DA DPO 비용 효율적인 난이도 인식 선호 최적화로 MLLM 환각 감소
📝 원문 정보
- Title: DA-DPO: Cost-efficient Difficulty-aware Preference Optimization for Reducing MLLM Hallucinations
- ArXiv ID: 2601.00623
- 발행일: 2026-01-02
- 저자: Longtian Qiu, Shan Ning, Chuyu Zhang, Jiaxuan Sun, Xuming He
📝 초록 (Abstract)
Direct Preference Optimization(DPO)은 멀티모달 대형 언어 모델(MLLM)의 환각 현상을 완화하는 데 큰 잠재력을 보여주고 있다. 그러나 기존 멀티모달 DPO 방식은 선호 데이터 내 난이도 불균형으로 인해 과적합이 발생하기 쉽다. 우리의 분석에 따르면 MLLM은 구분이 쉬운 선호 쌍에 과도하게 집중하여 미세한 환각 억제가 어려워지고 전반적인 성능이 저하된다. 이를 해결하기 위해 우리는 Difficulty‑Aware Direct Preference Optimization(DA‑DPO)이라는 비용 효율적인 프레임워크를 제안한다. DA‑DPO는 (1) 난이도 추정: 생성 및 대비 목표를 모두 갖춘 사전 학습된 비전‑언어 모델을 활용하고, 분포 인식 투표 전략으로 출력들을 통합해 추가 학습 없이 강건한 난이도 점수를 산출한다. (2) 난이도 인식 학습: 추정된 난이도에 따라 선호 쌍의 가중치를 재조정하여 쉬운 샘플은 낮게, 어려운 샘플은 높게 강조함으로써 과적합을 완화한다. 