- Title: A Comprehensive Dataset for Human vs. AI Generated Image Detection
- ArXiv ID: 2601.00553
- 발행일: 2026-01-02
- 저자: Rajarshi Roy, Nasrin Imanpour, Ashhar Aziz, Shashwat Bajpai, Gurpreet Singh, Shwetangshu Biswas, Kapil Wanaskar, Parth Patwa, Subhankar Ghosh, Shreyas Dixit, Nilesh Ranjan Pal, Vipula Rawte, Ritvik Garimella, Gaytri Jena, Vasu Sharma, Vinija Jain, Aman Chadha, Aishwarya Naresh Reganti, Amitava Das
📝 초록
이 논문에서는 AI 생성 이미지 감지를 위한 대규모 데이터셋을 소개합니다. 이 데이터셋은 실제 및 합성 이미지-캡션 쌍 96,000개를 포함하며, 합성 이미지는 여러 생성 모델로부터 생성되었습니다. 우리는 이 데이터셋 기반의 두 가지 작업을 제안하고 있습니다: AI 생성 이미지와 실제 이미지를 구분하는 이진 분류 작업과 특정 생성 모델을 식별하는 작업입니다.
💡 논문 해설
1. **데이터셋 개발**: "이 논문은 AI 생성 이미지 감지를 위한 데이터셋을 만드는 것에 초점을 맞춥니다. 이를 위해 실제 캡션을 가진 이미지와 같은 캡션으로 생성된 합성 이미지를 대규모로 수집했습니다. 이는 마치 공정한 시험에서 참가자들이 동일한 문제를 받는 것과 같습니다."
2. **이론적 기여**: "데이터셋은 AI 생성 이미지를 감지하는 두 가지 작업을 제안합니다: 실제와 합성 이미지를 구분하고, 합성 이미지를 생성한 모델을 식별하는 것입니다. 이는 마치 진품과 가짜를 구분하면서 동시에 어떤 회사에서 만든 가짜인지 알아내는 것과 같습니다."
3. **기술적 기여**: "기본적인 분류 방법으로 ResNet-50을 사용하여 합성 이미지 감지를 시도했습니다. 이는 마치 빛의 파장에 따라 물체를 구분하는 현미경처럼 작동합니다."
📄 논문 발췌 (ArXiv Source)
\[email=royrajarshi0123@gmail.com\]
AI 생성 이미지 , 감지 기법 , 합성 미디어 , 생성 AI , 다중 모달 AI
style=“width:85.0%” />
서론
Stable Diffusion, DALL-E 및 MidJourney와 같은 생성 AI 기술은 합성 시각 콘텐츠 생산을 혁신적으로 바꾸었습니다. 이러한 도구는 고급 신경망 구조를 사용하여 광범위한 분야에서 다양한 응용 프로그램을 가능하게 합니다. 그러나 창의적 표현에 기여하는 동일한 혁신이 잘못 사용될 경우 중요한 위험 요소가 됩니다. 예를 들어, 오해하거나 해로운 콘텐츠의 확산은 공공 논의를 교란하고 신뢰성을 훼손할 수 있습니다.
최근 주목받는 사건들은 AI 생성 이미지의 사회적 영향을 보여주었습니다. 공황을 일으키는 가짜 묘사부터 여론을 바꾸려는 정치적으로 충격적인 시각물까지, 이미지 생성 모델의 급속한 발전은 합성과 실제 이미지 사이의 경계를 희미하게 만들고 전통적인 감지 방법을 도전하며 오보와 싸우는 노력을 복잡하게 만들었습니다.
이러한 문제에 대처하기 위해 효과적인 감지 기법 개발 및 평가를 지원하는 강력한 데이터셋이 필요합니다. 본 논문에서는 AI 생성 이미지의 감지 및 분석을 위한 특별히 정리된 데이터셋을 소개합니다. 우리 데이터셋은 다양한 생성 모델로부터 생성된 이미지와 실제 세계 이미지를 결합하고, 출처 모델, 생성 시간 표시기 및 관련 컨텍스트 메타데이터를 포함한 상세 주석으로 풍부하게 합니다.
