합하여 읽기 단계에서 다중 스케일 특징을 결합합니다.
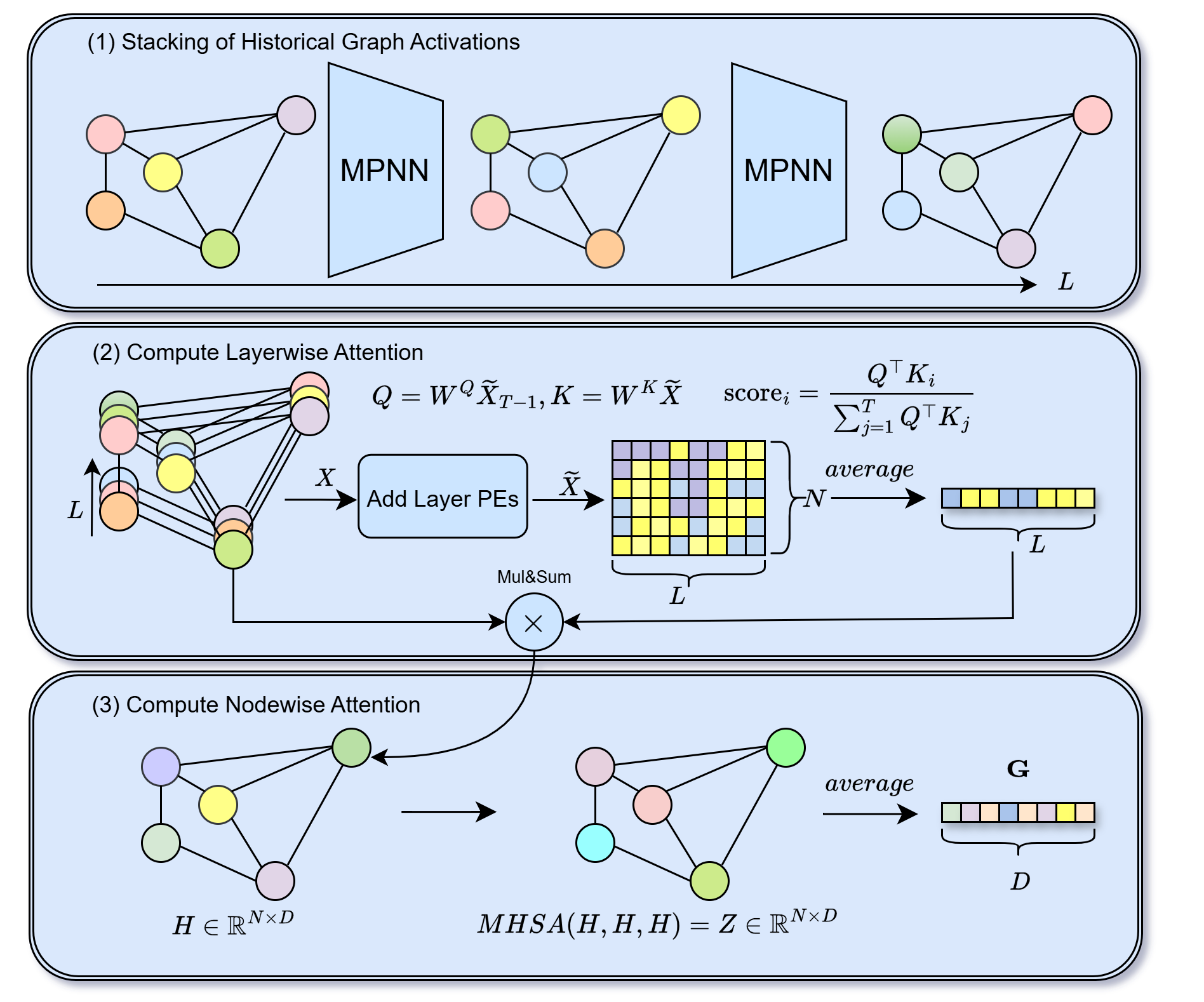
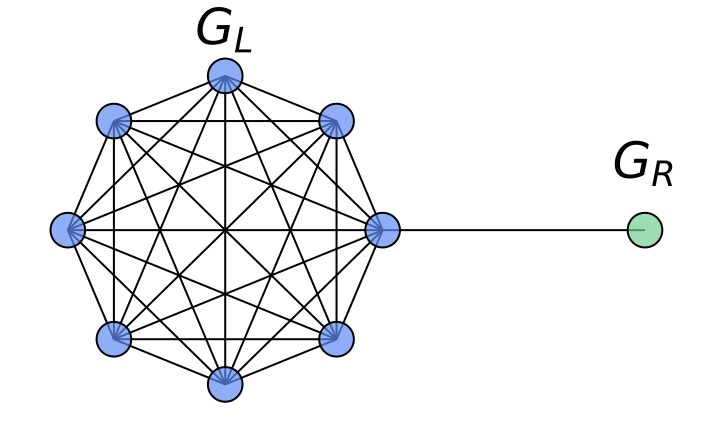
HistoGraph 개요. (1) 입력 노드 특징 X0와 인접성 A가 주어지면 백본 GNN은 역사적 그래프 활성화 X1, .., XL − 1를 생성한다. (2) 계층별 주의 모듈은 최종 계층 임베딩을 쿼리로 사용하여 모든 역사적 상태에 대해 주의를 집중하고 노드를 통해 평균화하여 각 노드에 대한 집계된 임베딩 H을 생성한다. (3) 노드별 자기 주의 모듈은 노드 간 상호작용을 모델링하여 H를 정제하고, 그래프 임베딩 G를 얻기 위해 평균화한다.
여러 연구가 더 깊은 표현의 중요성, 잔차 연결, 그리고 표현력 있는 집계 메커니즘을 탐구하여 이러한 제한을 극복하려는 시도를 했습니다. 우리의 접근 방식과 비슷한 전문적인 방법으로는 그래프에서 초기화 기법에 의해 얻어진 노드 특징의 시퀀스를 고려하는 상태 공간 및 자기 회귀 이동 평균 모델들이 있습니다. 