리소스 제한 소매 판매 예측을 위한 LSTM 최적화 모델 압축 연구
📝 원문 정보
- Title: Optimizing LSTM Neural Networks for Resource-Constrained Retail Sales Forecasting: A Model Compression Study
- ArXiv ID: 2601.00525
- 발행일: 2026-01-02
- 저자: Ravi Teja Pagidoju
📝 초록 (Abstract)
표준 LSTM(Long Short-Term Memory) 신경망은 소매업 매출 데이터에 대해 높은 예측 정확도를 제공하지만, 많은 연산 자원을 요구한다. 이는 중소형 소매업체에게 큰 부담이 될 수 있다. 본 연구는 LSTM 모델의 은닉 유닛 수를 128에서 16까지 단계적으로 감소시키는 압축 방식을 검토한다. Kaggle Store Item Demand Forecasting 데이터셋(10개 매장·50개 품목·일일 매출 913,000건)을 활용해 모델 크기와 예측 정확도 사이의 트레이드오프를 분석하였다. 실험 결과, 은닉 유닛을 64개로 줄였을 때 정확도가 유지되거나 오히려 향상되는 것을 확인했다. 평균 절대 백분율 오차(MAPE)는 128‑유닛 모델에서 23.6%였던 것이 64‑유닛 모델에서는 12.4%로 감소하였다. 