- Title: Avatar Forcing Real-Time Interactive Head Avatar Generation for Natural Conversation
- ArXiv ID: 2601.00664
- 발행일: 2026-01-02
- 저자: Taekyung Ki, Sangwon Jang, Jaehyeong Jo, Jaehong Yoon, Sung Ju Hwang
📝 초록
대화형 아바타 생성은 정적인 초상화에서 가상 커뮤니케이션 및 콘텐츠 제작을 위한 실감나는 아바타를 생성합니다. 하지만 현재 모델들은 진정한 상호 작용의 느낌을 전달하지 못하며, 종종 감정적 관여가 부족한 일방통행 응답을 생성합니다. 우리는 진정한 상호 작용 아바타로 나아가는 두 가지 주요 과제를 식별하였습니다: 인과 제약 하에서 실시간 동작 생성 및 추가 라벨 데이터 없이 표현력 있고 활기찬 반응 학습입니다. 이러한 과제들을 해결하기 위해, 저희는 확산 강제를 통해 사용자와 아바타 간의 실시간 상호 작용을 모델링하는 새로운 프레임워크인 아바타 강제(Avatar Forcing)를 제안합니다. 이 디자인은 음성과 동작을 포함한 사용자의 다중 입력을 저 지연으로 처리하여 말, 고개 끄덕임, 웃음 등 언어적 및 비언어적 시그널에 대한 즉각적인 반응을 가능하게 합니다. 또한 저희는 사용자 조건을 제거하여 구성된 합성 손실 샘플을 활용하는 직접 선호도 최적화 방법을 소개합니다. 이는 라벨 없는 표현력 있는 상호 작용 학습을 가능케 합니다. 실험 결과는 우리의 프레임워크가 저 지연(약 500ms)의 실시간 상호 작용을 가능하게 하며, 기준선에 비해 6.8배 빠른 속도를 달성하고, 반응적이고 표현력 있는 아바타 동작을 생성함으로써 기준선 대비 80% 이상 선호되는 결과를 보여줍니다.
💡 논문 해설
1. **실시간 반응형 아바타 생성**: 기존의 아바타는 사용자의 입력을 받고 나서 응답하는데 시간이 걸렸지만, 이 논문에서는 사용자의 실시간 입력에 즉시 반응하는 아바타를 만드는 방법을 제안합니다. 이를 위해 'Avatar Forcing'이라는 프레임워크를 도입하여, 과거 정보를 활용해 현재의 상황에 맞게 아바타를 조작할 수 있습니다. 이는 마치 실시간으로 대화를 나누는 것처럼 자연스러운 반응을 가능하게 합니다.
표현력 향상: 아바타가 사용자의 말이나 표정에 따라 적절한 반응을 보이게 하는 것이 쉽지 않습니다. 하지만 이 논문에서는 이러한 표현력을 개선하는 방법을 제시합니다. ‘Direct Preference Optimization’이라는 기법을 활용하여, 아바타의 동작을 더 다양하고 자연스럽게 만들어 사용자와의 상호 작용을 향상시키는 데 도움이 됩니다.
두 사람 간 대화 모델링: 이 논문은 두 사람이 실제로 대화하는 것처럼 아바타가 반응할 수 있는 방법을 연구합니다. 이를 위해, 말하는 사람과 듣는 사람의 역할에 따라 서로 다른 동작을 보이는 프레임워크를 만듭니다.
📄 논문 발췌 (ArXiv Source)
# 소개
토킹 헤드 생성은 정적 포트레이트 이미지를 실제와 같은 아바타로 애니메이션화하여 인간처럼 말하게 합니다. 이러한 시스템은 가상 프레젠터, 호스트 및 교육자 등을 만들기 위해 사용되며, 다양한 상황에서 실제 인체의 존재를 대신할 수 있습니다. 또한 사용자가 상호 작용할 수 있는 맞춤형 아바타도 지원하며, 예를 들어 선호하는 캐릭터와 대화하거나 콘텐츠 제작 및 시각적 커뮤니케이션에 유용한 도구로 활용됩니다.
