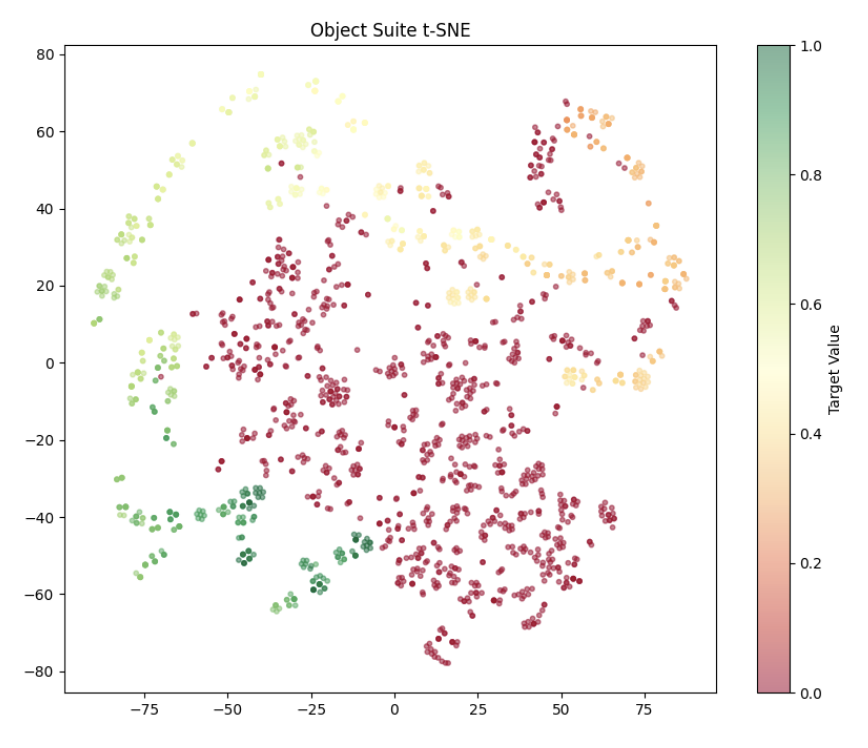
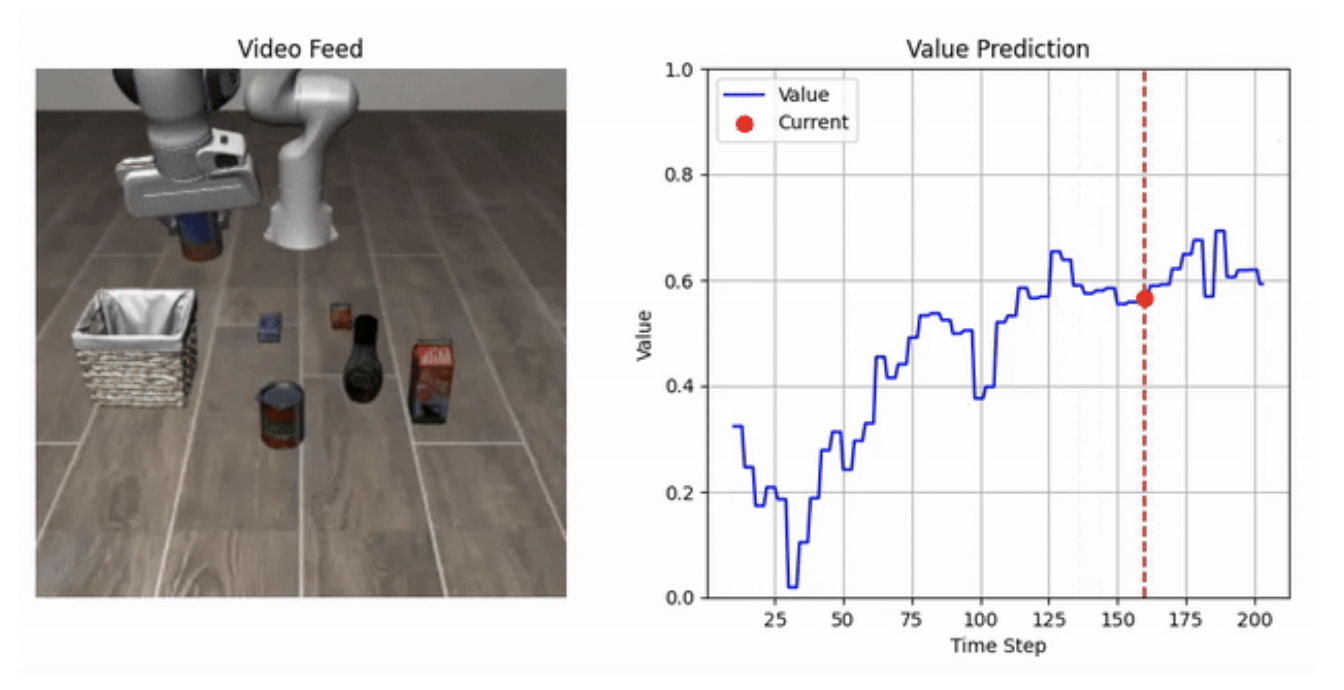
가치 기반 비전‑언어‑행동 계획 및 탐색
📝 원문 정보
- Title: Value Vision-Language-Action Planning & Search
- ArXiv ID: 2601.00969
- 발행일: 2026-01-02
- 저자: Ali Salamatian, Ke, Ren, Kieran Pattison, Cyrus Neary
📝 초록 (Abstract)
비전‑언어‑행동(VLA) 모델은 로봇 조작을 위한 강력한 범용 정책으로 부상했지만, 행동 복제에 의존하기 때문에 분포 이동 상황에서 취약한 한계를 가지고 있다. 테스트 시점 탐색 알고리즘인 몬테카를로 트리 탐색(MCTS)을 사전 학습된 모델에 결합하면 이러한 실패를 완화할 수 있지만, 기존 방식은 VLA 사전만을 탐색 가이드로 사용하고 미래 기대 보상의 근거가 되는 평가값을 제공하지 않는다. 따라서 사전이 부정확할 경우 탐색은 탐색 항에 의존해 행동을 교정해야 하는데, 이는 효과를 발휘하려면 많은 시뮬레이션이 필요하다. 이를 해결하기 위해 우리는 경량의 학습 가능한 가치 함수와 MCTS를 결합한 Value Vision‑Language‑Action Planning and Search(V‑VLAPS) 프레임워크를 제안한다. 고정된 VLA 백본(Octo)의 잠재 표현에 대해 간단한 다층 퍼셉트론(MLP)을 학습시켜 성공 가능성을 명시적으로 제공함으로써, 탐색이 고가치 영역을 우선적으로 탐색하도록 편향한다. LIBERO 로봇 조작 벤치마크에서 V‑VLAPS를 평가한 결과, 가치‑가이드 탐색이 성공률을 5% 이상 향상시키고, 사전만을 이용한 기존 방법에 비해 평균 MCTS 시뮬레이션 수를 5‑15% 감소시켰다.💡 논문 핵심 해설 (Deep Analysis)
