LLM이 IoT 규칙 보안 분석을 뛰어넘을 수 있을까
📝 원문 정보
- Title: Cracking IoT Security: Can LLMs Outsmart Static Analysis Tools?
- ArXiv ID: 2601.00559
- 발행일: 2026-01-02
- 저자: Jason Quantrill, Noura Khajehnouri, Zihan Guo, Manar H. Alalfi
📝 초록 (Abstract)
스마트 홈 IoT 플랫폼인 openHAB은 트리거‑액션‑조건(TAC) 규칙을 이용해 장치 동작을 자동화하지만, 이러한 규칙들 간의 상호 작용은 암묵적인 의존성, 충돌하는 트리거 또는 겹치는 조건으로 인해 의도되지 않거나 위험한 동작, 즉 인터랙션 위협을 초래할 수 있다. 이러한 위협을 식별하려면 의미적 이해와 구조적 추론이 필요하며, 전통적으로는 심볼릭하고 제약 기반의 정적 분석에 의존한다. 본 연구는 다중 카테고리 인터랙션 위협 분류 체계에 걸쳐 대형 언어 모델(LLM)의 성능을 최초로 종합 평가한다. 원본 openHAB(oHC/IoTB) 데이터셋과 규칙 변형에 대한 강인성을 시험하기 위해 설계된 구조적으로 어려운 Mutation 데이터셋을 사용한다. Llama 3.1 8B, Llama 70B, GPT‑4o, Gemini‑2.5‑Pro, DeepSeek‑R1을 제로‑샷, 원‑샷, 투‑샷 설정으로 벤치마크하고, oHIT의 수동 검증된 정답과 비교한다. 