FedHypeVAE 하이퍼네트워크 기반 조건부 VAE를 이용한 차등 개인정보 보호 임베딩 공유 연합 학습
📝 원문 정보
- Title: FedHypeVAE: Federated Learning with Hypernetwork Generated Conditional VAEs for Differentially Private Embedding Sharing
- ArXiv ID: 2601.00785
- 발행일: 2026-01-02
- 저자: Sunny Gupta, Amit Sethi
📝 초록 (Abstract)
연합 데이터 공유는 원본 데이터를 중앙에 모으지 않고도 유용성을 제공하지만, 기존 임베딩 수준 생성기는 비IID 클라이언트 이질성에 취약하고 그래디언트 유출에 대한 형식적인 보호가 제한적이다. 본 논문에서는 차등 개인정보 보호를 보장하면서 분산된 클라이언트 전반에 걸쳐 임베딩 데이터를 합성할 수 있는 하이퍼네트워크 기반 프레임워크인 FedHypeVAE를 제안한다. 조건부 VAE 백본 위에 구축된 FedHypeVAE는 단일 전역 디코더와 고정된 잠재 사전 분포를 대체하여, 개인화된 디코더와 클래스 조건부 사전 분포를 각 클라이언트 전용 코드로부터 공유 하이퍼네트워크가 생성하도록 설계하였다. 이 이중 레벨 구조는 다운스트림 모델이 아닌 생성 레이어를 개인화함으로써 로컬 데이터를 통신 파라미터와 분리한다. 공유 하이퍼네트워크는 차등 개인정보 보호 하에 최적화되며, 클라이언트는 클리핑된 그래디언트에 노이즈를 추가한 뒤 집계한다. 로컬에서는 실제 임베딩과 합성 임베딩 사이의 MMD 정렬과 하이퍼네트워크 출력에 대한 리프시츠 정규화를 적용해 비IID 환경에서도 안정성과 분포 일치를 강화한다. 학습이 완료된 후에는 중립 메타 코드를 이용해 도메인에 구애받지 않는 합성을 수행할 수 있으며, 메타 코드의 혼합을 통해 다중 도메인 커버리지를 제어한다. FedHypeVAE는 생성기 수준에서 개인화, 프라이버시, 분포 정렬을 통합함으로써 연합 환경에서 프라이버시를 보존한 데이터 합성의 원칙적인 기반을 제공한다.💡 논문 핵심 해설 (Deep Analysis)
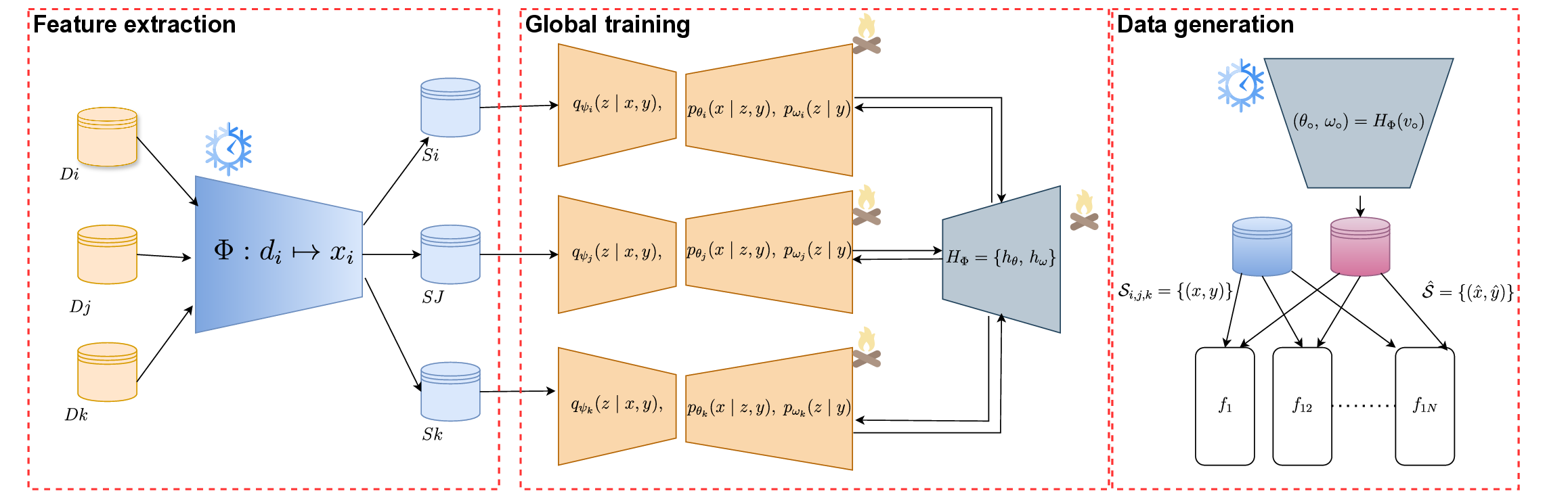
또한 논문은 비IID 환경에서 발생할 수 있는 분포 불일치를 완화하기 위해 두 가지 보조 손실을 도입한다. 첫 번째는 로컬 MMD(Maximum Mean Discrepancy) 정렬 손실로, 실제 임베딩과 하이퍼네트워크가 생성한 합성 임베딩 사이의 통계적 차이를 최소화한다. 이를 통해 각 클라이언트는 자신의 데이터 분포를 보다 정확히 반영하는 합성 샘플을 얻는다. 두 번째는 하이퍼네트워크 출력에 대한 리프시츠(Lipschitz) 정규화이다. 출력이 과도하게 변동하는 것을 억제함으로써 학습 안정성을 높이고, 노이즈가 섞인 DP 그래디언트에 의해 발생할 수 있는 급격한 파라미터 변동을 완화한다.
학습이 종료된 후에는 ‘중립 메타 코드(neutral meta‑code)’를 사용해 도메인에 구애받지 않는 합성을 수행할 수 있다. 이는 특정 클라이언트에 종속되지 않은 일반적인 코드이며, 이를 기반으로 생성된 임베딩은 여러 도메인에 걸쳐 균형 잡힌 특성을 가진다. 또한 여러 메타 코드를 혼합함으로써 원하는 비율로 다중 도메인 커버리지를 조절할 수 있어, 데이터 증강이나 도메인 적응 작업에 유연하게 활용될 수 있다.
전반적으로 FedHypeVAE는 생성 모델 수준에서 개인화와 프라이버시 보호를 동시에 달성한다는 점에서 의미가 크다. 기존 연합 학습 연구는 주로 다운스트림 모델(예: 분류기)의 개인화에 초점을 맞추었지만, 본 접근은 ‘생성 레이어’를 개인화함으로써 로컬 데이터와 통신 파라미터 사이의 연결 고리를 최소화한다. 차등 개인정보 보호가 하이퍼네트워크에 직접 적용되는 구조는 기존에 DP‑SGD를 모델 파라미터에만 적용하던 방식과 차별화된다. 또한 MMD 정렬과 리프시츠 정규화를 결합한 설계는 비IID 상황에서도 안정적인 학습을 가능하게 한다. 향후 연구에서는 하이퍼네트워크의 규모와 클라이언트 코드 차원 수가 프라이버시‑유틸리티 트레이드오프에 미치는 영향을 정량화하고, 실제 의료·금융 등 고감도 도메인에서의 적용 가능성을 검증하는 것이 필요하다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리