- Title: Generating Diverse TSP Tours via a Combination of Graph Pointer Network and Dispersion
- ArXiv ID: 2601.01132
- 발행일: 2026-01-03
- 저자: Hao-Tsung Yang, Ssu-Yuan Lo, Kuan-Lun Chen, Ching-Kai Wang
📝 초록
이 논문에서는 다각적 여행 상인 문제(D-TSP)를 해결하기 위한 새로운 프레임워크를 제안합니다. 이 작업은 고성능 해답을 찾으면서 동시에 해답의 다양성을 최대화하는 것을 목표로 합니다. 우리의 접근 방식은 전통적인 알고리즘과 신경망 기반 방법을 결합한 것입니다. 실험 결과는 40개 도시에 대해 몇 시간 동안 훈련하면, 우리의 모델이 현재까지 알려진 최고의 성능을 보여줍니다.
💡 논문 해설
1. **새로운 접근 방식**: 이 논문은 전통적인 알고리즘과 신경망 기반 방법을 결합하여 D-TSP를 해결하는 새로운 프레임워크를 제안합니다. 이를 통해 효율성과 다양성을 동시에 달성할 수 있습니다. 이는 마치 요리를 할 때, 고기와 채소를 혼합해 맛있으면서 영양가 있는 요리를 만드는 것과 같습니다.
효율적인 해답 생성: 논문은 두 단계로 구성된 과정을 제안합니다. 첫 번째 단계에서는 고성능 해답 후보군을 대규모로 샘플링하고, 두 번째 단계에서는 이 중에서 가장 다양한 $`k`$ 개의 해답을 선택합니다. 이를 통해 시간을 절약하면서도 효과적인 해답을 찾습니다. 이는 마치 옷장을 정리할 때, 먼저 모든 옷을 다 꺼내서 보고, 그중에서 잘 어울리는 것들만 골라내는 것과 같습니다.
성능의 개선: 실험 결과에 따르면, 우리의 모델은 다른 기존 방법보다 훨씬 빠르게 해답을 찾아냅니다. 예를 들어 783개 도시에 대해 1000개의 해답을 찾는 데 약 1.2시간이 소요되는데, 이는 기존 방법보다 최대 60배 빠릅니다. 이는 마치 자동차와 경주에서 전기 자동차가 디젤 자동차를 앞지를 수 있는 것과 같습니다.
📄 논문 발췌 (ArXiv Source)
# 서론
이 논문에서는 다각적 여행 상인 문제(D-TSP)에 대해 다룹니다. 주어진 가중치 그래프와 상수 $`c`$가 있을 때, D-TSP의 목표는 $`k`$ 개의 다른 TSP 투어 세트 $`S`$를 식별하는 것입니다. 이 세트는 두 가지 경쟁 기준을 충족해야 합니다: 첫 번째로, 모든 투어 $`T \in S`$의 길이는 최적 TSP 투어의 길이 $`|T^*|`$보다 $`c|T^*|`$ 이하여야 하며; 두 번째로, 세트 $`S`$ 내 모든 투어 쌍 간의 평균 Jaccard 유사도를 최소화해야 합니다. 이러한 포뮬레이션은 고성능 해답을 찾으면서 동시에 구조적인 다양성을 최대화하려는 것입니다.
해답 다양성 최적화의 개념은 최근 몇 년 동안 이론적 진전과 실용적인 적용 요구에 의해 많은 관심을 받았습니다. 이론적으로, 많은 고전적인 조합 최적화 문제들이 다각형 형태로 재검토되었습니다. 이를 포함하여 최소 $`s`$-$`t`$ 컷, 안정적인 매칭, 정점 덮개 등이 있습니다. 실용적인 측면에서는 다양성 목표는 강력한 휴리스틱 방법으로 작동하며 다양한 도메인에 걸쳐 상당한 이점을 제공합니다. 이러한 이점에는 효과적으로 근적선 해를 찾고, 학습된 정책의 견고성과 안정성을 향상시키며, 불투명한 블랙박스 모델에 대한 중요한 가독성을 제공하는 것이 포함됩니다.