결과는 LLM이 의미적 이해, 특히 액션 및 조건 관련 위협에서는 유망한 성능을 보이지만, 규칙 간 구조적 추론이 필요한 위협에서는 정확도가 크게 떨어지며, 변형된 규칙 형태에서는 더욱 악화된다는 점을 보여준다. 모델별 위협 카테고리와 프롬프트 설정에 따라 성능 편차가 크며, 일관된 신뢰성을 제공하는 모델은 없었다. 반면, 심볼릭 추론 기반 베이스라인은 두 데이터셋 모두에서 구조적 교란에 영향을 받지 않고 안정적인 탐지를 유지한다.💡 논문 핵심 해설 (Deep Analysis)
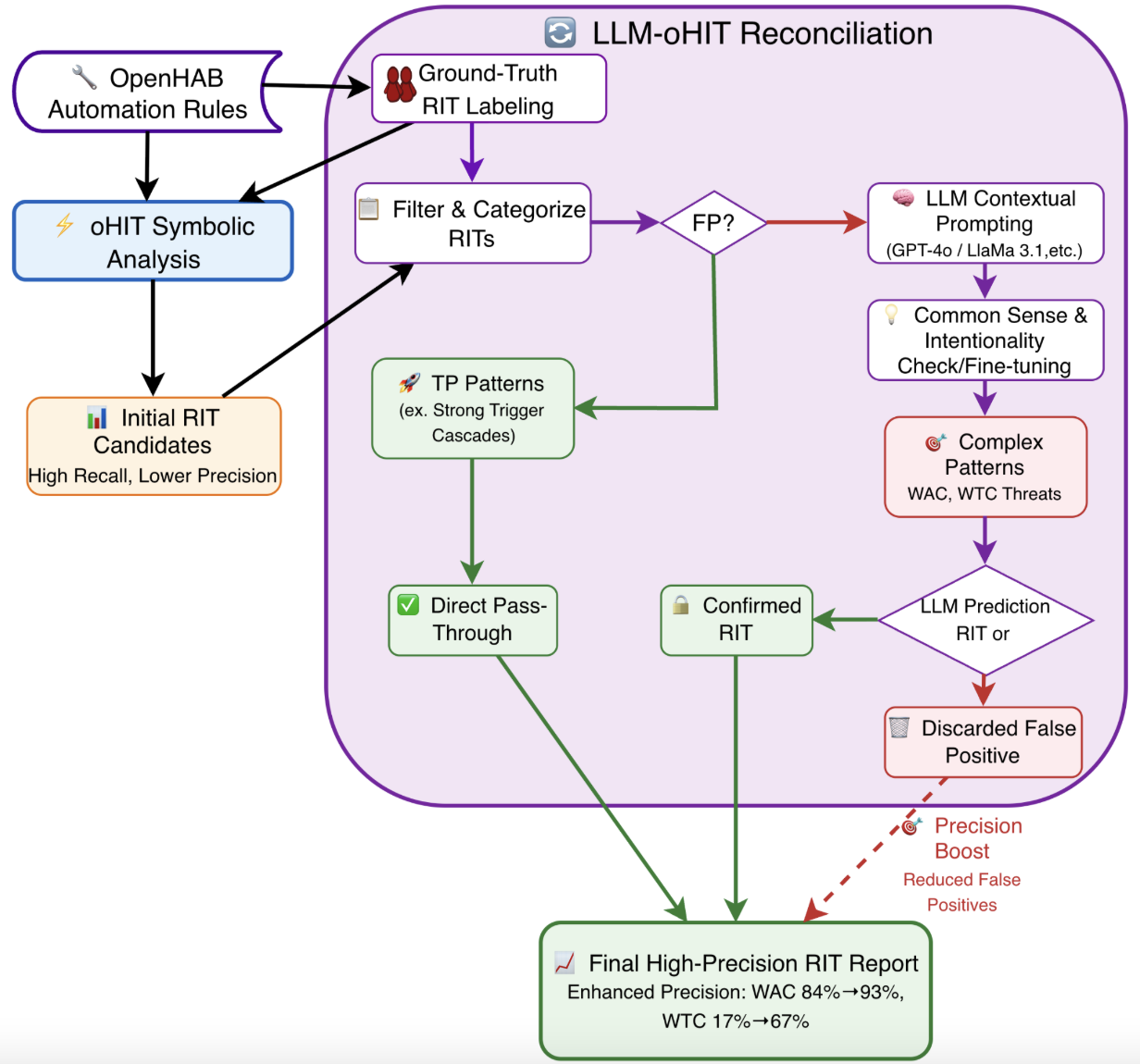
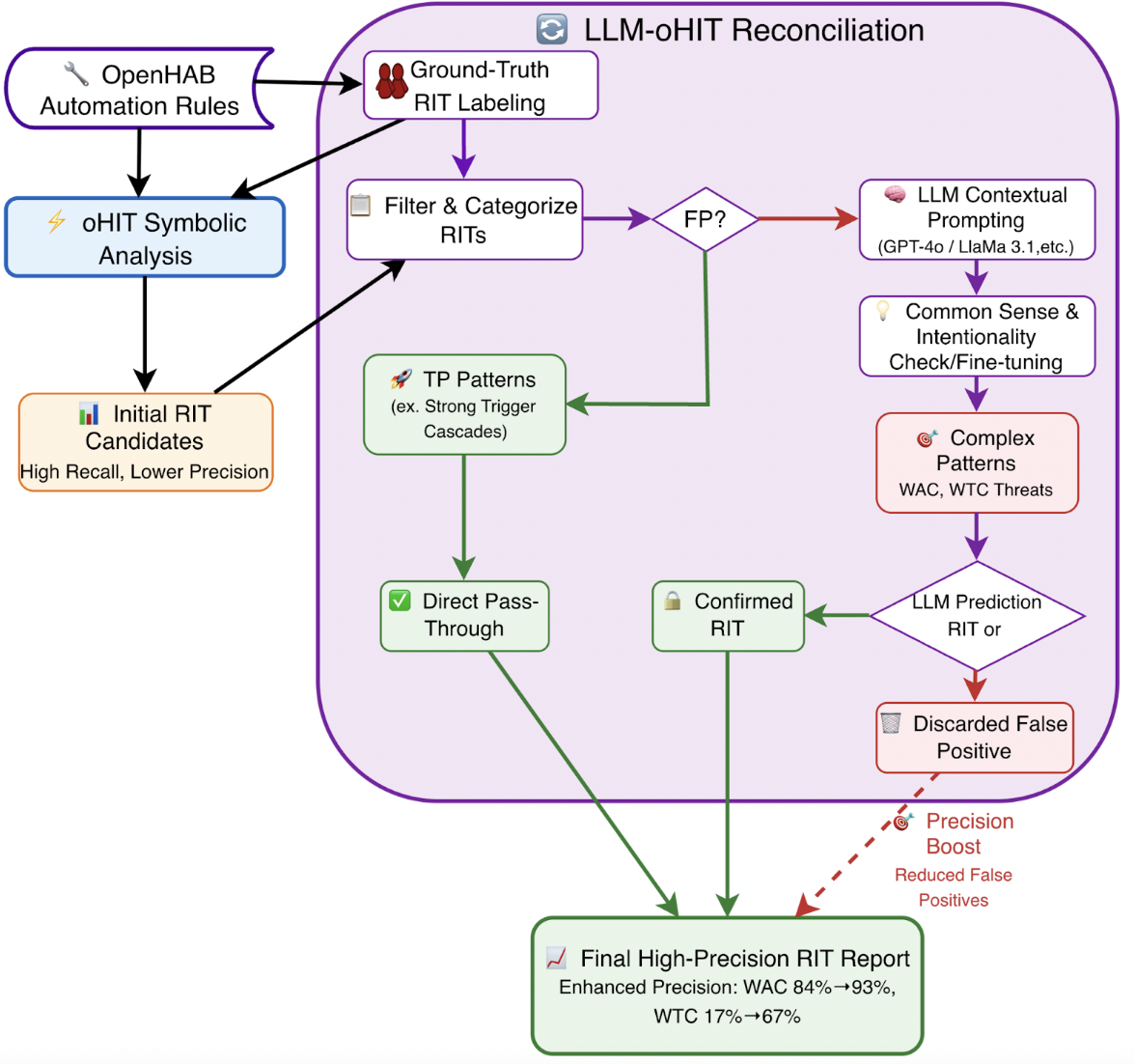
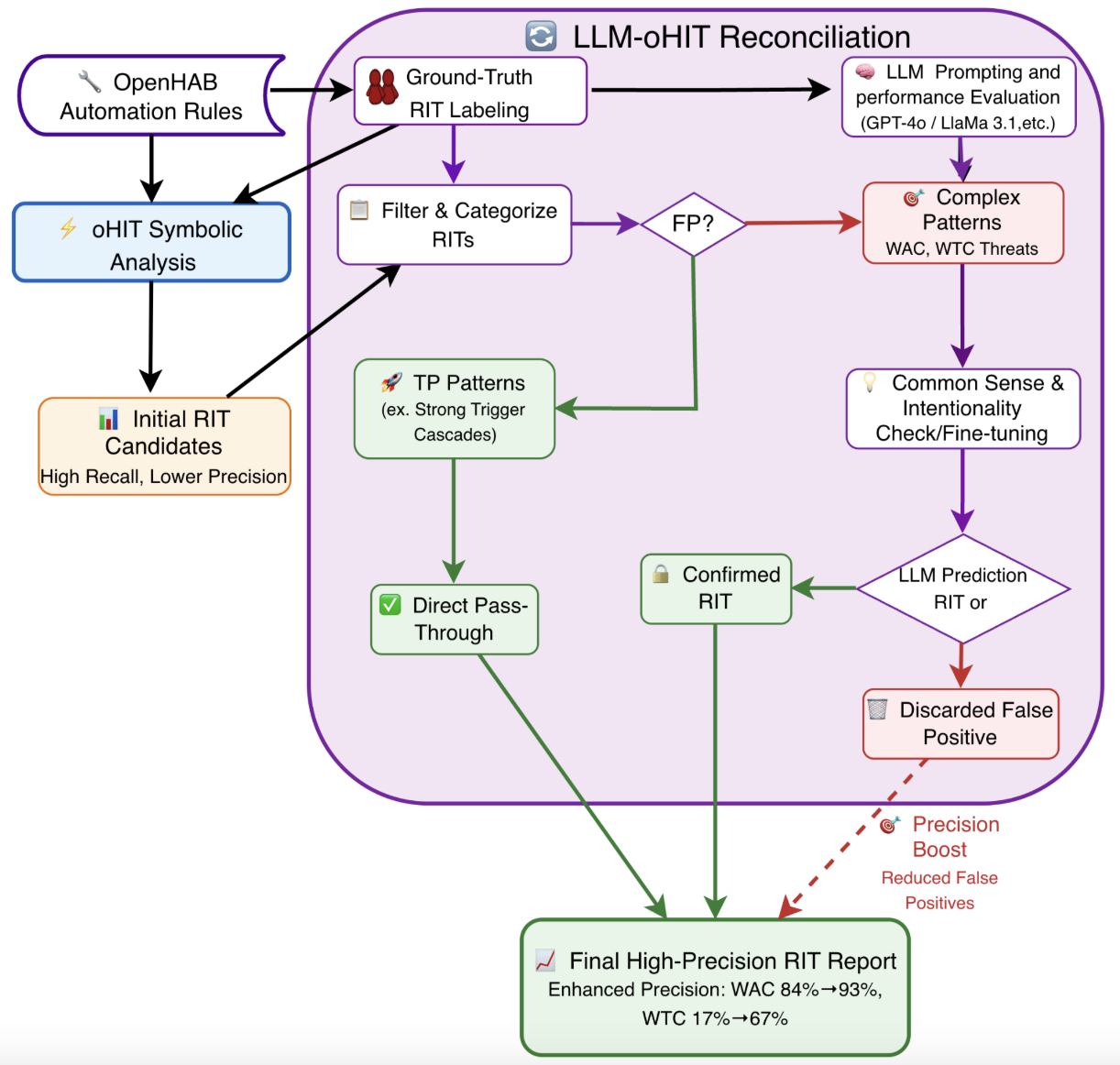
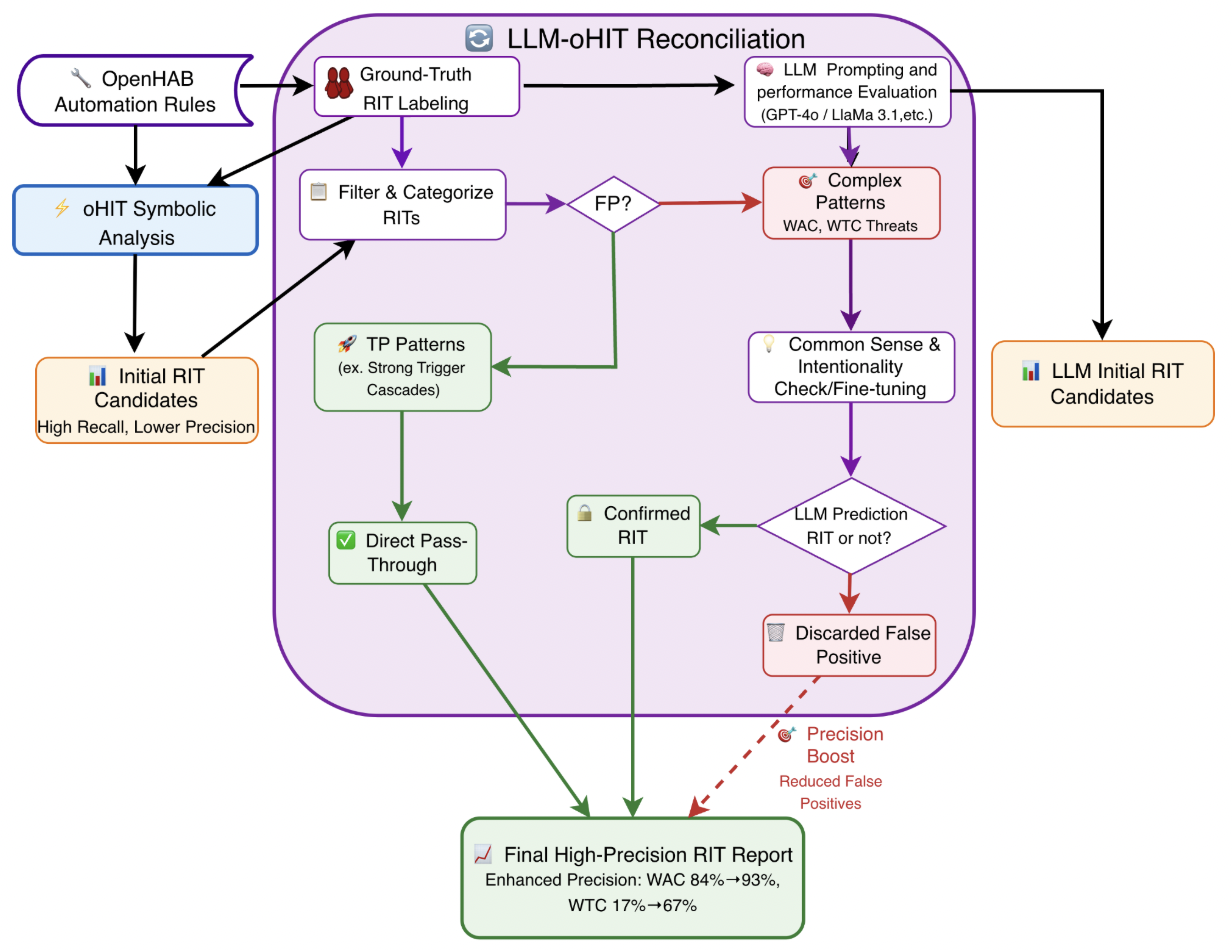