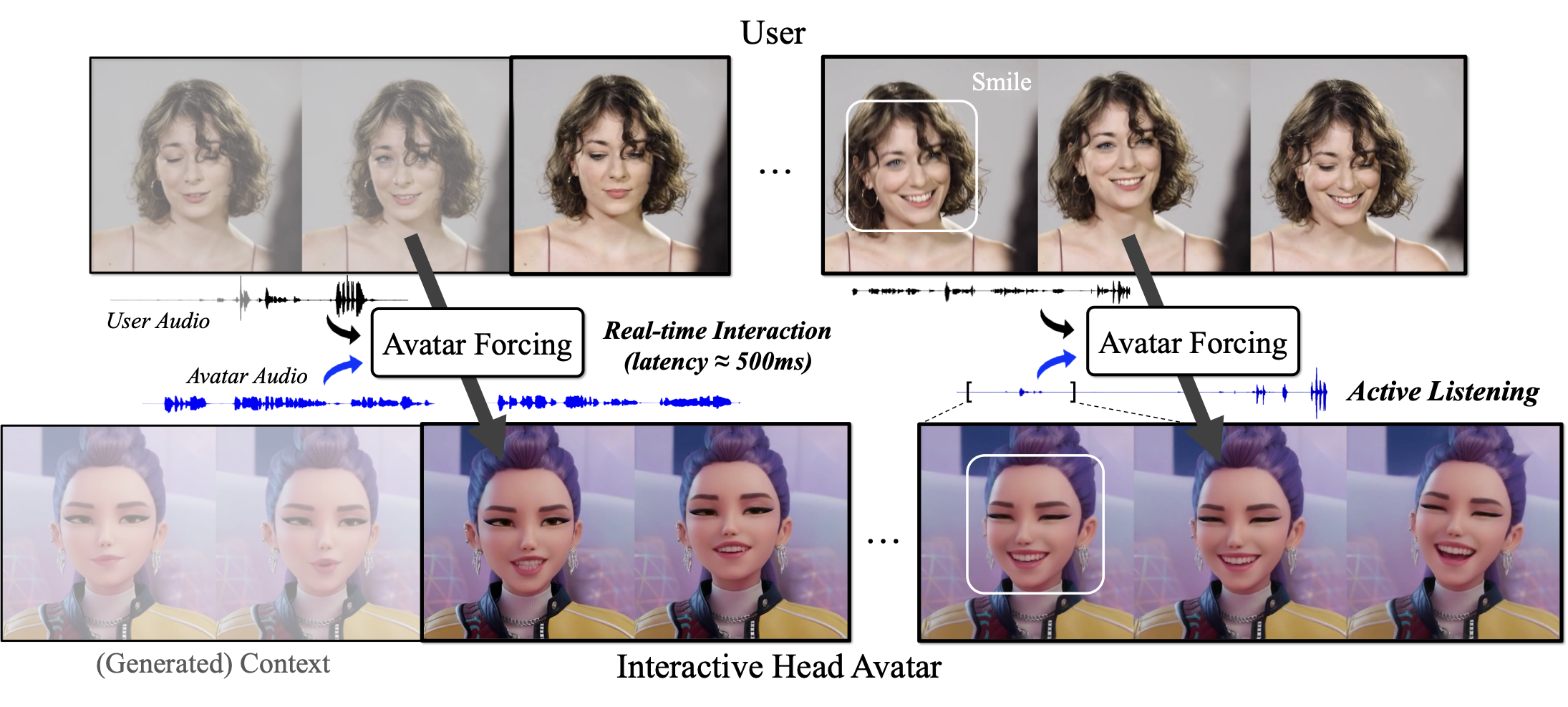
그러나 현재의 아바타 생성 모델은 실제 얼굴-대-얼굴 상호 작용의 느낌을 완벽히 재현하지 못합니다. 이들은 주로 오디오와 동기화된 입술 움직임이나 자연스러운 머리 움직임에 초점을 맞추어 정보를 정확하고 자연스럽게 전달하려고 노력하지만, 상호 작용적인 대화에는 참여하지 않습니다. 이러한 일방통행의 상호 작용은 실제 대화에서 중요한 역할을 하는 언어적 및 비언어적 신호의 지속적인 교환과 같은 양방향 성격을 간과합니다. 예를 들어, 고개 끄덕이기나 공감에 대한 반응과 같은 능동적인 청취 행동은 말하는 사람에게 계속하도록 장려하고, 미소 짓거나 눈을 마주치는 것과 같은 표현적인 발화 행동은 더 현실적이고 몰입도가 높은 대화를 돕습니다.