그러나 이러한 노력은 주로 훈련 중의 안정성을 개선하는 데 초점을 맞추고 있으며, 계층을 통해 노드 특징의 내부 궤적을 명시적으로 모델링하지는 않습니다. 즉, 우리는 GNN의 계산 경로와 계층을 통과하는 노드 특징의 시퀀스가 중요한 신호가 될 수 있다고 주장합니다. 이러한 궤적에 대한 반성은 모델이 어떤 변형이 유익했는지 이해하고 최종 예측을 더 정교하게 조정할 수 있게 합니다.
본 연구에서는 자기 반성적 아키텍처 패러다임인 HistoGraph를 제안합니다. HistoGraph는 GNN이 역사적 그래프 활성화에 대해 추론하도록 합니다.
HistoGraph은 계층 간 노드 임베딩의 진화와 그들의 공간적인 상호작용을 분리하고 모델링하는 두 단계 자기 주의 메커니즘을 도입합니다. 계층별 모듈은 각 노드의 계층 표현을 시퀀스로 취급하여 가장 정보가 많은 표현에 대해 학습할 수 있도록 합니다. 노드별 모듈은 전역 컨텍스트를 집약하여 더 풍부하고 컨텍스트 인식이 가능한 출력을 형성합니다.
HistoGraph의 설계는 기본 GNN 아키텍처를 수정하지 않고도 중간 표현에 부호화된 풍부한 정보를 활용하여 다양한 그래프 관련 예측(그래프 분류, 노드 분류 및 링크 예측)을 강화합니다.