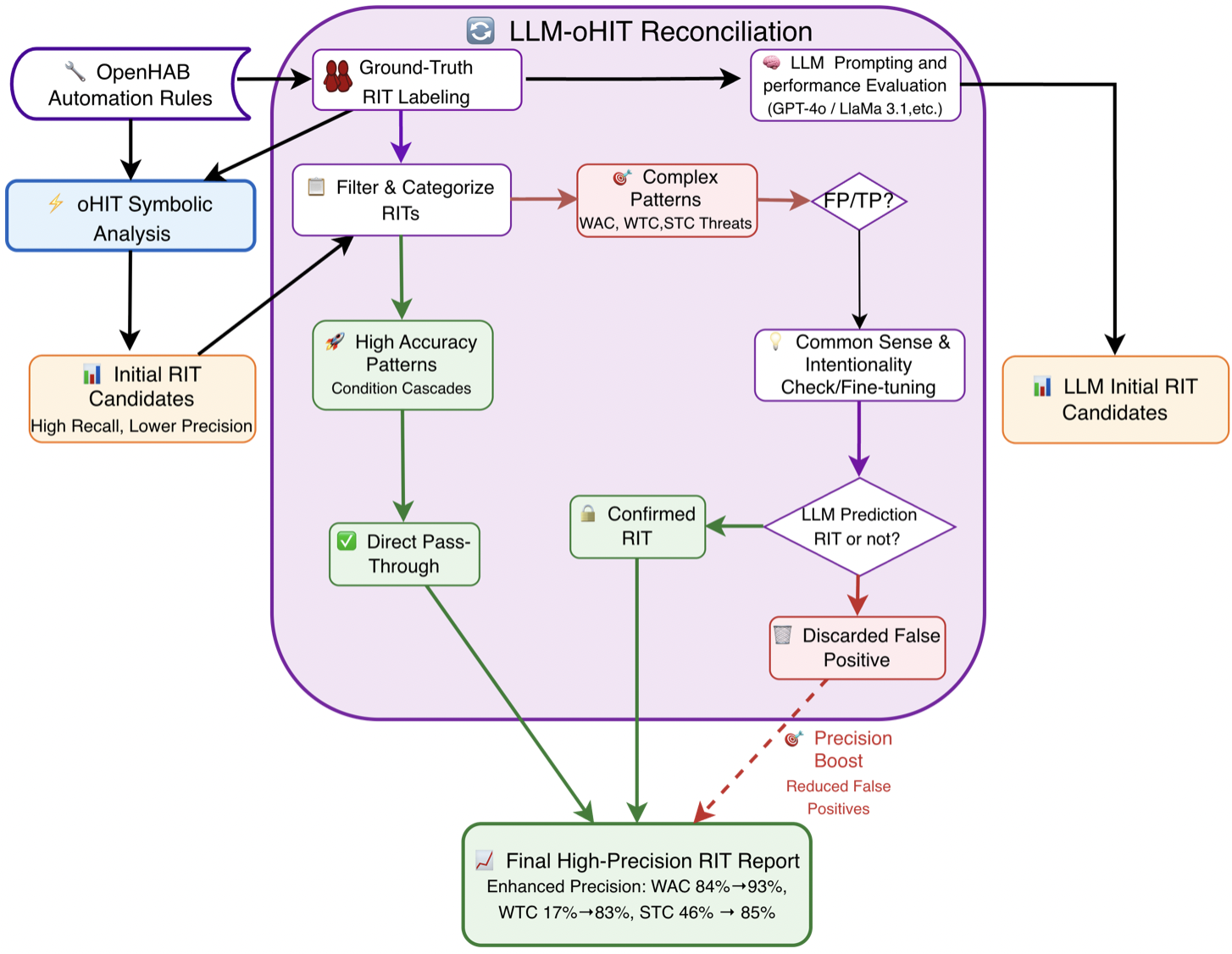
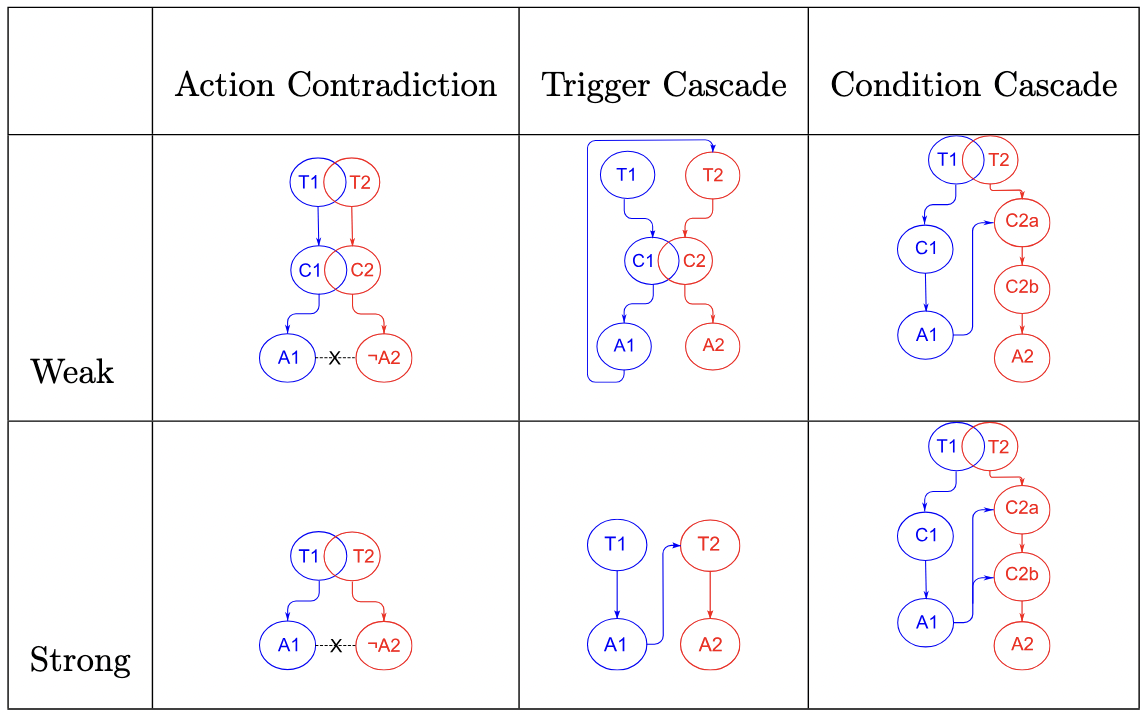
연구진은 두 종류의 데이터셋을 구축했다. 첫 번째는 기존 oHC/IoTB 데이터셋으로, 실제 openHAB 사용자들이 만든 규칙과 그에 대한 인간 전문가의 라벨링이 포함돼 있다. 두 번째는 ‘Mutation’ 데이터셋으로, 규칙을 동등하게 변형(예: 순서 바꾸기, 변수명 변경, 논리 연산자 교체)하여 구조적 형태만 바뀐 상황에서도 모델이 일관된 판단을 내릴 수 있는지를 평가한다. 이렇게 함으로써 LLM이 표면적인 텍스트 패턴에 의존하는지, 진정한 의미와 구조를 파악하는지를 가려낼 수 있다.
