- Title: QSLM A Performance- and Memory-aware Quantization Framework with Tiered Search Strategy for Spike-driven Language Models
- ArXiv ID: 2601.00679
- 발행일: 2026-01-02
- 저자: Rachmad Vidya Wicaksana Putra, Pasindu Wickramasinghe, Muhammad Shafique
📝 초록
대형 언어 모델(LLMs)과 스파이크 구동 언어 모델(SLMs)의 성능을 개선하고, 이를 임베디드 시스템에 효과적으로 구현하기 위한 양자화 기법에 대해 논한다. 본 연구에서는 SLMs의 메모리 및 에너지 효율성을 높이기 위해 자동화된 양자화 프레임워크인 QSLM을 제안하며, 이를 통해 SLMs의 성능과 메모리 요구사항을 충족시키는 효과적인 양자화 설정을 제공한다.
💡 논문 해설
1. **QSLM 프레임워크 소개**:
- QSLM은 대형 스파이크 구동 언어 모델(SLMs)의 메모리와 성능 요구사항에 맞춰 자동으로 양자화를 수행하는 새로운 프레임워크다. 이를 통해 SLMs는 임베디드 시스템에도 효과적으로 사용될 수 있다.
- **비교**: QSLM은 모델을 압축하는 과정에서 메모리 사용량을 최대 86.5%까지 줄이고, 에너지 소비를 최대 20%까지 감소시킨다.
네트워크 분석 및 양자화 검색 전략:
QSLM은 네트워크 구조를 분석하고 각 블록의 성능 민감도를 파악한다. 이를 기반으로 다양한 수준에서 자동으로 양자화를 수행하며, 최적의 설정을 선택한다.
비교: 이는 모델 별로 수작업이 필요했던 과거 방법과 달리, 자동화된 방식으로 효과적인 양자화 설정을 빠르게 찾아낼 수 있다.
최종 양자화 설정 선택:
QSLM은 성능 및 메모리 요구사항을 고려해 최적의 양자화 설정을 결정한다.
비교: 이는 다양한 모델과 다양한 성능, 메모리 제약 조건에 대해 자동으로 적합한 설정을 찾는 데 있어 큰 도움이 된다.
📄 논문 발췌 (ArXiv Source)
대형 언어 모델(LLMs), 스파이크 구동 언어 모델(SLMs),
양자화, 메모리 발자국, 임베디드 시스템, 설계 자동화.
서론
Transformer 기반 네트워크는 다양한 머신러닝(ML) 기반 응용 프로그램에서
상당한 성능 (예: 정확도)을 달성해 왔습니다. 특히 최근에는 transformer
기반 대형 언어 모델(LLMs)이 자연 언어 모델의 기능을 크게 향상시키면서,
입력에 대한 고품질의 언어 이해와 응답을 가능하게 했습니다. 따라서 이러한
모델은 자원 제약된 임베디드 장치에서 사용되길 원하는 수요가 많고, 이를
활용해 맞춤형 및 개인화 시스템을 구현하려는 노력이 활발히 진행되고
있습니다. 그러나 그들의 큰 계산 비용, 엄청난 메모리 발자국, 그리고 높은 처리
능력/에너지 소비는 임베디드 배포에 어려움을 주고 있습니다.
