IRPO: 브래들리‑터키 모델을 강화학습으로 확장하는 새로운 방법
📝 원문 정보
- Title: IRPO: Scaling the Bradley-Terry Model via Reinforcement Learning
- ArXiv ID: 2601.00677
- 발행일: 2026-01-02
- 저자: Haonan Song, Qingchen Xie, Huan Zhu, Feng Xiao, Luxi Xing, Fuzhen Li, Liu Kang, Feng Jiang, Zhiyong Zheng, Fan Yang
📝 초록 (Abstract)
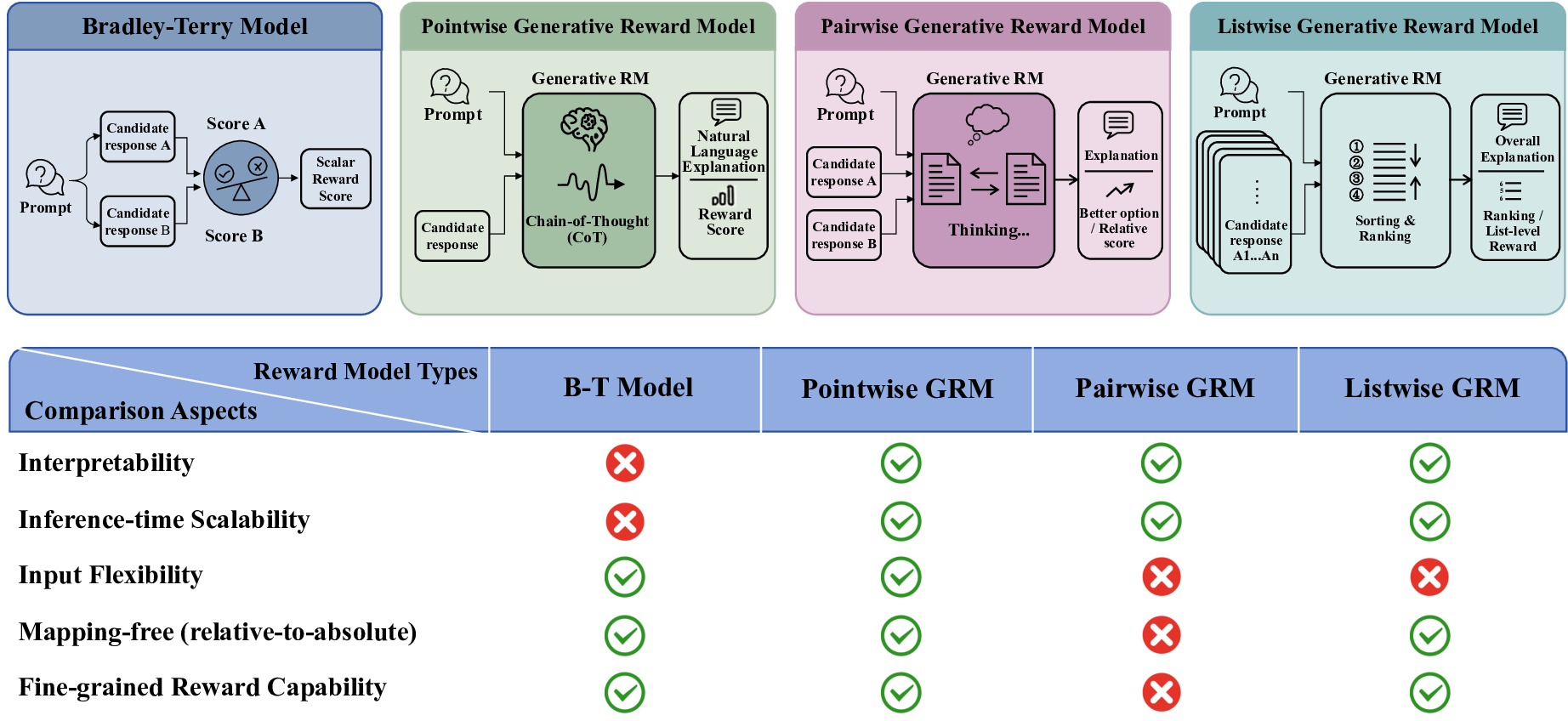
생성형 보상 모델(GRM)은 해석 가능성과 강화학습(RL)을 통한 정제 가능성 때문에 보상 모델링에서 뛰어난 성능을 보여왔다. 그러나 널리 사용되는 쌍대 GRM은 n개의 후보에 대해 선호 신호를 보정·통합할 때 O(n²)의 쌍별 판단이 필요해 인간 피드백 기반 강화학습(RLHF)의 계산 병목이 된다. 이를 해결하고자 우리는 그룹 간 상대 선호 모델링(IRPM)이라는 RL 기반 방법을 제안한다. IRPM은 브래들리‑터키 선호 학습 패러다임을 확장해, 쌍대 선호 데이터를 이용해 점별 GRM을 학습한다. 