우리 데이터셋은 대규모, 대표적인 벤치마크를 제공하여 합성 미디어 감지 연구를 진전시키고 AI로 인한 오보에 대한 확장 가능한 반대책 개발을 촉진하려는 목표입니다. Defactify 워크샵 시리즈와 같은 이니셔티브가 마련한 기초 위에 건설되어, 학술적 탐구와 실용적인 구현 사이의 간극을 메우고 디지털 정보 생태계의 정확성을 보호하려는 연구자, 정책 입안자 및 산업 관계자를 위한 귀중한 자원을 제공합니다. 이 작업은 AI 생성 텍스트 감지에 대한 병행 노력과 상보적입니다.
관련 연구
생성 모델의 급속한 성장으로 인해 실제 이미지와 구별하기 어려운 높은 수준의 사실적인 AI 생성 이미지가 만들어졌습니다. 본 절에서는 기존 데이터셋 및 감지 방법을 검토합니다.
AI 생성 이미지 데이터셋
다양한 데이터셋이 AI 생성 이미지 감지를 위해 소개되었습니다:
WildFake: 여러 오픈 소스 플랫폼에서 수집된 가짜 이미지를 포함하며, GANs와 확산 모델을 포괄하는 다양한 범주를 커버합니다. 그러나 통제되지 않은 수집은 혼합된 이미지 품질과 실제 및 합성 샘플 간의 불일치로 인해 생성자 아트팩터와 콘텐츠 차이를 구별하기 어렵게 합니다.
GenImage: AI 생성 및 실제 이미지 쌍으로 구성된 백만 단위 벤치마크를 구축했습니다. 규모가 크지만, 주로 오래된 생성자 모델을 특징으로 하며 현대 확산 모델을 연구하는 데 필요한 세부 모델 라벨이 부족합니다.
TWIGMA: 트위터에서 80만 개 이상의 AI 생성 이미지를 수집하고 트윗 텍스트 및 참여 메트릭과 같은 메타데이터를 제공합니다. 실제 세상 공유 패턴을 연구하는 데 유용하지만, 소셜 미디어로부터 얻은 이미지는 압축 아트팩터가 있으며 제한된 생성 설정이 있습니다.
Fake2M: 200만 개 이상의 이미지를 조립하고 인간들이 AI 생성 이미지 중 38.7%를 잘못 분류하는 것을 발견했습니다. 그러나 이 데이터셋은 캡션과 일치하지 않는 실제 및 합성 쌍을 제공하지 않아 동일한 텍스트 프롬프트에 대한 다양한 생성자 해석을 연구할 수 없습니다.
공통된 한계는 세미언틱 대응이 부족하다는 것입니다. 실제와 합성 이미지가 같은 텍스트 설명을 공유해야 합니다. 이러한 대응은 내용 편향과 생성 아트팩터를 구별하는 데 필요합니다. 또한, 오픈 소스 (Stable Diffusion) 및 클로즈드 소스(DALL-E, MidJourney) 생성자 모두를 포괄하거나 견고성 테스트를 위한 변동을 포함하는 데이터셋이 거의 없습니다.
감지 방법
다양한 접근 방식이 AI 생성 이미지를 감지하기 위해 제안되었습니다:
CLIP 기반 감지 : CLIP을 혼합된 실제/합성 데이터에 대해 미세 조정하면 AI 생성 이미지를 효과적으로 감지할 수 있습니다. 그러나 이러한 방법은 특정 생성자에 과적합되며 보이지 않는 모델에서 생성된 이미지에 대해서는 성능이 저하됩니다.