이 성장하는 주제 내에서 D-TSP도 많은 잠재적 응용 분야가 있습니다. 이에는 물류 최적화 작업 등이 포함되는데, 여기서 고장 허용을 위해 중복되고 다양한 경로 옵션이 필요합니다. 또한 로봇 공학에서도 효율적인 순찰 계획 및 태스크 할당과 같이 여러 루트가 커버되어야 하는 상황에서 활용됩니다. 그럼에도 불구하고, 이 문제에 대한 보장된 근사 알고리즘의 개발은 아직 열려 있습니다. 가장 관련이 있는 작업들은 저자들이 2개의 다양한 투어만을 집중적으로 다루고 있으며, 저자들은 $`k`$ 개의 다양한 근사 스패닝 트리를 생성하는 양기준 최적화를 다룹니다. 그러나 이러한 접근 방식을 TSP 투어로 변환하는 것은 중요한 한계점을 가지고 있습니다: 스패닝 트리에서 달성된 다양성의 질이 트리가 해밀턴 경로로 변환될 때 떨어질 수 있다는 점입니다. 따라서, 현존하는 연구는 주로 휴리스틱 방법으로 이 문제를 다룹니다. 이러한 접근 방식은 일반적으로 전통적인 Multi-Solution TSP(MSTSP) 휴리스틱과 신경망 기반 D-TSP 방법론으로 나눌 수 있습니다.
전통적인 MSTSP 휴리스틱: Multi-Solution TSP는 주로 전통적인 휴리스틱에 의해 해결되었습니다. 대부분의 이러한 방법은 유전자나 진화 기반 알고리즘을 기반으로 하며, 이들은 자연적으로 다양성을 유지하면서 해를 생성하는 “유전자” 또는 솔루션 구성 요소를 포함합니다. 연구 간 주요 차이는 어떻게 효과적으로 탐색 공간을 탐색하고 유지하며 동시에 생성된 해의 다양성과 품질을 보호할 수 있는지에 초점을 맞추는 것입니다. 이 일련의 작업에서 중요한 단점 중 하나는 문제 크기가 커짐에 따라 NP-난이도와 다중 해 성격으로 인해 필요한 계산 시간이 매우 많이 들기 때문에 발생합니다. 특히, Niching Memetic Algorithm(NMA)은 이 문제를 해결하는 데 있어 최고의 전통적인 휴리스틱으로 식별되었습니다. NMA는 처음에 생성된 TSP 투어를 서로 다른 그룹으로 나누는 니치 기법을 활용하여 각 할당된 니치 내에서 유사한 투어만 유지함으로써 솔루션 공간의 다양한 영역을 보호합니다. NMA 이후에는 Evolutionary Diversity Optimization(EDO)에 기반한 접근 방식이 제안되었습니다. EDO 프레임워크는 일반적으로 다양성 지표를 적합도 함수에 직접 통합하거나 특수화된 진화 연산자를 사용하여 인구를 다른 솔루션 공간 영역으로 이동시킵니다. NMA와 달리, EDO 방법은 알려진 최적 해에서 시작하여 단독으로 다양성을 극대화하기 위해 인구를 진화시키지만, TSP의 최적 해를 찾는 것이 NP-난이도 특성 때문에 실용적이지 않을 수 있습니다.
신경망 기반 D-TSP 접근 방식: 전통적인 휴리스틱과 대조적으로, 조합 최적화(CO)에 대한 신경망 방법은 데이터 주도 방식으로 해를 학습합니다. 이러한 알고리즘은 훈련 단계가 필요하지만 GPU의 병렬 구조로 인해 빠른 추론을 제공하는 이점을 갖습니다. 주요 도전 과제는 다른 크기와 위상 구조를 가진 그래프에 효과적으로 전이할 수 있는 정책 개발입니다. 초기 신경망 접근 방식은 대부분 단일 기준 최적화 CO에 초점을 맞추었으며, 이를 포함하여 Pointer Network, Graph Pointer Networks 및 Attention Model의 기본 작업을 수행했습니다. 최근 연구는 다중 해 생성으로 주목을 받았습니다. 복수 개의 병렬 디코더를 활용하면 모델이 솔루션 공간의 다양한 영역을 탐색할 수 있습니다. 저자들이 제안한 방법은 Diversity Optimization for TSP에 대한 심층 강화 학습 솔버입니다. 이 모델은 상대화 필터, 온도 소프트맥스 및 활성 검색 등의 여러 메커니즘을 갖추고 있습니다. 이러한 추가 메커니즘은 효과적이지만 기본 모델 아키텍처를 복잡하게 만들고 해석 가능성 전체를 감소시킵니다. 또한, 활성 검색 방법은 해의 품질을 향상시키지만 대도시 수가 많아지면 추론 단계에서 속도가 크게 느려집니다.