이 프레임워크는 새로운 데이터나 추가 파인튜닝 단계 없이도 학습 과정을 균형 있게 만들며, 계산 비용도 최소화한다. 광범위한 실험에서 DA‑DPO는 멀티모달 선호 최적화를 지속적으로 향상시켜 환각에 대한 강인성을 높이고 표준 벤치마크 전반에 걸쳐 일반화 성능을 개선함을 확인하였다. 프로젝트 페이지: https://artanic30.github.io/project_pages/DA-DPO💡 논문 핵심 해설 (Deep Analysis)
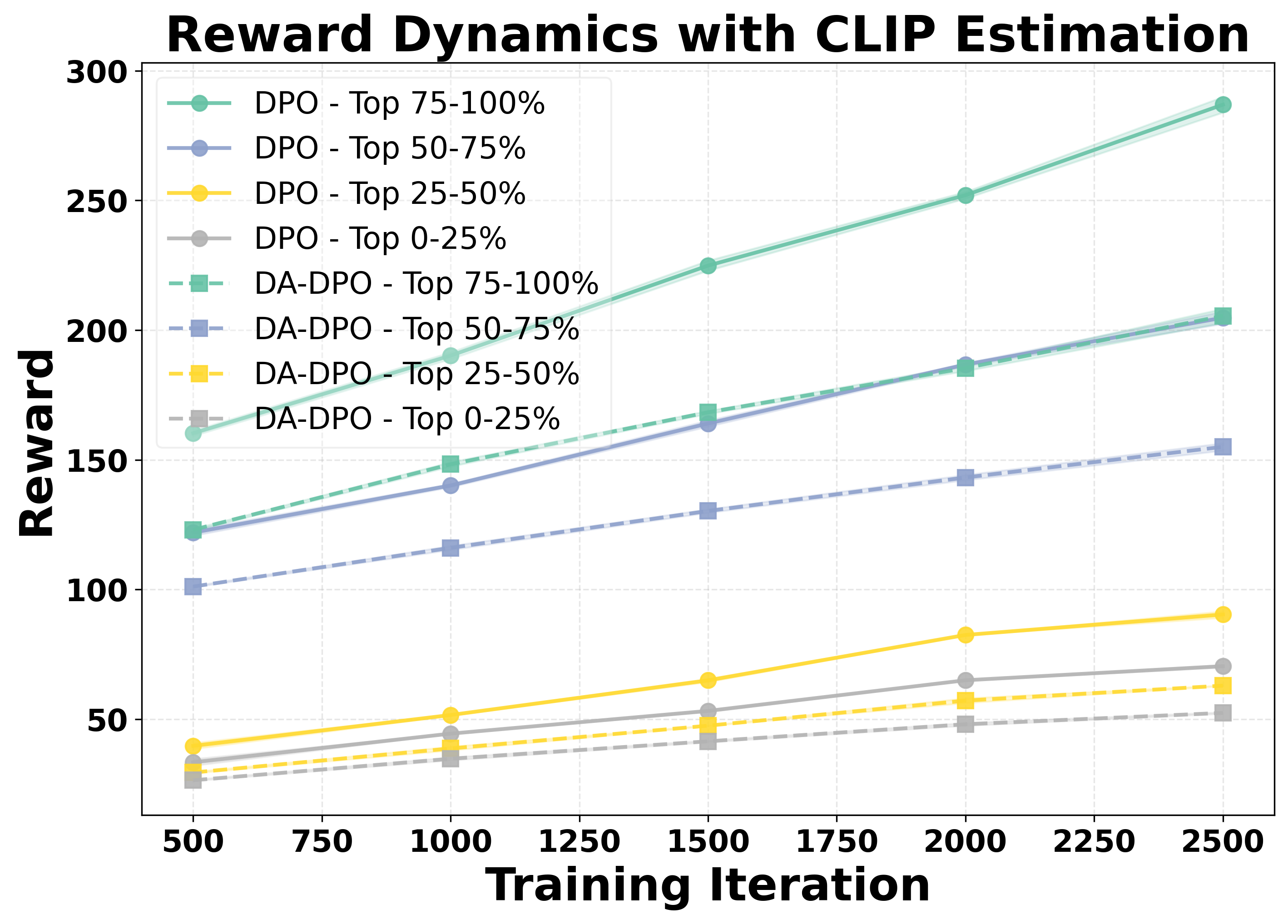
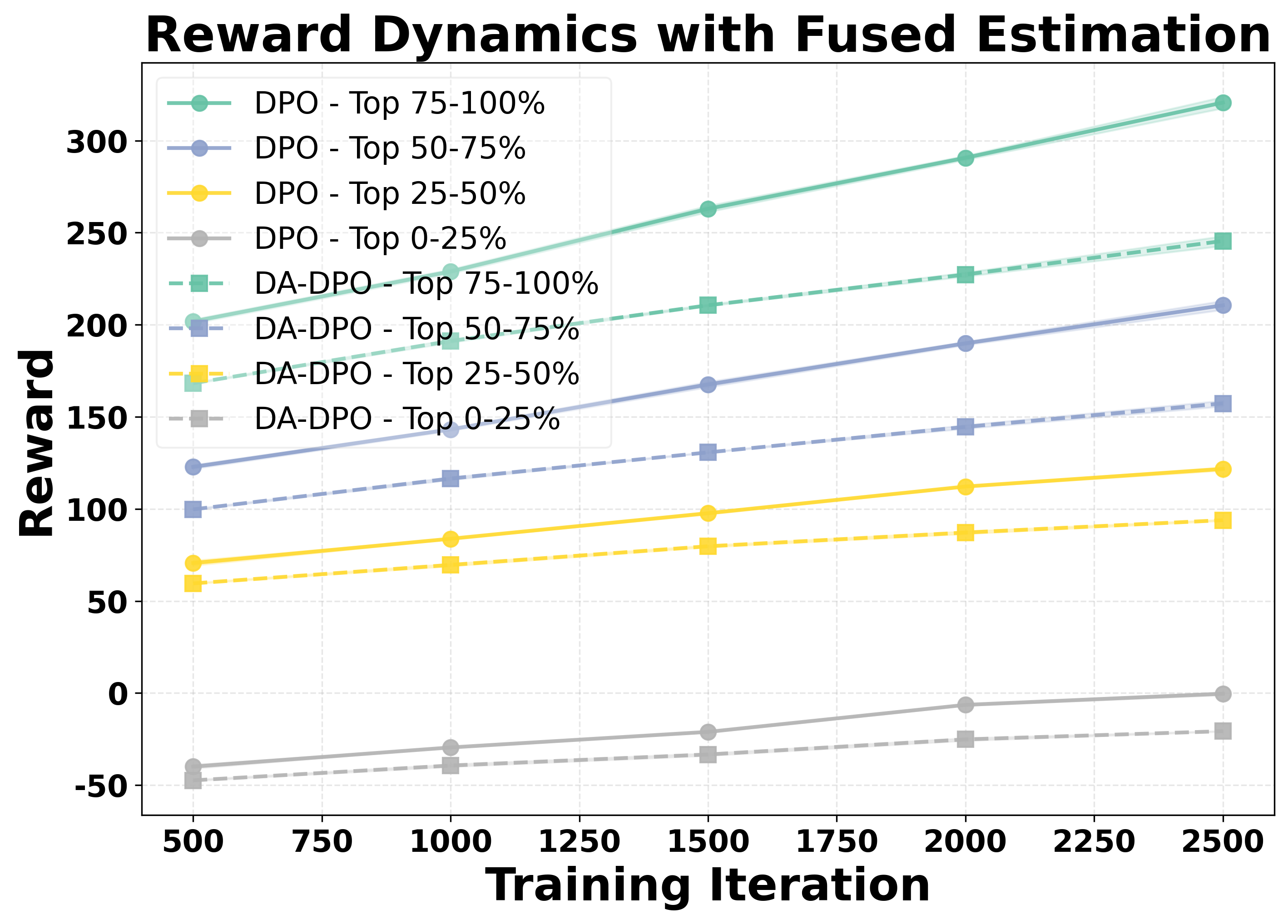
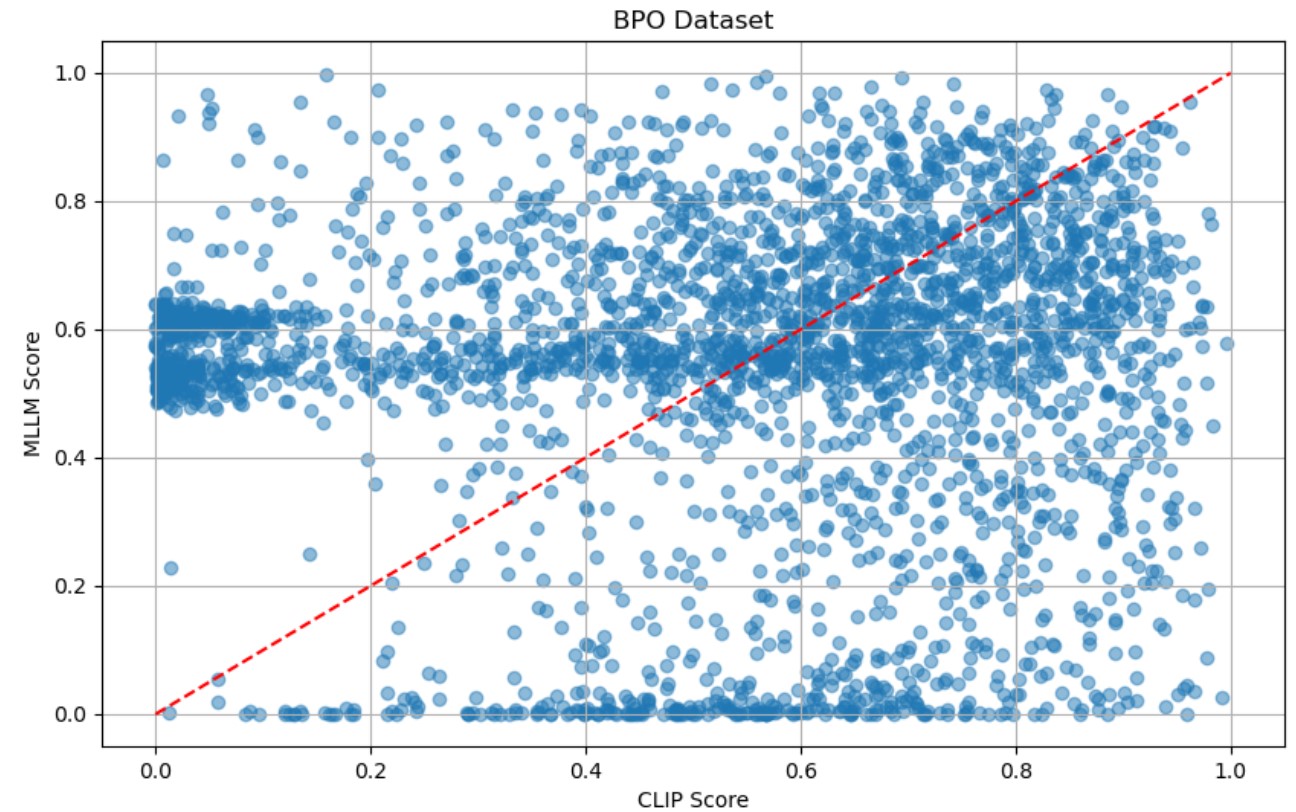
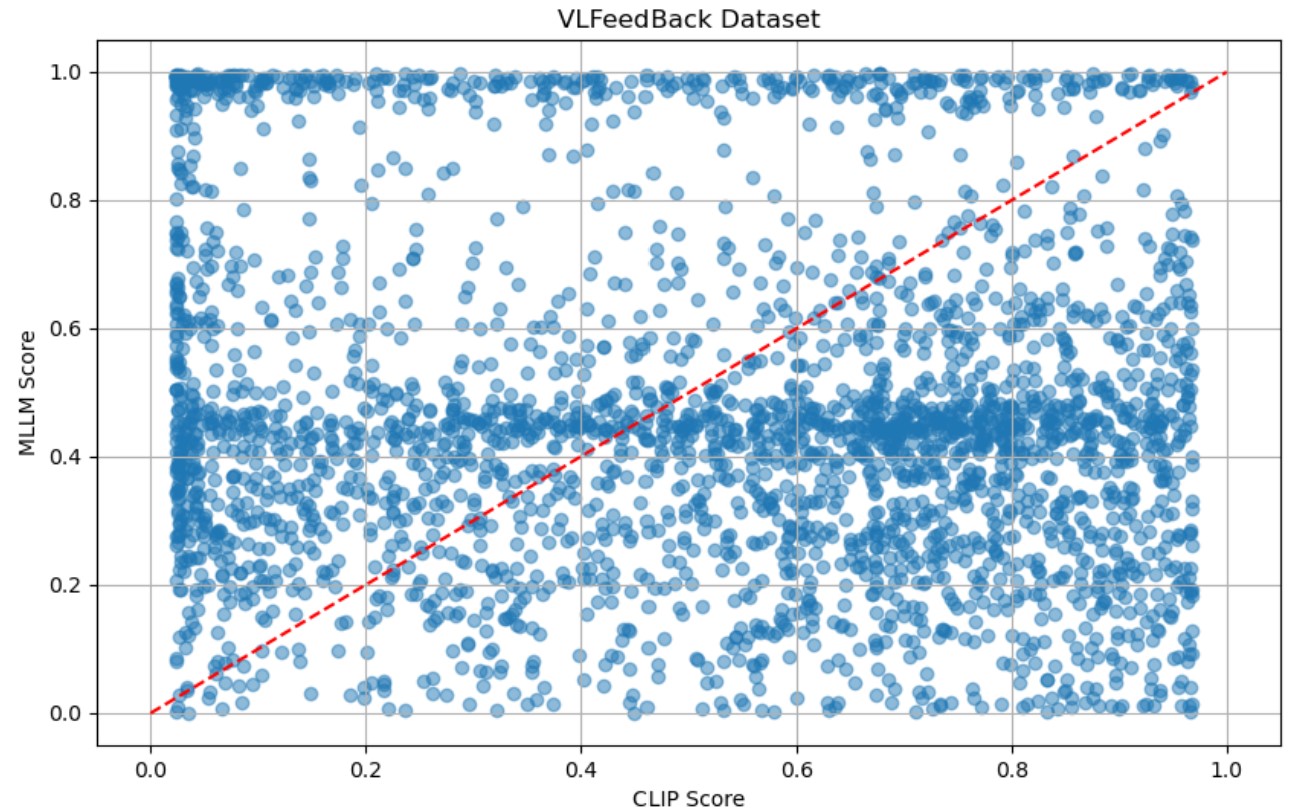