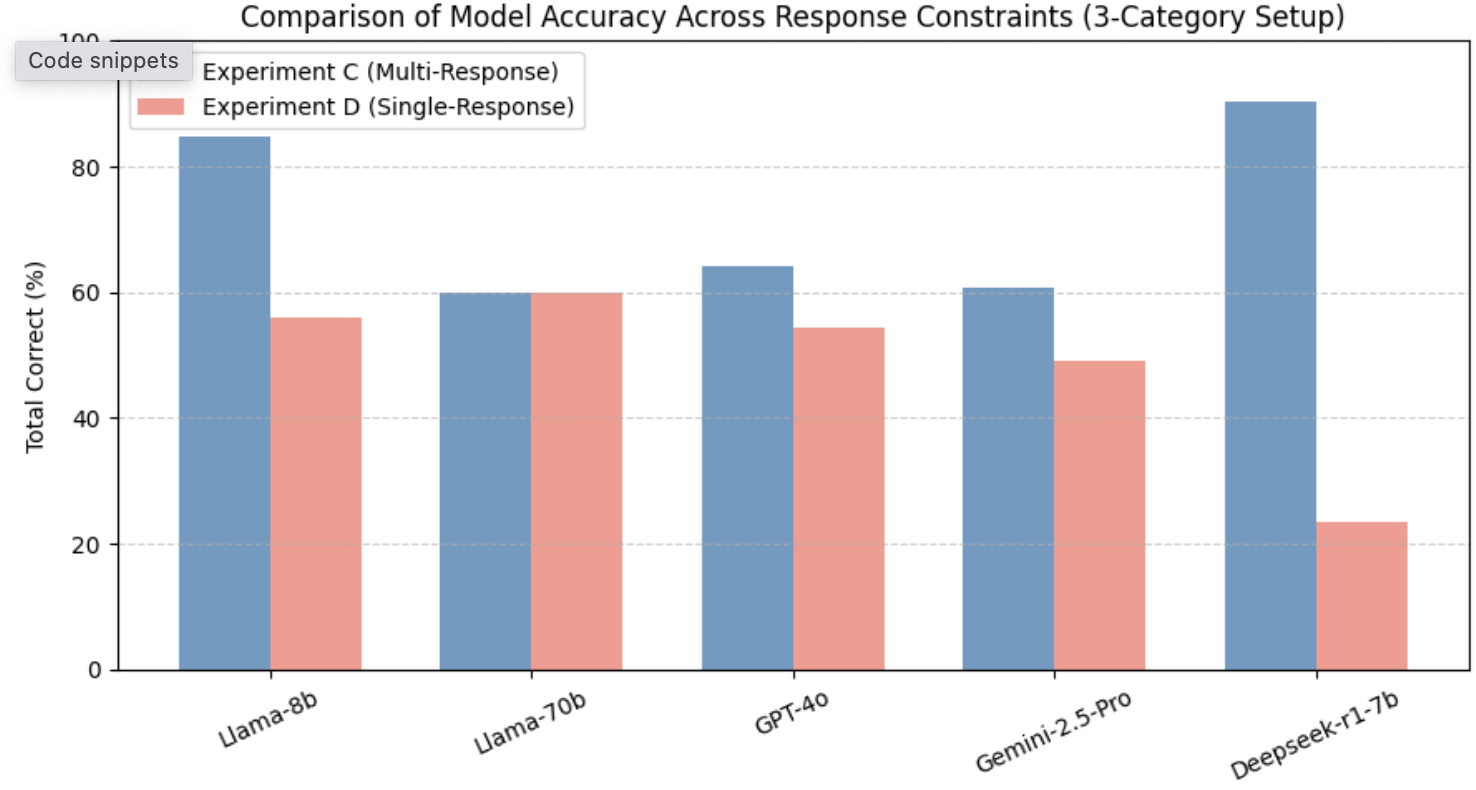
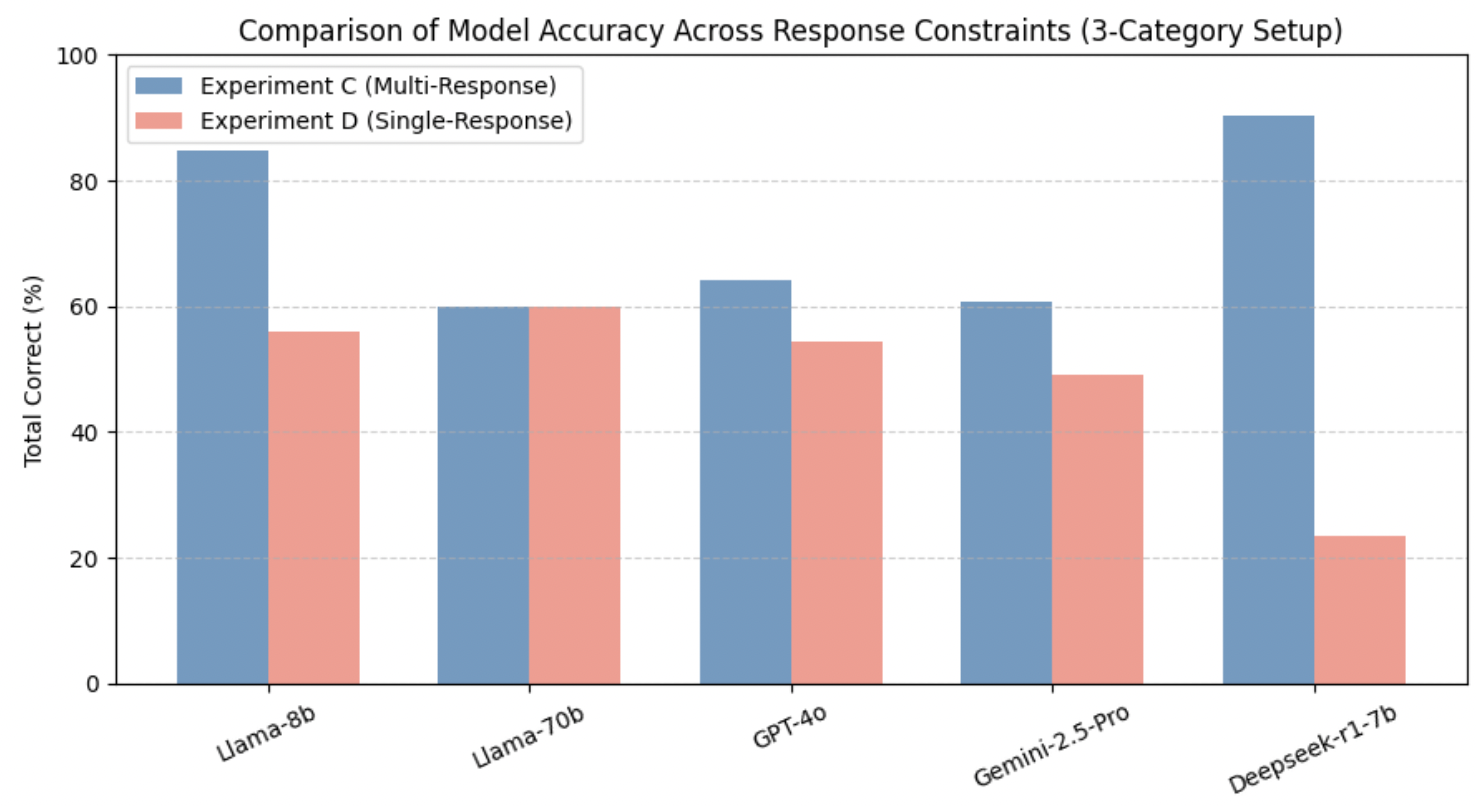
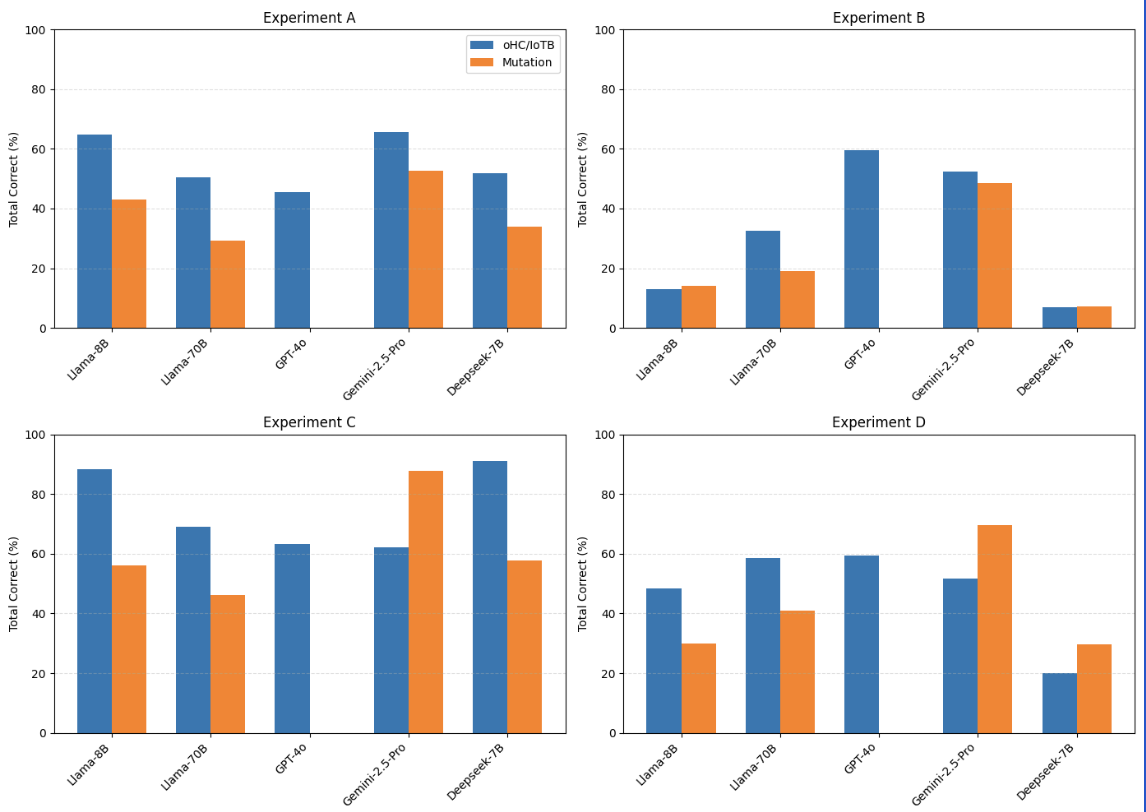
