Accelerating Monte-Carlo Tree Search with Optimized Posterior Policies
📝 원문 정보
- Title: Accelerating Monte-Carlo Tree Search with Optimized Posterior Policies- ArXiv ID: 2601.01301
- 발행일: 2026-01-03
- 저자: Keith Frankston, Benjamin Howard
📝 초록
알파제로는 신경망을 사용하여 게임에서 높은 수준의 플레이를 학습하는 방법입니다. 이 방법은 몬테카를로 트리 탐색(MCTS) 알고리즘을 활용해 주어진 게임 상태에 대한 개선된 가치와 정책을 탐구하고 학습합니다.💡 논문 해설
1. **알파제로의 MCTS-UCB**: 알파제로는 몬테카를로 트리 탐색(MCTS) 알고리즘을 사용해 게임 트리를 탐색하며, 이 과정에서 각 상태에 대한 가치와 정책을 개선합니다. 이를 통해 신경망이 점점 더 강력해집니다.-
정규화된 정책 최적화: MCTS-UCB 대신 정규화된 정책 최적화를 사용하여, 기존 정책과의 차이를 최소화하면서 예상 보상을 극대화하는 방법을 제안합니다. 이는 특히 시뮬레이션 횟수가 적을 때 더 우수한 성능을 제공할 수 있습니다.
-
RMCTS: MCTS-UCB와 달리 RMCTS는 트리의 모든 노드에서 최적화된 정책을 사용하여 Q값을 재귀적으로 계산합니다. 이 방법은 효율적인 GPU 인퍼런스를 통해 구현되며, 특히 복잡한 게임에 대해 우수한 성능을 보입니다.
📄 논문 발췌 (ArXiv Source)
알파제로는 신경망을 훈련시켜 높은 수준에서 게임을 플레이하는 방법입니다. 주요 아이디어는 몬테카를로 트리 탐색(MCTS)을 사용해 게임 트리를 탐색하고, 현재 네트워크의 이전 가치와 정책에 기반하여 개선된 가치와 정책을 학습하는 것입니다. 네트워크는 이러한 개선된 값과 정책으로 훈련되며 시간이 지날수록 강력해집니다.
알파제로에서 몬테카를로 트리 탐색 (MCTS-UCB)은 다음과 같이 작동합니다 (더 자세한 설명은 [alg:mcts] 참조, 섹션 4). 추정된 행동 가치 $`Q(s,\cdot)`$를 0으로 초기화하고, 여러 시뮬레이션을 수행하여 $`Q`$ 값을 정교하게 하고 후행 정책을 얻습니다. 시뮬레이션은 항상 루트 상태에서 시작하며, 최대 UCB 값을 가지는 행동을 선택합니다. 여기서 UCB 값은 다음과 같이 정의됩니다.
\mathop{\mathrm{ucb}}(s,a) = Q(s,a) + C \cdot \pi_0(s,a) \cdot \frac{\sqrt{\sum_{b} N(s,b)}}{1 + N(s,a)}여기서 $`s`$는 현재 상태, $`a`$는 $`s`$에서 가능한 행동이며, $`Q(s,a)`$는 상태 $`s`$에서 행동 $`a`$를 취했을 때의 추정 보상입니다. $`C > 0`$은 탐색 상수이고, $`N(s,a)`$는 이전 시뮬레이션에서 상태 $`s`$에서 행동 $`a`$가 선택된 횟수이며, 마지막으로 $`\pi_0(s,\cdot)`$는 사전 정책(네트워크)입니다.
우리는 계속해서 가장 높은 UCB 값을 가지는 행동을 선택하여 탐색 트리를 내려가며, 최종적으로 종료 상태 $`s'`$에 도달하거나 아직 트리에 포함되지 않은 상태에 도달할 때까지 진행합니다. 만약 $`s'`$가 종료 상태라면, 그 값은 단순히 게임 점수입니다. 그렇지 않다면, $`s'`$의 값은 네트워크 값 $`v_0(s)`$이고, 트리에 추가되며, 모든 행동에 대해 $`Q(s',\cdot)`$와 $`N(s',\cdot)`$를 0으로 초기화합니다. 이 최종 상태의 값은 적절한 플레이어 기호를 사용하여 루트까지 전파됩니다; 경로상의 각 상태는 자신의 $`Q`$ 및 $`N`$ 값을 적절히 업데이트합니다.
