- Title: RovoDev Code Reviewer A Large-Scale Online Evaluation of LLM-based Code Review Automation at Atlassian
- ArXiv ID: 2601.01129
- 발행일: 2026-01-03
- 저자: Kla Tantithamthavorn, Yaotian Zou, Andy Wong, Michael Gupta, Zhe Wang, Mike Buller, Ryan Jiang, Matthew Watson, Minwoo Jeong, Kun Chen, Ming Wu
📝 초록
코드 리뷰는 현대 소프트웨어 엔지니어링의 핵심이며, 품질 보장을 위해 중요합니다. 그러나 프로젝트가 복잡해짐에 따라 수동 코드 리뷰는 시간과 자원을 많이 필요로 하게 되며, 이는 개발 과정에서 병목 현상을 일으킬 수 있습니다. 대형 언어 모델(Large Language Models)을 사용하여 코드 리뷰의 일부를 자동화함으로써 이러한 문제를 해결할 수 있습니다. RovoDev 코드 리뷰어는 데이터 보안, 실용적인 가이드라인 제공, 새로운 프로젝트에 대한 컨텍스트 인식 능력 등 다양한 기능을 갖춘 자동화 도구입니다.
💡 논문 해설
1. **제품화 가능한 코드 리뷰 자동화**: RovoDev 코드 리뷰어는 데이터 보안과 사용자 친화적인 가이드라인 제공으로 실제 비즈니스 환경에서 활용할 수 있는 제품을 제시합니다. 이는 마치 복잡한 도서관 시스템에 필요한 검색 기능을 자동으로 갖춘 도우미와 같습니다.
2. **컨텍스트 인식 능력**: RovoDev은 프로젝트의 컨텍스트를 이해하고, 실제 개발 상황에 맞는 리뷰를 생성합니다. 이는 마치 새로운 음악 앱이 유저의 취향을 파악하여 추천하는 곡을 알려주는 것과 같습니다.
3. **품질 검증**: RovoDev은 생성된 리뷰가 실용적이고 정확한지 확인하며, 필요에 따라 수정합니다. 이는 마치 레스토랑에서 메뉴를 만들기 전에 먼저 요리사를 통해 맛을 테스트하는 것과 같습니다.
📄 논문 발췌 (ArXiv Source)
<ccs2012> <concept>
<concept_id>10011007.10011074.10011092</concept_id>
<concept_desc>소프트웨어 및 엔지니어링 소프트웨어 개발 기술</concept_desc>
<concept_significance>500</concept_significance> </concept>
</ccs2012>
서론
코드 리뷰는 현대 소프트웨어 엔지니어링의 기둥으로, 팀이 결함을 발견하고 지식을 공유하며 높은 코딩 표준을 유지하는 중요한 품질 보장 실천입니다. 그러나 소프트웨어 프로젝트가 크고 복잡해짐에 따라 수동 코드 리뷰는 시간과 자원을 많이 필요로 하게 되며, 이는 종종 개발 과정에서 병목 현상을 일으킵니다. 대형 언어 모델(Large Language Models)의 발전을 사용하여 코드 리뷰의 일부를 자동화하면 코드 리뷰 프로세스를 가속화할 수 있으며 특히 코드 리뷰 주석 생성이라는 자연어로 작성된 코드 변경에 대한 코드 리뷰 주석 생성 작업이 포함됩니다.
