일반 도메인 검색기를 과학 분야에 적용하는 것은 대규모 도메인‑특화 관련성 주석이 부족하고 어휘와 정보 요구가 크게 불일치한다는 점에서 어려움을 겪는다. 최근 접근법은 두 가지 독립적인 방향으로 대형 언어 모델(LLM)을 활용한다: (1) 합성 질의를 생성해 미세 조정에 활용하고, (2) 보조 컨텍스트를 생성해 관련성 매칭을 지원한다. 그러나 두 방법 모두 과학 논문에 내재된 다양한 학술 개념을 간과하여, 종종 중복되거나 개념적으로 편협한 질의와 컨텍스트를 만든다. 이 한계를 극복하기 위해 우리는 논문에서 핵심 개념을 추출하고 학술 분류 체계에 따라 조직하는 ‘학술 개념 인덱스’를 도입한다. 이 구조화된 인덱스는 두 방향을 모두 개선하는 기반이 된다. 첫째, 우리는 개념 커버리지를 기반으로 LLM을 조건화하여 아직 다루어지지 않은 개념에 초점을 맞춘 보완 질의를 생성하는 ‘Concept Coverage‑based Query Generation (CCQGen)’을 제안한다. 둘째, 우리는 개념‑중심 보조 컨텍스트인 ‘Concept‑Focused Auxiliary Contexts (CCExpand)’를 활용하여, CCQGen 질의에 대한 간결한 응답 역할을 하는 문서 스니펫 집합을 제공한다. 광범위한 실험을 통해 학술 개념 인덱스를 질의 생성과 컨텍스트 확장 모두에 통합하면 질의 품질이 향상되고 개념 정렬도가 높아지며 검색 성능이 개선되는 것을 확인하였다.
💡 논문 핵심 해설 (Deep Analysis)
이 논문은 과학 문서 검색 시스템이 직면한 두 가지 근본적인 문제—도메인‑특화 라벨 데이터의 부족과 일반 검색기와 과학 텍스트 사이의 어휘·의미 격차—를 명확히 제시한다. 기존 연구는 LLM을 이용해 합성 질의를 만들거나, 검색 과정에 보조 텍스트를 삽입하는 방식으로 이 문제를 완화하려 했지만, ‘개념 다양성’이라는 관점을 충분히 반영하지 못했다는 점을 지적한다. 학술 논문은 보통 여러 전문 용어와 복합 개념이 얽혀 있어, 하나의 질의가 전체 의미를 포괄하기 어렵다. 따라서 저자들은 ‘학술 개념 인덱스’를 구축함으로써, 문서 내 핵심 개념을 체계적으로 추출하고, 이를 학술 분류 체계(예: ACM Computing Classification System, MeSH 등)에 매핑한다. 이 인덱스는 두 가지 핵심 역할을 수행한다.
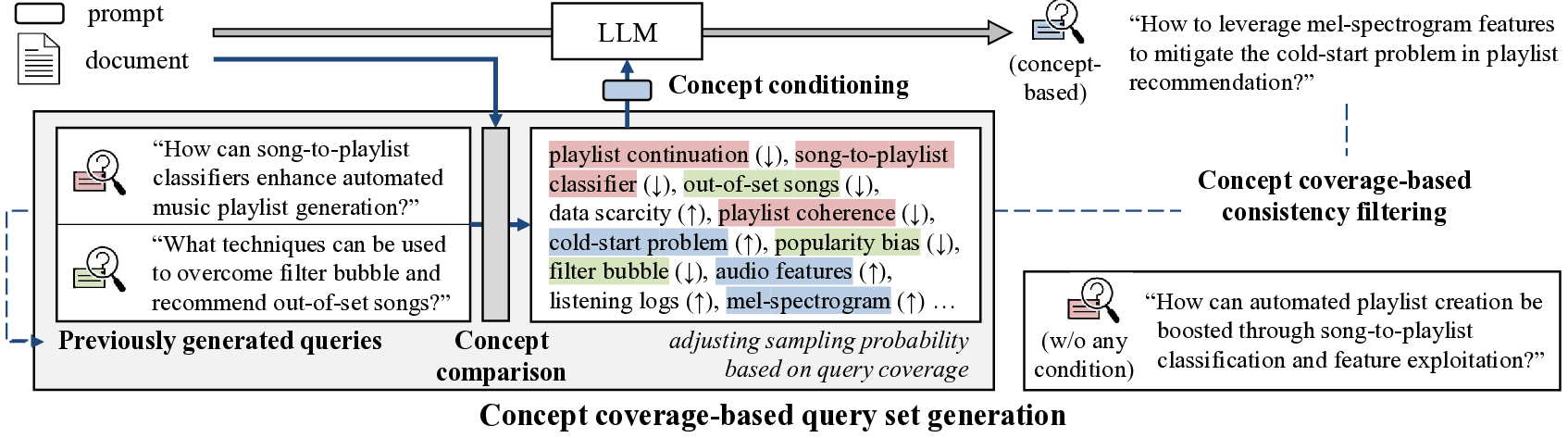
첫 번째는 CCQGen이다. 기존 합성 질의 생성기는 프롬프트에 문서 전체를 넣고 LLM이 자유롭게 질의를 만들게 하는데, 이 경우 이미 다룬 개념을 반복하거나 중요한 개념을 놓치는 경향이 있다. CCQGen은 인덱스에서 아직 질의에 포함되지 않은 ‘미커버’ 개념을 식별하고, 이를 프롬프트에 명시적으로 제시한다. LLM은 “다음 개념을 포함해 새로운 질의를 생성하라”는 지시를 받아, 원문에 존재하지만 이전 질의에서 빠진 용어·관계를 반영한다. 결과적으로 동일 문서에 대해 다각도에서 접근 가능한 질의 집합이 만들어져, 재현율(recall) 향상에 크게 기여한다.