우리의 기여: D-TSP 문제를 해결하기 위해 우리는 전통적인 알고리즘과 신경망 방법의 강점을 결합한 새로운 프레임워크를 제안합니다. 우리의 접근 방식은 문제를 두 단계로 나눠 처리합니다. 첫 번째 단계는 $`c|T^*|`$ 이하인 투어의 대규모 풀을 효율적으로 샘플링하는 것입니다. 두 번째 단계는 이러한 풀에서 $`k`$ 개의 가장 다양한 투어를 선택합니다. 우리는 두 번째 단계가 분산 문제와 수학적으로 관련되어 있으며, 그리디 알고리즘이 이 유형의 문제가 2-근사해를 제공한다는 것을 보여줍니다. 첫 번째 단계는 상대적으로 어렵습니다: 샘플링된 투어는 $`c|T^*|`$ 미만의 모든 고성능 해답을 대표하기 위해 다양해야 하며, 풀 크기는 지수적으로 증가하지 않아야 합니다. 따라서 우리는 그래프 포인터 네트워크 모델(GPN)을 사용합니다. 이는 그래프 컨볼루션 네트워크와 포인터 네트워크를 포함합니다. 놀랍게도, 디코딩 단계에서 순서 엔트로피를 근사하는 손실을 추가함으로써 모델은 생성된 세트의 투어 길이와 다양성 간의 타협점을 효과적으로 제어할 수 있습니다. 이 작업과 비교하면, 우리의 모델은 더 단순하며 복잡한 메커니즘이나 필요 없는 미세 조정 없이 성공적으로 작동합니다.
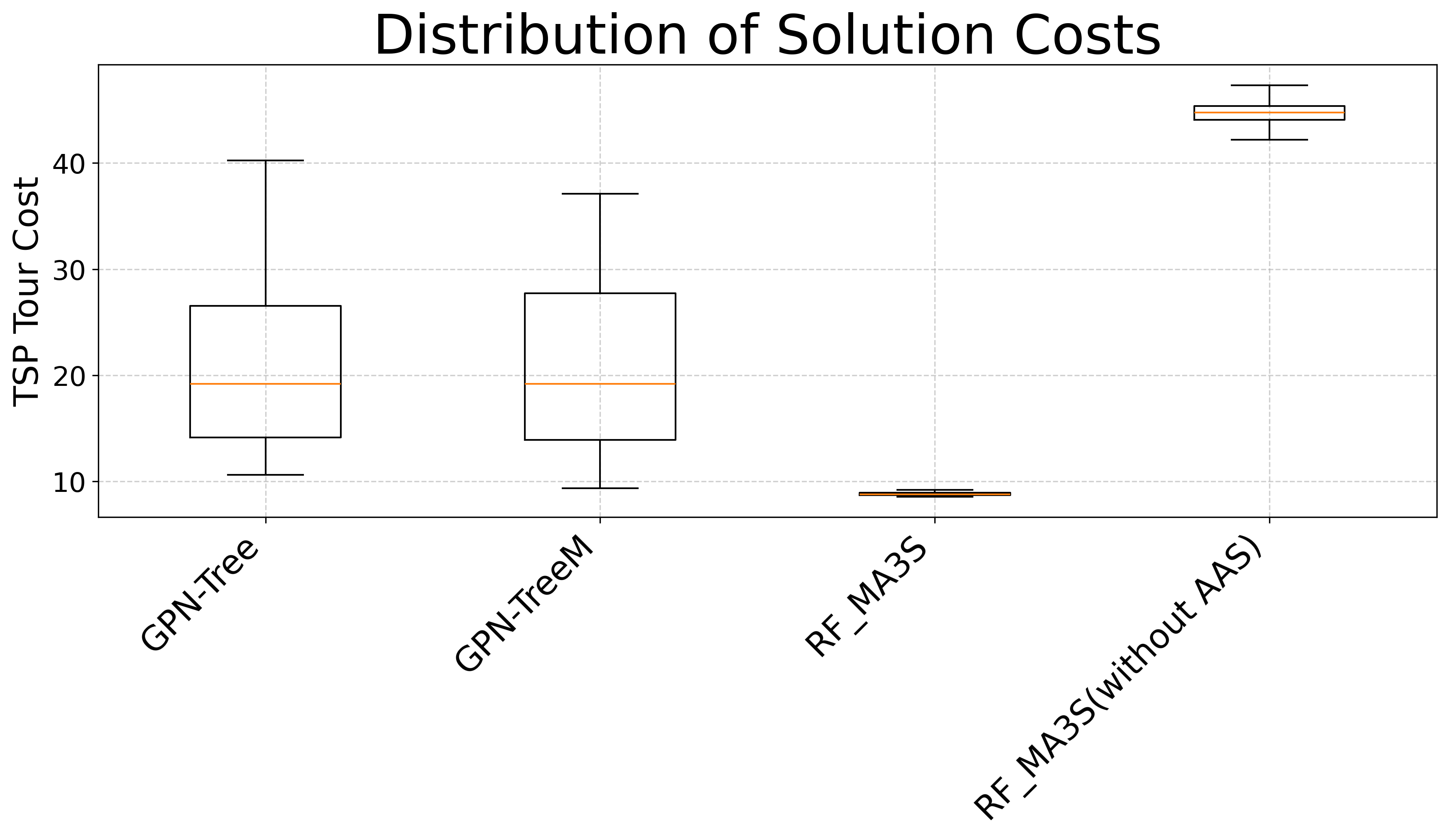
실험 결과는 우리의 연구가 40개 도시에 대해 몇 시간 동안 훈련하는 것으로 현재까지 알려진 최고의 성능을 크게 능가함을 보여줍니다. 예를 들어, berlin 데이터셋(52개 도시)에서 $`k=60`$ 및 $`c=4`$일 때, 우리의 방법은 평균 Jaccard 지수가 $`0.015`$입니다. 