$`Q`$와 $`N`$ 값을 업데이트하면 UCB 값이 변경되므로 다음 시뮬레이션에서는 다른 경로가 선택될 수 있습니다. $`N(s) = \sum_a N(s,a)`$가 예산된 시뮬레이션 횟수에 도달할 때까지 이 과정은 계속됩니다. 이 시점에서 상태 $`s`$의 후행 정책 $`\hat\pi`$는 표준화된 방문 횟수로 정의되며, $`\hat\pi(s,a) = \frac{N(s,a)}{N(s)}`$입니다.
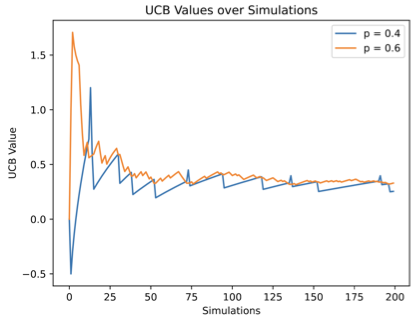
1은 단순한 (하나의 플레이어만 있는) 대포 게임에서 두 개의 슬롯 팔을 가진 UCB 값의 변화를 시각화합니다. 각 슬롯은 $`+1`$ 또는 $`-1`$ 보상을 제공하며, $`+1`$의 확률은 고정된 숨겨진 매개변수 $`p`$입니다. 한 슬롯에 대해 $`p = 0.6`$, 다른 슬롯에는 $`p = 0.4`$입니다. 우월하지 않은 선택 ($`p = 0.4`$)은 결코 포기되지 않습니다; 이 행동은 $`\Theta(1/\sqrt{N})`$의 확률로 선택되며, 여기서 $`N`$은 총 시뮬레이션 횟수입니다. $`N \to \infty`$일 때, 두 UCB 값은 점점 가까워져서 $`0.2 + \Theta(1 / \sqrt{N})`$에 접근합니다.
 />
/>
정규화된 정책 최적화
“몬테카를로 트리 탐색은 정규화된 정책 최적화”에서는 $`\hat\pi`$ 대신 다른 방법을 탐구했습니다. 최적화된 후행 정책 $`\bar{\pi}(s,\cdot)`$는 추정 보상 $`Q(s,a)`$를 가정한 예상 보상의 최대화와 사전 정책 $`\pi_0(s, \cdot)`$로부터의 페널티를 고려합니다. 구체적으로, $`\bar\pi(s,\cdot)`$는 게임 상태 $`s`$에서 행동에 대한 유일한 분포로 정의되며,
\sum_a \bar\pi(s,a) Q(s,a) - \frac{C}{\sqrt{N(s)}} \mathop{\mathrm{KL-Div}}(\pi_0(s,\cdot) \mid\mid \bar\pi(s, \cdot))여기서 $`\mathop{\mathrm{KL-Div}}`$는 Kullback-Leibler 발산이며, $`C > 0`$은 MCTS-UCB에서 사용된 동일한 탐색 상수입니다. 그들은 $`\bar{\pi}`$가 시뮬레이션 횟수가 무한대에 가까워질 때 $`\hat{\pi}`$(표준화된 방문 횟수)와 점점 더 비슷해진다는 것을 보였지만, 시뮬레이션 횟수가 적을 때 $`\bar{\pi}`$가 $`\hat{\pi}`$보다 우월하다고 주장합니다. 그들은 AlphaZero 알고리즘에서 $`\hat\pi`$를 $`\bar\pi`$로 대체할 것을 제안하며, 여기서 $`Q`$-값은 원래의 MCTS-UCB 버전의 AlphaZero에서 계산됩니다.
최적화된 후행 정책 $`\bar{\pi}`$는 흥미롭게도 모든 행동의 UCB 값을 같게 만드는 정책이라는 점에서 해석할 수 있습니다. UCB 값은 다음과 같이 정의됩니다.
\mathop{\mathrm{ucb}}(s,a) = Q(s,a) + C \cdot \pi_0(s,a) \cdot \frac{\sqrt{N(s)}}{1 + N(s,a)}.이제 상태 $`s`$에서 모든 시뮬레이션이 완료되었고, $`\hat{\pi}(s,a) = \frac{N(s,a)}{N(s)}`$는 표준화된 방문 횟수라고 가정합시다. 간단히 분모의 탐색 항목을 제거합니다. 이제 UCB 값을 다시 작성할 수 있습니다.
\begin{align*}
\mathop{\mathrm{ucb}}(s,a) &= Q(s,a) + C \cdot \pi_0(s,a) \cdot \frac{\sqrt{N(s)}}{\hat{\pi}(s,a) N(s)} \\
&= Q(s,a) + \frac{C}{\sqrt{N(s)}} \cdot \frac{\pi_0(s,a)}{\hat{\pi}(s,a)}.