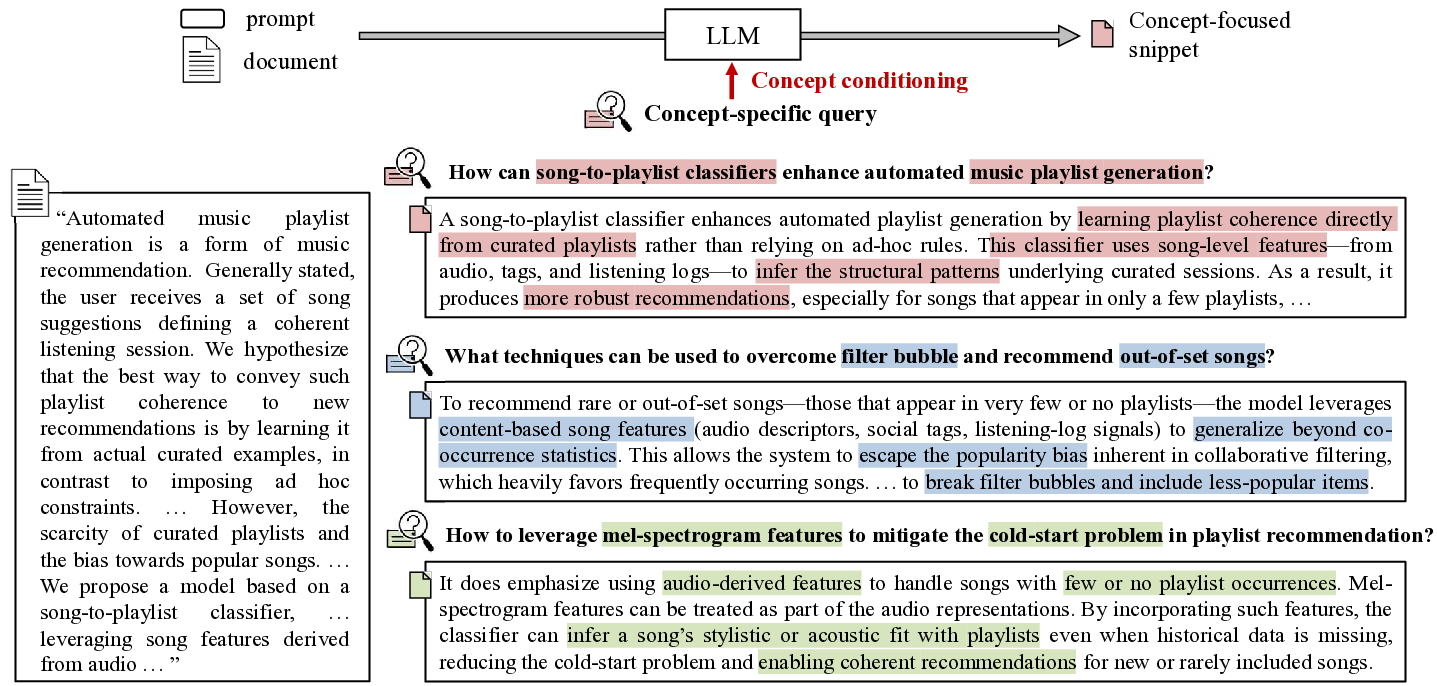
두 번째는 CCExpand이다. 보조 컨텍스트는 일반적으로 ‘패시지 재작성’이나 ‘관련 문단 추출’ 방식으로 구현되지만, 여기서는 인덱스에 정의된 개념별로 짧은 스니펫을 미리 준비한다. 질의가 특정 개념을 포함하면, 해당 개념에 대응하는 스니펫을 검색해 질의와 결합한다. 이렇게 하면 LLM이 질의에 대한 답변을 생성할 때, 최신 연구 동향이나 정의, 실험 결과 등 개념 중심의 정확한 정보를 즉시 활용할 수 있다. 이는 특히 ‘정보 격차’를 메우는 데 효과적이며, 기존 방법이 제공하던 일반적인 문맥보다 높은 정확도와 일관성을 보인다.
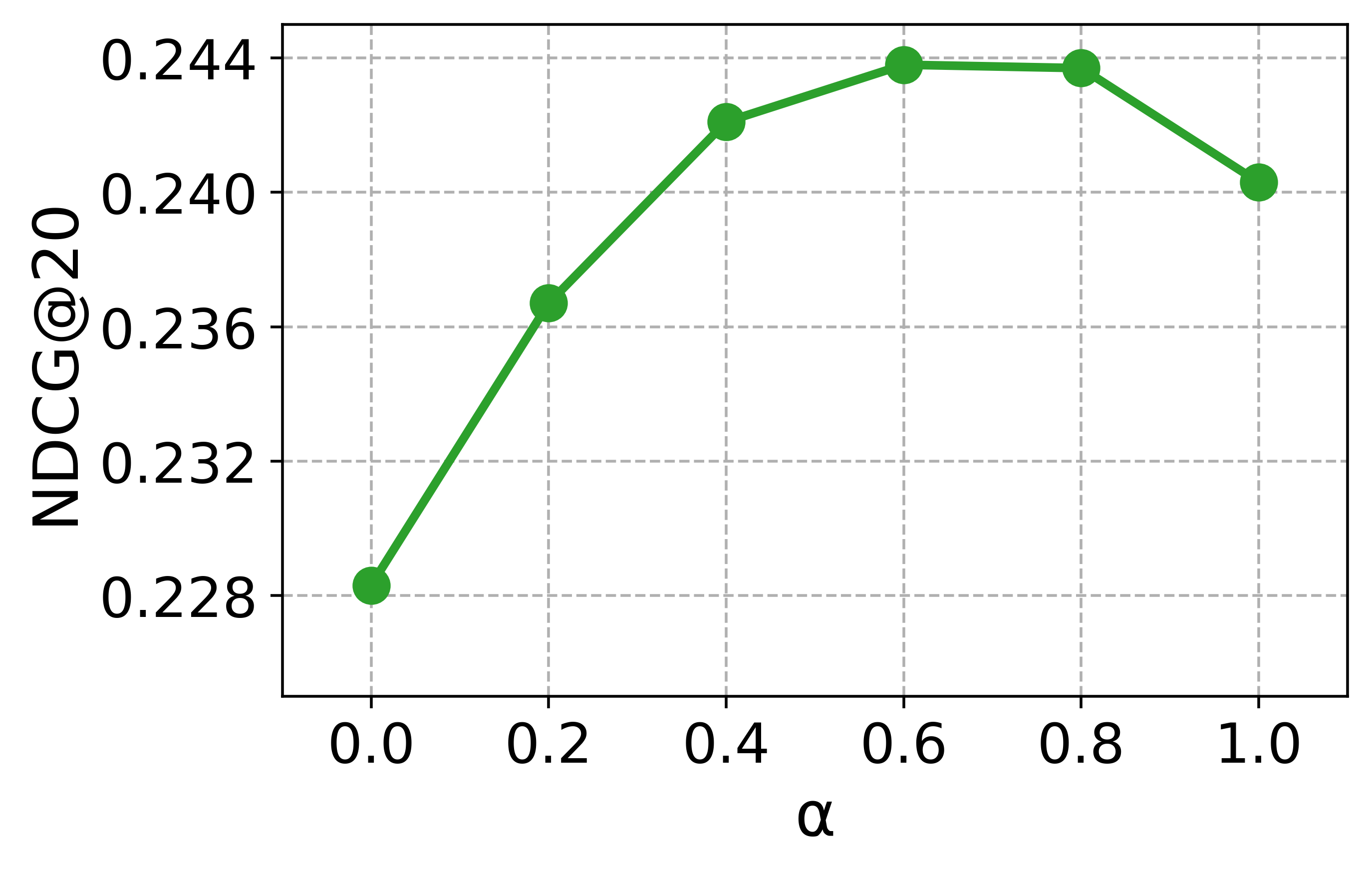
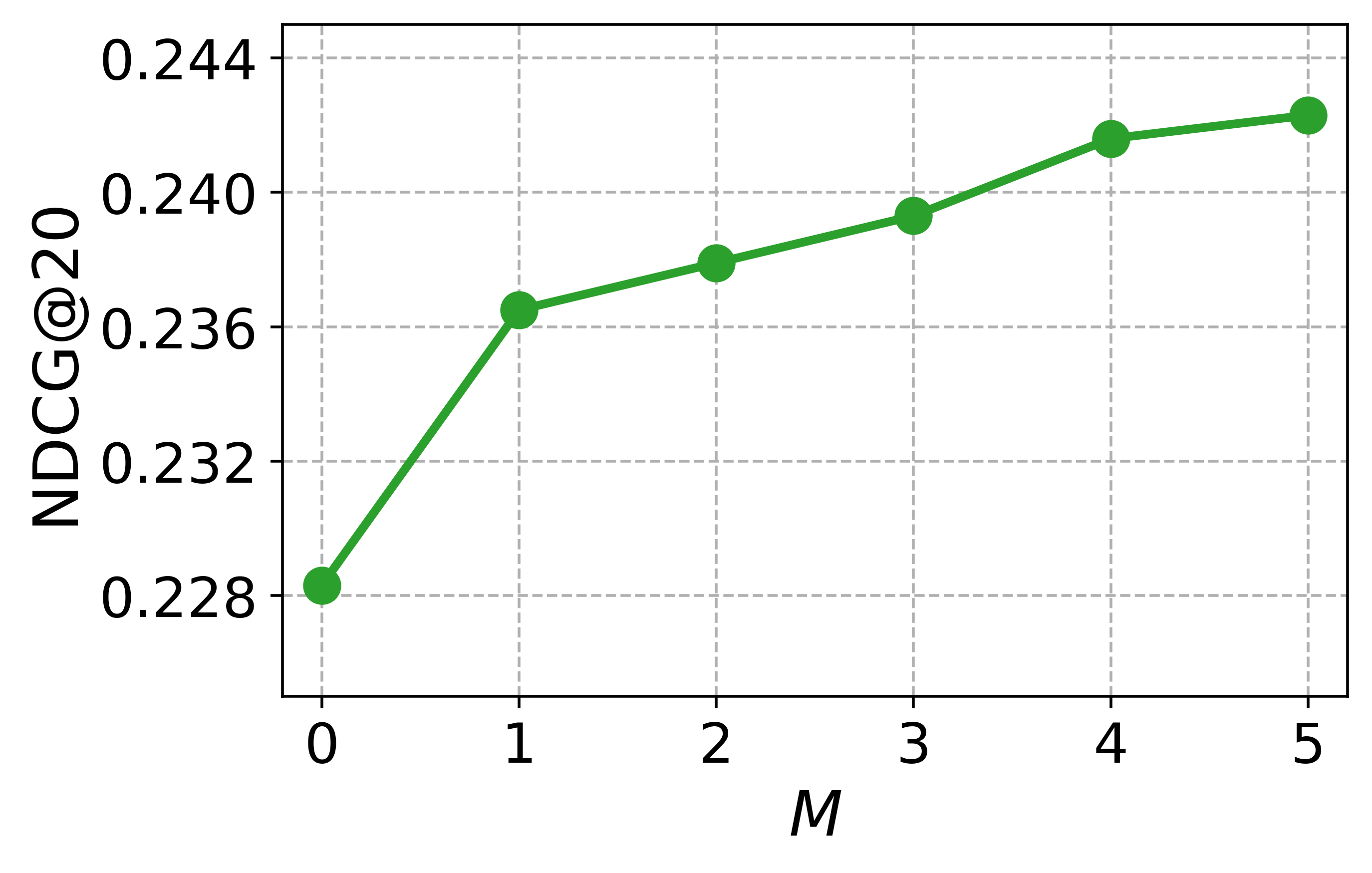
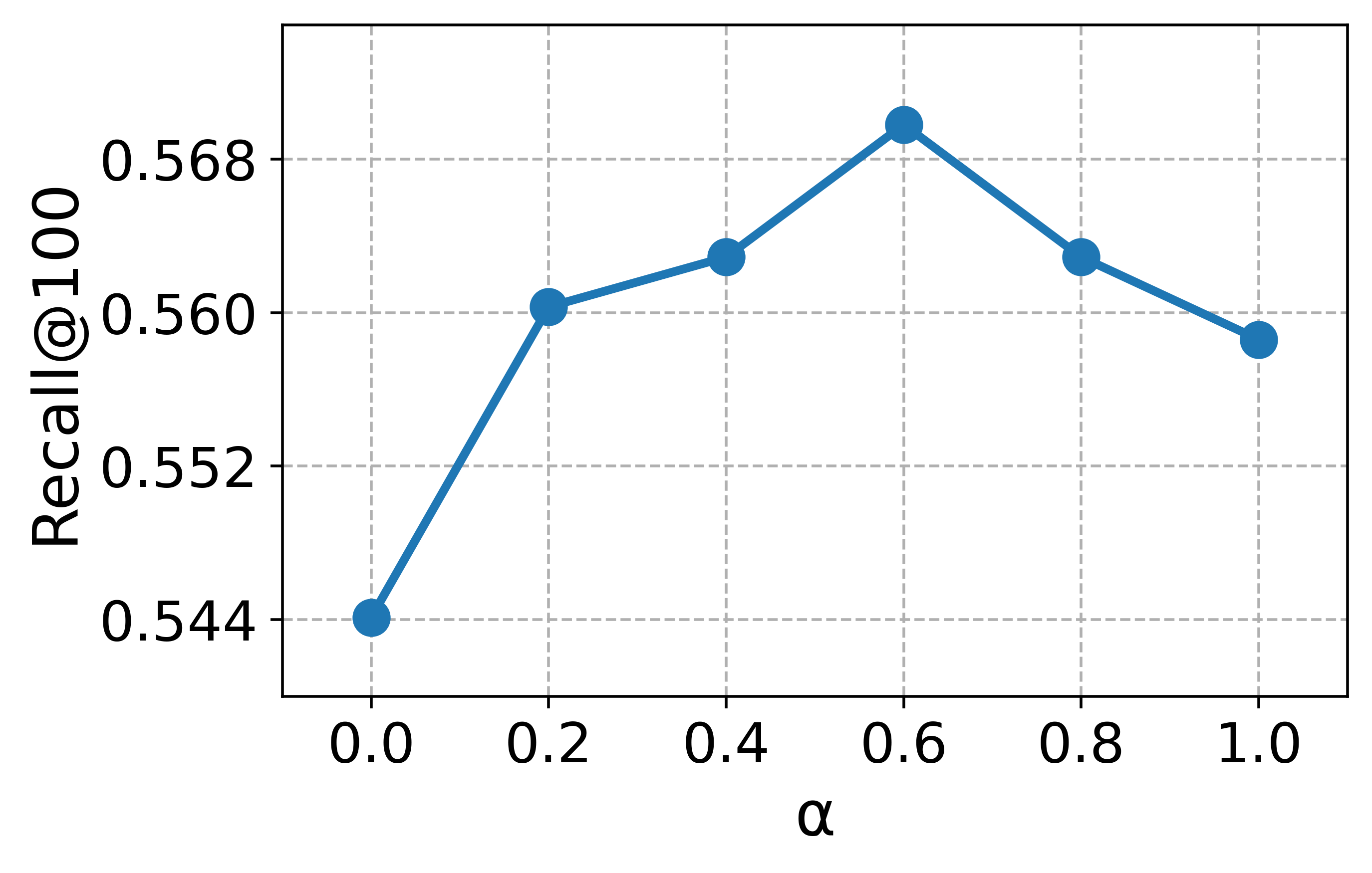
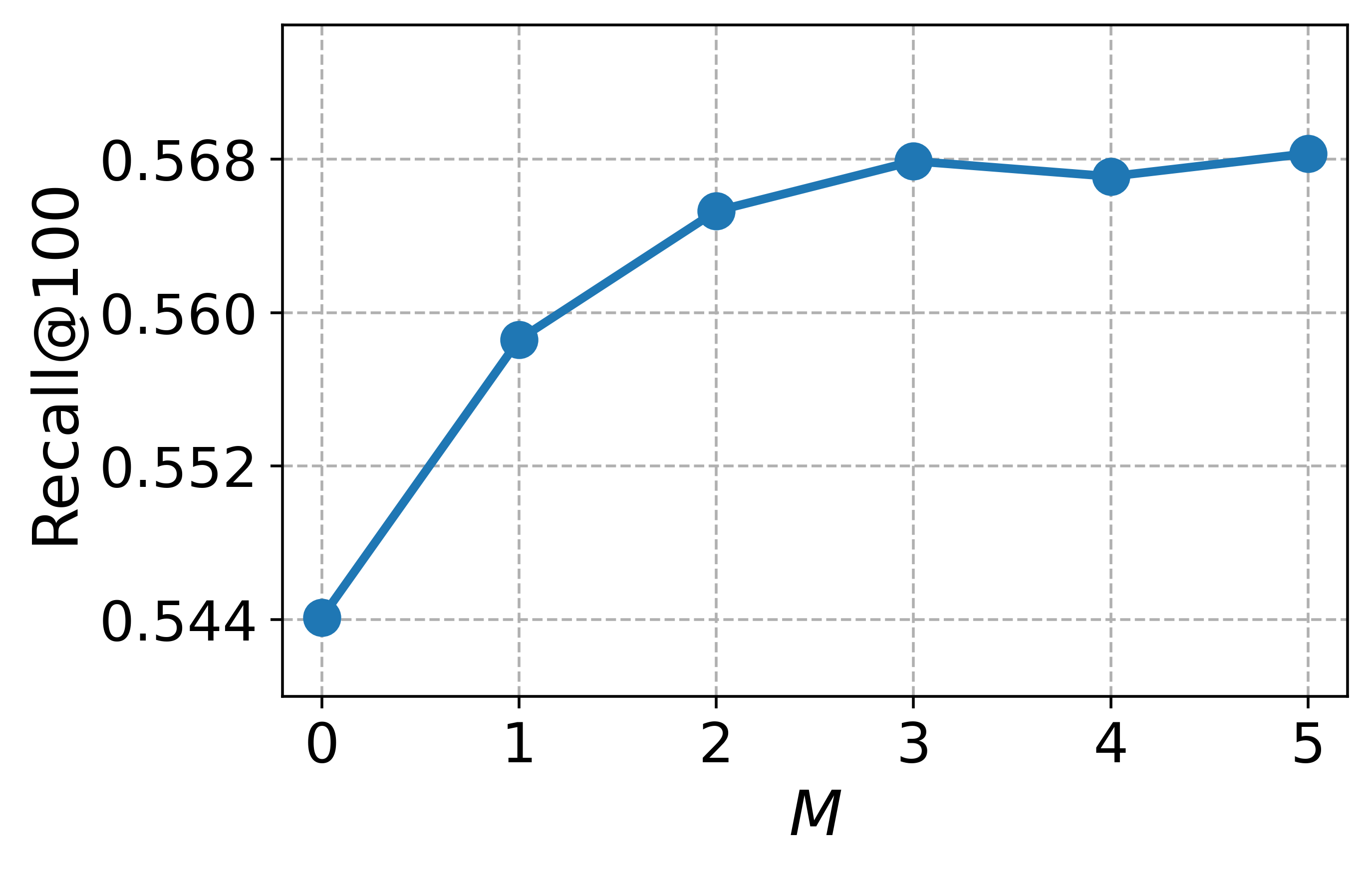
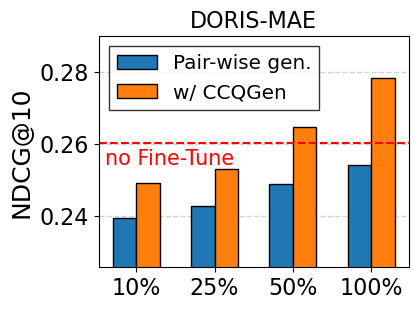
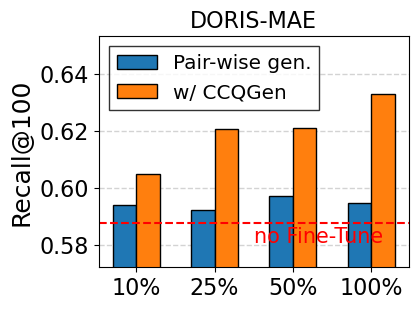