이는 NMA($`0.081`$), RF-MA3S($`0.509`$, 34배 더 높음)보다 훨씬 우수합니다. 우리의 다양성 성능은 근사 양기준 알고리즘의 $`0.016`$과 거의 동일하지만, 우리의 접근 방식이 전체 시간 복잡도가 $`O(n^3)`$인 제약 프로그래밍 문제를 해결하는 것에 비해 훨씬 빠릅니다. 이론적으로 GPN 모델은 $`O(n^3)`$ 시간 복잡도를 갖지만, GPU 구조에서 제공하는 빠른 병렬 컴퓨팅을 활용하면 총 실행 시간의 실제 성장률이 $`O(n)`$에 가깝습니다. 783개 도시로 이루어진 rat 데이터셋과 같이 대규모 인스턴스에서는 1000개의 해답을 생성하는 데 약 1.2시간이 소요됩니다. 이는 52개 도시 케이스보다 약 60배 더 오래 걸리지만, 양기준 알고리즘은 약 1.8일(360배 더 오래)이 소요되어 우리의 신경망-휴리스틱 하이브리드 접근 방식의 우수한 효율성을 명확히 합니다.
스팬 트리를 투어로 변환할 때 유사성을 유지할 수 없는 카운터 예입니다. (a)와 (b)는 정확히 한 개의 엣지만 공유하는 두 개의 다른 스팬 트리(결과적으로 Jaccard 지수가 거의 0에 가깝습니다). 그럼에도 불구하고, (c)에서 서로 다른 스팬 트리는 이중 트리 휴리스틱을 통해 동일한 TSP 투어를 생성할 수 있음을 보여줍니다.
문제 정의
우리는 Multi-Solution Traveling Salesman Problem(다중 해답 여행 상인 문제) 프레임워크 내에서 다양한 TSP 해답을 생성하는 문제를 포뮬레이션합니다. 우리의 목표는 고성능(근적선)이면서 서로 다른 해밀턴 사이클 세트를 식별하는 것입니다.
