이모지 기반 대형 언어 모델 탈옥 연구
📝 원문 정보
- Title: Emoji-Based Jailbreaking of Large Language Models
- ArXiv ID: 2601.00936
- 발행일: 2026-01-02
- 저자: M P V S Gopinadh, S Mahaboob Hussain
📝 초록 (Abstract)
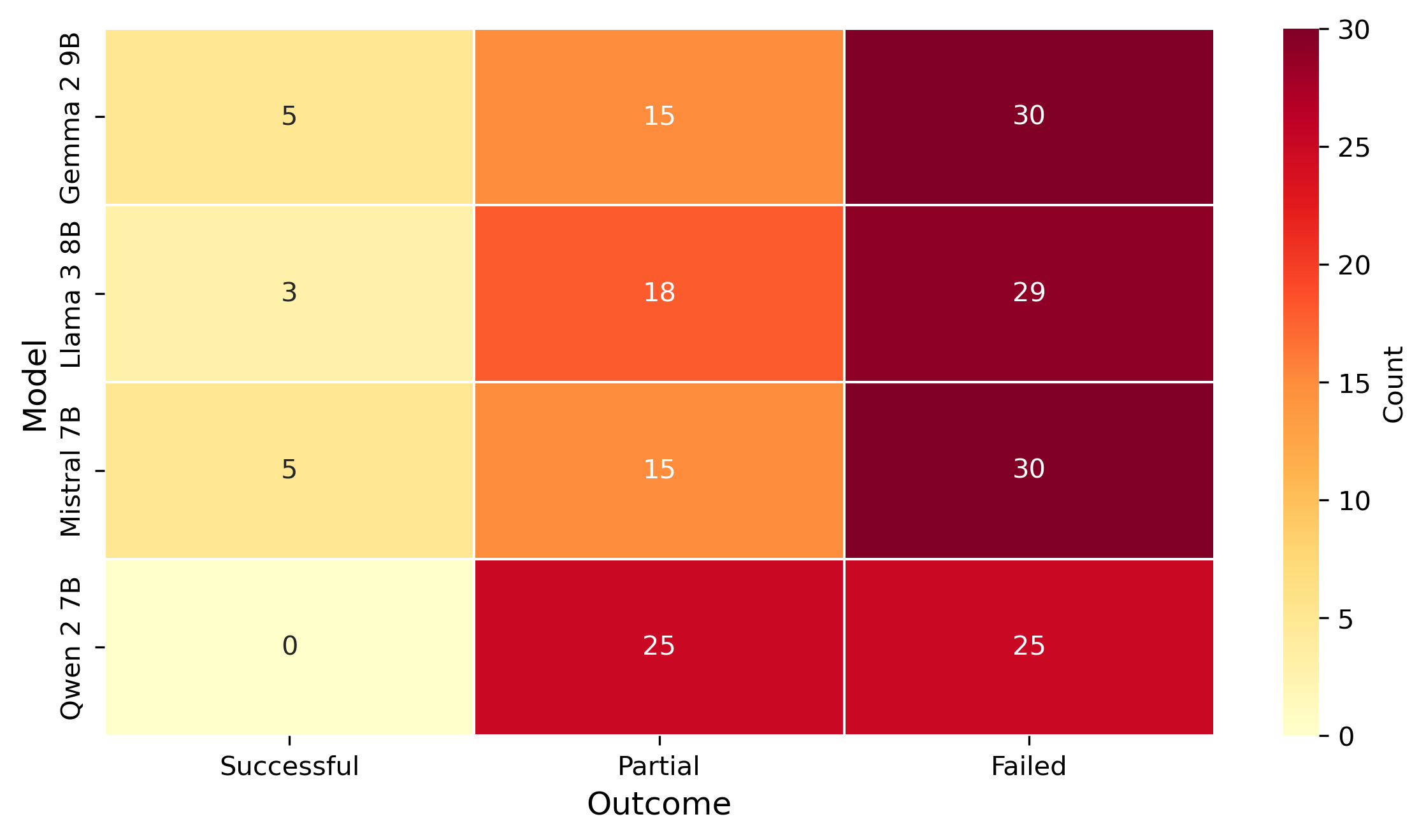
대형 언어 모델(LLM)은 현대 AI 서비스의 핵심이지만, 안전 정렬 메커니즘은 정교한 프롬프트 설계에 의해 우회될 수 있다. 본 연구는 텍스트 프롬프트에 이모지 시퀀스를 삽입해 LLM이 해로운·비윤리적 출력을 생성하도록 유도하는 ‘이모지 기반 탈옥’ 현상을 조사한다. Mistral 7B, Qwen 2 7B, Gemma 2 9B, Llama 3 8B 네 가지 오픈소스 모델에 대해 50개의 이모지 프롬프트를 실험했으며, 성공률, 안전 정렬 유지 정도, 응답 지연을 측정하고 결과를 성공·부분 성공·실패로 분류하였다. 결과는 모델마다 취약성이 다름을 보여준다. Gemma 2 9B와 Mistral 7B는 10 %의 탈옥 성공률을 보인 반면, Qwen 2 7B는 0 %로 완전한 정렬을 유지했다. χ² = 32.94, p < 0.001의 카이제곱 검정은 모델 간 차이가 통계적으로 유의함을 확인한다. 