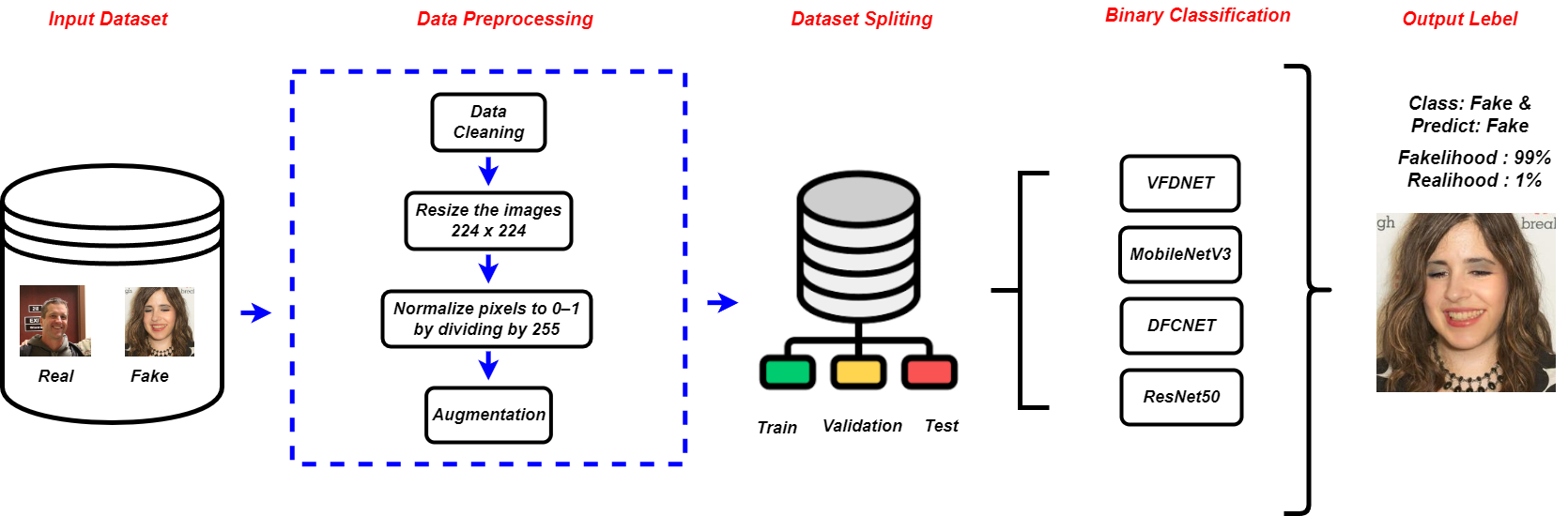
딥페이크 검출 연구는 딥페이크가 초래한 심각한 문제를 해결하기 위한 방법론을 제시합니다. 본 논문에서는 DFCNET, VFDNET, MobileNetV3, ResNet50 모델의 성능을 분석하여 실제와 가짜 이미지를 구별하는 데 가장 정확하게 작동하는 모델을 찾아내고자 합니다.
💡 논문 해설
1. **딥페이크 검출 시스템 개발:** 딥페이크는 디지털 미디어의 진실성을 훼손하고 있습니다. 본 논문에서는 딥페이크를 효과적으로 감지할 수 있는 모델을 제시함으로써, 디지털 미디어에 대한 대중의 신뢰를 회복하는데 기여합니다.