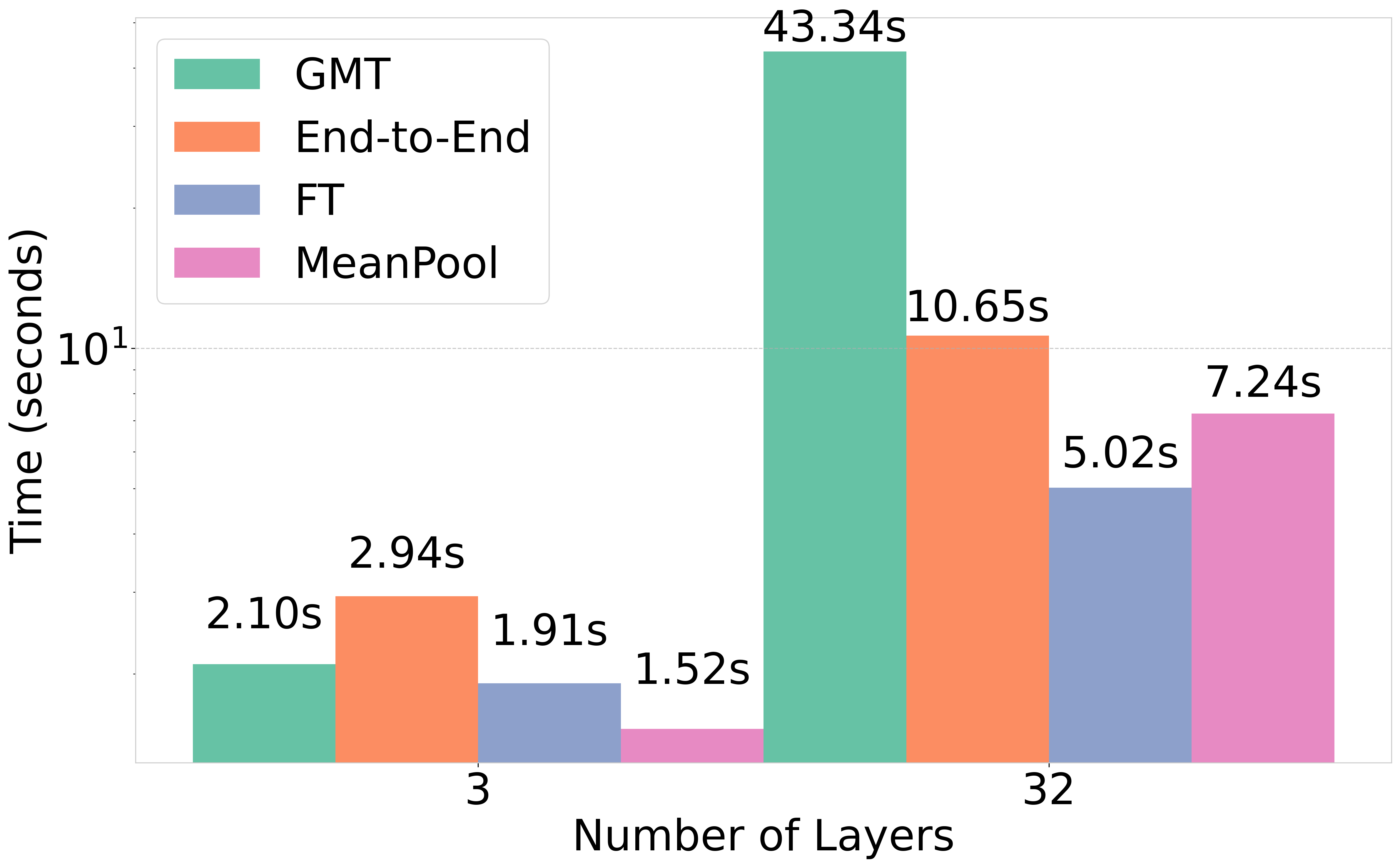
HistoGraph는 두 가지 보완적인 모드로 적용됩니다: (1) 백본과 함께 엔드-투-엔드 합성 훈련, 그리고 (2) 동결된 사전 학습 GNN 위의 가벼운 머리 부분으로 후처리. 엔드-투-엔드 변형은 중간 표현을 풍부하게 만들고, 후처리 변형은 머리 부분만 훈련하여 최소한의 부가적인 오버헤드로 큰 성능 향상을 얻습니다.
HistoGraph는 TU와 OGB 벤치마크에서 강력한 GNN 및 풀링 기저 모델을 능가하며, 계산 역사가 강력하고 일반적인 근거를 제공한다는 것을 보여줍니다. 그림 1은 HistoGraph의 개요를 보여줍니다.
