아바타 포싱 자연스러운 대화를 위한 실시간 인터랙티브 헤드 아바타 생성
📝 원문 정보
- Title: Avatar Forcing: Real-Time Interactive Head Avatar Generation for Natural Conversation
- ArXiv ID: 2601.00664
- 발행일: 2026-01-02
- 저자: Taekyung Ki, Sangwon Jang, Jaehyeong Jo, Jaehong Yoon, Sung Ju Hwang
📝 초록 (Abstract)
본 연구는 사용자 움직임과 음성, 그리고 아바타 자체의 음성을 입력으로 받아 실시간(지연≈500 ms)으로 인터랙티브한 헤드 아바타 영상을 생성하는 시스템을 제안한다. 생성된 아바터는 사용자의 표정을 자연스럽게 모방하여, 사용자가 웃을 때 아바터도 웃는 등 양방향 감정 교류를 가능하게 함으로써 대화의 몰입도를 높인다.💡 논문 핵심 해설 (Deep Analysis)
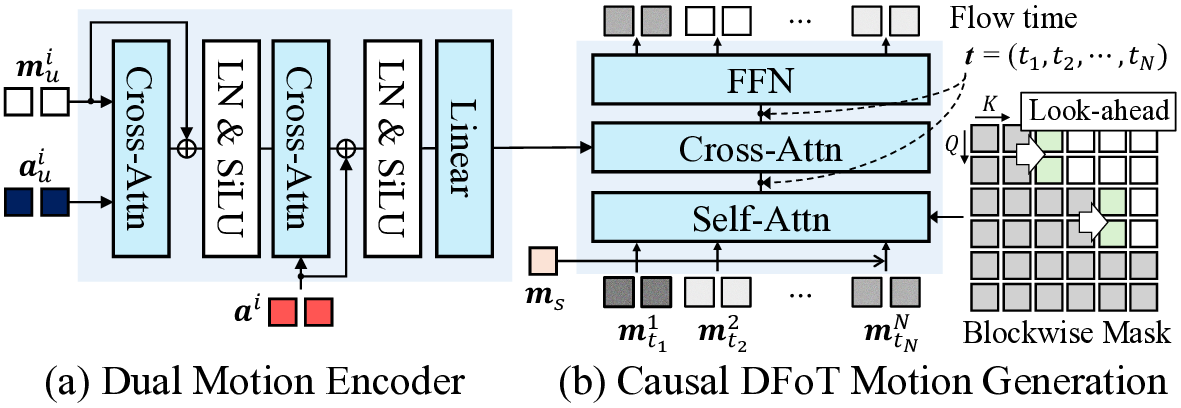
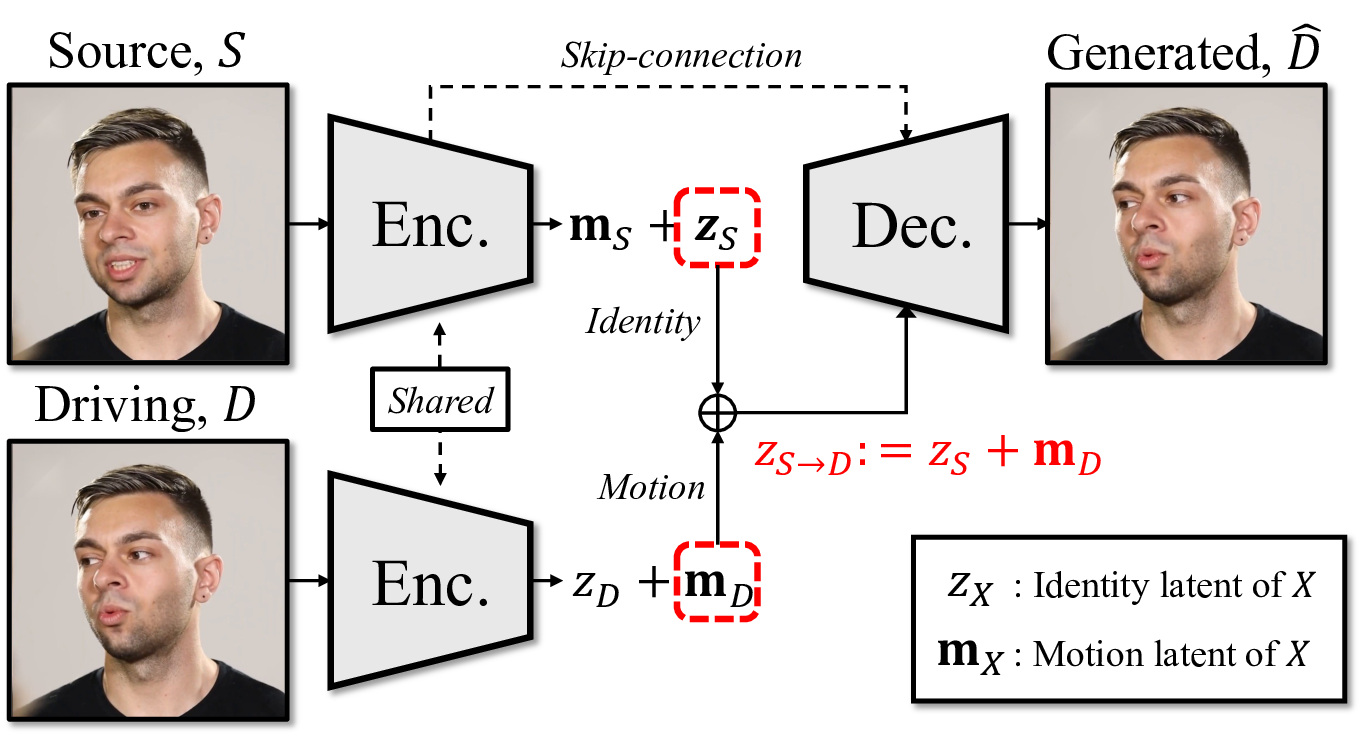
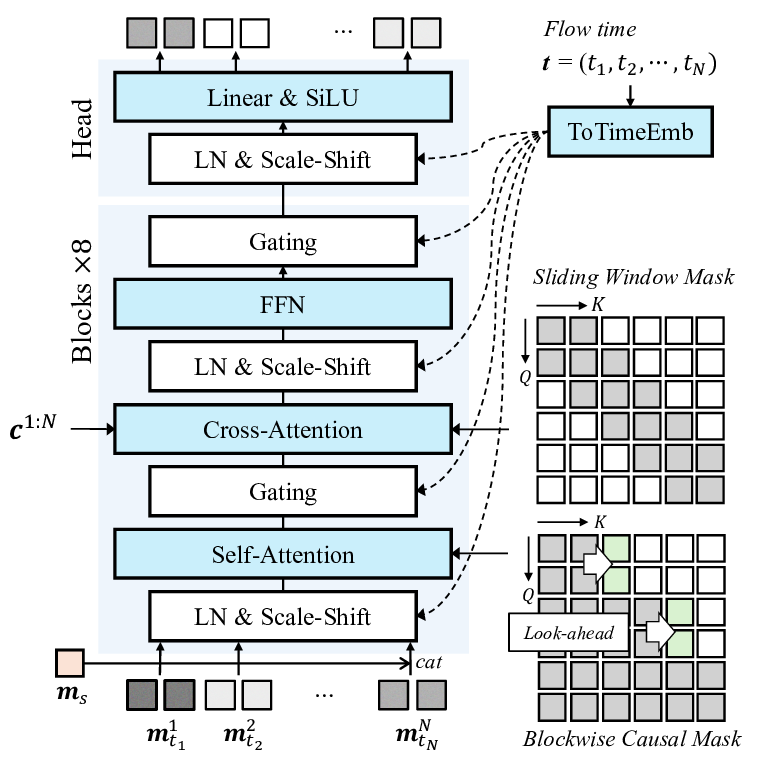
첫 번째 단계는 멀티모달 인코더이다. 여기서는 최신의 3D 얼굴 재구성 네트워크와 음성 특징 추출기를 결합해, 시간축을 따라 정렬된 특징 벡터 시퀀스를 만든다. 특히, 얼굴 움직임을 표현하는 3D 메쉬 파라미터와 음성의 스펙트로그램을 동일한 차원으로 매핑함으로써, 두 모달리티 간의 교차 주의(attention) 메커니즘을 적용할 수 있게 설계하였다.