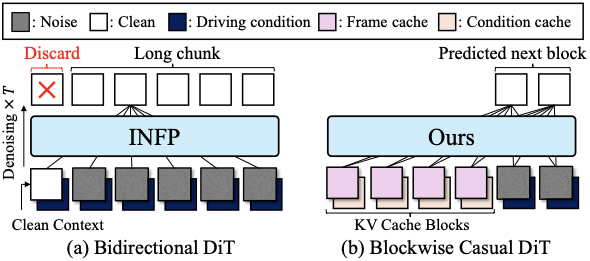
우리는 진정으로 상호 작용할 수 있는 아바타 생성의 두 가지 주요 도전 과제를 식별합니다. 첫 번째 도전 과제는 사용자의 다중 모달 입력을 실시간 처리하는 것입니다. 상호 작용형 아바타 시스템은 말하기, 머리 움직임 및 표정과 같은 사용자의 다중 모달 신호를 지속적으로 수신하고 응답해야 하며 이는 추론 시간이 짧고 지연 시간이 최소화되어야 합니다. 기존 방법들은 모션 잠재 공간에서 빠른 추론을 달성하지만, 전체 대화 맥락(예: 3초 이상)을 포함하는 미래 프레임까지 필요하기 때문에 지연 시간이 높습니다. 모델은 움직임 생성에 충분히 긴 오디오 세그먼트를 기다려야 하므로 사용자 상호 작용에서 눈에 띄는 지연이 발생합니다.
3. 이는 즉시 실시간 입력에 반응하는 인과적 움직임 생성 프레임워크의 필요성을 강조합니다.
두 번째 도전 과제는 표현력 있고 활기찬 상호 작용형 움직임을 학습하는 것입니다. 인간 간의 상호 작용에서 표현성은 정의하거나 애노테이션하기가 본질적으로 어렵고, 잘 관리되지 않은 데이터로 인해 자연스러운 상호 작용 행동을 모델링하는 것이 어려워집니다. 특히 청취 행동에 대한 훈련 데이터 대부분은 덜 표현적이고 변동성이 낮으며, 자주 경직된 자세를 보입니다.
5. 또한 입술 동기화와 달리 아바타 오디오와 밀접하게 연결되어 상대적으로 쉽게 학습할 수 있지만, 사용자 신호에 적절히 반응하는 것은 다양한 가능성 있는 움직임을 대응해야 하므로 모호성이 매우 높아져 학습 어려움이 증가하고 특히 비언어적 신호에 대해 덜 다양하고 경직된 움직임을 보이는 경우가 많습니다.
이러한 도전 과제를 해결하기 위해, 우리는 새로운 상호 작용형 머리 아바타 생성 프레임워크 Avatar Forcing을 제시합니다. 이는 사용자와 아바타 간의 인과적 상호 작용을 학습된 모션 잠재 공간에서 모델링합니다. 최근 확산 강제를 기반으로 하는 상호 작용형 비디오 생성 모델에 영감을 받아, 인과적 확산 강제를 사용하여 실시간으로 다중 모달 사용자 입력을 처리하면서 동시에 인터랙티브 머리 움직임 잠재 공간을 생성합니다. 이전 접근 방식이 미래 대화 맥락을 필요로 했던 것과 달리
3, Avatar Forcing은 효율적으로 과거 정보를 재사용하여 키-값 캐싱을 통해 즉시 반응형 아바타 생성이 가능하도록 설계되었습니다.