하이브리드 특징 기법: 고수준의 의미적 특징과 낮은 수준의 노이즈 패턴을 결합하면 제너레이터 간 성능이 개선됩니다. 하지만 많은 감지기들은 장면 유형이나 객체 빈도와 같은 단순한 단서에 의존하는 것으로 나타났습니다.
주파수 영역 분석: 합성 이미지가 독특한 주파수 패턴을 가짐을 보여줍니다. GAN 생성 콘텐츠에는 효과적이나 확산 모델은 약한 주파수 아트팩터를 생성하므로 새로운 감지 방식이 필요합니다.
워터마크 기반 감지: 워터마크 기반 방법이 변동에 대해 수동 감지기보다 우월함을 보여줍니다. 그러나 워터마킹은 제너레이터의 협력을 요구하며 내장된 워터마크가 없는 모델에서는 실패합니다.
최근 연구는 텍스트-이미지 생성기의 체계적인 벤치마킹에 초점을 맞추었습니다. CLIP 유사성, LPIPS 및 FID를 사용하는 통합 평가 프레임워크를 제시하여 구조화된 프롬프트가 다양한 아키텍처에서 생성 품질을 어떻게 영향시키는지 보여줍니다.
우리의 데이터셋은 다섯 개의 현대적 생성자 (Stable Diffusion 3, Stable Diffusion 2.1, SDXL, DALL-E 3, MidJourney v6)로부터 캡션과 일치하는 실제 및 합성 이미지를 제공하며 모델 귀속 라벨과 견고성 평가를 위한 체계적인 변동을 포함합니다.
데이터셋
이 절에서는 데이터셋 생성 과정과 분석에 대해 설명합니다.
이미지 생성 및 주석
우리의 데이터셋은 MS COCO 데이터셋을 기반으로 합니다. 이는 고품질 실제 이미지와 인간이 작성한 캡션을 제공합니다. 우리는 MS COCO 데이터셋에서 무작위로 16k 이미지-캡션 쌍을 샘플링했습니다. 각 캡션은 다섯 가지 이미지 생성 모델 (Stable Diffusion 3, Stable Diffusion 2.1, SDXL, DALL-E 3, MidJourney v6)에 대한 텍스트 시드로 사용되어 합성 이미지를 생성합니다. 각 캡션마다 각 모델은 하나의 합성 이미지를 생성하여 다중 소스의 AI 생성 샘플을 수집했습니다.
모든 실제 이미지는 MS COCO에서 직접 원본이고, 모든 캡션은 원래 데이터셋에 의해 작성된 인간 주석가가 작성되었습니다. 자동 캡션 또는 추가 주석 단계는 사용되지 않았습니다. 모든 생성 이미지는 AI로만 생성되었으며 실제 부분에는 오직 인간이 촬영한 사진들만 포함됩니다.
변형
견고성 및 불변성 연구를 위해 각 합성 이미지에 대해 네 가지 독립적인 변환을 사용하여 변형된 버전을 만듭니다:
수평 반전 – 이미지를 표준 수평 거울링.
밝기 감소 – 이미지 밝기를 $`0.5`$ 배로 조정.
가우시안 노이즈 – 표준 편차 $`\sigma = 0.05`$를 가진 가우시안 노이즈 추가.
JPEG 압축 – 이미지를 품질 요소 $`50`$으로 재인코딩.
각 변형은 별도로 적용되어 각 기본 이미지의 독립된 확장 버전을 생성합니다. 복합 또는 연속 변형은 적용되지 않습니다.
데이터 구조
수집 후, 데이터셋은 다음과 같은 필드를 포함하는 표준화된 스키마로 구성됩니다:
id — 각 샘플의 고유 식별자.
image — 실제 또는 모델 생성 이미지.
caption — 원래 MS COCO 캡션.
label_1 — 이미지가 실제 (0)인지 AI 생성 (1)인지를 나타내는 이진 라벨.
label_2 — 특정 생성 모델(SD 3, SDXL, SD 2.1, DALL-E 3 또는 MidJourney 6)을 나타내는 범주형 라벨.