그러나 이러한 진보에도 불구하고, 기업급 코드 리뷰 자동화 도구 설계에는 여전히 몇 가지 실용적인 도전 과제가 있습니다. 첫째, 데이터 프라이버시 및 보안은 특히 민감한 고객 코드와 메타데이터를 처리할 때 중요하며, 이로 인해 많은 산업적 맥락에서 대형 언어 모델을 조정하는 것이 불가능합니다. 둘째, 리뷰 가이드라인은 경험이 부족한 리뷰어에게 코드 리뷰를 수행하도록 안내하는데 중요한 역할을 하지만, 최근의 대형 언어 모델에 기반한 코드 리뷰 주석 생성 접근법에서는 거의 무시되고 있습니다. 셋째, 대부분의 검색 강화 생성(Retrieval-Augmented Generation) 방법은 풍부한 역사적 데이터를 사용하지만, 이는 새로 만들어진 프로젝트나 컨텍스트가 제한적인 프로젝트에는 적합하지 않을 수 있습니다. 마지막으로, 대형 언어 모델은 노이즈가 많거나 환각된 주석을 생성할 가능성이 있어, 이것이 사실적으로 부정확하거나 실질적이지 않은 경우 자동화된 코드 리뷰 도구의 활용도를 감소시킬 수 있습니다.
이 논문에서, 우리는 RovoDev Code Reviewer라는 검토 지침에 따라 품질을 체크한 코드 리뷰 자동화를 제시합니다. 우리의 RovoDev Code Reviewer는 세 가지 핵심 구성 요소로 이루어져 있습니다: (1) 제로샷 컨텍스트 인식 리뷰 가이드 주석 생성; (2) 사실적 정확성을 체크하여 노이즈가 많은 주석을 제거하는 과정 (예: 무관한, 부정확한, 일관되지 않은, 또는 비논리적인); 그리고 (3) 주석의 실질성을 체크하여 RovoDev 생성된 주석이 코드 해결로 이어지는지 확인하는 과정.
전통적인 코드 리뷰 벤치마크 데이터셋과 유사하게 오프라인 평가 측면은 인간과의 정합성 (즉, LLM 주석이 제공된 인적 주석과 의미론적으로 얼마나 유사한지를 나타냄), 정적 (소프트웨어 엔지니어와 상호작용 없음)이며 현실 세계 소프트웨어 엔지니어링 작업의 전체 복잡성 또는 진화하는 특성을 포착하지 못합니다. 실제로, 코드 리뷰 주석은 다양한 형태로 작성될 수 있습니다. RovoDev Code Reviewer의 활용도를 더 잘 캡처하기 위해 우리는 Atlassian의 1,900개 이상의 소스 코드 저장소에 구현 및 배포하여 약 54,000개 이상의 리뷰 주석을 생성했습니다. 그런 다음 Atlassian 내부 코드 리뷰 워크플로우에 대한 실용적 가치와 영향을 엄격하게 평가하며 이는 일반적인 학계 평가를 뛰어넘습니다. 아래에서 우리는 다음 세 가지 RQs에 답합니다:
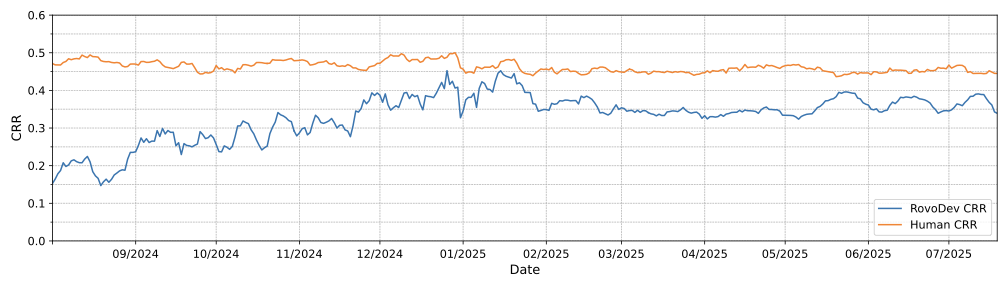
RovoDev Code Reviewers가 생성한 주석이 인간이 작성한 주석과 비교했을 때 소프트웨어 엔지니어들이 얼마나 자주 해결하는가?
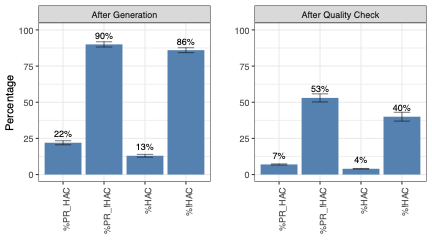
RovoDev 코드 리뷰어는 38.70%의 코드 해결률을 달성하며, 이는 인간이 작성한 주석의 코드 해결률 (44.45%)보다 상대적으로 12.9% 적습니다.