\end{align*}이제 $`\hat{\pi}(s,a)`$를 변수 $`\bar{\pi}(s,a)`$로 대체하고, 목적 함수
F(\bar{\pi}(s,\cdot)) = \sum_a \bar{\pi}(s,a) Q(s,a) - \frac{C}{\sqrt{N(s)}} \mathop{\mathrm{KL-Div}}(\pi_0(s,\cdot) \mid\mid \bar{\pi}(s, \cdot)),를 최대화하는 문제를 고려해봅시다. 여기서 제약 조건은 $`\sum_a \bar{\pi}(s,a) = 1`$입니다. 간단한 계산을 통해 $`\frac{\partial F}{\partial \bar{\pi}(s,a)} = \mathop{\mathrm{ucb}}(s,a)`$ 를 얻을 수 있습니다. 다른 한편으로, 제약 함수 $`\sum_a \bar{\pi}(s,a) = 1`$는 각 변수에 대해 부분 도함수 $`1`$을 가집니다. 따라서 라그랑주 승수법은 최적의 $`\bar{\pi}(s,\cdot)`$가 모든 UCB 값 $`\mathop{\mathrm{ucb}}(s,a)`$가 같아지는 곳에서만 발생할 수 있음을 알려줍니다. 1을 보면 MCTS-UCB의 UCB 값이 시간이 지남에 따라 서로 가까워진다는 것을 볼 수 있습니다; 이 최적화된 후행 정책 $`\bar{\pi}`$는 이를 강제합니다.
만약 $`u`$가 최적의 후행 정책 $`\bar{\pi}(s,\cdot)`$에 대한 공통 UCB 값이라면, 다음과 같습니다.
\bar{\pi}(s,a) = \frac{C}{\sqrt{N(s)}} \frac{\pi_0(s,a)}{u - Q(s,a)}.특히 $`u > \max_a Q(s,a)`$인 유일한 값에 대해 다음과 같습니다.
\sum_a \frac{C}{\sqrt{N(s)}} \frac{\pi_0(s,a)}{u - Q(s,a)} = 1.이 값은 확실히 존재합니다. $`u \to \max_a Q(s,a)^+`$일 때 왼쪽 항이 $`+\infty`$로 접근하므로, $`u \to +\infty`$일 때 왼쪽 항이 $`0`$으로 접근합니다.
최적의 후행 정책 $`\bar{\pi}`$는 뉴턴 방법을 사용하여 효율적으로 계산할 수 있습니다 (cf. [alg:eucb] 참조, 섹션 4). 이 알고리즘에서 함수 $`f`$는 볼록하며 초기값이 해의 적절한 측면에 있으므로 뉴턴 방법은 수렴을 보장합니다.
RMCTS
최적화된 후행 정책 $`\bar{\pi}`$의 중요한 특징 중 하나는 각 게임 상태 $`s`$에서 단순히 추정 행동 가치 $`Q(s,\cdot)`$와 사전 정책 $`\pi_0(s,\cdot)`$만을 사용하여 로컬하게 계산될 수 있다는 것입니다. 이는 검색 트리의 나머지 세부 사항에 대한 정보가 필요하지 않음을 의미합니다. 이를 통해 우리는 MCTS-UCB를 대체하는 재귀적 방법인 RMCTS를 정의할 수 있습니다.
최적화된 후행 정책 $`\bar{\pi}`$는 추정된 $`Q`$ 값을 AlphaZero의 원래 MCTS-UCB 변형에서 얻습니다. 반면에 RMCTS는 트리 전체에서 최적화된 정책을 사용하여 MCTS 자체를 완전히 재정의합니다. $`Q`$ 값은 재귀적으로 계산되며, 검색 트리의 노드 $`s'`$의 값은 아래 $`s'`$에서 최적화된 후행 정책을 계산함으로써 근사됩니다 (자세한 설명은 [alg:rmcts] 참조, 섹션 4).