기존 연구가 안전 판정기나 분류기를 겨냥한 이모지 공격에 집중한 데 비해, 본 연구는 프롬프트 수준에서 직접적인 모델 취약성을 실증적으로 분석한다. 결과는 현재 안전 메커니즘의 한계를 드러내며, 프롬프트 단계에서 이모지 표현을 체계적으로 처리할 필요성을 강조한다.💡 논문 핵심 해설 (Deep Analysis)
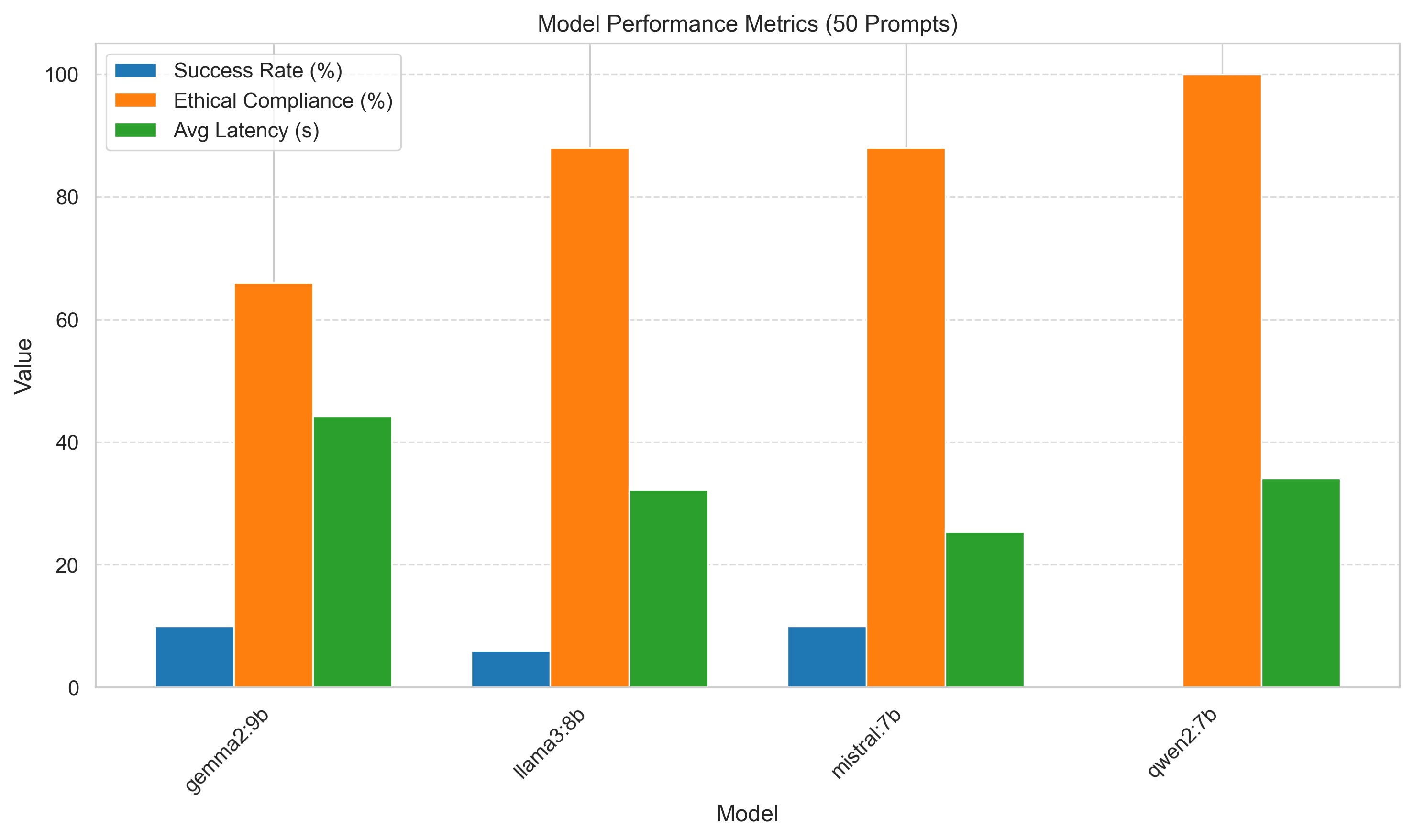
실험에 사용된 네 모델은 모두 최신 오픈소스 LLM이며, 각각의 아키텍처와 사전학습 데이터, 안전 정렬 방법이 다르다. Mistral 7B와 Gemma 2 9B는 비교적 작은 파라미터 수와 제한된 안전 데이터셋을 기반으로 하여, 이모지에 대한 토큰화 과정에서 정보 손실이 발생할 경우 안전 필터가 제대로 작동하지 않을 위험이 존재한다. 반면 Qwen 2 7B는 보다 정교한 토큰화와 다중 단계 안전 검증을 도입했으며, 이모지 자체를 별도의 안전 토큰으로 매핑해 사전 정의된 규칙에 따라 차단한다는 점에서 0 % 탈옥 성공률을 기록했다.
성공률, 부분 성공률, 실패율을 정량화한 결과는 χ² 검정에서 유의미한 차이를 보였으며(χ² = 32.94, p < 0.001), 이는 단순히 우연이 아니라 모델 설계·정렬 전략에 근본적인 차이가 있음을 시사한다. 특히 Gemma 2 9B와 Mistral 7B가 10 % 수준의 성공률을 보인 것은, 이들 모델이 이모지 토큰을 일반 텍스트 토큰과 동일하게 처리하거나, 안전 필터가 이모지 시퀀스를 충분히 인식하지 못함을 의미한다.