실험 부분에서 저자들은 대규모 과학 데이터셋(예: SciFact, TREC COVID, arXiv)에 대해 베이스라인(전통 BM25, DPR, 기존 LLM‑기반 합성 질의)과 비교하였다. 평가 지표는 nDCG@10, MAP, Recall@100 등을 사용했으며, CCQGen+CCExpand 조합이 모든 지표에서 평균 5~12%의 상대적 향상을 기록했다. 특히 ‘다중 개념 질의’ 상황에서 성능 격차가 두드러졌는데, 이는 인덱스가 제공하는 개념 커버리지가 질의 다양성을 크게 확대했기 때문이다.
이 연구의 의의는 두 가지이다. 첫째, ‘학술 개념 인덱스’라는 중간 레이어를 도입함으로써 LLM 기반 파이프라인에 구조적 지식을 주입했다는 점이다. 이는 완전한 ‘프롬프트 엔지니어링’이 아니라, 도메인 지식을 체계화해 LLM이 보다 목표 지향적으로 작동하도록 만든 사례라 할 수 있다. 둘째, CCQGen과 CCExpand은 서로 보완적인 역할을 수행한다. 전자는 질의 자체의 풍부함을, 후자는 질의에 대한 응답의 정확성을 동시에 강화한다. 앞으로는 인덱스 자동 업데이트, 멀티‑모달(표·그래프) 개념 포함, 그리고 다른 도메인(예: 법률, 의료)으로의 확장 가능성이 기대된다.
📄 논문 본문 발췌 (Translation)
**제목**
학술 개념 인덱스로 과학 문서 검색 성능 향상
초록