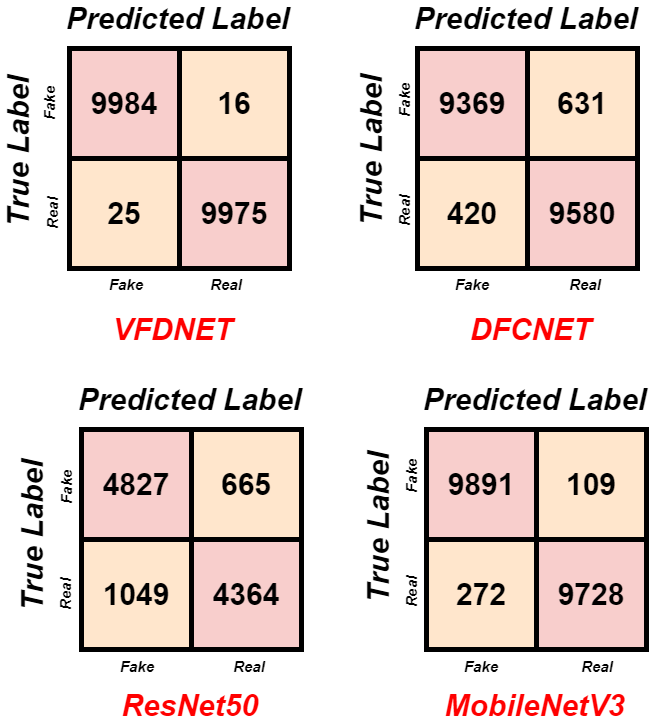
2. **다양한 딥페이크 검출 모델 분석:** DFCNET, VFDNET, MobileNetV3, ResNet50 등 다양한 모델을 사용하여 진짜와 가짜 이미지를 구분하는 데 가장 효과적인 방법을 찾습니다.
3. **데이터 전처리 및 특징 분석:** 데이터의 정규화, 크기 조정, 회전, 스케일링 등을 통해 모델 성능을 최적화하고 과적합을 줄입니다.
메타포 설명:
딥페이크는 마치 거짓말처럼 진실을 속이지만, 우리는 이 거짓말을 찾아내는 ‘거짓말 탐지기’를 개발합니다.
각 모델은 감지기에 해당하며, 가장 정확한 거짓말 탐지기를 찾는 것이 우리의 목표입니다.
📄 논문 발췌 (ArXiv Source)
딥페이크 검출, DFCNET, VFDNET, MobileNetV3, ResNet50
서론
딥페이크의 발전은 디지털 미디어의 풍경을 바꾸었으며, 초현실적인 콘텐츠를 생성할 수 있게 되었습니다. 창조적 응용이 칭찬받는 경우도 있었지만, 윤리적으로 문제가 있는 사용 사례가 많이 보고되었습니다. 2017년에는 가짜 연예인 컨텐츠와 동의 없이 변형된 포르노 등으로 인해 AI 및 개인 정보 문제에 대한 심각한 우려가 제기되었습니다.
Sensity AI(전 Deeptrace)의 2020 보고서에 따르면 온라인에서 발견된 딥페이크 비디오의 96%는 동의 없이 만들어진 포르노물로, 주로 여성들을 표적으로 삼아 성인 웹사이트와 다크웹을 통해 유포되었습니다. 딥페이크 기술의 부적절한 사용은 심리적 트라우마와 명예훼손을 초래하며, 디지털 콘텐츠에 대한 대중의 신뢰를 저하시킵니다. 딥페이크는 개인 정보 침해 위협을 넘어 민주주의와 안보에도 중대한 위험을 제기합니다. 정치적 조작과 신분 도용, 사기가 가능하며 광범위한 거짓 정보를 생성하여 법 체계에 위기를 초래할 수 있습니다.
이러한 증가하는 위협에 대응하기 위해 본 연구에서는 수정된 얼굴 사진을 인식하는 기계 학습 및 딥 러닝 기반 방법론을 제안합니다. 우리는 DFCNET, MobileNetV3, ResNet50, VFDNET의 효율성을 분석하여 진짜와 변형된 정보를 구별할 수 있는 모델을 찾습니다. 이는 핵심 연구 질문입니다: 이 중 어떤 모델이 다양한 수정 기법으로 딥페이크 이미지를 가장 정확하게 감지하는가? 우리의 목표는 디지털 미디어에 대한 대중의 신뢰를 회복할 수 있는 정확한 검출 시스템 개발에 기여하는 것입니다.