다른 한편으로, 스파이킹 신경망(SNNs)의 진전은 인공 신경망(ANN)
알고리즘에 대한 에너지 효율적인 대안을 제시하고 있습니다. 이는 희박한
스파이크 구동 연산 때문입니다. 따라서 최근 연구들은 LLMs에서 스파이크 구동
연산을 활용하여 처리 능력/에너지 요구사항을 줄이는 방법, 즉 *스파이크 구동 언어 모델(SLMs)*를 제안하고 있습니다; 참고
[[IMG_PROTECT_N]]. 그러나 그들의 메모리 발자국은 여전히 임베디드 배포에
적합하지 않습니다. 스파이크 구동 모델의 메모리 발자국을 줄이는 방법으로는
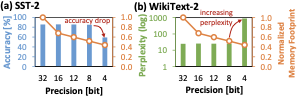
양자화가 주요한 방법 중 하나입니다. 양자화는 약간의 정확도 저하를 감수하고
메모리 발자국을 효과적으로 줄일 수 있습니다. 그러나 어떤 SLM에 대해
적절한 양자화 설정을 수동으로 결정하는 것은 대량의 디자인 시간과 많은 에너지 소비가 필요합니다. 따라서 이 접근법은 다양한 SLM들을 압축하기 위한 확장성이 어렵습니다. 게다가, 기존 ANN 양자화 프레임워크는 ANNs와 SNNs 간 합성곱 및 뉴런 연산의 근본적인 차이 때문에 직접 사용할 수 없습니다.
이러한 조건은 이 논문에서 다루려는 연구 문제로 이어집니다, 즉,
어떤 주어진 사전 훈련된 SLM을 효율적으로 양자화하면서 높은 성능(예: 정확도)과 메모리 제약 조건을 충족하는 방법은 무엇인가? 이 문제의 해결책은 효과적인 임베디드 구현을 위한 SLMs 설계 자동화를 앞당길 수 있습니다.
/>
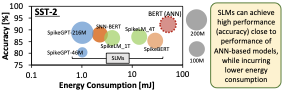
SST-2 데이터셋에서 감성 분석 작업의 성능(즉, 정확도), 가중치 매개변수의 수 (단위: 백만 [106] 개의 매개변수), 그리고 에너지 소비에 대한 SLMs의 현재 추세 .
SLMs의 최신 기술 및 제한점
SLMs 개발은 비교적 새로운 연구 분야이기 때문에, 현재의 최신 기술은 여전히 높은 성능(예: 정확도)을 달성하는 것에 중점을 두고 있습니다. 예를 들어 SpikeBERT, SpikingBERT, SNN-BERT, SpikeLM, SpikeLLM, 및 SpikeGPT가 있습니다. 특히, 스파이크 구동 BERTs는 ANN 영역의 BERT 네트워크를 기반으로 하며, 다양한 기법 (예: 지식 증류 및 입력 코딩 강화)을 사용해 스파이크 뉴런 동역학을 적용합니다. SpikeLM과 SpikeLLM은 스파이크 뉴런 동역학을 대형 모델(예: SpikeLLM의 경우 70억 개의 가중치 매개변수)에 확장하려고 합니다. 한편, SpikeGPT는 SLMs에서 계산 복잡도를 줄이는 동시에 높은 성능을 유지하기 위해 스파이크 구동 변환 모듈 대신 스파이크 구동 수용가중치 키 값(SRWKV) 모듈을 사용합니다. 이 최신 기술들은 SLMs의 양자화에 대한 종합적인 탐구가 이루어지지 않았음을 강조합니다.
사례 연구 및 연관된 연구 과제
/>
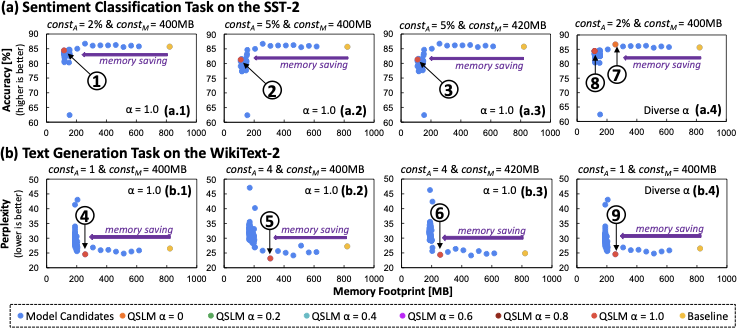
SpikeGPT-216M의 주의 블록에 걸쳐 균일한 가중치 매개변수 양자화를 적용하고, 이를 통해 수행된 감성 분류(SST-2 데이터셋)와 퍼플렉서티(WikiText-2 데이터셋) 평가 작업의 성능 프로파일. 퍼플렉서티 점수가 낮을수록 텍스트 생성 성능이 좋다는 의미이다.