선택된 샘플 그룹과 거부된 샘플 그룹을 대비시켜 각 응답에 대한 점별 보상을 도출함으로써 후보 집합 간에 비교 가능한 점수를 제공하고, RL 훈련 중 가변적인 후보 수에 대해 O(n)의 보상 평가를 가능하게 한다. 해석 가능성과 확장성을 유지하면서도 IRPM은 RM‑Bench, JudgeBench, RewardBench에서 점별 GRM 중 최고 수준의 성능을 기록했으며, 최첨단 쌍대 GRM에 근접하는 결과를 보였다. 또한 사후 훈련 평가에서도 큰 향상을 보여, 이 방법의 실효성을 입증한다.💡 논문 핵심 해설 (Deep Analysis)
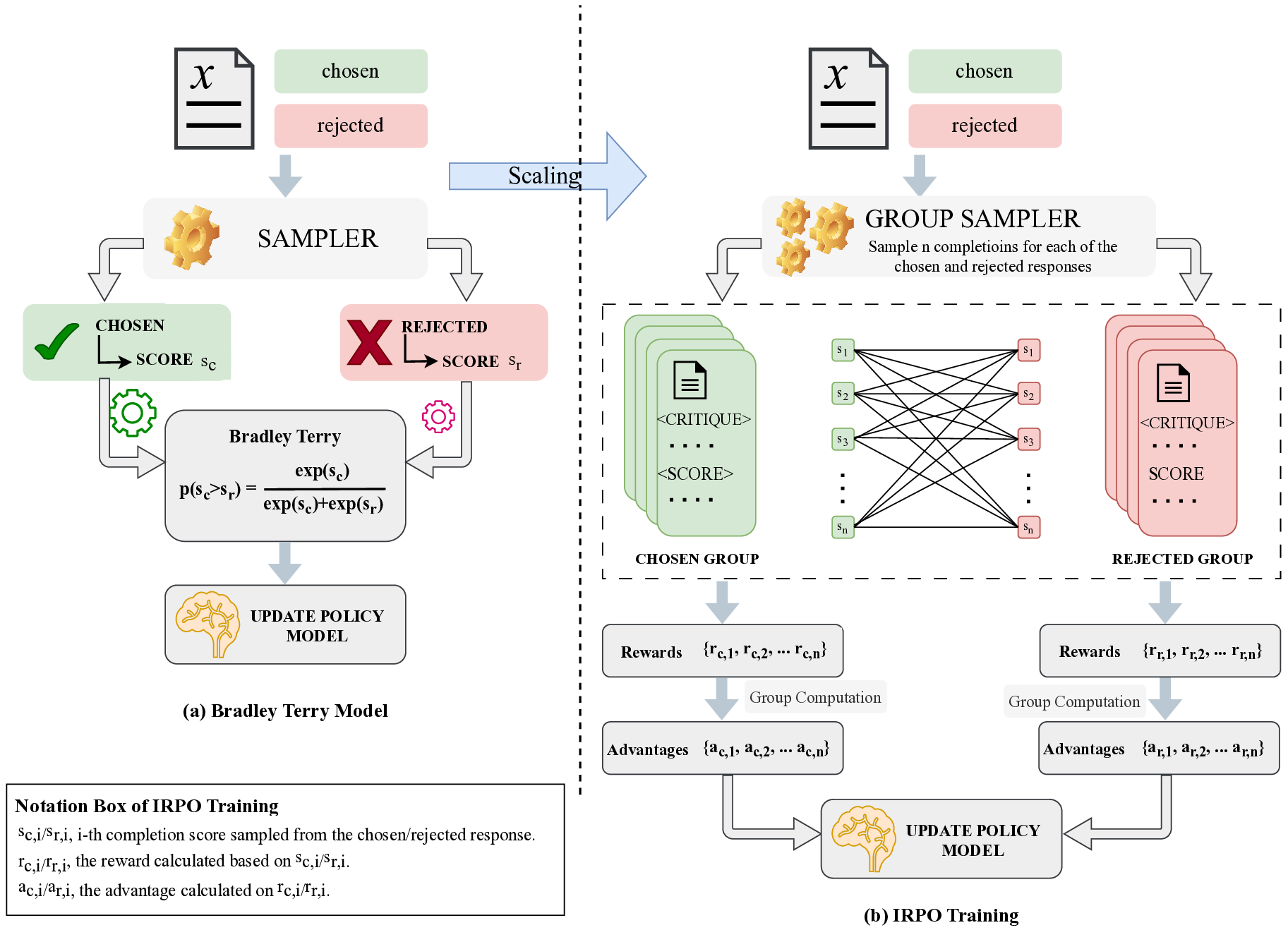
IRPM은 “그룹 간 비교”라는 새로운 시각을 도입한다. 구체적으로, 인간 라벨러가 제공한 쌍대 선호 데이터를 이용해 ‘선택된’ 샘플 집합과 ‘거부된’ 샘플 집합을 구성하고, 두 집합의 평균 점수를 대비시켜 점별 보상 함수를 학습한다. 이 과정은 브래들리‑터키 모델의 로그우도 함수를 그룹 수준으로 확장한 형태이며, 각 후보에 대한 점별 스코어를 직접 출력한다. 따라서 훈련 중에는 후보 개수 n에 비례하는 O(n) 연산만으로 보상을 계산할 수 있다.