검색 트리는 각 노드에서 사전 네트워크 정책을 따르는 방식으로 생성됩니다 (특히 UCB 값에 의해 정의되지 않습니다). 트리의 각 노드 $`s`$는 한 번의 시뮬레이션을 소비하고, 나머지 시뮬레이션은 사전 정책 $`\pi_0(s,\cdot)`$에 따라 자식 행동에게 분배됩니다. 따라서 상태 $`s`$가 $`N(s)`$ 시뮬레이션을 받았다면, 네트워크에서 사전 정책 $`\pi_0(s,\cdot)`$와 값 $`v_0(s)`$를 얻는데 한 번의 시뮬레이션이 사용되므로 나머지 $`N(s)-1`$ 시뮬레이션은 상태 $`s`$에서 가능한 행동들 사이에 분배됩니다. 행동 $`a`$에게 할당된 시뮬레이션 횟수 $`N(s,a)`$(참조 [alg:assign_sims])의 기대값은 $`\mathbb{E}[N(s,a)] = \pi_0(s,a) (N(s)-1)`$이며, 여기서 $`\pi_0`$는 상태 $`s`$에서 사전 네트워크 정책입니다. MCTS-UCB와 마찬가지로, $`s'`$가 비종료 리프(하나의 시뮬레이션을 받음)라면 그 값은 네트워크 값 $`v_0(s')`$입니다. $`s'`$가 종료 상태라면, 그 값은 단순히 게임 점수입니다 (5 섹션에서 RMCTS를 설명하는 간단한 예제 참조).
효율적으로 RMCTS 구현
4 섹션에서의 RMCTS 설명은 수학적으로 정확하지만 재귀 호출을 사용하는 방식으로 효율적으로 구현하기는 어렵습니다. https://github.com/bhoward73/rmcts 를 참조하여 효율적인 C 구현체를 확인하세요. 이 효율적인 구현에서 [alg:rmcts]는 반복적으로 동작하며, 검색 트리를 너비 우선 탐색 방식으로 탐색합니다. 동일 깊이의 모든 노드는 하나의 큰 GPU 추론 배치를 형성하므로 GPU 지연 비용은 크게 완화됩니다. 검색 트리와 관련 데이터에 대한 연속 메모리는 미리 할당되어 캐시 성능을 개선합니다.
타이밍 및 품질 비교
6 섹션에서 보고한 타이밍은 위에서 설명한 효율적인 RMCTS 구현을 기반으로 합니다. 7 섹션에서는 Connect-4, Dots-and-Boxes, Othello 세 가지 게임에서 RMCTS와 MCTS-UCB의 품질을 비교합니다. 이 대회에서 RMCTS와 MCTS-UCB는 같은 신경망을 사용합니다.
알고리즘 설명
이 섹션에서는 MCTS-UCB([alg:mcts])와 RMCTS([alg:rmcts])의 정확한 설명을 제공합니다.
서브루틴 [alg:assign_sims] (ASSIGN-SIMULATIONS)은 사전 정책 $`\pi_0(s,\cdot)`$에 따라 총 $`N`$ 시뮬레이션을 행동에 무작위로 분배합니다. 행동 $`a`$는 $`N(s,a)`$ 시뮬레이션을 할당받습니다. 기대값은 $`\mathbb{E}[N(s,a)] = \pi_0(s,a) N`$, 그리고 $`\lfloor \pi_0(s,a) N \rfloor \leq N(s,a) \leq \lceil \pi_0(s,a) N \rceil`$입니다. 특히 모든 행동 $`a`$는 적어도 $`\lfloor \pi_0(s,a) N \rfloor`$ 시뮬레이션을 보장받습니다. 마지막으로, $`\sum_a N(s,a) = N`$입니다.
간단한 예제
다음 단순 게임 트리를 참조하세요. 이 게임은 두 개의 비종료 상태 $`s`$와 $`t`$를 가진 이진 트리로 구성됩니다 (그림 2). 가능한 행동은 왼쪽($`\ell`$)과 오른쪽($`r`$)입니다. 루트 상태 $`s`$에서 시작하여 왼쪽으로 간다면 종료 상태에 도달하고 그 값은 $`1`$입니다. 대신 오른쪽으로 가면 비종료 상태 $`t`$에 도착합니다. $`t`$에서 왼쪽으로 가면 값이 $`-3`$인 종료 상태에 도달하며, 오른쪽으로 가면 값이 $`2`$인 종료 상태에 도달합니다.
$`N = 1003`$ 시뮬레이션이 루트 $s`에서 제공되는 경우를 가정합니다.
📊 논문 시각자료 (Figures)