더 나아가, 선호도 최적화 방법의 학습에서 패러다임에 따라 우리는 아바타 동작의 상호 작용성을 높이는 선호도 최적화 방법을 제안합니다. 사용자 신호를 무시하고 이를 덜 선호하는 샘플로 합성하여 표현력과 반응성이 크게 향상됩니다. 추가적인 인간 애노테이션이 필요 없이 자연스러운 상호 작용을 달성할 수 있습니다.
[fig:concept]. 결과적으로 Avatar Forcing은 더 자연스럽고 몰입도가 높은 인터랙티브 비디오를 생성합니다.
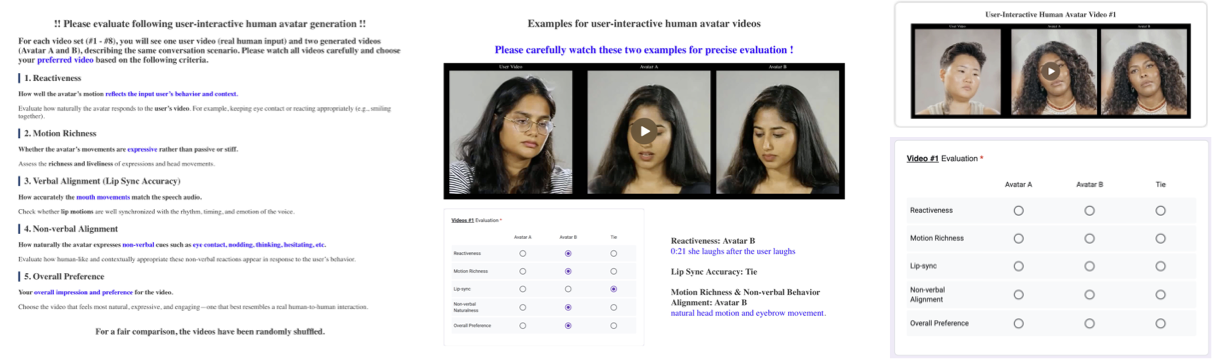
수많은 실험을 통해 Avatar Forcing이 약 500ms의 지연 시간으로 실시간 상호 작용을 지원한다는 것을 확인할 수 있습니다. 또한 제안된 선호도 최적화는 동작 반응성과 풍부함을 크게 개선하여 더 자연스럽고 몰입감 있는 비디오를 생성합니다. 인간 평가에서 우리의 방법은 가장 강력한 베이스라인보다 80% 이상 선호되어 자연스러움, 반응성 및 전반적인 상호 작용 품질 측면에서 명확한 우위를 보여줍니다.
관련 연구
토킹 아바타 생성
토킹 아바타 생성은 주어진 참조 이미지와 오디오로부터 실제와 같은 말하는 아바타 비디오를 생성합니다. 이 분야의 초기 방법들은 드라이빙 오디오로부터 정확한 입술 움직임을 합성하는 데 초점을 맞추었습니다.
이 접근 방식은 전체 머리 움직임, 리듬적인 머리 움직임 및 눈 깜빡임과 같은 생생한 얼굴 표정 생성으로 확장되었습니다. SadTalker는 예를 들어 비언어적 얼굴 표정을 중간 표현으로 사용하는 3D 모라블 모델(3DMM)을 활용합니다. EMO와 그 후속 모델들은 기초 이미지 확산 모델(예: StableDiffusion)을 사용하여 사진 같은 포트레이트 애니메이션을 생성했습니다. 최근 연구에서는
확산 모델 또는 흐름 일치를 학습된 움직임 공간에 도입하여 실시간 머리 움직임 생성을 달성했습니다.