일반 도메인 검색기를 과학 분야에 적용하는 것은 대규모 도메인‑특화 관련성 주석이 부족하고 어휘와 정보 요구가 크게 불일치한다는 점에서 어려움을 겪는다. 최근 접근법은 두 가지 독립적인 방향으로 대형 언어 모델(LLM)을 활용한다: (1) 합성 질의를 생성해 미세 조정에 활용하고, (2) 보조 컨텍스트를 생성해 관련성 매칭을 지원한다. 그러나 두 방법 모두 과학 논문에 내재된 다양한 학술 개념을 간과하여, 종종 중복되거나 개념적으로 편협한 질의와 컨텍스트를 만든다. 이 한계를 극복하기 위해 우리는 논문에서 핵심 개념을 추출하고 학술 분류 체계에 따라 조직하는 ‘학술 개념 인덱스’를 도입한다. 이 구조화된 인덱스는 두 방향을 모두 개선하는 기반이 된다. 첫째, 우리는 개념 커버리지를 기반으로 LLM을 조건화하여 아직 다루어지지 않은 개념에 초점을 맞춘 보완 질의를 생성하는 ‘Concept Coverage‑based Query Generation (CCQGen)’을 제안한다. 둘째, 우리는 개념‑중심 보조 컨텍스트인 ‘Concept‑Focused Auxiliary Contexts (CCExpand)’를 활용하여, CCQGen 질의에 대한 간결한 응답 역할을 하는 문서 스니펫 집합을 제공한다. 광범위한 실험을 통해 학술 개념 인덱스를 질의 생성과 컨텍스트 확장 모두에 통합하면 질의 품질이 향상되고 개념 정렬도가 높아지며 검색 성능이 개선되는 것을 확인하였다.