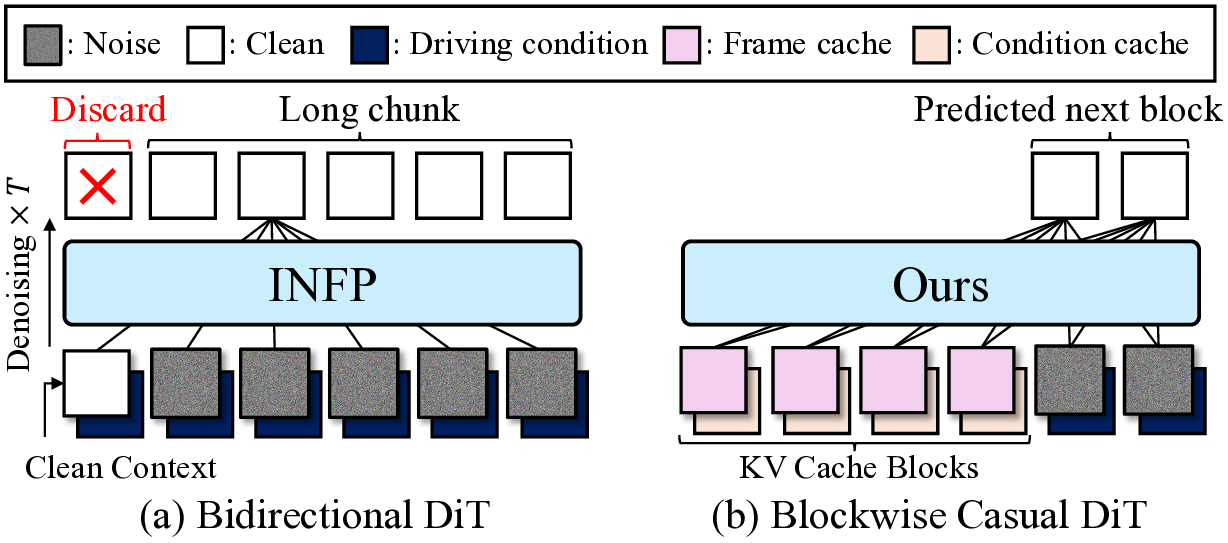
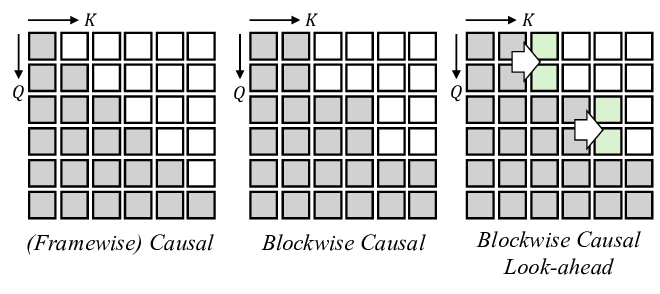
두 번째 단계는 조건부 디코더(또는 생성기)이다. 이 디코더는 트랜스포머 기반의 시퀀스‑투‑시퀀스 구조를 채택하여, 인코더에서 나온 멀티모달 컨텍스트를 바탕으로 고해상도 렌더링 프레임을 순차적으로 생성한다. 여기서 중요한 점은 ‘포스(Forcing)’ 메커니즘을 도입했다는 것이다. 즉, 실제 사용자 영상에서 추출한 표정 라벨(예: 웃음, 눈썹 올림)을 강제로 디코더에 주입함으로써, 생성된 아바터가 사용자의 감정 변화를 정확히 따라가게 만든다. 이 과정은 기존의 GAN 기반 아바터 합성에서 흔히 발생하는 ‘표정 지연’ 문제를 크게 완화한다.