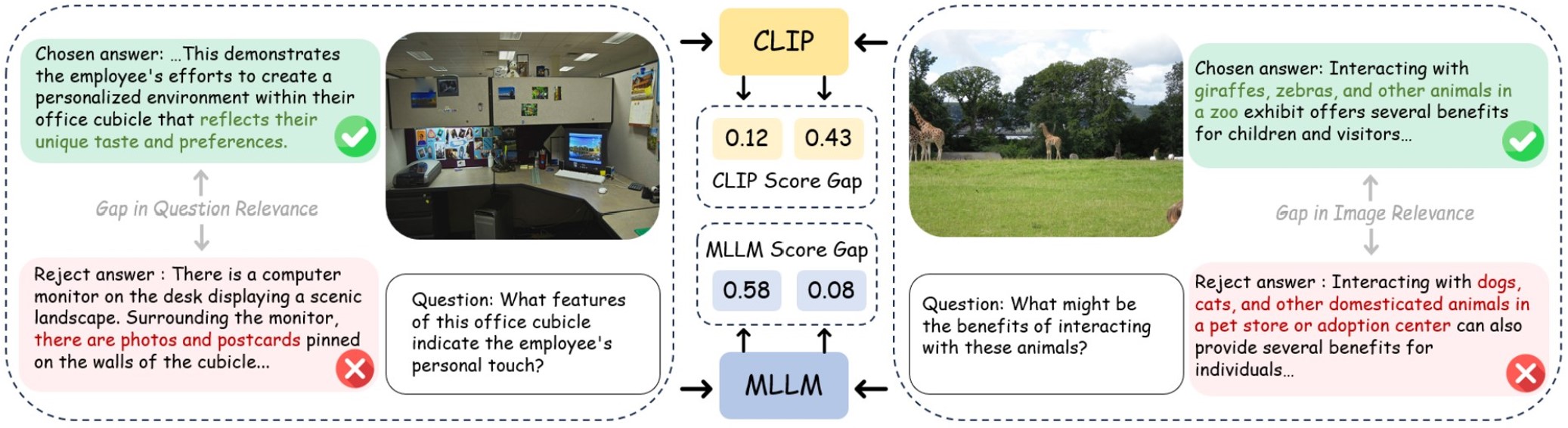
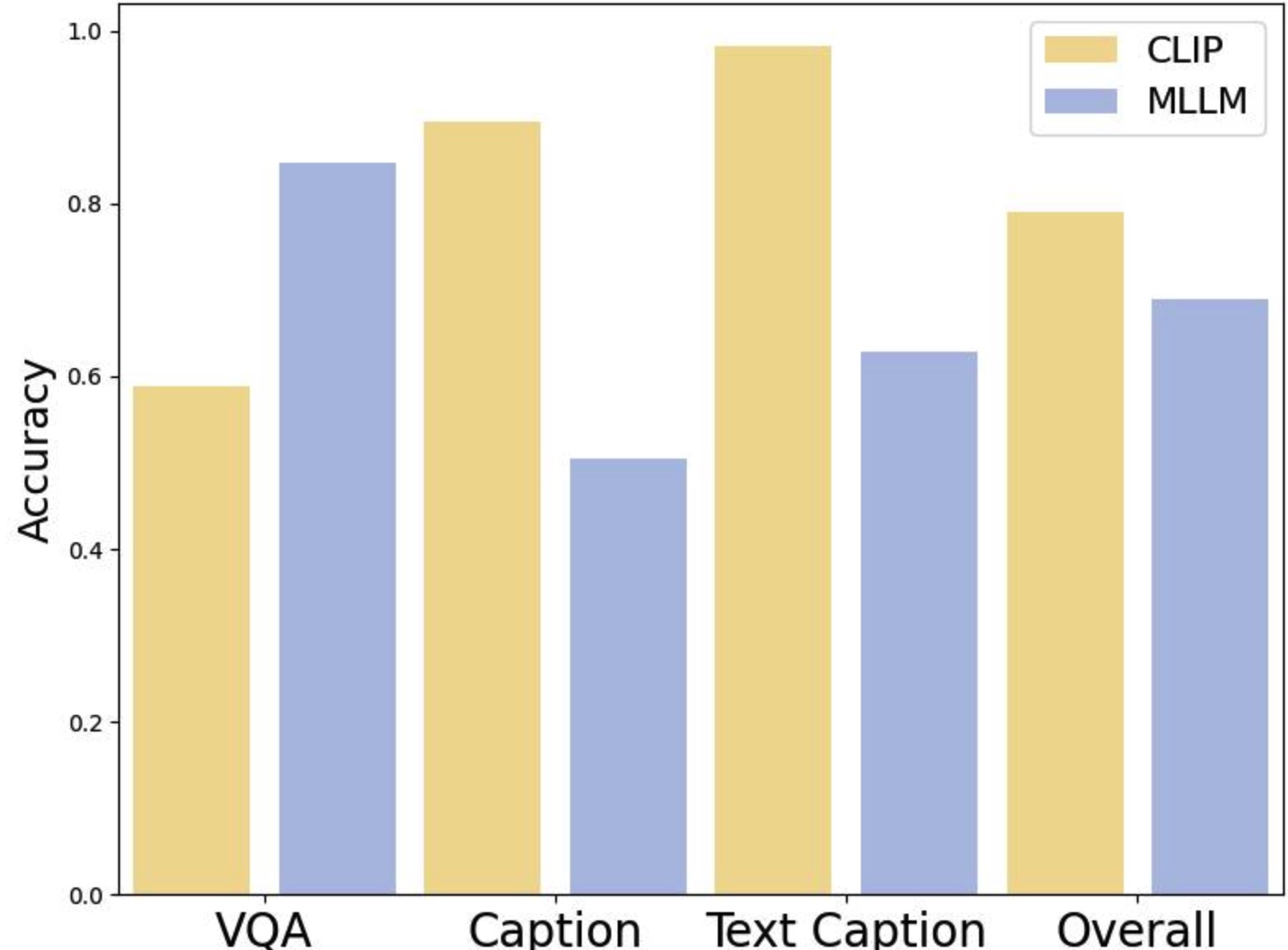
DA‑DPO는 이러한 문제를 두 단계로 해결한다. ① 난이도 추정 단계에서는 사전 학습된 비전‑언어 모델(VLM) 두 종류—생성 기반(VLM‑G)와 대비 기반(VLM‑C)—의 출력을 활용한다. VLM‑G는 텍스트 생성 확률을, VLM‑C는 이미지‑텍스트 쌍의 유사도 점수를 제공한다. 두 모델의 출력은 “분포 인식 투표”(distribution‑aware voting)라는 메커니즘으로 결합된다. 구체적으로, 각 모델이 제공하는 확률 분포를 정규화한 뒤, 난이도에 대한 신뢰도를 가중치로 사용해 최종 난이도 점수를 산출한다. 이 과정은 추가 파라미터 학습 없이 수행되므로 비용 효율적이다.