RovoDev 생성된 주석의 채택은 코드 리뷰 워크플로우에 어떤 영향을 미치는가?
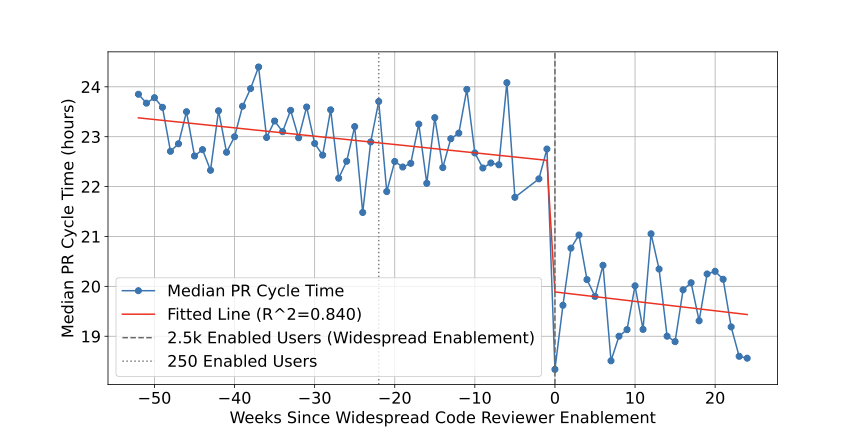
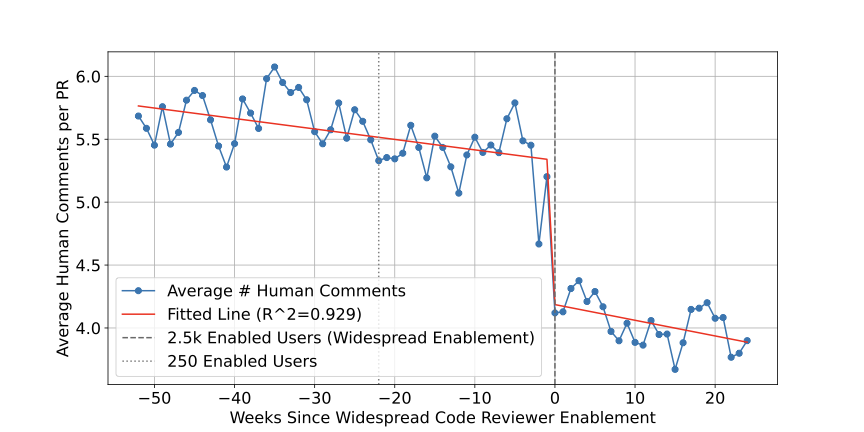
RovoDev은 Atlassian에서 코드 리뷰 워크플로우에 긍정적인 영향을 미쳐 중앙 PR 사이클 시간을 30.8% 가속화하고 인간이 작성한 주석의 수를 35.6% 줄였습니다.
소프트웨어 엔지니어들은 RovoDev 코드 리뷰어가 생성한 코드 리뷰 주석의 품질을 어떻게 평가하는가?
소프트웨어 엔지니어는 RovoDev이 정확한 오류 감지를 제공하고 실질적인 제안을 하는 것으로 발견했습니다. 그러나 컨텍스트 정보가 알려져 있지 않을 때 RovoDev은 잘못된 또는 실질적이지 않은 주석을 생성할 수 있습니다.
1년 동안 1,900개 이상의 저장소에서 대규모 온라인 생산 및 평가를 통해 우리는 RovoDev 코드 리뷰어는 코드 해결로 이어지는 코멘트를 생성하는 데 효과적이라는 결론을 내렸습니다 (즉, 다음 커밋에서 주석이 달린 코드 줄이 해결됨), 코드 리뷰 워크플로우에 긍정적인 영향을 미치며 (즉, PR 사이클 시간 감소 및 인간이 작성한 주석의 수를 줄임) 몇몇 실무자들로부터 긍정적인 정성적 피드백을 받았습니다 (즉, 실질적인 제안과 함께 오류 발견).