모든 이미지는 동일한 원래 해상도에서 생성되거나 수집되었으며 저장하기 전에 리사이징이나 정규화가 수행되지 않습니다. 데이터셋 샘플은 fig:teaser[fig:teaser] 참조>에서 제공됩니다.
데이터 분석
데이터셋에는 96,000개의 이미지-캡션 쌍이 포함되어 있으며 학습(42,000), 검증(9,000), 테스트(45,000) 하위 집합으로 나뉩니다. 표 tab:dataset_stats는 출처별 분포를 요약합니다.
Source
Count
Real (MS COCO)
16,000
SD 2.1
16,000
SDXL
16,000
SD 3
16,000
DALL-E 3
16,000
MidJourney v6
16,000
Total
96,000
MS COCOAI 데이터셋에서 출처별 이미지 분포.
모든 캡션은 MS COCO에서 원래 제공되었으므로 그 특징적인 스타일을 따릅니다: 간결하고 설명적인 문장입니다. 표 tab:caption_stats는 캡션 길이 통계를 제공합니다.
Statistic
Value
최소 단어 수
7
최대 단어 수
34
평균 단어 수
10.37
중앙값 단어 수
10
캡션 길이 통계 (단어 수).
그림 fig:wordcloud_all은 데이터셋의 모든 캡션에 대한 워드 클라우드를 제공합니다. 시각화는 풍부한 의미적 다양성을 드러냅니다. 주요 용어는 여러 개념 범주를 가로지르고 있습니다: 도시 환경 (스트리트, 빌딩, 시티, 트래픽), 실내 공간 (itchens, bathroom, toilet, sink), 야생 동물 (giraffe, cat, dog, bird, sheep), 교통수단 (train, bus, motorcycle, airplane, car), 인간 주제 (man, woman, people, group), 색상 기술자 (white, black, red, blue, green) 및 공간 관계 (front, top, side, large, small). 이 광범위한 의미적 커버리지는 생성 모델이 다양한 시각 개념을 평가하도록 하여 감지 성능의 도메인 특정 편향 위험을 줄입니다.
style="width:90.0%" />
데이터셋 내 모든 캡션의 워드 클라우드 시각화. 단어 크기는 용어 빈도를 나타내며, 코퍼스 전체에서 의미 분포를 드러냅니다. 주요 용어는 일상적인 장면, 일반 물체, 동물, 인간 활동 및 색상 설명자에 대한 포괄적인 커버리지를 반영합니다.
작업 A (이진 분류): 주어진 이미지가 AI 생성인지 실제 세계에서 캡처되었는지를 구분하는 것.
작업 B (모델 식별): 특정 생성 모델(SD 3, SDXL, SD 2.1, DALL-E 3 또는 MidJourney 6)이 주어진 합성 이미지를 생성한 것을 식별하는 것.
베이스라인
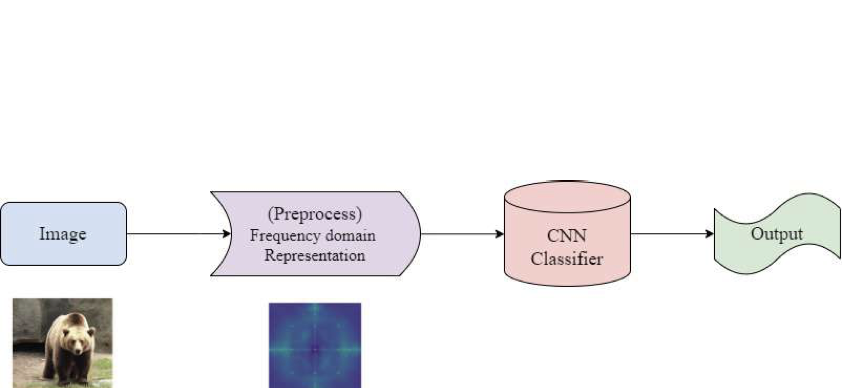
베이스라인을 설정하기 위해 주파수 도메인에서의 이미지 표현을 사용하여 ResNet-50 분류기를 훈련시킵니다. 이 주파수 도메인 표현은 제안된 방법론에 영감을 받아 사전 처리 전략을 적용함으로써 생성됩니다. 이러한 변환은 합성 이미지에 종종 나타나는 미세한 아트팩터를 드러내기 위해 글로벌 주파수 특성을 포착합니다.