주요 기여: (1) GNN이 계층을 통해 노드 임베딩의 전체 궤적을 활용하는 자기 반성적 아키텍처 패러다임을 소개합니다; (2) 계층 간 노드 임베딩의 진화와 노드 특징의 공간적 집합을 분리하고 모델링하는 두 단계 자기 주의 메커니즘인 HistoGraph를 제안합니다; (3) 그래프 수준 분류, 노드 분류 및 링크 예측 태스크에서 HistoGraph의 경험적 검증을 통해 기존 최고 모델에 비해 일관된 개선을 보여줍니다; 그리고 (4) HistoGraph가 표준 그래프 풀링 계층으로 학습된 모델의 성능을 더욱 강화하는 후처리 도구로 사용될 수 있음을 보여줍니다.
관련 연구
r0.55
방법
중간 표현
구조적 정보
계층-노드 모델링
JKNet
Yes
No
No
Set2Set
No
Yes
No
SAGPool
No
Yes
No
DiffPool
No
Yes
No
SSRead
No
Yes
No
DKEPool
No
Yes
No
SOPool
No
Yes
No
GMT
No
Yes
No
평균/최대/합 풀링
No
No
No
HistoGraph (우리)
Yes
Yes
Yes
그래프 신경망. GNNs는 에지 따라 메시지를 전파하고 집계하여 지역 구조와 특징을 포착하는 노드 임베딩을 생성합니다. GNN 아키텍처는 주로 스펙트럼 GNNs(예: ChebNet, GCN)과 공간적 GNNs(예: GraphSAGE, GAT) 두 가지 계열로 나뉩니다. 더 깊은 GNN은 수용 필드를 확장하지만 과도한 스무딩 및 과도한 압축을 초래할 수 있습니다. 대응책으로는 잔차와 스킵 연결, 그래프 재연결 및 위치 인코딩 또는 주의를 통한 전역 컨텍스트가 포함됩니다(예: Graphormer, GraphGPS). 여러 모델은 겹치는 정보를 유지하고 표현력을 높이기 위해 다중 합 정보를 보존합니다. HistoGraph는 전파 과정에서 노드 임베딩의 역사들을 유지하고 읽기 단계에서 결합합니다. 각 계층별 혼합과 달리, 이는 중간 특징의 퇴화를 완화하고 지역적 및 장거리 정보를 유지하는 통합 다중 스케일 요약을 제공합니다.
그래프 학습에서 풀링. 그래프 수준 태스크(예: 분자 속성 예측, 그래프 분류)는 고정 크기의 노드 임베딩 요약이 필요합니다. 초기 GNNs는 합, 평균 및 최대와 같은 순열 불변 읽기를 사용했습니다(GIN). 더 풍부한 구조를 위해 학습된 풀링이 도입되었습니다: SortPool은 임베딩을 정렬하고 상위-$`k`$를 선택합니다; DiffPool은 계층적 압축을 위한 부드러운 클러스터링을 학습합니다; SAGPool은 노드를 점수화하고 일부를 유지합니다. Set2Set은 반복 읽기를 위한 LSTM 주의를 사용하며, GMT는 쌍방향 상호작용을 위한 다중 헤드 주의를 사용합니다. SOPool은 공분산 유형 통계를 추가합니다. 최근 조사는 TU와 OGB 벤치마크에서 평탄 및 계층적 기법을 검토했습니다. 계층적 접근 방식(예: Graph U-Net)은 다중 스케일 구조를 포착하지만 복잡성을 증가시키고 정보 손실의 위험을 안깁니다. 반면에 HistoGraph는 역사적 활성화를 직접 풀링합니다: 계층별 주의는 다중 깊이 특징을 결합하고, 노드별 주의는 공간적 종속성을 모델링하며 정규화는 기여를 안정화시킵니다. 이로 인해 클러스터링이나 노드 제거 없이 전파 깊이에 걸친 정보를 유지합니다.
표 [tab:pooling-methods]는 설계 선택 사항을 요약하고 HistoGraph이 중간 표현과 구조적 정보를 결합하는 유일한 방법임을 보여줍니다.