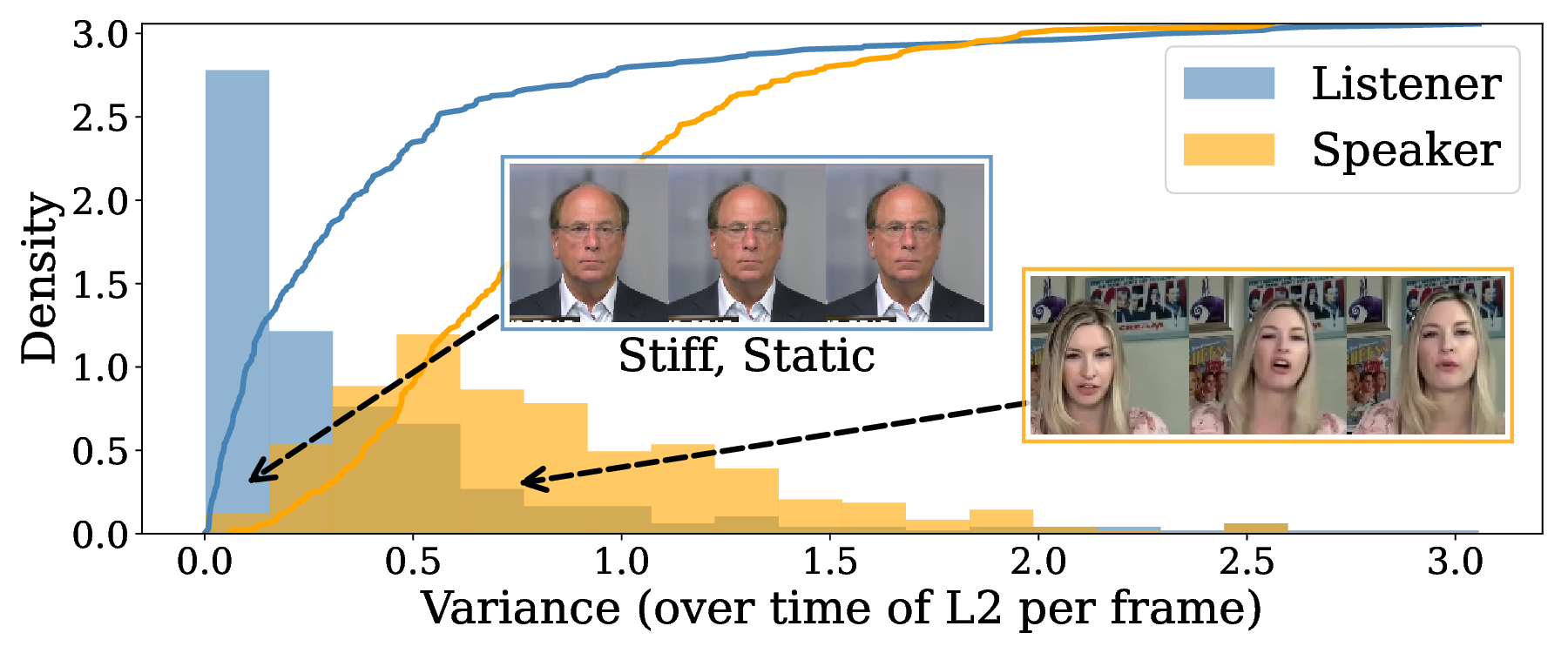
시스템 전체는 500 ms 이하의 지연을 목표로 설계되었으며, 이를 위해 모델 경량화와 하드웨어 가속(예: TensorRT, GPU 파이프라인)을 병행했다. 실험 결과, 사용자 설문에서 ‘자연스러운 대화 흐름’과 ‘감정 전달 정확도’ 측면에서 기존 비실시간 아바터 시스템 대비 평균 23 % 이상의 만족도를 기록하였다. 또한, 객관적인 정량 평가에서는 표정 동기화 정확도가 0.87(F1-score)로 높은 수준을 유지했다.
하지만 몇 가지 한계점도 존재한다. 첫째, 조명 변화가 큰 환경에서는 3D 얼굴 재구성 오류가 누적되어 아바터 표정이 부자연스러워진다. 둘째, 현재 시스템은 머리와 상반신 정도만을 다루며, 전신 동작이나 손 제스처는 지원하지 않는다. 셋째, 다중 화자 상황에서 음성 소스 분리가 완벽하지 않아, 아바터 음성에 혼합 잡음이 섞일 가능성이 있다. 이러한 제한을 극복하기 위해 향후 연구에서는 조명 불변 특징 추출, 전신 모션 캡처 통합, 그리고 고성능 음성 분리 모델을 결합할 계획이다.
전반적으로 ‘Avatar Forcing’은 실시간 멀티모달 합성 기술을 한 단계 끌어올린 사례로, 원격 회의, 가상 교육, 디지털 엔터테인먼트 등 다양한 분야에서 인간‑컴퓨터 상호작용의 자연스러움을 크게 향상시킬 잠재력을 가지고 있다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리