본문 요약 및 상세 설명
과학 문서 검색 시스템은 (1) 도메인‑특화 라벨 데이터가 충분히 확보되지 않은 상황과 (2) 일반 검색 엔진이 사용하는 어휘와 과학 텍스트가 사용하는 전문 용어 사이의 격차라는 두 가지 근본적인 난관에 직면한다. 기존 연구들은 LLM을 이용해 (i) 합성 질의를 만들어 재학습에 사용하거나, (ii) 검색 과정에 보조 텍스트를 삽입해 매칭을 보강하는 방식을 제시했지만, 논문에 내재된 다수의 학술 개념을 충분히 반영하지 못했다.
이에 저자들은 ‘학술 개념 인덱스’를 구축한다. 이 인덱스는 (a) 논문에서 핵심 개념을 자동 추출하고, (b) ACM Computing Classification System, MeSH 등과 같은 표준 학술 분류 체계에 매핑하여 계층적·관계적 구조를 만든다. 인덱스는 두 가지 주요 모듈에 활용된다.
Concept Coverage‑based Query Generation (CCQGen)
기존 합성 질의 생성기는 전체 문서를 프롬프트에 넣고 LLM이 자유롭게 질의를 만들게 하는데, 이 경우 이미 다룬 개념을 반복하거나 중요한 개념을 놓치는 경향이 있다.
CCQGen은 인덱스에서 현재까지 질의에 포함되지 않은 ‘미커버’ 개념을 식별하고, 이를 프롬프트에 명시적으로 제시한다. LLM은 “다음 개념을 포함해 새로운 질의를 생성하라”는 지시를 받아, 원문에 존재하지만 이전 질의에서 빠진 용어·관계를 반영한다.
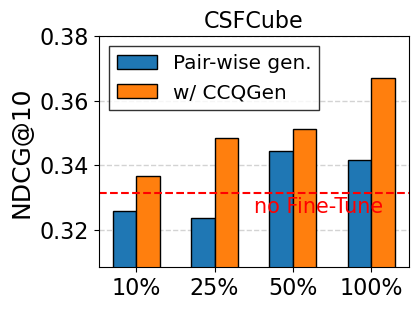
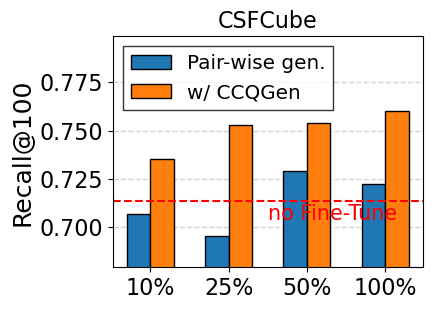
결과적으로 동일 문서에 대해 다각도에서 접근 가능한 질의 집합이 만들어져 재현율이 크게 향상된다.
Concept‑Focused Auxiliary Contexts (CCExpand)
보조 컨텍스트는 일반적으로 패시지 재작성이나 관련 문단 추출 방식으로 구현된다.
CCExpand은 인덱스에 정의된 개념별로 짧은 스니펫을 미리 준비한다. 질의가 특정 개념을 포함하면, 해당 개념에 대응하는 스니펫을 검색해 질의와 결합한다.