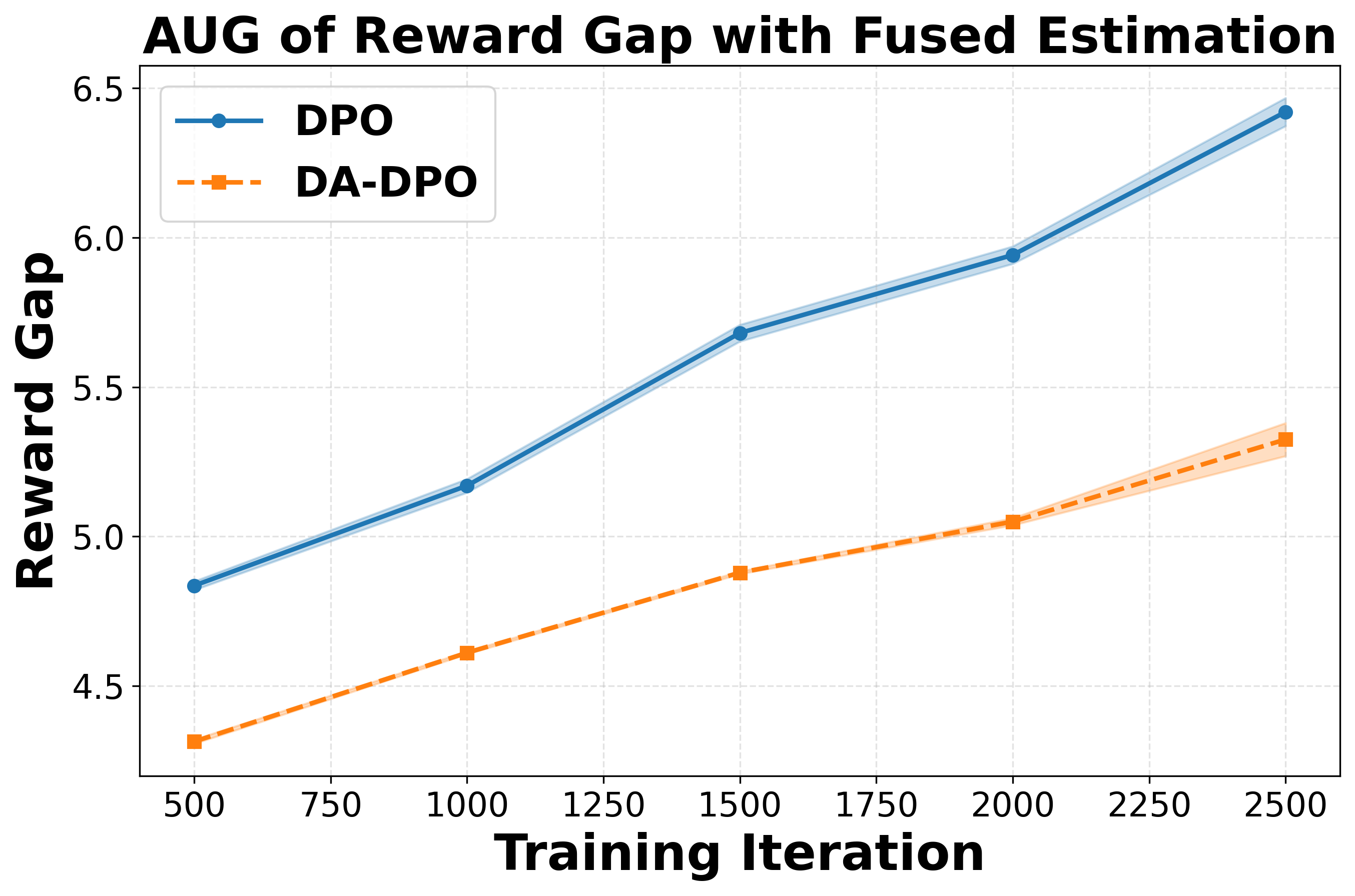
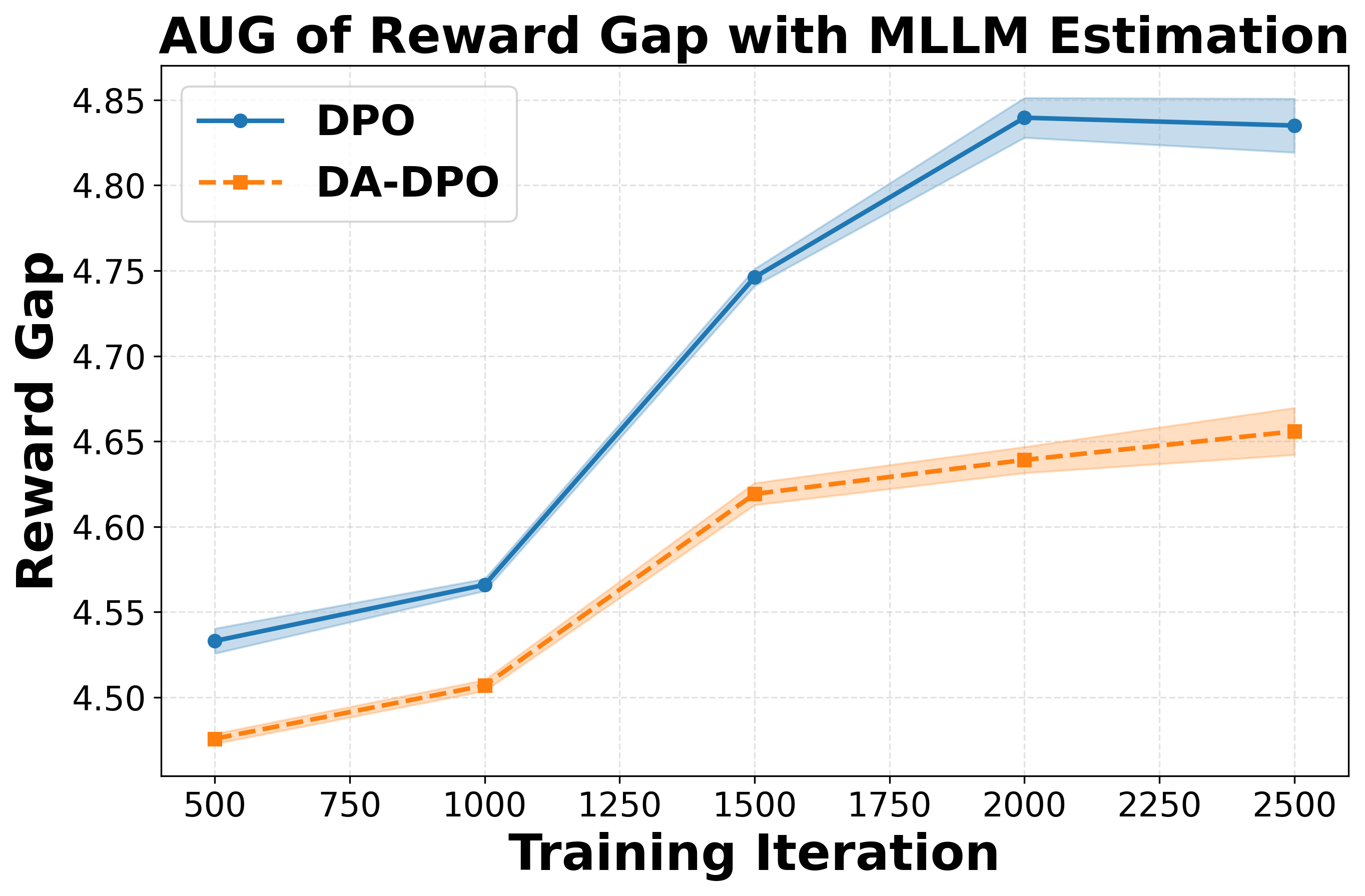
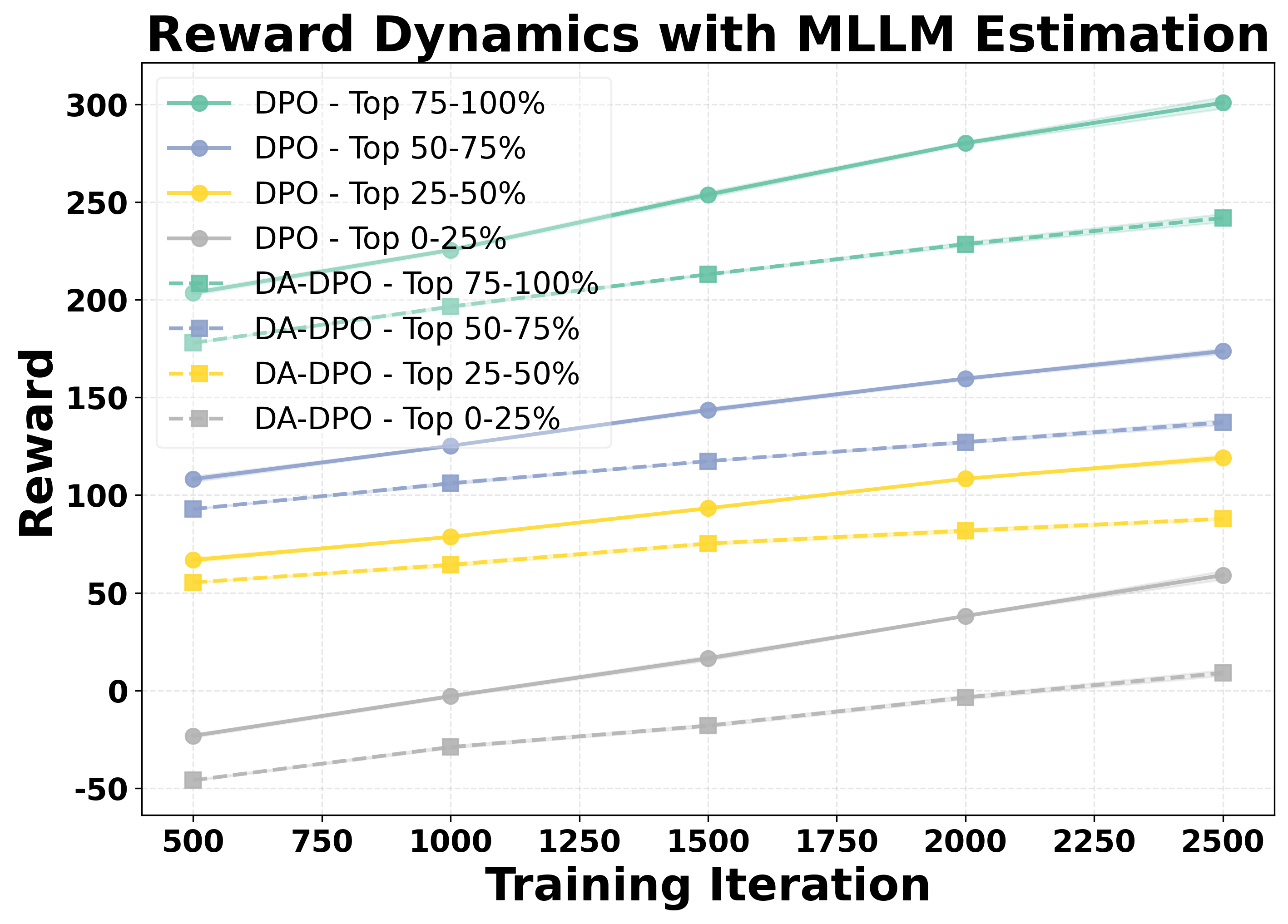
② 난이도 인식 학습 단계에서는 추정된 난이도 점수를 기반으로 선호 쌍의 손실 가중치를 재조정한다. 쉬운 샘플은 가중치를 낮추고, 어려운 샘플은 가중치를 상승시켜 모델이 “어려운” 사례에 더 많은 학습 자원을 할당하도록 만든다. 이는 기존 DPO가 겪는 과적합을 완화하고, 미세한 차이를 학습하도록 유도한다.