전체 파이프라인은 그림 fig:baseline_pipeline에 설명되어 있습니다. 입력 이미지를 시작으로, 우리는 2D 푸리에 변환을 사용하여 이를 주파수 도메인으로 전환합니다. 결과 표현은 ResNet-50 CNN 모델로 전달되며 이 모델은 이미지를 6개 클래스 (실제 및 각 이미지 생성 모델당 하나의 클래스) 중 하나로 분류하도록 훈련됩니다.
이 베이스라인은 주파수 기반 특징의 효능을 평가함으로써 더 복잡한 기법과 비교할 수 있는 기준점을 제공합니다.
style=“width:90.0%” />
결과
베이스라인 성능 지표는 표 tab:baseline-results에 주어져 있으며, 진위 감지 및 모델 귀속 작업에 대한 벤치마크를 설정합니다. 이후 연구 개발의 참조점으로 기능합니다.
Task
Description
Baseline Score
Task A
각 이미지를 AI 생성 또는 인간이 만든 것인지 분류하기
0.80144
Task B
주어진 합성 이미지가 어떤 특정 모델에 의해 생성되었는지를 결정하기
0.44913
공유 작업의 두 가지 작업에 대한 베이스라인 결과.
작업 A (AI 생성 이미지와 인간이 만든 콘텐츠를 구분하는 이진 분류)에서 베이스라인 접근 방식은 0.80144 점을 얻습니다. 작업 B (AI 생성 이미지를 생성한 특정 생성 모델 식별)에서는 베이스라인 방법론이 0.44913 점을 얻었습니다.
이러한 베이스라인 점수는 두 가지 작업 간의 상당한 난이도 차이를 강조하며, 모델 귀속이 이진 진위 감지보다 훨씬 어려운 문제임을 보여줍니다. 성능 격차는 복잡성이 더 큰 다중 클래스 분류 시나리오를 나타내며 데이터셋은 고급 감지 및 귀속 방법론 개발에 대한 엄격한 벤치마크로 설정됩니다.
결론
이 논문에서는 AI 생성 이미지 감지를 위한 96,000개의 실제와 합성 이미지-캡션 쌍을 포함하는 대규모 데이터셋을 발표합니다. 이 데이터셋의 주요 특징 중 하나는 세미언틱 대응입니다 - 모든 합성 이미지는 실제 동반 이미지와 동일한 캡션으로 생성되어 내용 편향과 생성 아트팩터를 구별할 수 있는 통제된 연구가 가능합니다.
우리는 이 데이터셋 기반의 두 가지 작업을 제안하고 있습니다: 작업 A (AI 생성 이미지와 실제 이미지를 구분하는 이진 분류) 및 작업 B (특정 생성 모델 식별). 우리의 베이스라인은 ResNet-50으로 작업 A에서 점수 0.80을 달성하여 단순한 접근 방식으로도 이진 감지가 가능함을 보여줍니다. 그러나 작업 B에서 0.45의 베이스라인 점수는 모델 귀속이 훨씬 더 어려운 문제임을 나타냅니다.
미래 연구 방향에는 모델 귀속을 위한 고급 지문 기법 개발, 캡션-이미지 관계를 활용하는 크로스 모달 학습 접근 방법 탐색 및 감지 성능 향상을 위한 추가적인 작업들이 포함됩니다.