Traveling Salesman Problem
$`G = (V, E, w)`$가 완전 가중치 그래프라고 할 때, $`V = \{v_1, \dots, v_n\}`$는 $`n`$개의 정점 집합이고, $`E`$는 엣지 집합이며, $`w: E \to \mathbb{R}^+`$는 정점 간 유클리드 거리를 나타내는 가중치 함수입니다. TSP의 해답은 해밀턴 사이클(투어) $`\pi`$, 즉 $`V`$의 순열 또는 동등하게 $`E_\pi \subset E`$와 같은 하위 엣지 집합으로 정의되며, 각 정점이 2개의 차수를 가지고 하위 그래프가 연결되어 있습니다. 투어의 비용은 $`C(\pi) = \sum_{e \in E_\pi} w(e)`$로 주어집니다. 표준 TSP의 목표는 이 비용을 최소화하는 해답 $`\pi^*`$를 찾는 것입니다: $`C(\pi^*) = \min_{\pi} C(\pi)`$.
Diverse TSP 포뮬레이션
표준 TSP와 달리 단일 최적 값을 찾는 것이 아닌, D-TSP는 서로 다른 $`k`$ 개의 투어 세트 $`\Pi = \{\pi_1, \pi_2, \dots, \pi_k\}`$를 찾는 것을 목표로 합니다. 이 세트는 해답 품질과 다양성이라는 두 가지 경쟁 기준에 따라 최적화됩니다.