문헌 고찰
딥페이크 검출 연구는 특정 데이터셋으로 훈련된 모델의 성능을 중점적으로 다룹니다.
Patel 등(2023)은 D-CNN을 개발하여 실제와 가짜 이미지 데이터셋에서 97.2% 정확도를 달성했습니다. D-CNN은 MesoNet 변형보다 GDWCT에서는 99.33%, StarGAN에서는 99.17%의 정확도를 보였지만, StyleGAN2에서 생성된 고해상도 이미지는 94.67%로 성능이 저하되었습니다.
Ghita 등(2024)은 Vision Transformers(ViT)와 4만 개의 Kaggle 이미지를 사용하여 89.91% 정확도를 달성했습니다. 이 접근법은 잠재력을 보였지만, 다양한 데이터셋에 대한 테스트 없이 대규모 컴퓨팅 자원을 필요로 하며 중간 수준의 정확도만 나타냈습니다.
Alkishri 등(2023)은 DFT 기반 주파수 분석 방법으로 14만 개의 실제와 가짜 얼굴 데이터를 처리하여 DenseNet-121과 VGG16 모델에서 각각 99% 검출 정확도를 달성했습니다. 그러나 해상도가 낮은 이미지에서는 주파수 정보 부족으로 인해 성능이 저하되었습니다.
Zhang 등(2022)의 연구는 경사와 주파수 및 텍스처 특성을 통합하는 앙상블 학습 기법을 제시합니다. CelebA와 5개의 GAN 기반 가짜 데이터셋으로 구성된 학습 데이터셋에서 모델은 97.04%의 정확도를 달성했습니다.
방법론
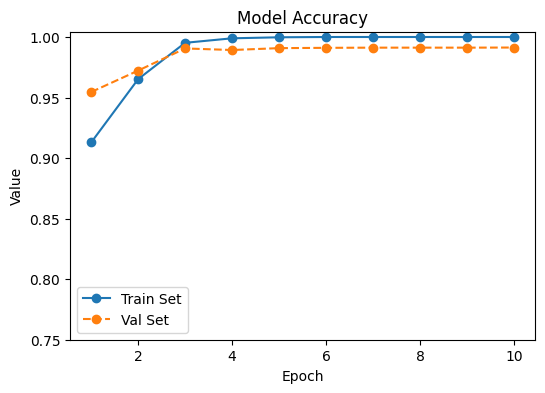
딥페이크 검출을 위해 본 연구는 비전 트랜스포머와 컨볼루션 신경망에 초점을 맞추고 있습니다. 주요 전처리 과정과 특징 분석이 수행되었습니다. 이는 Figure 1에서 볼 수 있습니다.
제안된 방법의 스케마 워크플로우
일반화를 위한 모델 전처리 파이프라인
데이터셋은 픽셀 값을 $`[0,1]`$으로 정규화하고 이미지를 $`224 \times 224`$로 크기 조정하는 등의 특정 전처리 단계가 필요합니다. 이 과정은 RGB 이미지를 16개의 그레이스케일 배치로 변환합니다. 실제와 가짜 데이터는 각각 라벨 0과 1로 분류됩니다. 이미지 증강 기술을 사용하여 데이터 일반화를 향상시키고 과적합을 줄입니다.