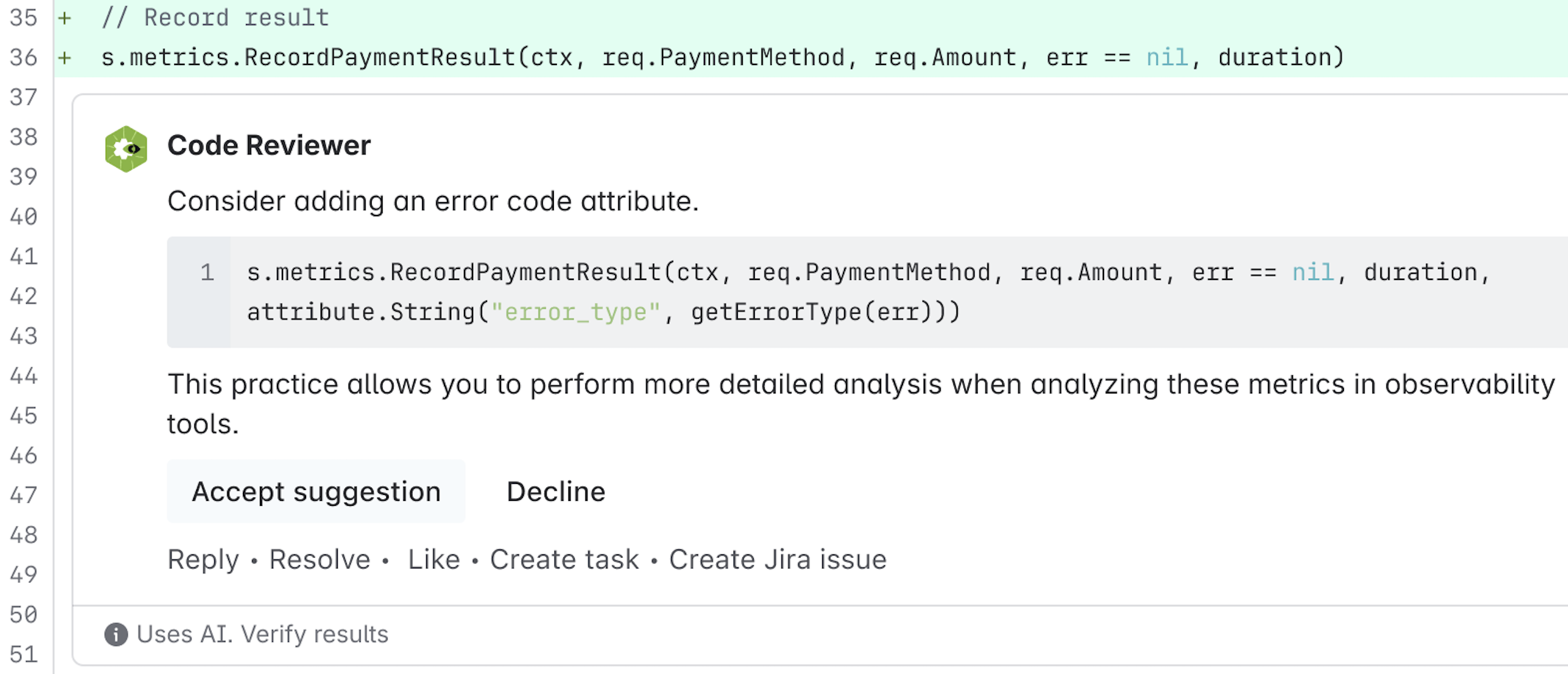
RovoDev 코드 리뷰어가 생성한 코드 리뷰 주석의 예.