청취 아바타 생성
다른 연구는 말하는 사람과 듣는 사람이 상호 작용하는 실제와 같은 청취 머리 움직임, 예를 들어 고개 끄덕이기나 집중 등을 생성합니다. 그러한 반응형 움직임을 생성하는 것은 어렵습니다. 말하는 사람과 듣는 사람 간의 관계가 본질적으로 일대다이며, 큐는 맥락에 따라 결정되고 약하게 감독되기 때문입니다.
따라서 대부분의 연구에서는 개인화된 청취 움직임을 생성하거나 명시적인 제어 신호를 활용하여 텍스트 지시문과 포즈 기준을 사용합니다.
이중 대화형 아바타 생성
최근 몇몇 연구는 두 참가자가 대화 상황에 참여하는 상호 작용 행동을 모델링하는 이중 동작 생성을 조사했습니다. DIM은 양자적 동작을 두 개의 분리된 잠재 공간으로 양자화합니다, 하나는 언어적이고 다른 하나는 비언어적인 것입니다. 그러나 이것은 두 공간 사이에 수동적으로 역할 전환 신호를 필요로 하므로 말하는 사람과 듣는 상태 간의 이행이 중단됩니다. INFP는 양방향 변환기가 전체 대화 맥락에 접근해야 하기 때문에 실시간 상호 작용 생성에는 적합하지 않습니다.
ARIG은 주로 얼굴 표정에 초점을 맞추는 은닉 3D 키포인트를 움직임 표현으로 생성합니다. 그러나 시간 일관성을 유지하는 데 어려움을 겪고 전체 머리 움직임을 생성하지 못합니다.
이 연구에서는 두 참가자가 언어적 및 비언어적 신호를 통해 서로 영향을 미치는 상호 작용 행동을 계속해서 모델링하는 것을 중점으로 합니다. 우리는 확산 강제 프레임워크를 사용하여 다중 모달 사용자 신호에 즉시 반응하는 전체적인 상호 작용 움직임, 예를 들어 말하기, 머리 움직임, 청취 및 집중을 생성합니다.
배경
확산 강제
확산 강제는 잡음이 있는 과거 토큰에 기반하여 다음 토큰을 예측하는 효율적인 순차적 생성 모델로 돋보입니다.
$`\mathbf{x}_1 = (x_1^{1}, x_1^2, \cdots, x_1^{N}) \in \mathbb{R}^{N \times 3 \times H \times W}`$
는 데이터 분포 $`p_1`$에서 샘플링된 $`N`$ 개의 토큰 시퀀스를 나타냅니다. 각 토큰은 토큰별 독립적인 노이즈 레벨
$`\boldsymbol{t}\coloneqq (t_1, t_2, \cdots, t_N) \in [0, 1]^{N}`$
을 통해 오염되어 독립적으로 노이즈가 있는 시퀀스
$`\mathbf{x}_{\mathbf{t}} \coloneqq (x^1_{t_1}, x^2_{t_2}, \cdots, x^N_{t_N})`$
를 형성합니다. 여기서 $`x^{n}_{t_n} = t_n x_1^{n} + (1-t_n)x_0^n`$이고
$`\mathbf{x}_0 = (x_0^{n})_{n=1}^{N}\sim p_0`$. 여기서 우리는 흐름 일치의 노이즈 스케줄러를 따릅니다. 확산 강제의 학습 목표는 벡터 필드 $`v_\theta`$가 대상 벡터 필드 $`v^n_{t_n} = x^n_1-x^n_0`$
에 수렴하도록 회귀하는 것입니다:
여기서 $`c`$는 조건, $`x^w`$와 $`x^l`$은 각각 선호 및 덜 선호 샘플을 나타내며, $`\pi_{\text{ref}}`$는 최적화 중에 동결된 참조 모델로 일반적으로 $`\pi_\theta`$의 사전 학습 가중치로 초기화됩니다. 여기서 $`\sigma(\cdot)`$은 시그모이드 함수이고, $`\beta`$는 편차 매개변수입니다.