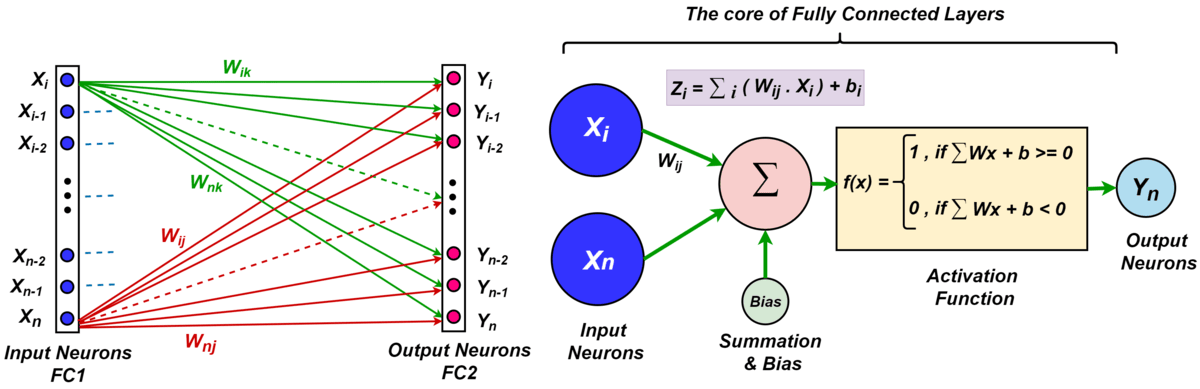
기본 컨볼루션 신경망 층
컨볼루션 신경망(CNN)은 입력 데이터를 추출, 축소 및 분류하는 필수 층으로 구성됩니다. 이 섹션에서는 CNN 아키텍처의 기초 층을 설명합니다.
풀링 층
풀링 층은 이미지 크기를 줄이면서 핵심 특징을 유지합니다. 출력은 풀링 피쳐 맵이라고 불립니다. 이러한 층을 포함하는 것은 과적합을 줄이는 데 도움이 되며, 계산 비용도 줄입니다.
컨볼루션 층
컨볼루션 층 활성화는 $`Height`$ $`X`$ $`Width`$ $`X`$ $`F_m`$, 즉 $`F_m`$ 피쳐 맵의 수를 나타내는 텐서 크기로 표현됩니다. 알고리즘은 입력 이미지를 $`Height`$ $`X`$ $`Width`$ 섹션으로 분할하고 각 부문에서 시각적 패턴을 식별합니다. 각 필터는 입력 이미지에 컨볼루션을 수행하여 특정 특징을 발견하고 편향 항을 추가합니다.
네 가지 모델, 즉 세 개의 CNN 기반과 한 개의 트랜스포머 기반 모델을 적응 학습하여 실제와 가짜 딥페이크 이미지를 분류합니다.
딥페이크 컨볼루션 네트워크 (DFCNET)
DFCNET 모델은 다양한 층을 연결한 함수입니다. 각 층에서 피쳐 맵 $`z_i \in \mathbb{R}^{m_i \times n_i \times c_i}`$를 생성하며, 이는 이전 층 $`z_{i-1}`$의 출력으로부터 얻어집니다. 입력 이미지 $`x`$는 첫 번째 층 $`z_{0}`$로 사용되며, 최종 층은 출력 이미지 $`y`$를 생성합니다.
각 입력 채널은 특정 필터와 합성되어 편향을 더한 후 비선형 함수를 통과합니다. 다양한 필터와 함께 이를 반복하면 여러 개의 출력 채널이 생성됩니다.
여기서 $`\phi`$는 비선형 활성화 함수입니다. $`\beta_{ij} \in \mathbb{R}`$는 편향이고, $`f_{ij}`$는 $`c_{i-1}`$의 각 채널을 필터와 합성하여 결과를 더합니다.