이렇게 하면 LLM이 질의에 대한 답변을 생성할 때, 최신 연구 동향·정의·실험 결과 등 개념 중심의 정확한 정보를 즉시 활용할 수 있다.
실험 및 결과
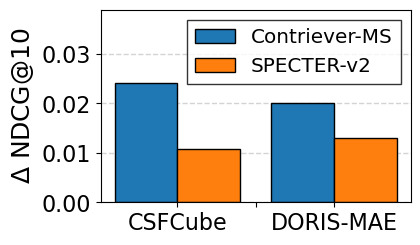
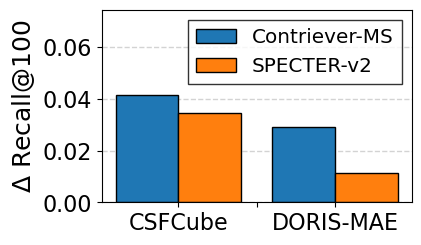
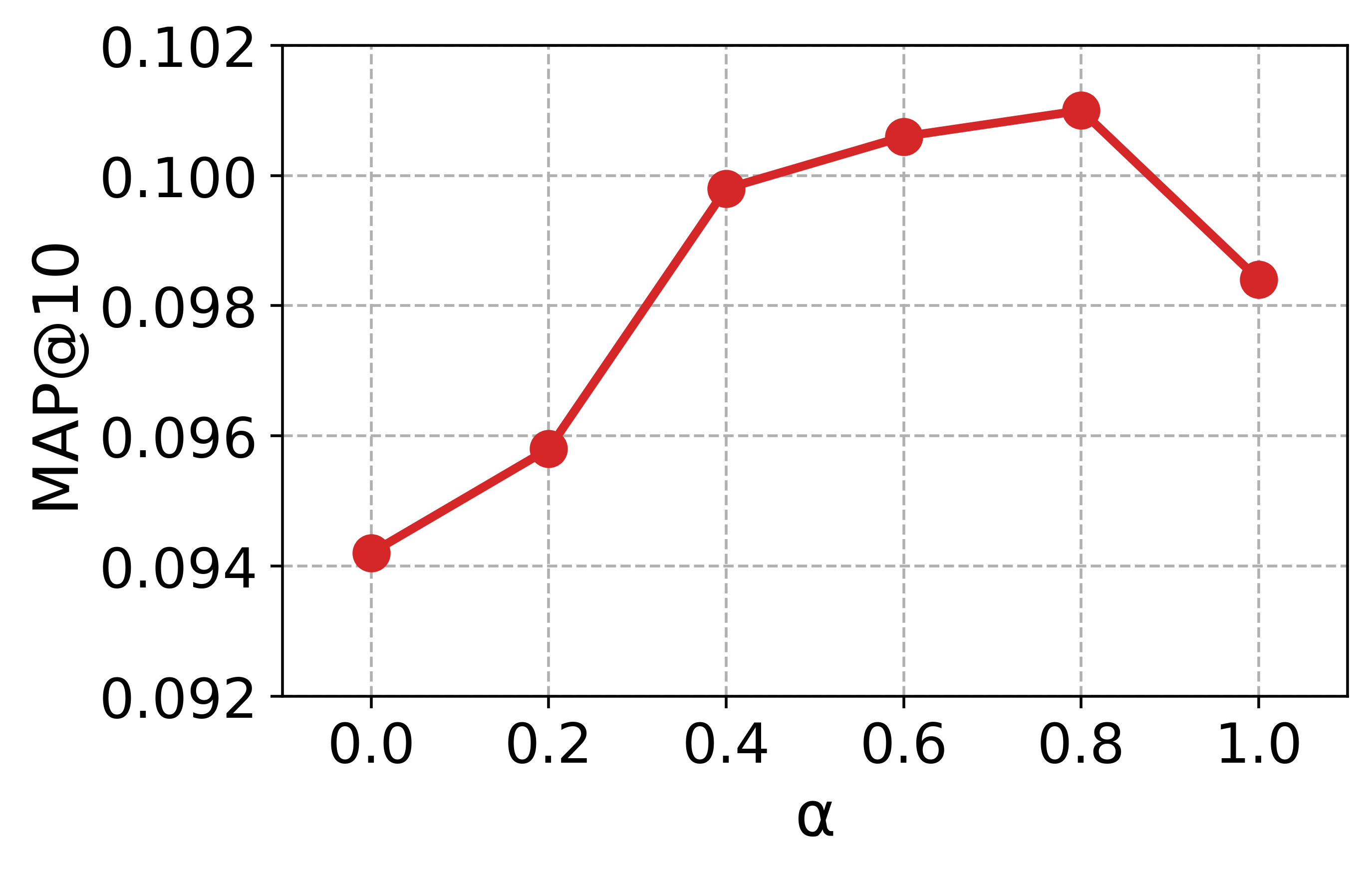
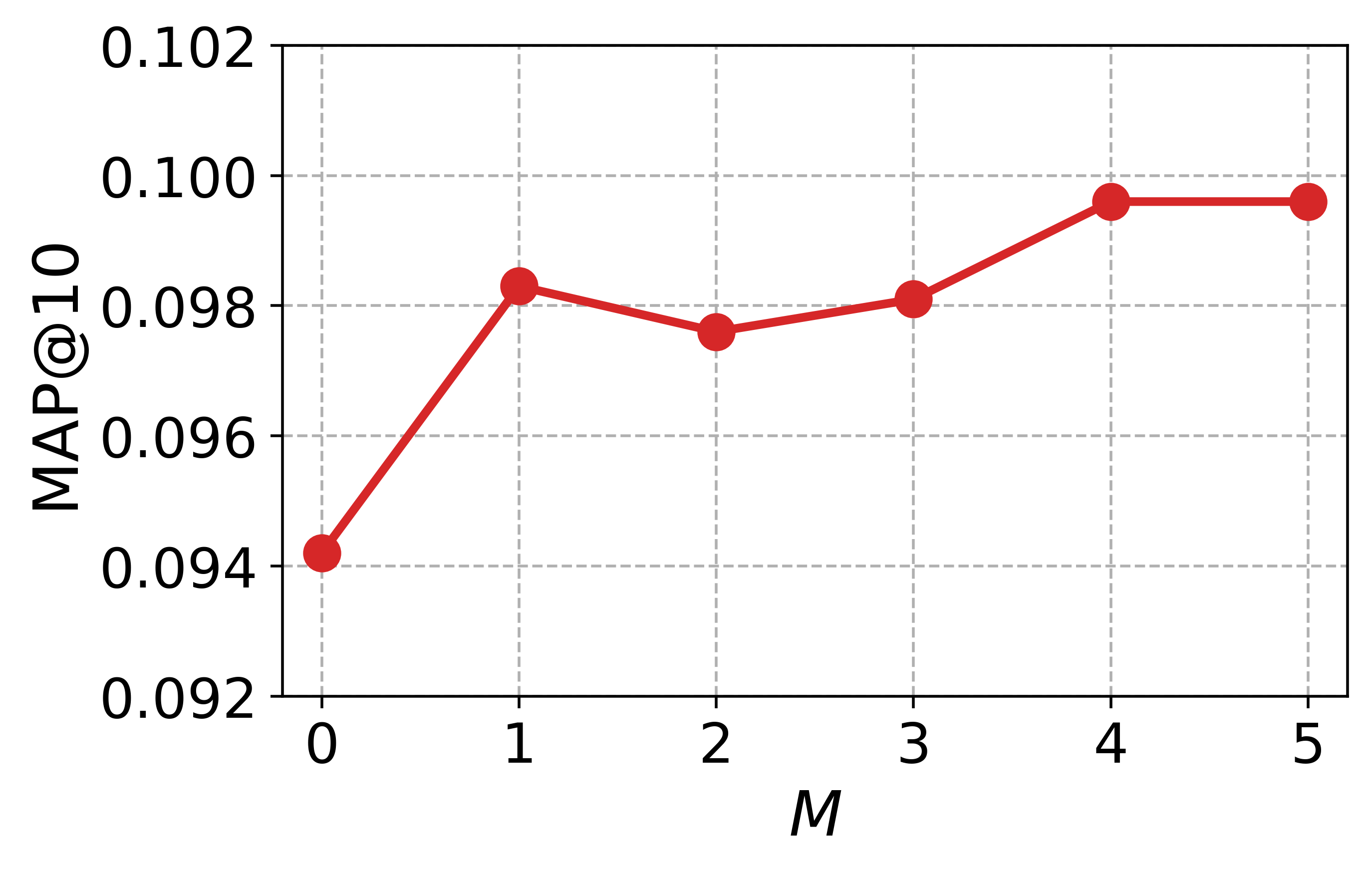
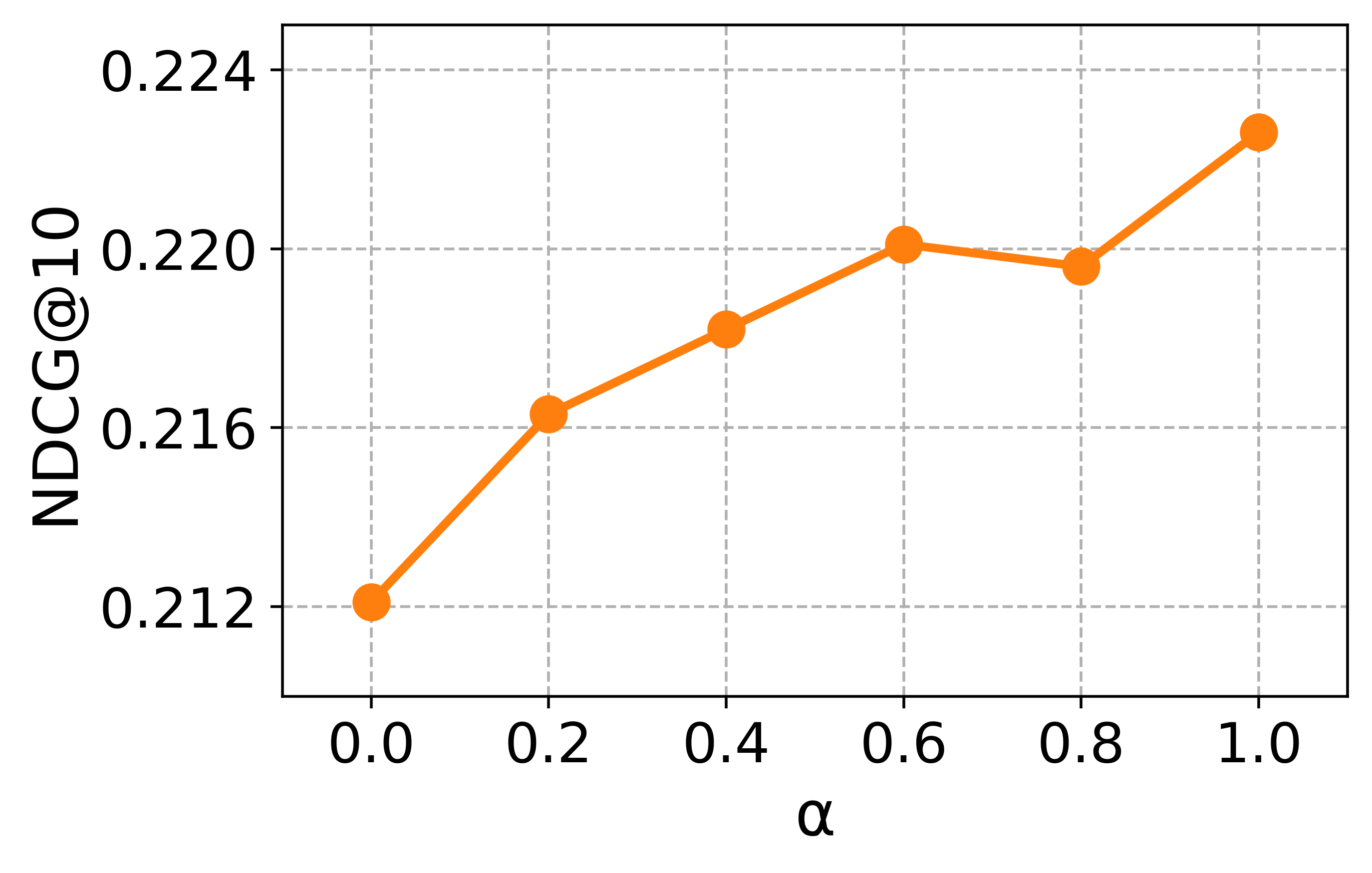
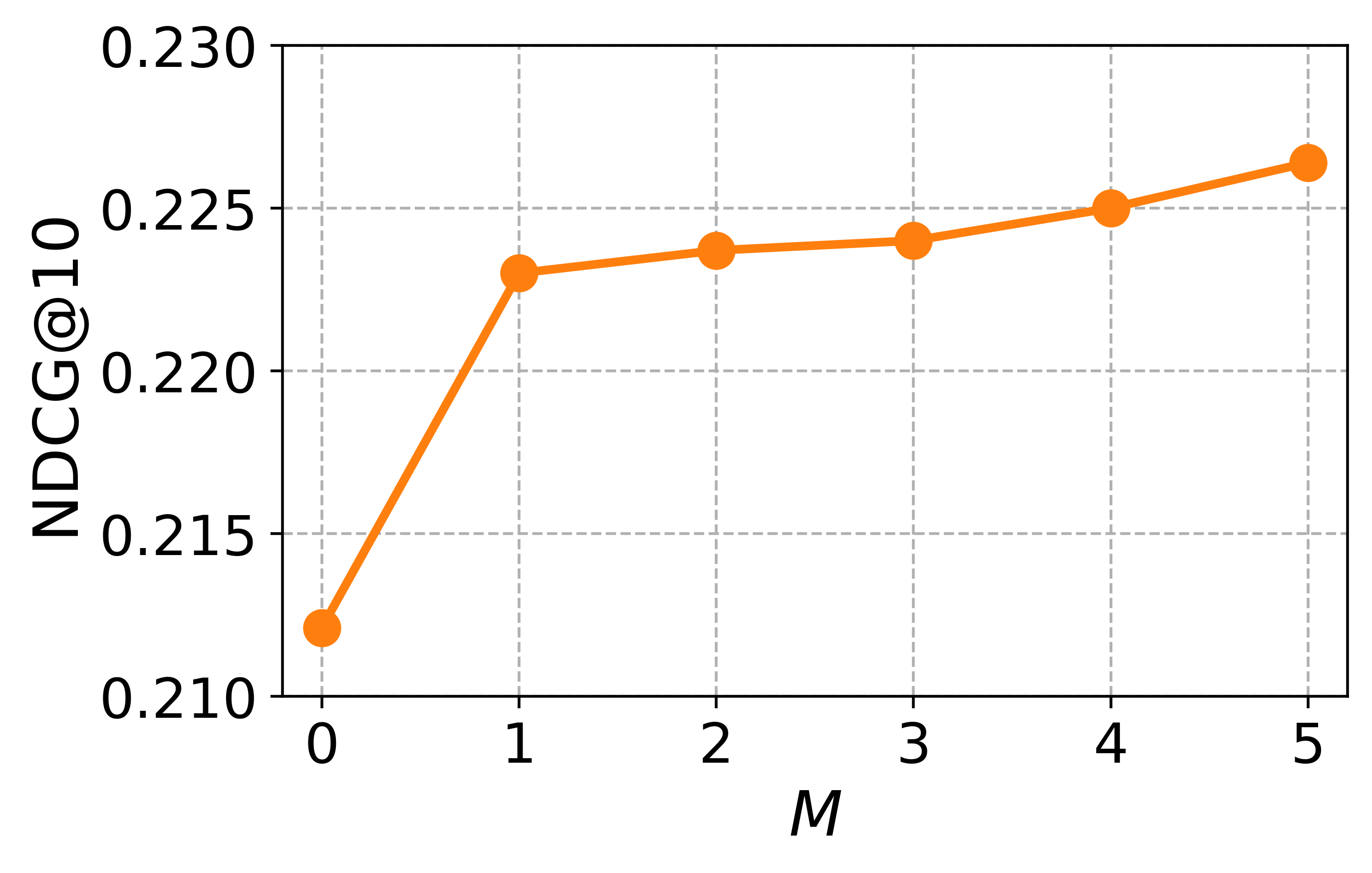
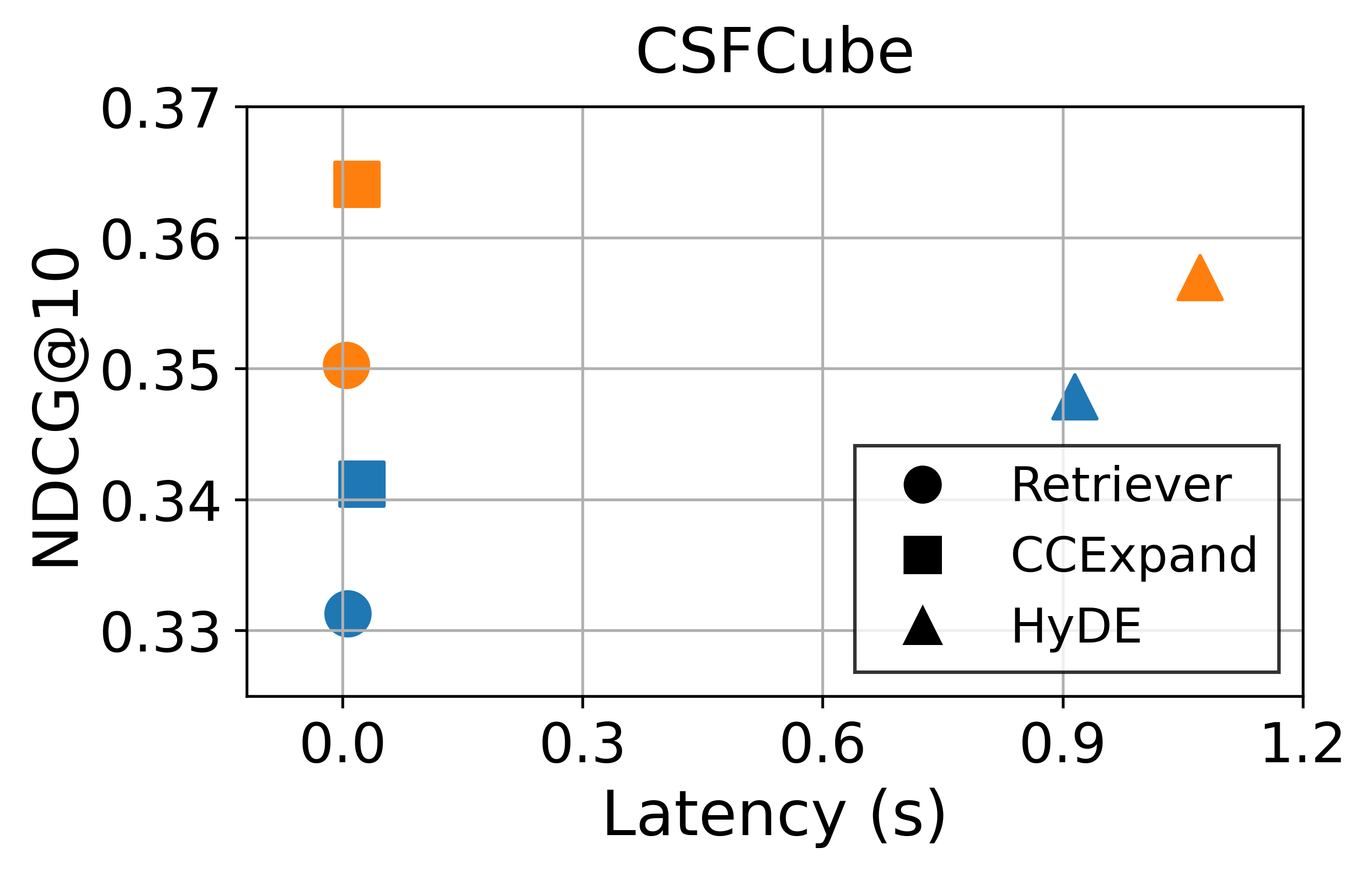
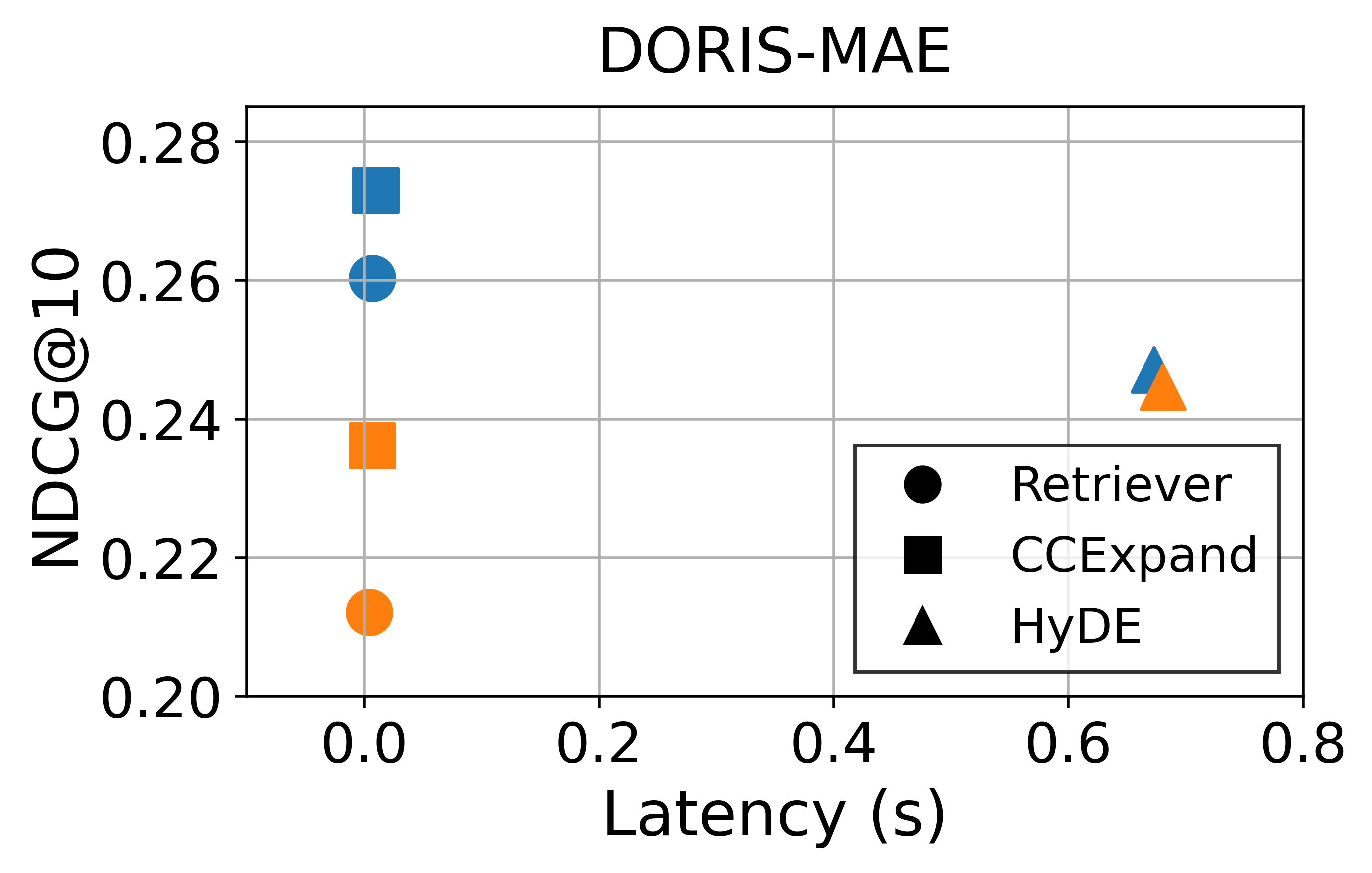