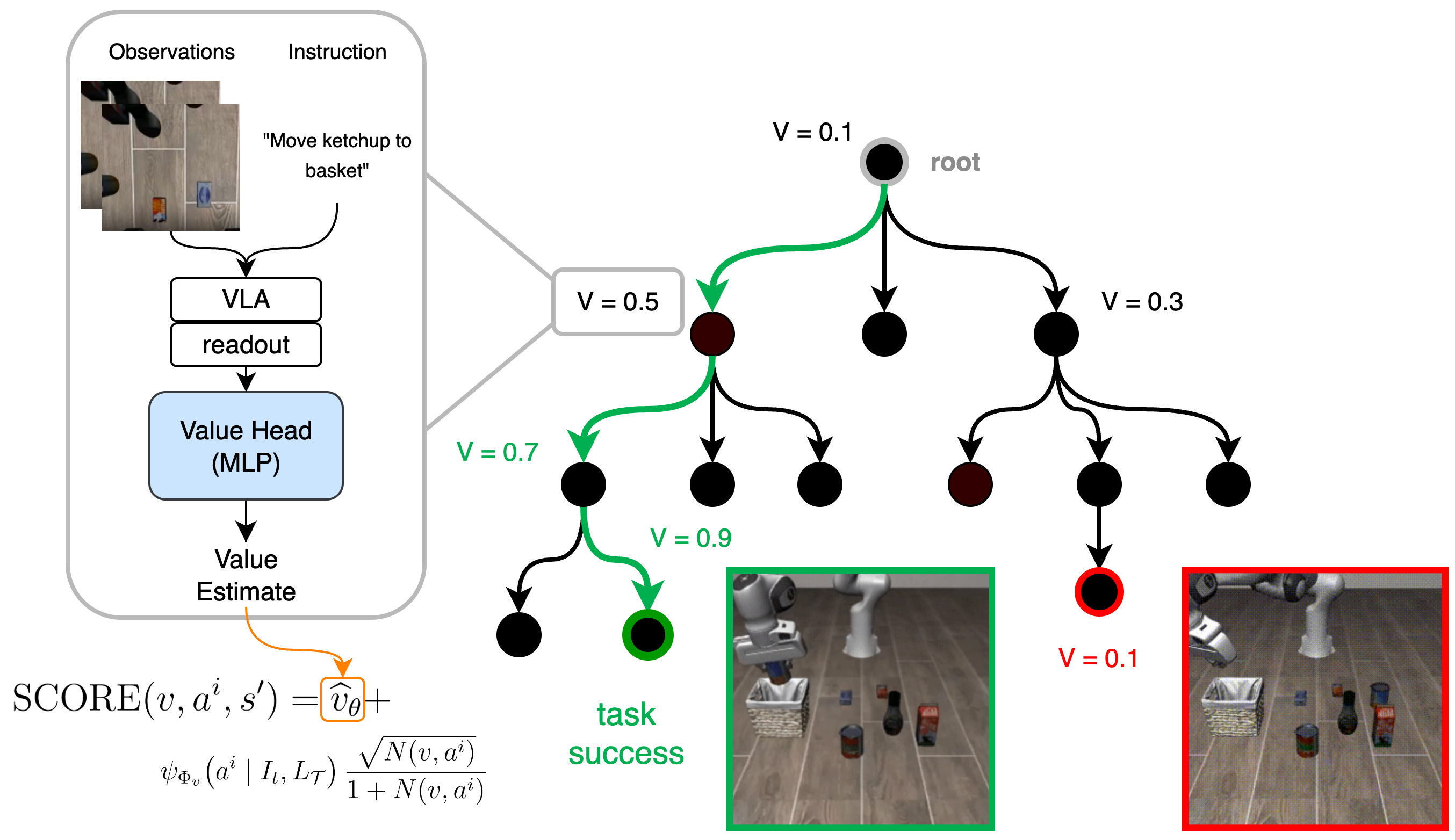
이 문제를 완화하기 위한 기존 접근법으로는 테스트 시점에 MCTS와 같은 탐색 알고리즘을 결합하는 방법이 있다. MCTS는 현재 상태에서 가능한 행동들을 시뮬레이션하고, 탐색 트리의 확장과 백업 과정을 통해 최적 행동을 추정한다. 그러나 기존 MCTS‑VLA 결합 방식은 탐색의 ‘정책’ 부분에만 VLA 사전을 사용하고, ‘가치’ 평가에 해당하는 기대 보상 추정값을 제공하지 않는다. 즉, 트리의 선택 기준이 ‘사전 확률 × 탐색 보너스’ 형태로만 구성되며, 사전이 부정확하면 탐색 보너스(예: UCB 탐색 항)가 충분히 큰 시뮬레이션 수를 요구한다. 이는 실시간 로봇 제어에서 계산 비용을 크게 증가시켜 실용성을 저해한다.
V‑VLAPS는 이러한 구조적 결함을 보완한다. 핵심 아이디어는 고정된 VLA 백본(Octo)의 잠재 표현을 입력으로 하는 가벼운 MLP 기반 가치 함수(value function)를 학습시켜, 각 상태‑행동 쌍에 대한 성공 가능성을 직접 예측하도록 하는 것이다. 이 가치 함수는 두 가지 중요한 역할을 수행한다. 첫째, MCTS의 선택 공식에 ‘가치’ 항을 추가함으로써, 사전 확률이 낮더라도 높은 성공 확률을 가진 행동이 탐색 초기에 우선 고려된다. 둘째, 가치 함수가 제공하는 명시적 성공 신호는 탐색 보너스에 대한 의존도를 감소시켜, 적은 수의 시뮬레이션으로도 충분히 좋은 정책을 도출할 수 있게 만든다.