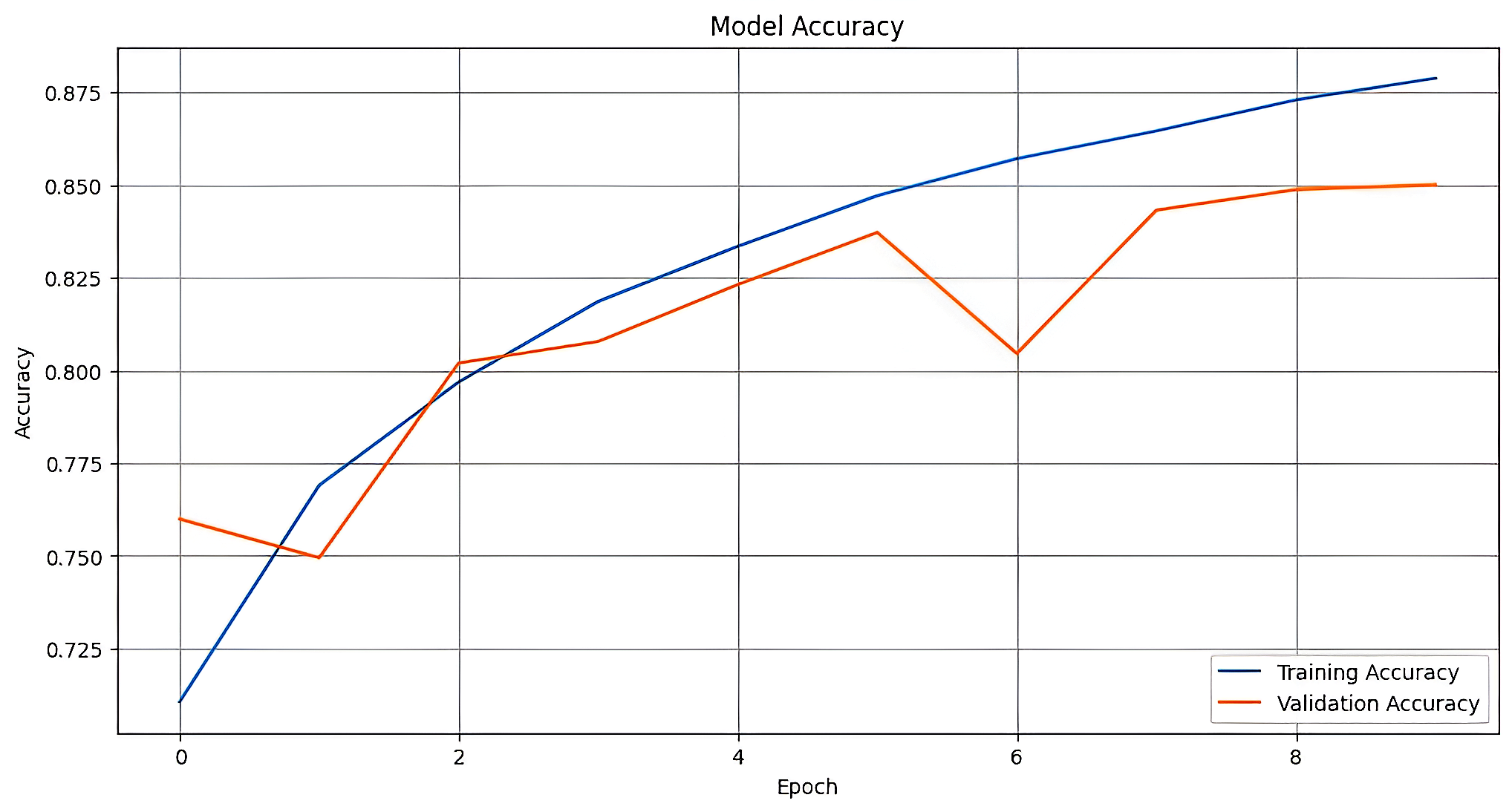
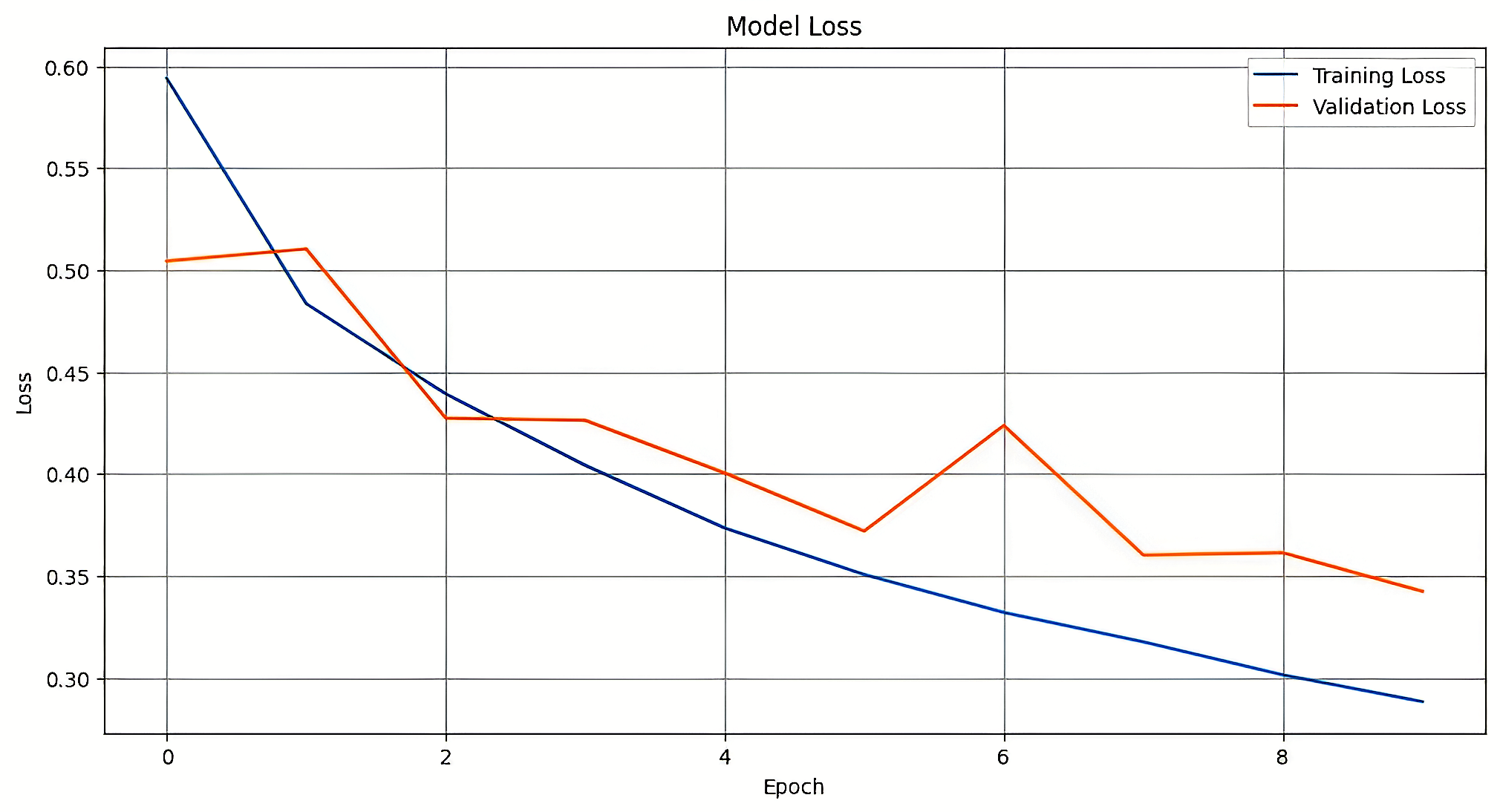
비선형성을 도입하기 위해 3개의 2D 컨볼루션 레이어와 ReLU 활성화 함수를 사용한 Max-Pooling을 구현했습니다. 과적합을 방지하기 위해 각 컨볼루션 레이어 후에 드롭아웃을 도입했으며, 256차원의 ReLU 활성화 유닛을 가진 깊은 층을 사용하여 고급 특징을 표현했습니다. 이 층은 시그모이드 분류 함수를 통해 이진 분류기 출력을 생성합니다. 훈련 과정에서는 Adam 최적화자를 사용해 이진 교차 엔트로피 손실과 정확도 지표에 기반한 모델 평가를 수행했습니다.