잔차 연결. 잔차는 깊은 GNNs와 다중 스케일 특징에 있어 핵심입니다. Jumping Knowledge는 계층을 유연하게 결합하고 APPNP는 개인화된 페이지 랭크를 사용하여 장거리 신호를 유지하며 GCNII는 초기 잔차 및 항등 매핑을 추가하여 안정성을 보장합니다. 풀링에서 Graph U-Net은 인코더-디코더 사이에 스킵 연결을 활용하고 DiffPool의 클러스터 할당은 부드러운 잔차로서 초기 계층 정보를 유지하도록 합니다. 다른 방법들은 학습 가능한 잔차 연결이 과도한 스무딩을 완화할 수 있음을 보여주며 그래프에 대한 동역학적 관점을 제공합니다. 다르게, 우리의 HistoGraph은 역사적 풀링을 도입하여 읽기 단계에서 각 노드의 계층 간 역사적인 임베딩들을 누적하고 최종 표현에 다중 합 특징을 통합하는 전역 스킵 연결을 생성합니다. 이는 이전 모델들이 노드 업데이트 내부 또는 계층적 압축을 통해만 잔차를 적용하는 것과 달리 작동합니다.
역사적 그래프 활성화에서 학습하기
HistoGraph는 다운스트림 태스크에 걸친 그래프 표현 학습을 향상시키기 위해 계층 진화와 공간 상호작용을 통합하는 학습 가능한 풀링 연산자를 소개합니다. 기존의 마지막 GNN 계층에서 작동하는 풀링과 달리, HistoGraph는 은닉 표현을 역사적 활성화 시퀀스로 취급합니다. 각 노드의 역사를 최종 계층 표현으로 쿼리하고 공간 자기 주의를 적용하여 고정 크기의 그래프 표현을 생성합니다. 세부 사항은 부록 8 및
알고리즘 [alg:method];
그림 1은 HistoGraph의 개요를 보여주며 표 [tab:pooling-methods]는 다른 방법들과 비교합니다.
표기법. $`\mathbf{X} \in \mathbb{R}^{N \times L \times D_{\text{in}}}`$은 일괄 처리된 역사적 그래프 활성화로, 여기서 $`N`$은 배치 내 노드 수이고 $`L`$는 GNN 계층이나 시간 단계의 수이며 $`D_{\text{in}}`$은 특징 차원입니다. 각 노드에는 메시지 패싱에 따른 여러 깊이의 중간 표현 $`L`$개가 있습니다. 모든 GNN 계층은 동일한 차원 $`D_{\text{in}}`$에서 활성화를 생성한다고 가정합니다.
우리는
$`\mathbf{X} = [\mathbf{X}^{(1)}, \ldots, \mathbf{X}^{(L-1)}]`$을 GNN 계산이 $`L`$ 계층에 걸쳐서 생성하는 활성화 역사로 표시합니다. 초기 표현은 다음과 같이 주어집니다:
$`\mathbf{X}^{(0)} = \text{Emb}_{\text{in}}(\mathbf{F})`$, 여기서
$`\mathbf{F} \in \mathbb{R}^{N \times D_{\text{in}}}`$은 입력 노드 특징이고 $`\text{Emb}`$는 선형 계층입니다. 그 다음 각각의 후속 계층 $`l = 1, \ldots, L-1`$, 표현들은 재귀적으로 다음과 같이 계산됩니다:
$`\mathbf{X}^{(l)} = \text{GNN}^{(l)}(\mathbf{X}^{(l-1)})`, 여기서
$\text{GNN}^{(l)}$는 $l$번째 GNN 계층을 나타냅니다.
입력 투영 및 각 계층 위치 인코딩. 우리는 선형 변환을 통해 입력 특징을 공통 숨겨진 차원 $`D`$로 투영합니다:
여기서 $`0 \le l < L`$, $`0 \le k < D/2`$이고, 결과는
$`\mathbf{P} \in \mathbb{R}^{L \times D}`$이며 계층 인식 특징 $`\widetilde{\mathbf{X}} = \mathbf{X}' + \mathbf{P}.`$를 얻습니다.
계층별 주의와 노드별 주의. 우리는 각 노드의 역사적 활성화 시퀀스를 통해 이를 보고 주의를 사용하여 가장 관련성이 높은 활성화를 학습합니다.