DiffusionDPO는 확산 가능성을 사용하여 목적을 재정식화함으로써 선호도 최적화를 확산 모델에 확장합니다.
Avatar Forcing
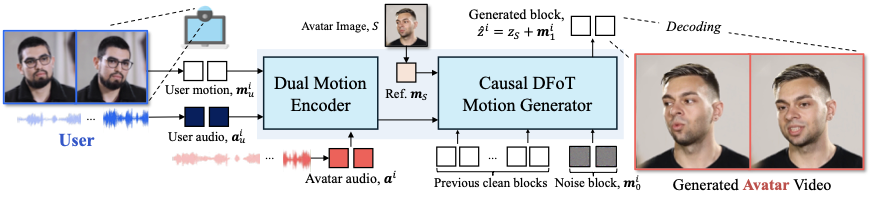
본 연구에서는Avatar Forcing을 제시합니다. 이는 사용자의 다중 모달 신호와 아바타 오디오에 조건부로 실시간 상호 작용형 머리 아바타 비디오를 생성하는 것입니다.
1.에서 우리의 프레임워크 개요를 제공합니다.
4.1에서는 모션 잠재 공간에서 인과적 확산 강제를 기반으로 실시간 상호 작용형 머리 아바타 생성을 달성하는 우리의 프레임워크에 대해 설명합니다. 이는 다중 모달 사용자 및 아바타 신호의 인코딩과 인과적 추론 두 가지 주요 단계로 구성됩니다.
4.2에서는 추가적인 인간 레이블 없이 표현력 있는 상호 작용을 강화하는 인터랙티브 동작 생성을 위한 선호도 최적화 방법을 소개합니다.
/>
Avatar Forcing의 전체 아키텍처. 우리는 사용자 동작 및 오디오와 아바타 오디오를 단일 조건으로 인코딩합니다. 인과적 모션 생성기는 아바타의 모션 잠재 블록을 추론한 후 이를 아바타 비디오로 디코딩합니다. style="width:49.0%" />
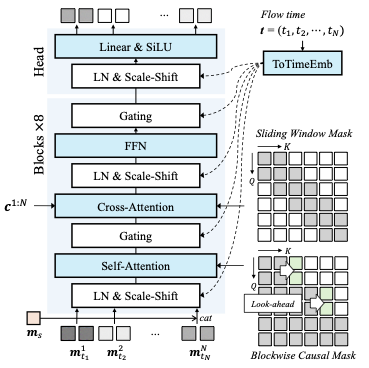
아키텍처의vθ. 예측 가능한 인과적 주의 마스크는 블록 간의 부드러운 전환을 가능하게 합니다.
실시간 상호 작용을 위한 확산 강제
모션 잠재 공간 인코딩
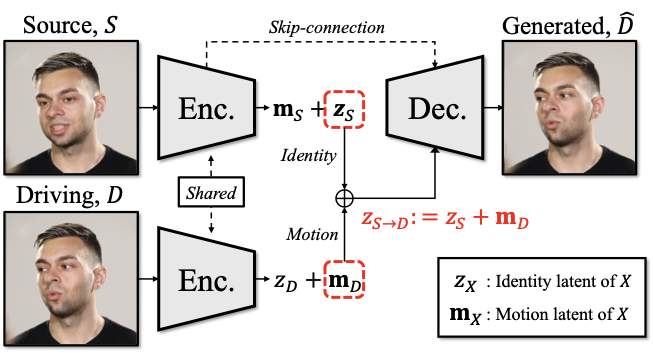
모션 인코딩을 위해, 우리는 .에서 사용된 모션 잠재 오토인코더를 활용합니다. 이 오토인코더는 입력 이미지
$`S\in\mathbb{R}^{3 \times\! H \!\times\! W}`$
로부터 ID와 움직임이 분해 가능한 잠재변수 $`z \in \mathbb{R}^d`$로 매핑합니다:
MATH
\begin{equation}
z = z_{S} + \mathbf{m}_S \in \mathbb{R}^d,
\end{equation}
클릭하여 더 보기
여기서 $`z_{S}\in\mathbb{R}^d`$와 $`\mathbf{m}_S\in\mathbb{R}^d`$
는 각각 ID 잠재변수 및 모션 잠재변수입니다. ID 잠재변수 $`z_S`$는 아바타 이미지의 ID 표현(예: 외관)을 인코딩하고, 움직임 잠재변수 $`\mathbf{m}_S`$
는 풍부한 언어적 및 비언어적 특성(예: 얼굴 표정, 머리 움직임)을 인코딩합니다. 우리는 이 잠재 표현을 사용하여 실제 아바타 생성에 중요한 전체 머리 움직임과 미세한 얼굴 표정을 포착합니다.