비전 가짜 검출 네트워크 (VFDNET)
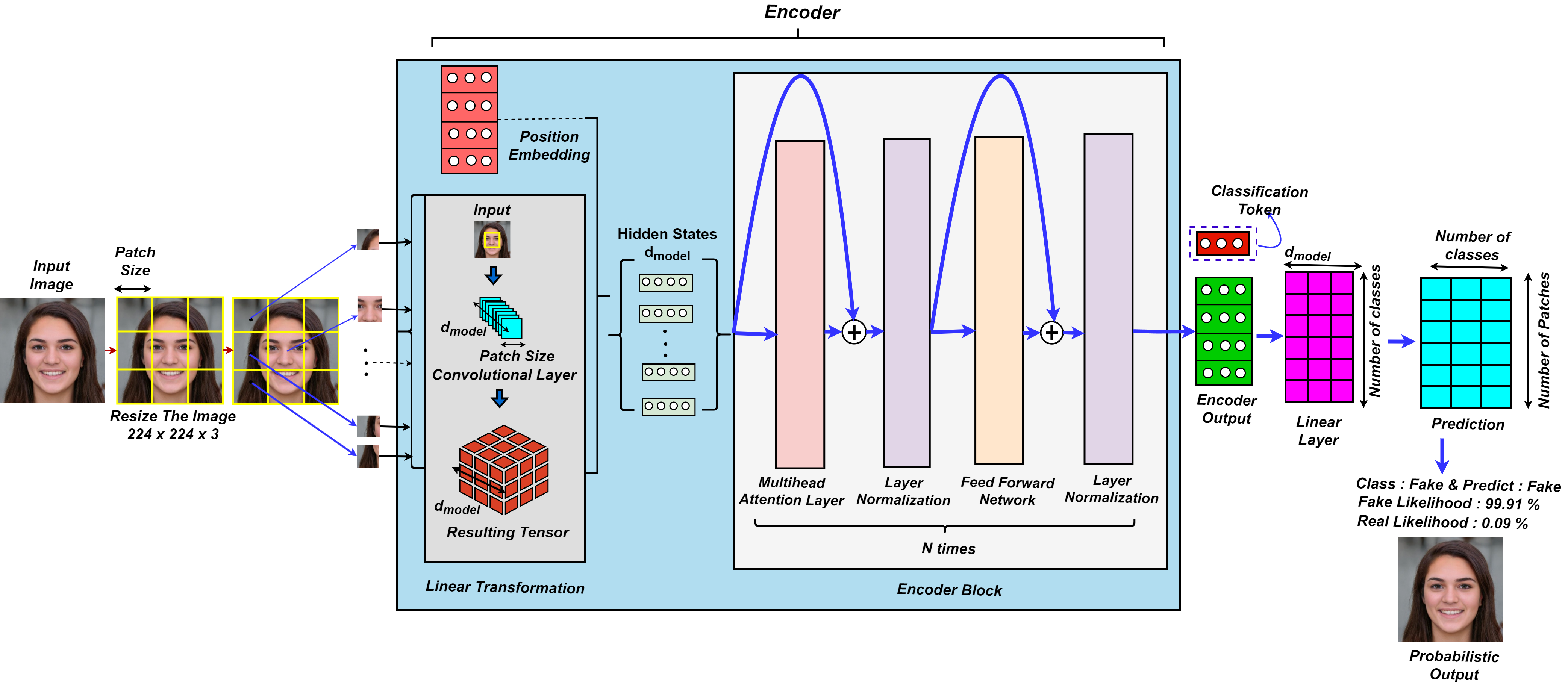
이미지 분류에서 Vision Transformer(ViT)는 CNN보다 유사하거나 더 뛰어난 성능을 보여주는 트랜스포머 기반 설계입니다. 자기 주의를 통해 전역적 문맥 관계를 수집하는 능력으로 허위 이미지 식별과 같은 작업에 이상적입니다. 본 논문에서는 또한 분류 문제 해결을 위한 ViT 기반 모델을 제안합니다.