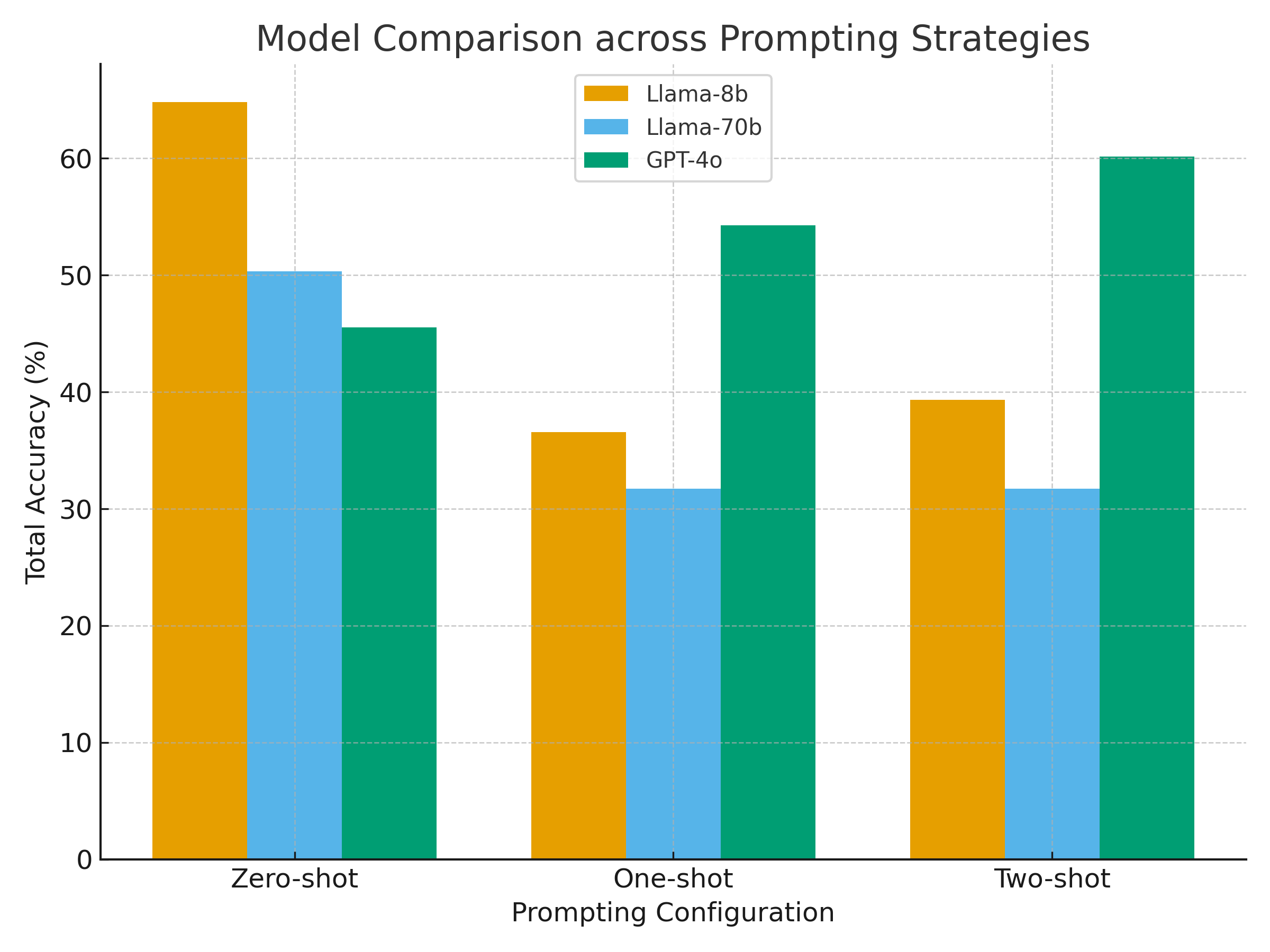
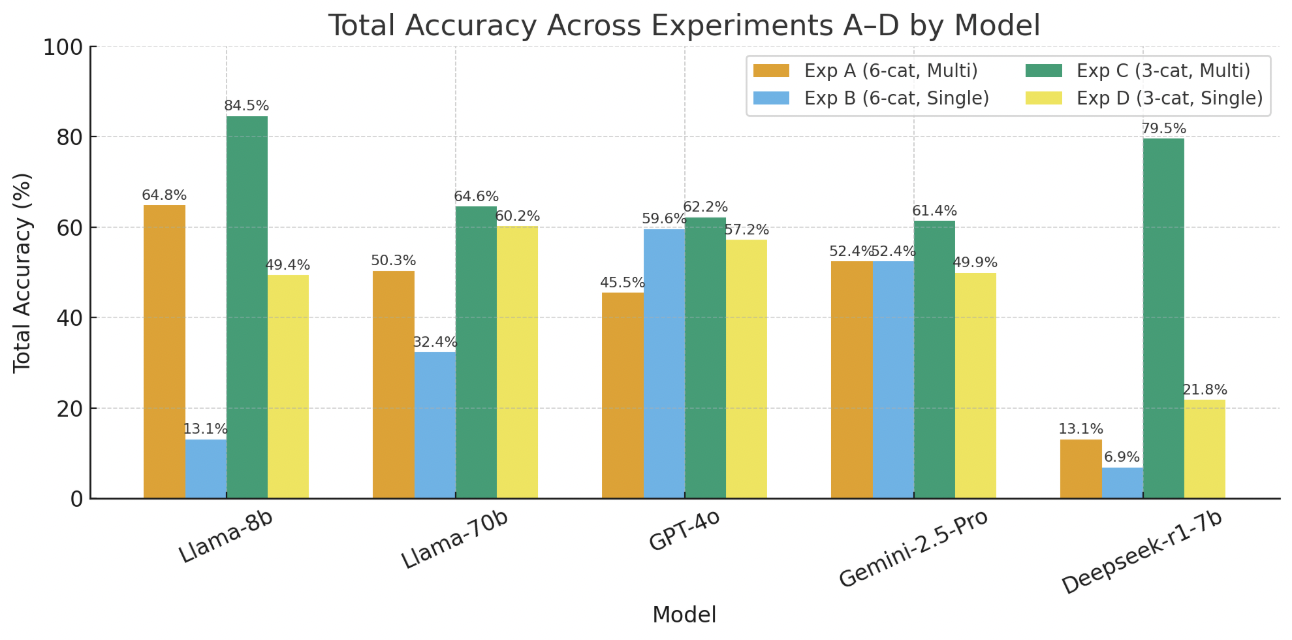
벤치마크에는 Llama 3.1 8B, Llama 70B, GPT‑4o, Gemini‑2.5‑Pro, DeepSeek‑R1 등 최신 상용·오픈소스 모델을 포함했으며, 제로‑샷(프롬프트 없이), 원‑샷(예시 1개), 투‑샷(예시 2개) 설정을 적용했다. 평가 지표는 정확도, 정밀도, 재현율, F1 점수이며, oHIT이 제공한 인간 검증 라벨을 ‘ground truth’로 삼았다.