새로움 및 기여: 이 논문은 다음과 같은 것들을 처음으로 제시합니다:
RovoDev 코드 리뷰어: 컨텍스트 인식 리뷰 지침에 따른 품질 검증 대형 언어 모델(Large Language Models) 기반 코드 리뷰 자동화 (섹션 3).
1년 동안 1,900개 이상의 소스 코드 저장소에서 RovoDev Code Reviewer를 온라인 배포 및 평가하여 약 54,000개 이상의 코드 리뷰 주석을 생성 (RQ1부터 RQ3까지).
논문 구성: 이 논문은 다음과 같이 구성되어 있습니다. 섹션 2에서는 Atlassian에서의 현대 코드 리뷰, 관련 연구 및 한계를 설명합니다. 섹션 3에서는 Atlassian의 RovoDev Code Reviewer를 제시합니다. 섹션 4에서는 실험 설계와 오프라인 및 온라인 평가 결과를 제시합니다. 섹션 6에서는 유효성에 대한 위협을 밝힙니다. 마지막으로, 섹션 7에서는 결론을 맺습니다.
배경 및 관련 연구
이 섹션에서 우리는 Atlassian의 현대 코드 리뷰에 대해 간략하게 설명하며, 산업적 맥락에서 코드 리뷰 자동화의 필요성과 이전 연구의 한계를 다룹니다.
Atlassian의 현대 코드 리뷰
현대 코드 리뷰 (MCR)는 전통적인 정식 검사 대신 가벼운 도구 지원 및 비동기 프로세스를 활용하여 현대 소프트웨어 엔지니어링 실천의 핵심이 되었습니다. 이전 접근법은 인원 참석 회의와 체크리스트에 의존했지만, MCR은 Bitbucket, Gerrit, GitHub, GitLab과 같은 플랫폼을 통해 분산된 코드 변경 리뷰를 용이하게 합니다.
**At Atlassian (Bitbucket, Jira 및 Confluence와 같은 소프트웨어 개발 도구 세트로 알려진 글로벌 기술 회사)**에서는 모든 소프트웨어 엔지니어링 팀에서 코드 리뷰가 필수적이고 깊이 결합된 관행입니다. 크기에 상관없이 모든 코드 변경은 주요 코드베이스에 통합되기 전에 피어 리뷰를 받아야 하며, 이를 통해 코드의 품질, 유지 가능성 및 보안을 확보합니다. 이 프로세스는 Bitbucket에서 주로 수행되며 소프트웨어 엔지니어가 변경 사항을 제출하고 리뷰자로부터 피드백을 요청합니다. 이 과정은 협업적이며, 리뷰자와 작성자가 의도를 명확히 하거나 문제를 해결하고 일치하는 데서 의견을 교환하기 위한 것입니다.
도전: Atlassian의 규모와 개발 속도는 코드 리뷰가 병목 현상이 될 수 있으며 특히 활동이 많은 기간이나 여러 시간대에 흩어져 있는 팀이 있을 때 더욱 그렇습니다. 리뷰 사이클 지연은 기능 배달을 느리게 하고 엔지니어의 생산성과 코드 리뷰 워크플로우에 영향을 미칩니다. 그러나 기본적인 리뷰 프로세스는 여전히 주로 인간 리뷰어의 전문성과 가용성을 의존하는 수동적입니다.
대형 언어 모델 기반 코드 리뷰 자동화 및 한계
코드 리뷰 자동화는 소프트웨어 품질 개선, 엔지니어 생산성 향상, 그리고 코드 리뷰 속도를 높이기 위해 활발히 연구되고 있습니다. 기계 학습과 자연어 처리의 발전으로 인해 연구자들은 데이터 중심 접근법을 통해 코드 리뷰 자동화를 탐색하고 있습니다. 예를 들어, 리뷰어 추천, 코드 리뷰 우선 순위 지정, 라인 수준 로케이션, 코드 리뷰 주석 생성 및 추천, 코드 리뷰 활용성, 그리고 코드 정제 등이 포함됩니다.