품질 제약: 생성된 해답이 실용적으로 유효한지(예: 효율적인 물류나 안전 순찰) 확인하기 위해, 우리는 최적 해답 비율의 허용 가능한 최적성 격차를 통제하는 $`c \ge 1`$이라는 관계 비율에 대한 비용 제약을 부과합니다:
MATH
\begin{equation}
C(\pi) \le c \cdot C(\pi^*)
\end{equation}
클릭하여 더 보기
여기서 $`c`$는 허용 가능한 최적성 격차를 통제하는 관대성 매개변수입니다. 이는 고품질 해답의 탐색 공간을 정의합니다.
다양성 지표: 우리는 두 개의 투어 $`\pi_i`$와 $`\pi_j`$ 사이의 다양성을 그들의 엣지 집합 간의 불일치를 기반으로 측정합니다. Jaccard Index는 유사도를 측정하기 위해 사용됩니다:
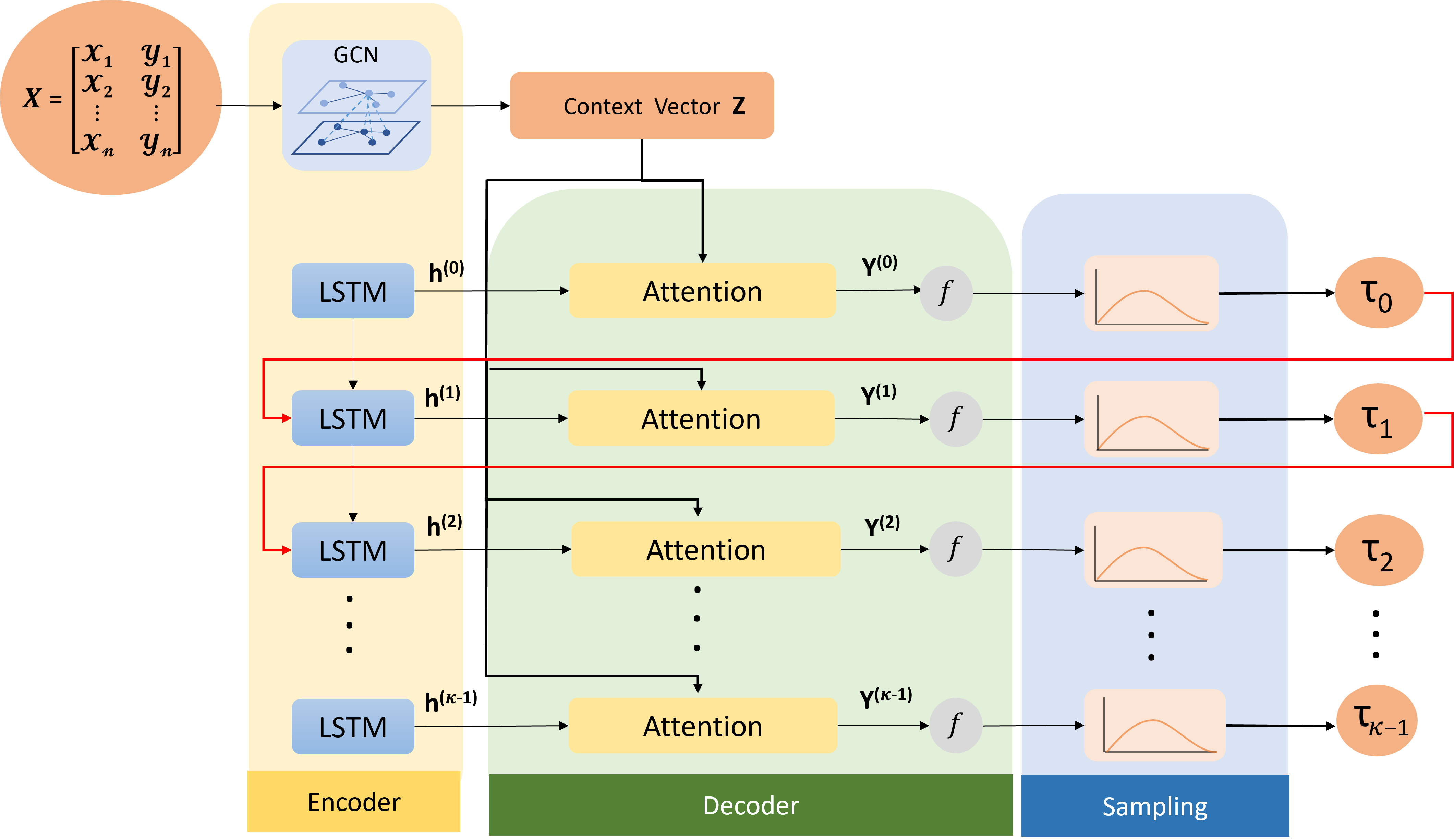
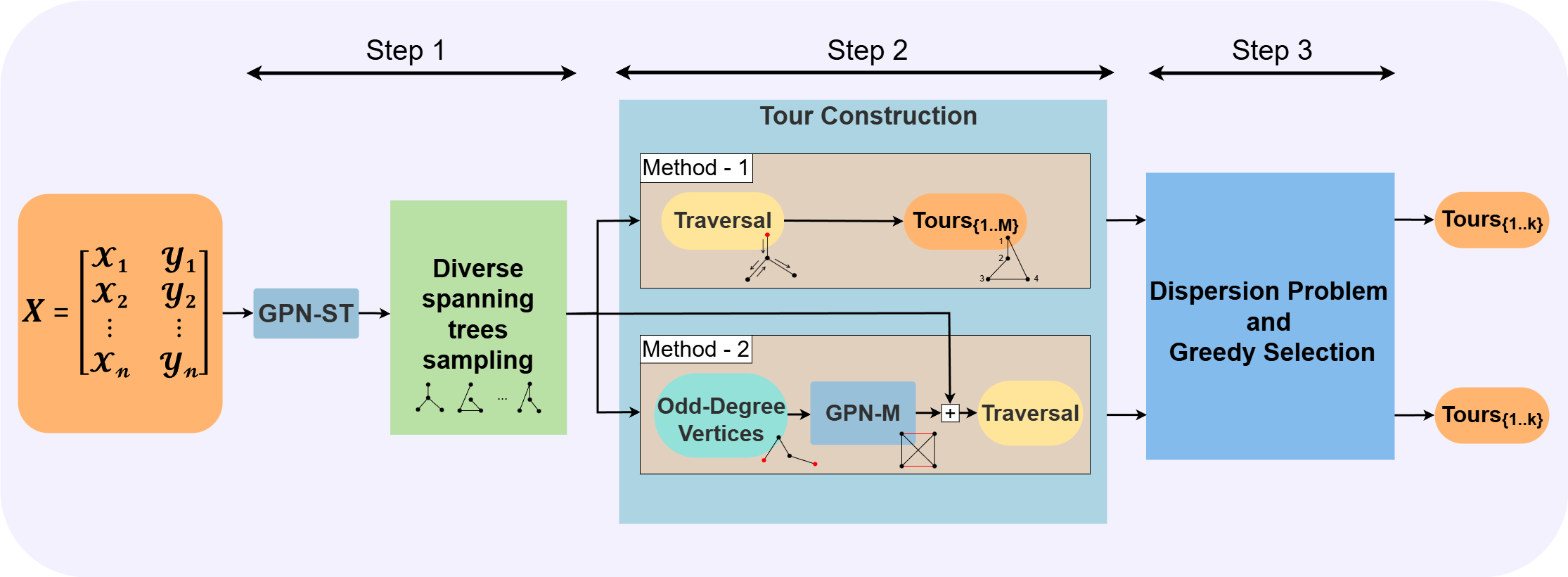
제안된 아키텍처는 GPN을 통한 스패닝 트리 및 완전 매칭 생성을 통합하고, 이를 분산 모듈로 다양한 투어 선택에 사용합니다.