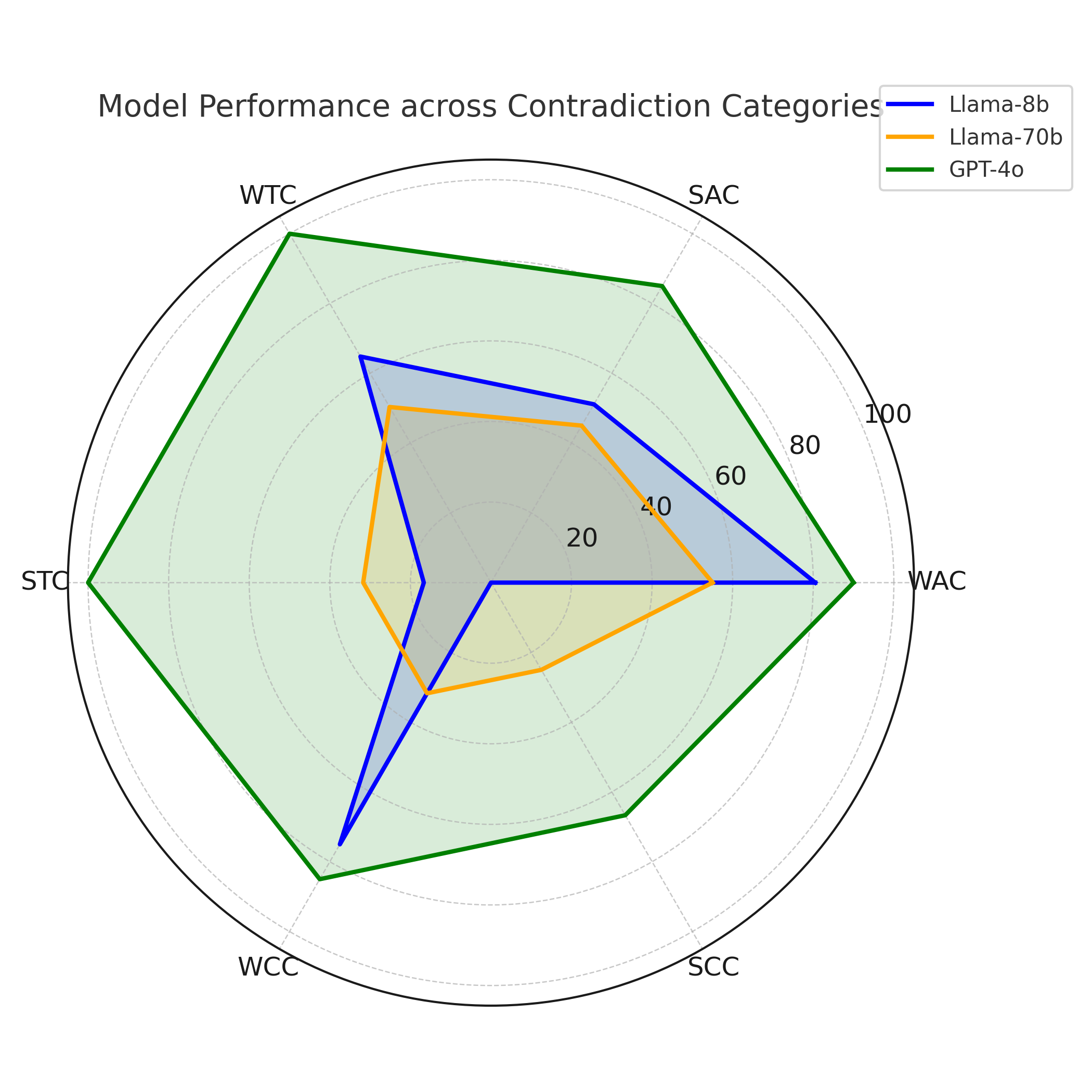
결과는 몇 가지 중요한 인사이트를 제공한다. 첫째, 모든 모델이 ‘액션‑조건’ 카테고리(예: 불필요한 장치 활성화, 조건 누락)에서는 비교적 높은 정확도를 기록했다. 이는 LLM이 규칙 내 개별 명령과 조건을 자연어 수준에서 이해하는 데 강점을 보인다는 의미다. 둘째, ‘규칙‑간 구조적 의존성’(예: 트리거 충돌, 순환 의존성)에서는 성능이 급격히 저하되었다. 특히 변형된 Mutation 데이터셋에서는 정확도가 30% 이상 떨어지는 경우가 많았다. 이는 모델이 규칙의 형식적 구조—예를 들어 논리 연산자의 결합 방식이나 변수 스코프—를 충분히 파악하지 못하고, 표면적인 텍스트 패턴에 과도하게 의존한다는 점을 시사한다.
또한 프롬프트 설정에 따른 변동도 눈에 띈다. 원‑샷과 투‑샷이 제로‑샷보다 전반적으로 향상된 결과를 보였지만, 향상 폭은 모델마다 크게 달랐다. GPT‑4o와 Gemini‑2.5‑Pro는 예시 제공 시 평균 8%p 정도 정확도가 상승했지만, Llama 8B는 거의 변화를 보이지 않았다. 이는 모델 규모와 사전 학습 데이터의 다양성이 프롬프트 민감도에 영향을 미친다는 점을 뒷받침한다.
대조군인 심볼릭 정적 분석 도구는 두 데이터셋 모두에서 일관된 성능을 유지했다. 규칙 변형이 있더라도 제약식 변환 단계에서 구조적 정보를 보존하기 때문에, 탐지율이 크게 변동하지 않았다. 이는 현재 LLM이 정적 분석을 완전히 대체하기엔 아직 한계가 있음을 강조한다.
논문의 의의는 LLM이 보안 분야, 특히 IoT 규칙 검증에 적용될 가능성을 실증적으로 조명했다는 점이다. 그러나 결과는 “LLM이 의미적 이해는 가능하지만, 구조적 추론과 변형 강인성에서는 아직 부족하다”는 결론을 낳는다. 향후 연구는 (1) LLM에 구조적 정보를 명시적으로 주입하는 프롬프트 설계, (2) 하이브리드 시스템—LLM의 의미 이해와 심볼릭 엔진의 구조 분석을 결합—을 탐색함으로써 두 접근법의 장점을 통합하는 방향이 유망하다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리