**LLM 기반의 코드 리뷰 주석 생성은 대형 언어 모델(Large Language Models)을 사용하여 특정 코드 변경에 대한 리뷰 주석을 자동으로 생성하는 연구 분야입니다. 최근 연구에서는 오프 더 셸프 LLMs, 예를 들어, 신경망 기계 번역, T5, CodeT5, Llama, GPT-3.5 및 GPT-4o를 활용한 사례가 있습니다. 많은 연구에서 태스크별 데이터로 LLM을 미세 조정하면 코드 리뷰 주석 생성에 대한 최상의 효과를 얻는다는 것을 보여주었습니다. 이 과정은 일반적으로 공개 저장소 (예: TufanoT5)에서 소스된 코드와 해당 인적 주석으로 구성된 데이터셋을 기반으로 합니다. 그러나 대기업급 코드 리뷰 주석 생성 도구를 설계할 때 몇 가지 실용적이지만 해결되지 않은 도전 과제가 있습니다.
**첫째, 업무용 코드 리뷰 주석 생성 도구는 고객의 코드와 관련 메타데이터를 보호해야 합니다. Atlassian의 기업 고객들에게 데이터 프라이버시 및 보안은 최우선 사항입니다—대략 절반은 이를 AI 기반 소프트웨어 개발 도구를 채택하는 데 중요한 장애물로 지목합니다. 고객 데이터 처리 부주의는 극히 심각한 결과를 초래할 수 있습니다, 예를 들어 보안 침해, 고객 신뢰의 손실, 규제 준수 위반 (예: GDPR 또는 CCPA), 그리고 중대한 재정적이나 명성상의 손실입니다. 따라서 기존 작업에서 일반적으로 사용되는 것과 같이 코드 리뷰 주석 생성을 위해 대형 언어 모델을 미세 조정하는 것은 업무용 자동화된 코드 리뷰 도구에 대한 데이터 보안 및 프라이버시 위험을 초래할 수 있습니다.
**둘째, 업무급 코드 리뷰 주석 생성 도구는 고수준의 코드 리뷰 가이드라인을 갖추어야 합니다. 코드 리뷰 가이드라인 또는 체크리스트는 종종 코드 리뷰 프로세스의 기본 구성 요소입니다. 이전 연구에서는 체크리스트 기반 코드 리뷰가 경험이 부족한 리뷰어에게 코드 리뷰를 수행하는 데 효과적인 메커니즘이라는 것을 발견했습니다, 왜냐하면 체크리스트는 코드 검토 시 중요한 문제나 결함에 주의하도록 안내하기 때문입니다. 그러나 이러한 코드 리뷰 체크리스트는 최근 자동화된 코드 리뷰 접근법에서 무시되었습니다.
**셋째, 업무급 코드 리뷰 주석 생성 도구는 컨텍스트 인식 능력을 갖추면서 제한적인 컨텍스트 정보를 가진 새롭게 만들어진 소프트웨어 프로젝트를 지원해야 합니다. 최근 연구에서는 검색 강화 생성(Retrieval-Augmented Generation)을 사용하여 저장소 내부의 컨텍스트 정보를 검색하여 코드 리뷰 주석 생성 작업의 효과성을 더욱 향상시키는 것을 제안했습니다. 예를 들어, Hong 등은 가장 유사한 입력된 코드에 해당하는 리뷰 주석을 검색하도록 제안했습니다. 마찬가지로 Olewick 등은 특정 코드 변경사항에 대한 관련 코멘트 예제를 추출하도록 제안했습니다. 이러한 RAG 기반 접근법은 일반적으로 상당한 역사적 데이터를 가진 성숙하고 오랜 소프트웨어 프로젝트를 위한 것이지만, 새로운 프로젝트에는 적합하지 않을 수 있습니다.