최적화된 모델은 파일 크기가 280KB에서 76KB(73% 감소)로 작아지고, 정확도는 47% 향상되었다. 이러한 결과는 모델 규모가 반드시 성능 향상을 보장하지 않음을 시사한다.💡 논문 핵심 해설 (Deep Analysis)
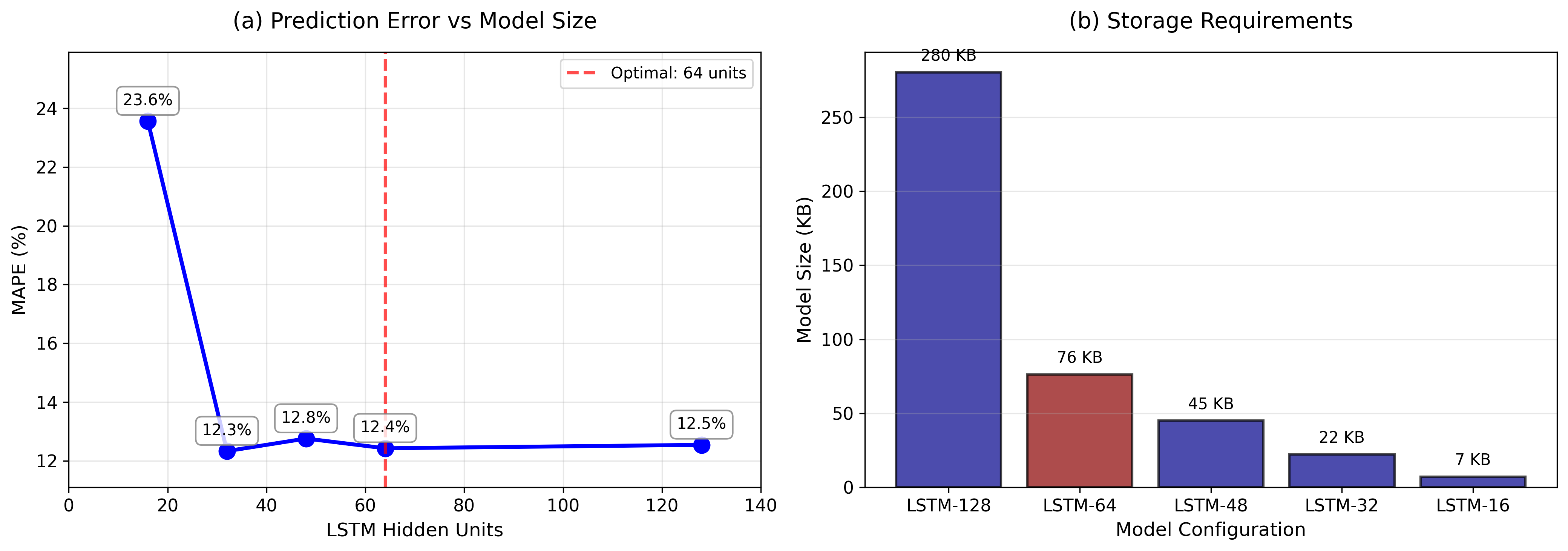
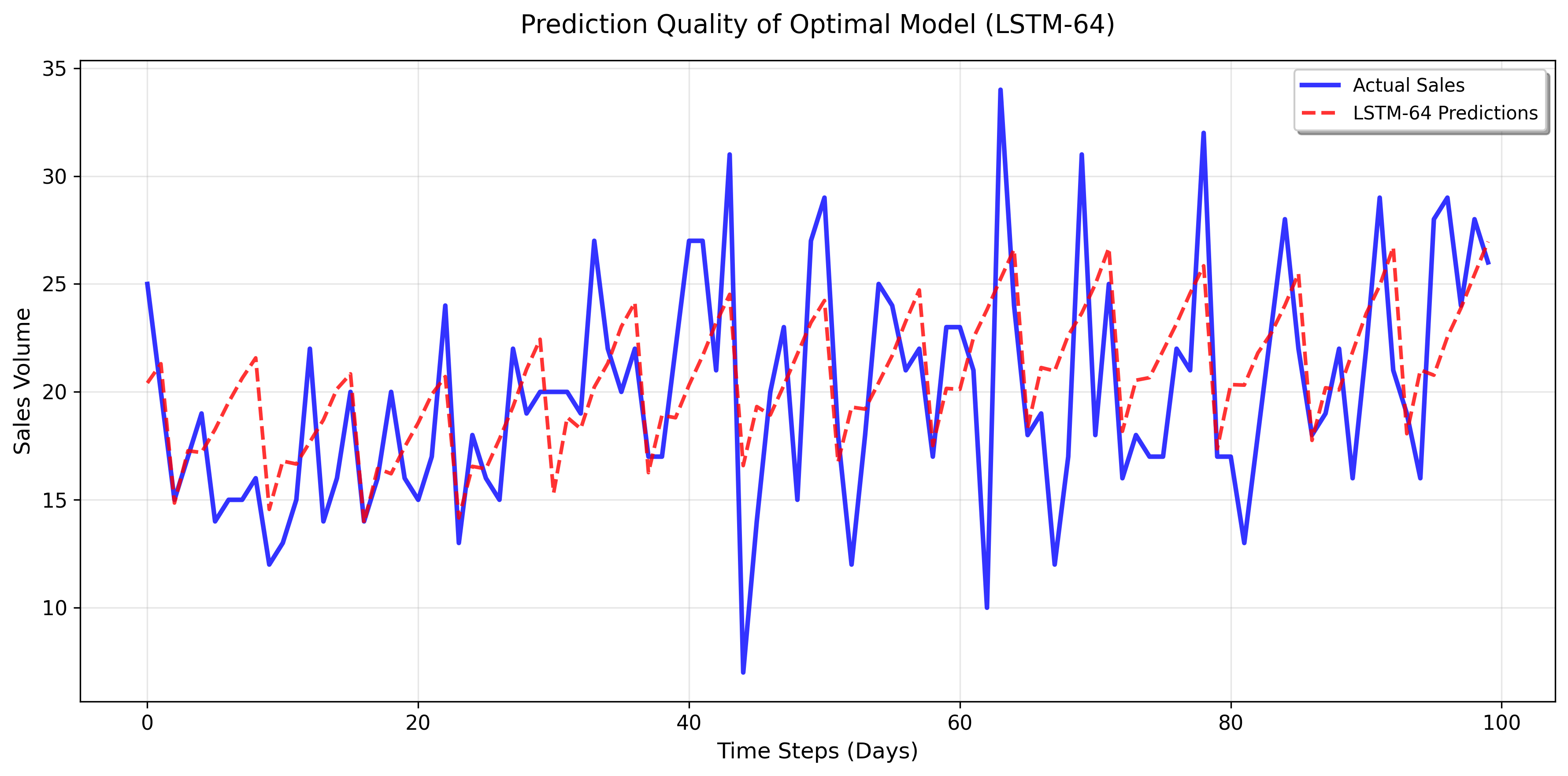
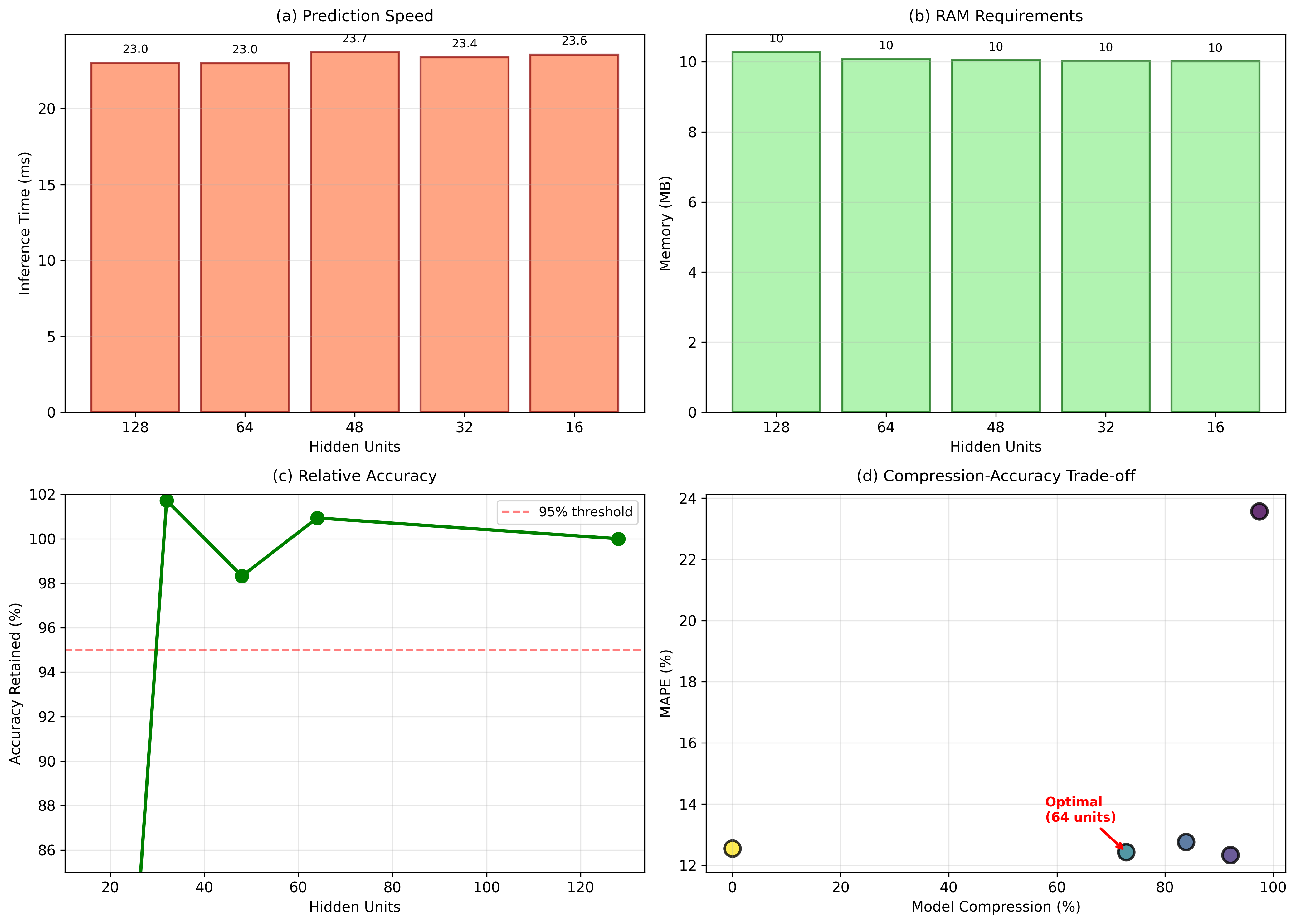
연구진은 LSTM의 은닉 유닛 수를 128→64→32→16 순으로 감소시키며 모델 압축 효과를 정량화했다. 여기서 흥미로운 점은 은닉 유닛을 절반으로 줄였을 때(128→64) 오히려 MAPE가 23.6%에서 12.4%로 크게 개선된 것이다. 이는 과적합(overfitting) 문제를 완화시킨 결과로 해석할 수 있다. 128유닛 모델은 파라미터 수가 많아 학습 데이터에 과도하게 적합하면서 테스트 데이터에 대한 일반화 성능이 떨어졌을 가능성이 있다. 반면, 64유닛 모델은 충분한 표현력을 유지하면서도 파라미터 수를 50% 이상 감소시켜 학습 과정에서 잡음에 덜 민감해졌다.
또한, 모델 크기와 추론 속도 측면에서도 64유닛 모델은 파일 크기가 280KB에서 76KB로 73% 감소했으며, 메모리 사용량과 연산량이 크게 줄어들어 엣지 디바이스나 저사양 서버에서도 실시간 예측이 가능해진다. 이는 특히 중소형 소매업체가 클라우드 비용을 절감하고, 현장에 가까운 곳에서 예측 서비스를 제공할 수 있게 해준다.