우리는 고품질이고 다양한 TSP 투어 세트를 생성하기 위한 통합 학습 기반 프레임워크를 제안합니다. 그림 2에서 보여주듯이, 우리의 접근 방식은 “생성-선택” 방식을 따르며 세 단계로 구성됩니다:
다양한 스패닝 트리 샘플링: 입력 그래프는 먼저 우리의 GPN-ST(세부사항은 섹션 4 참조)를 통해 대규모의 다양한 스패닝 트리 풀을 샘플링합니다. 이 샘플된 트리는 우리의 솔루션에 대한 기하학적 백본 역할을 합니다.
투어 구성: 샘플링된 트리는 두 가지 병렬 추론 전략으로 유효한 TSP 투어 $`\mathcal{T}_{valid}`$로 변환됩니다: Method 1은 클래식 이중 엣지 휴리스틱과 무작위 샘플링을 사용하며, Method 2는 완전 매칭을 심층 강화 학습 접근 방식으로 대체하는 크리스토퍼 알고리즘을 채택합니다. 이 작업에서는 첫 번째 단계와 동일한 네트워크 구조(GPN-ST)를 사용합니다.
분산 문제 및 그리디 선택: 샘플링된 투어 집합 $`\mathcal{T}_{valid}`$가 주어진 경우, $`k`$ 개의 최대 다양성 투어를 선택하는 문제가 발생합니다(방정식 [eq:obj of max diversity] 참조). 이 문제는 분산 문제로 축소되며 NP-난이도입니다. 따라서, 우리는 $`\mathcal{T}_{valid}`$에서 다양성을 극대화하기 위해 순차적으로 $`k`$ 개의 투어를 선택하는 그리디 방법을 사용합니다. 최근 연구에 따르면 이 그리디 방식은 2-근사해를 제공하며, 지수 시간 가설을 가정할 때 이는 꽉 찬 경계입니다.
다음은 단계 2와 3의 세부 사항입니다.
Method 1: 탐색을 통한 다양성
첫 번째 전략은 샘플링된 스패닝 트리를 유효한 TSP 투어로 변환하기 위해 이중 트리 휴리스틱을 간단히 사용합니다. 그러나 직접 이중 트리를 탐색하는 대신, 탐색 중에 모든 인접 정점을 균일하게 샘플링하여 서로 다른 구조의 스패닝 트리에서 동일한 정점 순서를 생성할 확률을 줄입니다(그림 [fig:counter_example_tour] 참조). 즉, 각 샘플링된 스패닝 트리에 대해 엣지를 두 배로 늘린 다음, 재귀 단계마다 현재 정점의 모든 방문하지 않은 인접 정점을 식별하고 이 집합에서 균일하게 샘플링하여 다음 방문할 정점을 선택합니다. 탐색 중 방문 목록을 유지하면 유효한 해밀턴 사이클을 직접 형성할 수 있습니다.
Method 2: 다양한 매칭을 사용하는 크리스토퍼 알고리즘
두 번째 방법은 크리스토퍼 알고리즘을 채택합니다만, 최소 가중치 완전 매칭을 심층 강화 학습 메커니즘으로 대체합니다. 이는 크리스토퍼 알고리즘이 결정적이며 매칭 단계로 인해 계산적으로 비싸다는 이점을 제공합니다. 우리의 접근 방식은 동일한 구조의 GPN을 사용하는 심층 매칭 네트워크를 도입하며, 목적은 다양성과 고품질을 갖춘 양기준 매칭을 학습하는 것입니다.
샘플링된 스패닝 트리 $`T`$가 주어진 경우, 먼저 트리에서 홀수 차수를 가진 정점 집합 $`O \subseteq V`$를 식별합니다($`|O|`$는 항상 짝수입니다). 그런 다음, $`O`$를 입력으로 받아서 하위 그래프에 대한 다양한 매칭 세트를 출력하는 심층 매칭 네트워크가 있습니다.