**마지막으로, 업무급 코드 리뷰 주석 생성 도구는 유효하고 사실적으로 정확한 코드 리뷰 주석을 생성해야 합니다. Tufano 등이 정의한 바와 같이 유효한 리뷰 주석은 소스 코드 품질 개선에 중점을 둔 명확한 제안을 제공하는 것에 관한 것입니다. Liu 등은 많은 코드 리뷰 주석이 노이즈가 많거나 실질적이지 않은 피드백 (예: “여기에 줄을 추가하세요”)이라고 발견했습니다. 이러한 노이즈로 인해 LLMs는 낮은 품질의 리뷰 주석을 생성할 수 있습니다. 더욱이, LLMs는 환각에 취약합니다—즉, 제공된 코드 변경 사항에 기반하여 사실적으로 부정확하거나 일관되지 않거나 비논리적인 코드 리뷰 주석을 생성하는 것입니다. Zhang 등은 이러한 환각이 코드 생성 작업에서 흔히 발견된다고 밝혔습니다. 이러한 유효하지 않은 코드 리뷰 주석은 업무급 자동화된 코드 리뷰 도구의 전체 활용도를 감소시킬 수 있습니다. 이러한 업무용 코드 리뷰 주석 생성을 설계하는 데 있어 실용적인 도전 과제들은 우리에게 다음과 같은 최종 연구 질문을 제기하게 합니다: 리뷰 지침에 따라 컨텍스트 인식 능력과 품질 검증을 갖춘 코드 리뷰 주석 생성은 미세 조정 없이 어떻게 설계할 수 있을까요?
Atlassian의 RovoDev Code Reviewer
이 섹션에서는 Atlassian의 RovoDev Code Reviewer 기술 아키텍처를 제시합니다.
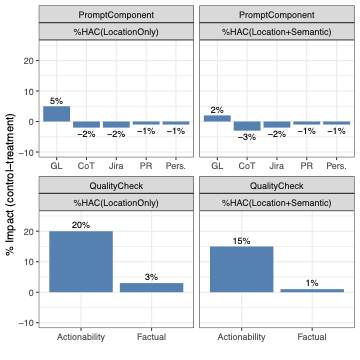
개요: 우리는 RovoDev 코드 리뷰어를 제로샷, 리뷰 지침에 따른 품질 검증 대형 언어 모델(Large Language Models)을 활용한 방식으로 설계했습니다. 플러그 레퍼와 관련된 컨텍스트 정보 (즉, 플러그 제목, 설명, 관련 파일 및 연결된 이슈 요약 등)를 주어진 코드 변경에 대한 유효하고 정확하며 관련성 있고 실질적인 리뷰 주석을 자동으로 생성하는 것이 RovoDev Code Reviewer의 목표입니다. Figure 2은 우리의 접근 방식에 대한 개요를 제시하며 다음과 같은 세 가지 핵심 구성 요소로 이루어져 있습니다.
/>
RovoDev 코드 리뷰어의 개요.
제로샷 컨텍스트 인식 리뷰 지침에 따른 주석 생성 모델: 고객 데이터의 프라이버시와 보안을 보장하고 규제 준수를 유지하기 위해, 우리는 모델 훈련 또는 미세 조정 목적으로 사용자 생성 콘텐츠를 수집하지 않습니다. 대신, 우리는 준비된 컨텍스트 정보 (즉, 플러그 리퀘스트 및 Jira 이슈 정보)를 구조화된 설계와 인물, 사고 체인, 그리고 리뷰 가이드라인을 사용하여 제로샷 구조적 프롬프트 접근 방식에 의존합니다. 이를 통해 RovoDev Code Reviewer는 프로젝트의 성숙도에 관계없이 코드 리뷰 주석을 생성하는 데 더 확장 가능해집니다.
사실적 정확성 검증 구성 요소: 생성된 코드 리뷰 주석이 환각되지 않도록 (즉, 특정 코드 변경 및 관련 플러그 리퀘스트와 일치), LLM-as-a-Judge 접근 방식을 사용하여 주어진 주석이 특정 플러그 리퀘스트와 코드 변경 영역과 일치하는지 검증합니다.