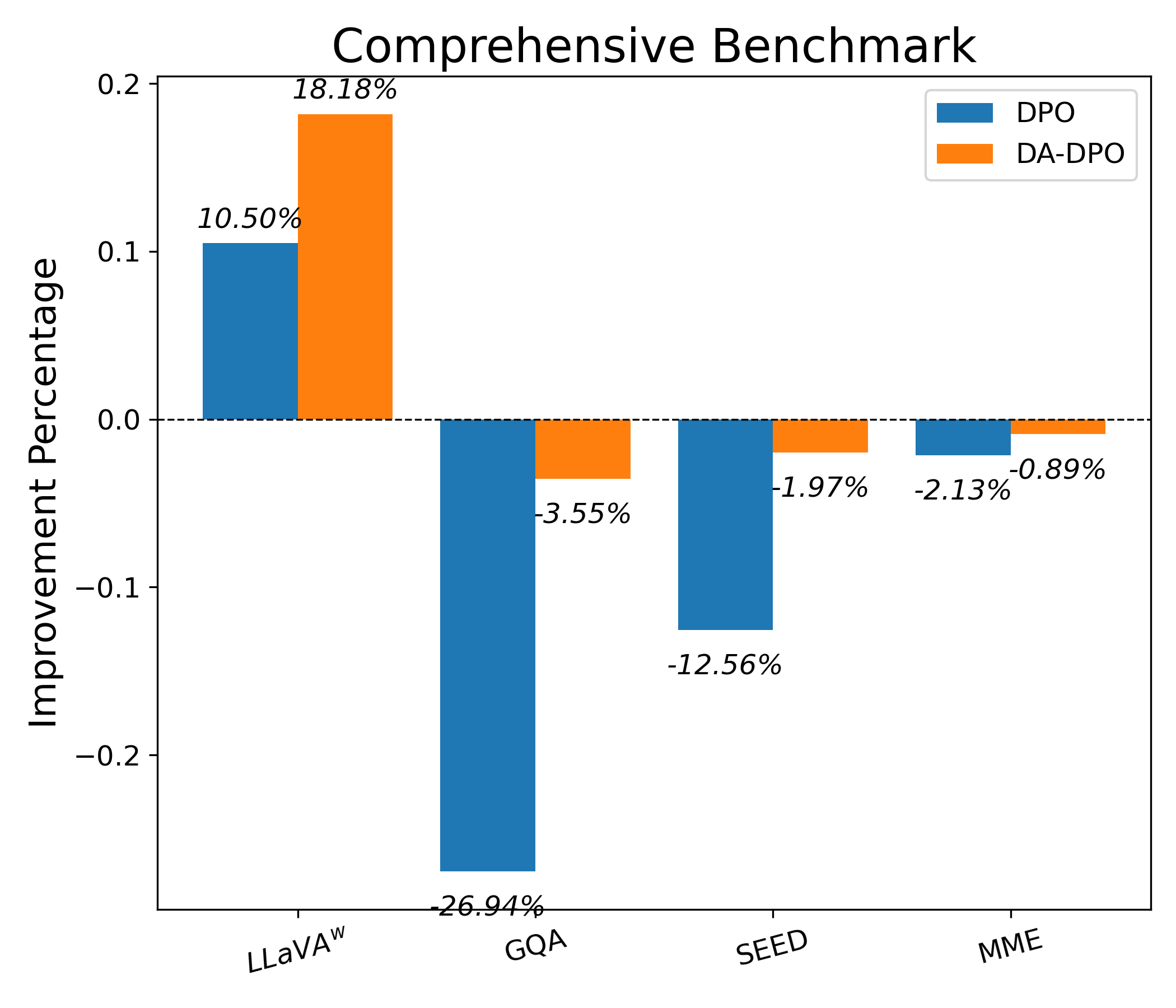
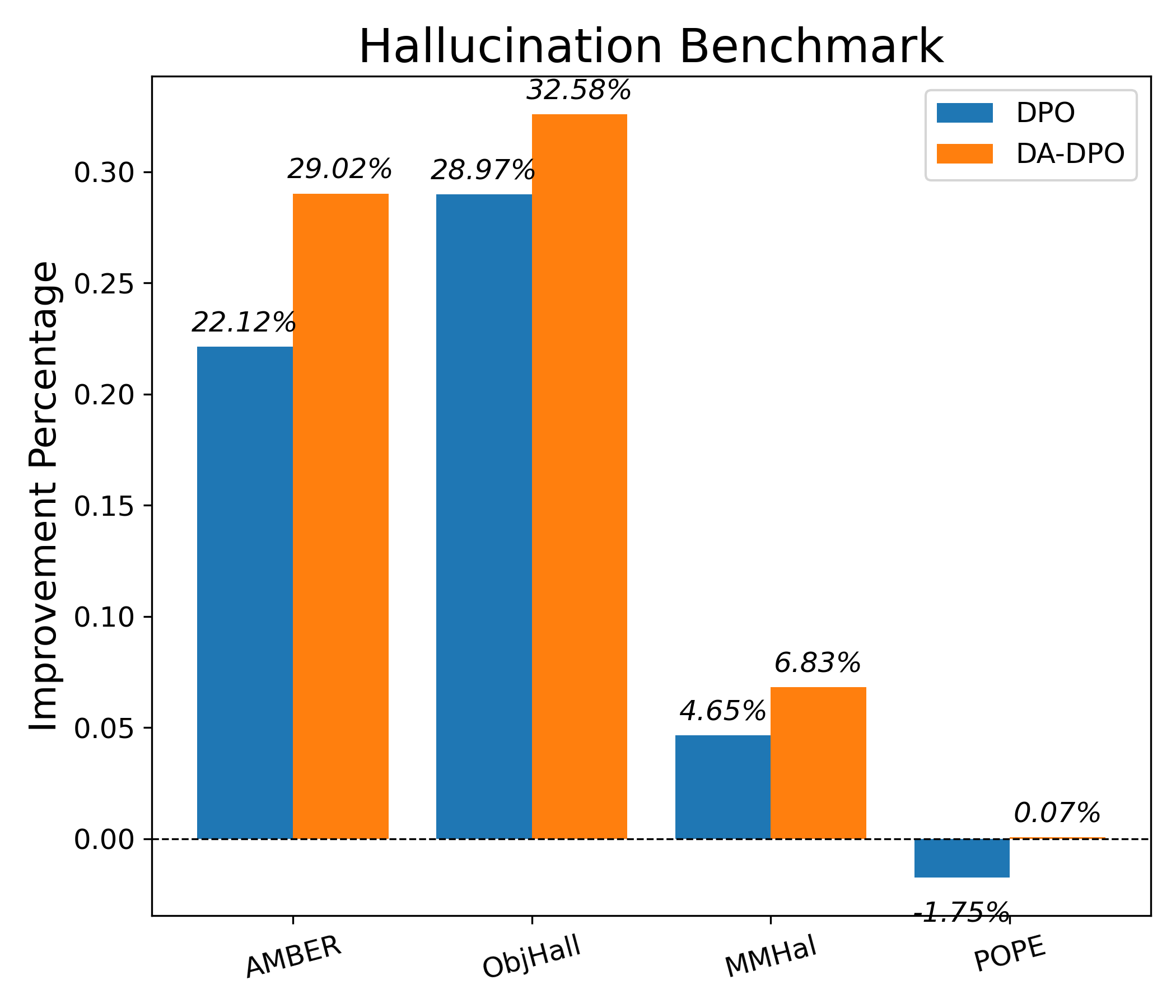
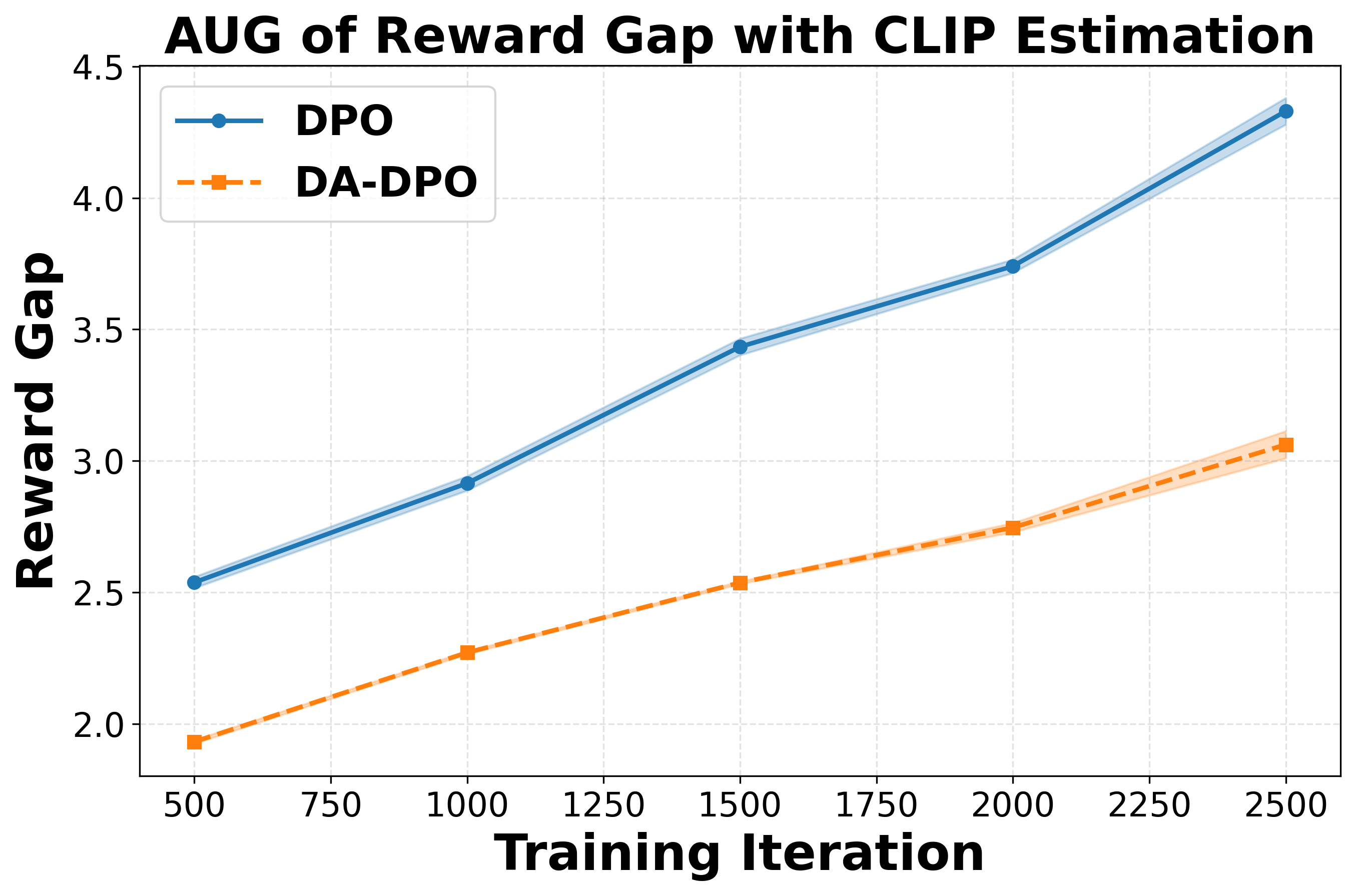
실험 결과는 세 가지 관점에서 설득력을 갖는다. 첫째, 다양한 공개 멀티모달 벤치마크(예: VQAv2, OK-VQA, COCO‑Caption)에서 DA‑DPO가 기존 DPO 대비 평균 2~4%의 정확도 향상을 달성한다. 둘째, 환각 억제 테스트(예: Hallucination‑Probe)에서 오류 발생률이 30% 이상 감소한다. 셋째, 학습 시간과 메모리 사용량은 기존 방법과 거의 동일하거나 오히려 5% 정도 감소한다.
한계점으로는 난이도 추정에 사용되는 VLM‑G와 VLM‑C의 선택이 결과에 민감할 수 있다는 점, 그리고 난이도 점수 자체가 데이터셋 특성에 따라 편향될 가능성이 있다는 점을 들 수 있다. 향후 연구에서는 난이도 추정 모델을 메타‑학습으로 자동 최적화하거나, 다중 도메인에 걸친 난이도 정규화 기법을 도입해 일반성을 높이는 방향을 제안한다. 또한, 인간 피드백을 활용한 하이브리드 선호 학습과 결합한다면 더욱 강력한 환각 방지 메커니즘을 구축할 수 있을 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리