SLMs 양자화의 가능성과 과제를 보여주기 위해 실험적 사례 연구를 수행한다. 여기에서 우리는 pre-trained SpikeGPT-216M에 균일한 양자화를 적용하고, 이를 통해 감성 분석(SST-2 데이터셋) 및 퍼플렉서티(WikiText-2 데이터셋) 평가 작업을 수행한다. 실험의 자세한 내용은
Sec. 4에 제공되며, 실험 결과는 Fig. 2에서 확인할 수 있다. 이러한 결과들은 후 훈련 양자화(PTQ) 방식이 적절한 양자화를 사용할 때 높은 성능을 유지하면서 메모리 감소에 큰 효과가 있음을 보여준다. 그렇지 않으면, 성능 저하가 발생한다.
또한 이러한 관찰은 다음과 같은 몇 가지 연구 과제를 드러낸다:
양자화 과정은 다양한 네트워크 복잡성 수준(예: 층의 수)을 효율적으로 처리해야 한다.
양자화 과정은 다양한 성능 및 메모리 제약 조건을 충족시켜야 하므로, 다양한 응용 프로그램에 실용적이다.
양자화 과정은 수작업의 개입을 최소화하여 다양한 네트워크, 성능 요구사항, 그리고 메모리 예산에 대해 확장성을 높여야 한다.
우리의 새로운 기여
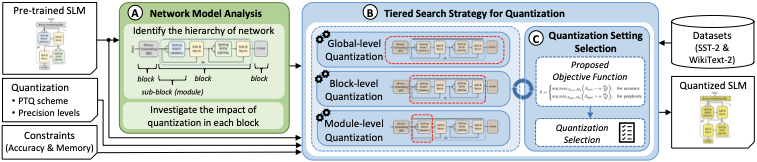
제안된 문제와 연구 과제를 해결하기 위해 QSLM이라는 새로운 프레임워크를 제안한다. QSLM은 사전 훈련된 스파이크 구동 언어 모델(SLM)을 압축하여 성능(예: 정확도)과 메모리 제약 조건을 충족시키는 자동 양자화를 수행한다. 이를 달성하기 위해 QSLM은 다음 주요 단계를 수행한다; 개요는 Fig. 3에 보여진다.
네트워크 모델 분석 (Sec. 3.1): 주어진 사전 훈련된 모델의 구조를 식별하고 양자화 검색을 위해 고려할 네트워크 계층을 결정하며, 각 네트워크 블록에 대한 성능 민감도(예: 정확도)를 조사한다.
계층적 검색 전략 (Sec. 3.2): 네트워크 계층과 민감도 분석에 기반하여 다양한 단계(예: 전체, 블록, 모듈 수준 양자화)에서 자동으로 양자화 및 평가를 수행하며 성능과 메모리 제약 조건을 고려한다.
양자화 설정 선택 (Sec. 3.3): 성능과 메모리 발자국에 기반한 후보의 이점을 측정하는 우리의 타협 함수를 활용해 최종 양자화 설정을 선택한다.
주요 결과: QSLM 프레임워크는 PyTorch로 구현되어 Nvidia RTX A6000 다중 GPU 머신에서 실행된다. 실험 결과 QSLM은 SLMs에 대한 효과적인 양자화 설정을 제공하며, 메모리 발자국을 최대 86.5%까지 줄이고, 에너지 소비를 최대 20%까지 감소시킨다. 또한 다양한 작업(예: SST-2의 감성 분류에서 최대 84.4% 정확도 및 WikiText-2의 텍스트 생성에서 23.2 퍼플렉서티 점수)에서 높은 성능을 유지하면서 성능과 메모리 제약 조건을 충족한다. 이러한 결과는 QSLM 프레임워크가 SLMs의 임베디드 구현을 가능하게 하는 잠재력을 보여준다.