실험은 LIBERO라는 대규모 로봇 조작 벤치마크에서 수행되었다. LIBERO는 다양한 작업(예: 물체 잡기, 스위치 누르기, 도구 사용 등)과 복잡한 환경 변이를 포함해 VLA 모델의 일반화 능력을 엄격히 평가한다. 결과는 두 가지 관점에서 의미가 있다. 첫째, V‑VLAPS는 평균 성공률을 5% 이상 끌어올렸다. 이는 로봇이 이전에 보지 못한 상황에서도 가치 함수가 제공하는 보조 정보 덕분에 더 안정적인 행동을 선택한다는 증거다. 둘째, MCTS 시뮬레이션 횟수를 5‑15% 절감했다는 점은 실시간 제어에 필요한 연산량을 현저히 낮추었다는 의미이며, 이는 실제 로봇 시스템에 적용 가능한 수준의 효율성을 보여준다.
또한, 가치 함수가 ‘경량’이라는 점도 주목할 만하다. 복잡한 딥 네트워크 대신 MLP를 사용함으로써 학습과 추론 비용을 최소화했으며, 이는 기존 VLA 백본을 그대로 재사용하면서도 추가적인 하드웨어 요구사항을 크게 늘리지 않는다. 향후 연구에서는 가치 함수의 구조를 더 깊게 탐색하거나, 강화학습 기반의 가치 추정과 결합해 더욱 정교한 보상 모델을 구축할 가능성도 열려 있다.
요약하면, V‑VLAPS는 VLA 모델의 사전 기반 한계를 가치 함수라는 명시적 보상 추정으로 보완함으로써, 탐색 효율성과 정책 성능을 동시에 향상시킨 혁신적인 프레임워크라 할 수 있다. 이는 로봇 조작 분야에서 ‘사전 + 탐색 + 가치’ 삼위일체 접근법이 앞으로 표준이 될 가능성을 시사한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리