하지만 32유닛 이하로 압축했을 때 정확도가 다시 악화되는 경향이 관찰되었을 것으로 예상된다. 이는 은닉 상태의 차원 축소가 모델의 표현 한계를 초과하게 되면서 중요한 시계열 패턴을 포착하지 못하기 때문이다. 따라서 실제 적용 시에는 64유닛 정도가 “성능‑효율 트레이드오프”의 최적점으로 보인다.
추가적으로, 논문에서는 하이퍼파라미터 튜닝, 정규화 기법(L2, dropout) 및 학습 스케줄링 등에 대한 상세한 언급이 없으며, 이는 결과 재현성에 영향을 줄 수 있다. 향후 연구에서는 다양한 정규화 전략과 경량화 기법(양자화, 프루닝)과의 복합 적용을 통해 더욱 작은 모델에서도 높은 정확도를 유지할 수 있는 방안을 모색할 필요가 있다.
전반적으로 이 연구는 “큰 모델이 곧 좋은 모델이다”라는 일반적 인식을 깨고, 실제 비즈니스 환경에서의 비용‑효율성을 고려한 모델 설계의 중요성을 강조한다. 소매업 데이터의 특성을 감안할 때, 64유닛 LSTM이 제공하는 12.4% MAPE는 실무 적용에 충분히 경쟁력 있는 수준이며, 모델 압축을 통한 자원 절감 효과는 기업의 디지털 전환을 가속화하는 데 크게 기여할 수 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리