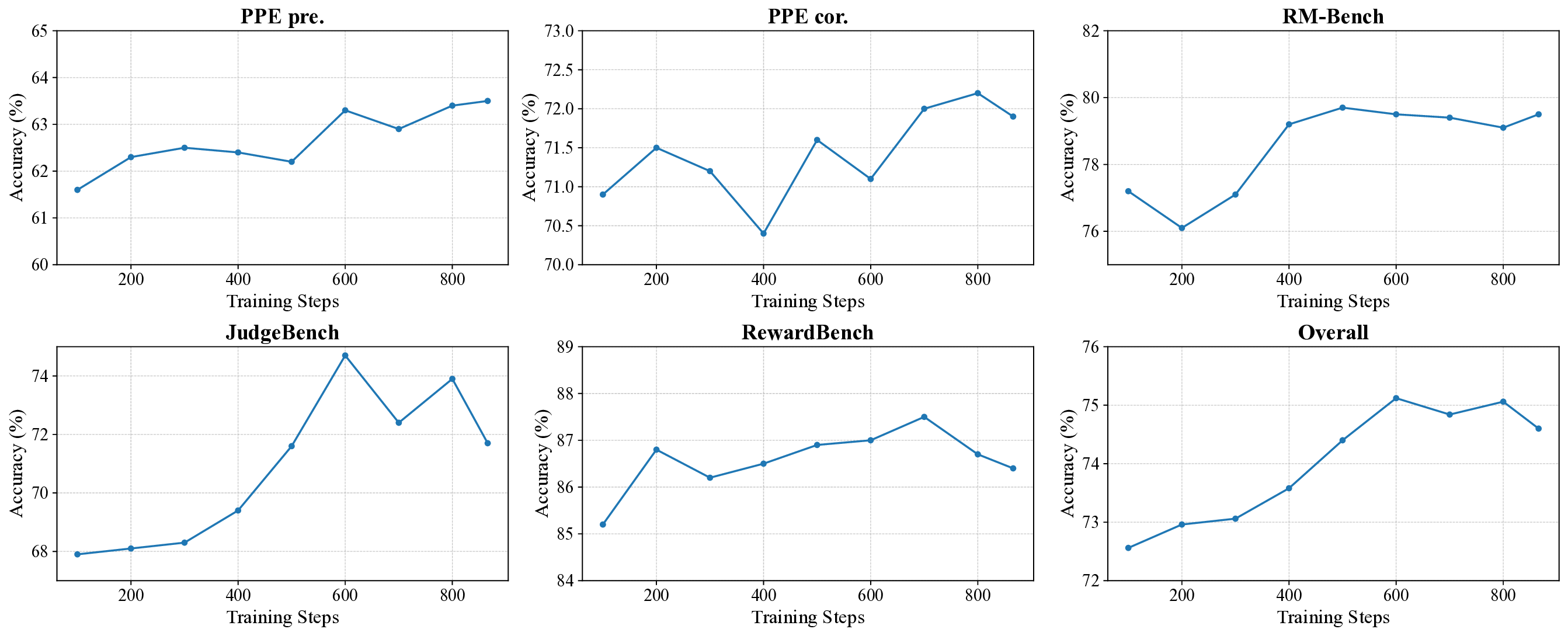
핵심적인 장점은 세 가지이다. 첫째, 확장성이다. 후보 수가 늘어나도 연산량이 제곱으로 증가하지 않으므로 대규모 언어 모델의 RL 단계에 바로 적용 가능하다. 둘째, 해석 가능성이다. 점별 보상은 기존 브래들리‑터키 모델과 동일한 의미 체계를 유지하므로, 인간 라벨러가 이해하기 쉬운 “선호 점수” 형태로 제공된다. 셋째, 성능이다. 실험 결과는 RM‑Bench, JudgeBench, RewardBench 등 다양한 벤치마크에서 점별 GRM 중 최고 수준을 기록했으며, 최첨단 쌍대 GRM과의 격차를 크게 좁혔다. 특히 사후 훈련(post‑training) 단계에서의 향상은 IRPM이 학습된 보상 함수를 실제 응용에 효과적으로 전이할 수 있음을 시사한다.