/>
우리의 새로운 기여 개요.
배경
SNNs: SNN 모델 설계는 일반적으로 스파이크 뉴런, 네트워크 아키텍처, 신경/스파이크 코딩 및 학습 규칙을 포함한다. 최근 소프트웨어와 하드웨어를 통한 SNN의 발전은 다양한 저에너지 응용 사례에서 SNNs의 실용성을 높였습니다.
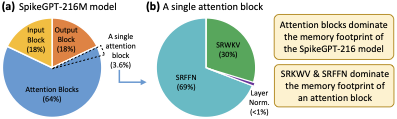
SLMs: SpikeBERT, SpikingBERT, SNN-BERT, SpikeLM, SpikeLLM 및 SpikeGPT 등 최근 연구에서는 여러 SLM을 제안하였습니다. 본 논문에서는 계산 복잡도가 낮아 에너지 소비가 적은 경쟁력을 갖춘 모델로 임베디드 시스템에서의 가능성을 확인하기 위해 SpikeGPT를 고려하였다; 참고
[[IMG_PROTECT_N]]. 구체적으로, SpikeGPT는 기존 자기 주의 메커니즘을 Spiking Receptance Weighted Key Value (SRWKV)와 Spiking Receptance Feed-Forward Networks (SRFFN)로 대체한다.
/>
SpikeGPT 아키텍처 개요. B는 주의 블록의 수를 나타냅니다.
예를 들어, 사전 훈련된 SpikeGPT-216M은 B=18 블록을 가지고 있습니다 . />
우리의 QSLM 프레임워크는 네트워크 모델 분석, 계층적 검색 전략 및 양자화 설정 선택을 포함하는 주요 단계를 보여줍니다.
SRWKV는 행렬-행렬 곱셈 대신 원소별 곱셈을 사용하여 자기 주의 메커니즘의 계산 비용을 줄입니다. 한편, SRFFN은 기존의 전방 네트워크(FFN)를 스파이크 호환 버전으로 대체합니다. 그 아키텍처는
Fig. 4에 설명되어 있으며, Table 13에서 요약되어 있습니다. 네트워크 레이어를 모두 통과한 데이터는 자연 언어 이해(NLU)를 위해 분류 헤드 또는 자연 언어 생성(NLG)을 위해 생성 헤드를 사용합니다.
SpikeGPT-216M의 아키텍처 계층 . 주의 매개변수 SRWKV에는 K, V, 및 R이 포함되어 있으며, 각각 Key, Value, 그리고 Receptance를 나타냅니다.
블록
SpikeGPT-216M의 아키텍처 계층 . 주의 매개변수 SRWKV에는 K, V, 및 R이 포함되어 있으며, 각각 Key, Value, 그리고 Receptance를 나타냅니다.
서브-블록
(모듈)
SpikeGPT-216M의 아키텍처 계층 . 주의 매개변수 SRWKV에는 K, V, 및 R이 포함되어 있으며, 각각 Key, Value, 그리고 Receptance를 나타냅니다.
매개변수의 수
양
SpikeGPT-216M의 아키텍처 계층 . 주의 매개변수 SRWKV에는 K, V, 및 R이 포함되어 있으며, 각각 Key, Value, 그리고 Receptance를 나타냅니다.
전체 매개변수의 수
Input
SpikeGPT-216M의 아키텍처 계층 . 주의 매개변수 SRWKV에는 K, V, 및 R이 포함되어 있으며, 각각 Key, Value, 그리고 Receptance를 나타냅니다.
Embedding
Layer Norm.
SpikeGPT-216M의 아키텍처 계층 . 주의 매개변수 SRWKV에는 K, V, 및 R이 포함되어 있으며, 각각 Key, Value, 그리고 Receptance를 나타냅니다.
 />
/>
 />
/>
 />
/>
 />
/>
 />
/>