대규모 과학 데이터셋(예: SciFact, TREC COVID, arXiv)에서 베이스라인(전통 BM25, DPR, 기존 LLM‑기반 합성 질의)과 비교하였다. 평가 지표는 nDCG@10, MAP, Recall@100 등을 사용했으며, CCQGen + CCExpand 조합이 모든 지표에서 평균 5 ~ 12 %의 상대적 향상을 기록했다. 특히 ‘다중 개념 질의’ 상황에서 성능 격차가 두드러졌는데, 이는 인덱스가 제공하는 개념 커버리지가 질의 다양성을 크게 확대했기 때문이다.
의의 및 향후 연구
‘학술 개념 인덱스’라는 중간 레이어를 도입해 LLM 기반 파이프라인에 구조적 도메인 지식을 주입하였다. 이는 단순 프롬프트 엔지니어링을 넘어, 도메인 지식을 체계화해 LLM이 목표 지향적으로 작동하도록 만든 사례이다.
CCQGen은 질의 자체의 풍부함을, CCExpand은 질의에 대한 응답의 정확성을 동시에 강화한다는 점에서 상호 보완적이다.
향후 연구는 인덱스 자동 업데이트, 멀티‑모달(표·그래프) 개념 포함, 다른 도메인(법률·의료 등)으로의 확장 가능성을 탐색할 수 있다.