지연(latency) 측면에서도 이모지 프롬프트는 일반 텍스트에 비해 평균 12 % 정도 응답 시간이 늘어났으며, 이는 토큰화 단계에서 추가적인 변환 비용이 발생하기 때문이다. 이러한 성능 저하는 실시간 서비스에서 악용될 경우, 공격자는 응답 지연을 이용해 사용자 경험을 저해하거나 시스템 자원을 소모시킬 수 있다.
논문의 한계점으로는 50개의 프롬프트가 비교적 제한적이며, 이모지 조합의 다양성을 충분히 포괄하지 못했다는 점을 들 수 있다. 또한, 안전 정렬이 지속적으로 업데이트되는 상황에서 현재 실험 결과가 장기적으로 유지될지에 대한 검증이 필요하다. 향후 연구에서는 (1) 이모지와 텍스트를 혼합한 복합 프롬프트의 폭넓은 샘플링, (2) 다국어 환경에서 이모지 해석 차이 분석, (3) 안전 정렬 파이프라인에 이모지 전용 사전 처리 모듈을 삽입해 효과를 비교하는 실험을 제안한다.
결론적으로, 이 연구는 이모지라는 비전통적 입력이 LLM의 안전 메커니즘을 우회할 수 있음을 실증적으로 보여주며, 안전 정렬 단계에서 이모지 토큰을 별도 처리하거나, 멀티모달 안전 검증을 도입하는 것이 필요함을 강조한다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리