비전 가짜 검출 네트워크 (VFDNET)의 아키텍처
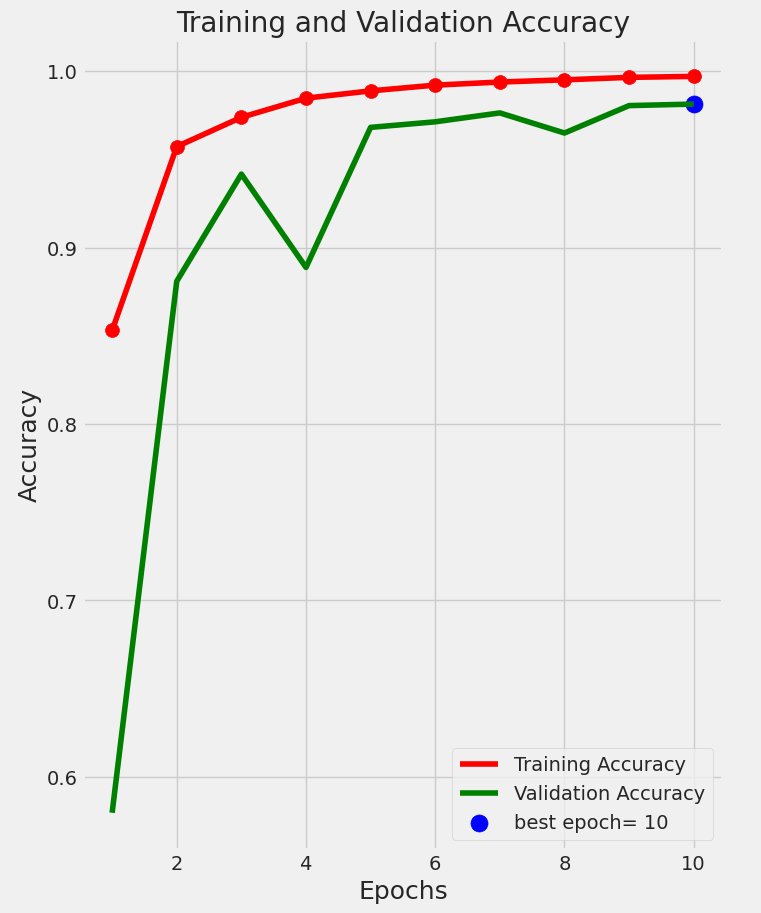
Figure 3에서 보듯이, 제안된 VFDNET 모델은 입력 이미지를 고정 크기의 패치로 나누고 각 패치를 토큰으로 선형 변환하여 시퀀스를 형성합니다. 세 가지 데이터 증강 기술인 AutoAugment_transform, RandAugment_transform, Auto_RandAugment_transform을 적용하여 모델의 견고성을 높였습니다. 모든 입력 이미지는 224 × 224 × 3으로 크기 조정되었습니다. 증강된 데이터셋은 ImageFolder 클래스를 사용해 조직화하고 DataLoader를 통해 학습 및 평가에 로드했습니다. Adam 최적화자를 사용한 이유는 적응형 학습률 능력 때문입니다. 트랜스포머 인코더 설계는 여러 블록을 포함하며, 각각은 다중 헤드 자기 주의(MSA)와 피드포워드 네트워크(FFN)를 결합합니다. FFN은 첫 번째 선형 층에 GELU 비선형성을 적용한 두 개의 멀티레이어 퍼셉트론을 구현하며, 각 블록 내에서 계층 정규화(LN)가 지원됩니다.