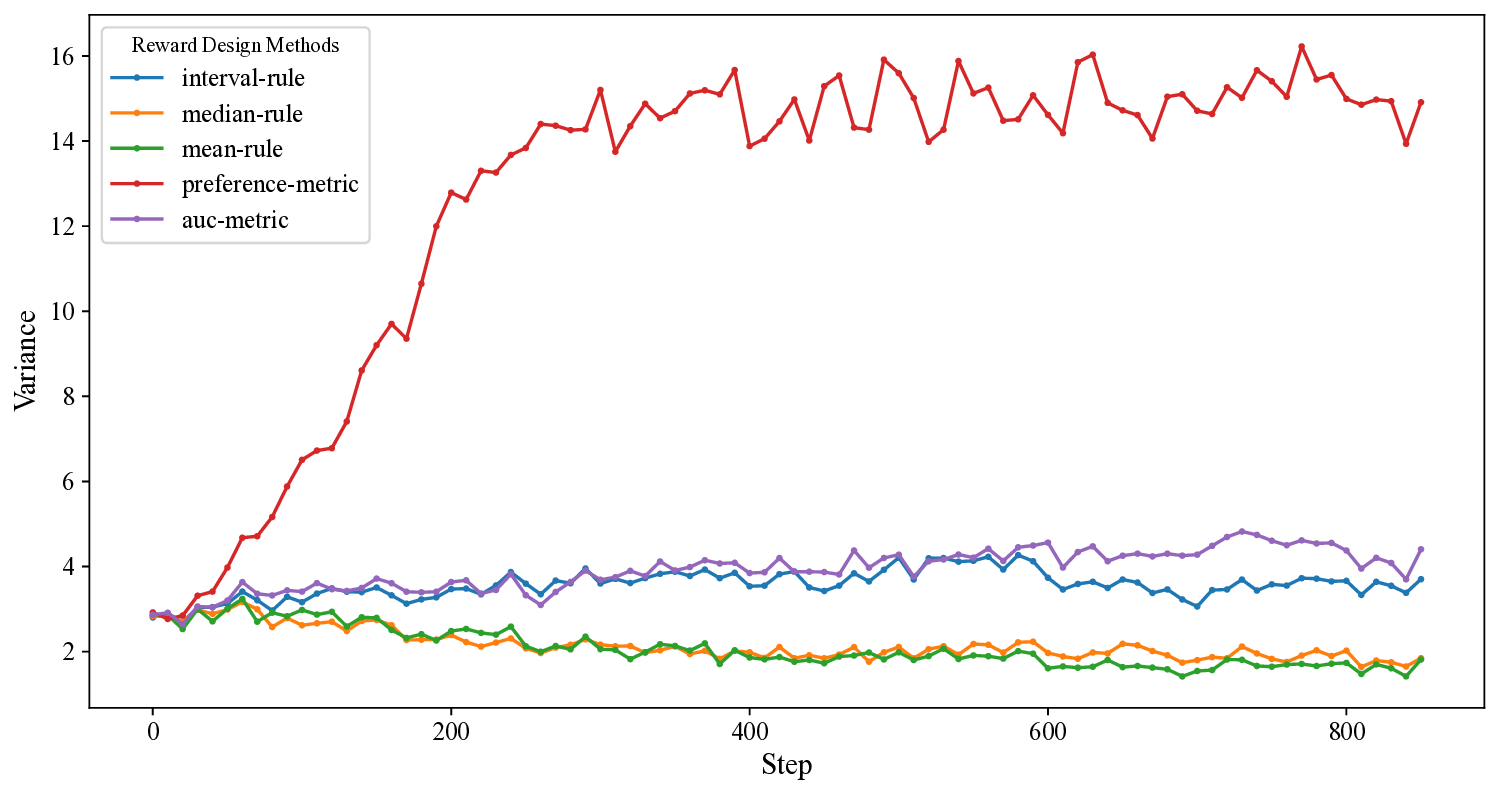
하지만 몇 가지 한계도 존재한다. 그룹을 어떻게 구성하느냐에 따라 보상의 편향이 발생할 수 있으며, 라벨링 비용이 여전히 쌍대 데이터에 의존한다는 점이다. 또한, “선택 vs. 거부”라는 이진 구분이 복잡한 다중 선호 구조를 충분히 포착하지 못할 가능성도 있다. 향후 연구에서는 그룹 샘플링 전략을 최적화하고, 다중 라벨링 혹은 순위 기반 데이터를 통합하는 확장 모델을 모색할 필요가 있다.
전반적으로 IRPM은 RLHF의 효율성을 크게 개선하면서도 기존 브래들리‑터키 모델의 장점을 보존하는 혁신적인 접근법이며, 대규모 언어 모델의 실용적 배포에 중요한 전환점을 제공한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리