Appendix B에서 오토인코더에 대한 자세한 내용을 제공합니다.
상호 작용형 모션 생성
Avatar Forcing에서는 다중 모달 사용자 신호와 아바타 오디오를 조건으로 모션 잠재변수를 생성합니다. 이를 다음과 같이 자기회귀 모델로 정식화할 수 있습니다:
여기서 각 모션 잠재변수 $`\mathbf{m}^i`$
는 과거의 모션 잠재변수와 조건 트리플렛
$`\mathbf{c}^{i} = (\mathbf{a}_u^{i}, \mathbf{m}_u^i, \mathbf{a}^i)`$
에서 예측됩니다. 여기서 사용자 오디오 $`\mathbf{a}_u^{i}`$, 사용자 동작 $`\mathbf{m}_u^i`$ 및 아바타 오디오 $`\mathbf{a}^i`$를 포함합니다.
이 정식화 기반으로, 우리는 모션 잠재 공간에서 작용하는 인과적 모션 생성기를 도입합니다. 이는 벡터 필드 모델 $`v_\theta`$
을 사용하여 모델링됩니다.
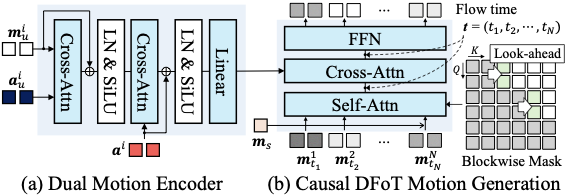
2에서 보듯이, 모델 $`v_\theta`$는 두 가지 주요 구성 요소로 구성됩니다: Dual Motion Encoder와 Causal DFoT Motion Generation.
Dual Motion Encoder의 목표는 다중 모달 사용자 신호와 아바타 오디오 간의 양방향 관계를 포착하고 이를 단일 조건으로 인코딩하는 것입니다.
2(a)에서 보듯이, 인코더는 먼저 사용자 신호($`\mathbf{m}^{i}_u`$ 및 $`\mathbf{a}^{i}_u`$)
를 교차 주의 층을 통해 정렬하여 전체 사용자 동작을 포착합니다. 이 표현은 다른 교차 주의 층을 통해 아바타 오디오와 통합되어 사용자와 아바타 간의 인과 관계를 학습하고 단일 사용자-아바타 조건을 생성합니다.
5.5에서 우리는 사용자의 동작 $`\mathbf{m}^{i}_u`$를 사용하여 상호 작용하는 아바타를 생성하는 데 중요한 역할을 하는지 경험적으로 검증합니다.
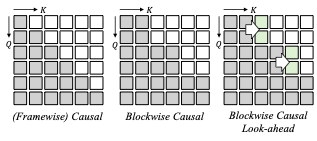
인과적 모션 생성기에서는 확산 강제 변환기(DFoT)와 블록별 인과 구조를 채택했습니다. 잠재 프레임은 지역적인 양방향 관계를 포착하기 위해 블록으로 나뉩니다.