- Title: Value Vision-Language-Action Planning & Search
- ArXiv ID: 2601.00969
- 발행일: 2026-01-02
- 저자: Ali Salamatian, Ke, Ren, Kieran Pattison, Cyrus Neary
📝 초록
> Vision-Language-Action(VLA) 모델은 로봇 조작에 강력한 일반화 정책으로 등장했지만, 행동 클로닝에 의존하기 때문에 분포 변동 시 민감하고 취약하다. 사전 훈련된 모델을 Monte Carlo Tree Search(MCTS)와 같은 검색 알고리즘으로 보완해도 VLA prior가 미래의 기대 수익률을 추정하는 데 부족함이 있어, 정확하지 않은 prior는 광범위한 시뮬레이션 없이는 행동 선택을 수정할 수 없다. 이를 해결하기 위해 우리는 Value Vision-Language-Action Planning and Search(V-VLAPS) 프레임워크를 도입하여 MCTS에 가벼운 학습 가능한 가치 함수를 추가한다. VLA 백본의 잠재 표현(Octo) 위에서 간단한 다층 퍼셉트론(MLP)을 훈련시켜 검색에 명시적인 성공 신호를 제공하고, 이를 통해 행동 선택이 높은 가치 영역으로 편향된다. LIBERO 로봇 조작 스위트에서 V-VLAPS를 평가한 결과, 우리의 가치 지향적 검색이 성공률을 5% 이상 향상시키고 MCTS 시뮬레이션의 평균 횟수를 5-15% 줄이는 것으로 나타났다.
💡 논문 해설
**3개의 핵심 기여:**
1. **가치 함수 도입:** VLA 모델이 미래 성공을 예측하는 데 부족함을 메꾸어, 가치 함수를 통해 행동 선택에 더 정확한 방향성을 제공한다.
2. **MCTS 개선:** MCTS 검색 알고리즘에 가치 함수를 통합하여 기존보다 효과적인 계획과 검색이 가능하다.
3. **성능 향상:** LIBERO 로봇 조작에서 성공률을 높이고 시뮬레이션 횟수를 줄여, 효율성을 크게 개선한다.
간단한 설명:
비교: VLA 모델은 카메라와 언어 지시를 통해 로봇에게 행동을 가르치는 방법이다. 그러나 그 자체로는 미래 성공을 예측하는 데 한계가 있다.
해결책: 이 논문에서는 MCTS 검색 알고리즘에 가치 함수를 추가하여, 로봇이 더 효과적으로 행동할 수 있도록 돕는다.
Sci-Tube 스타일 스크립트:
초급: “로봇에게 어떻게 행동하도록 가르칠까? 이 논문은 MCTS 검색 알고리즘에 가치 함수를 추가해 로봇이 더 똑똑하게 움직일 수 있게 한다.”
중급: “VLA 모델은 로봇을 가르치는 데 효과적이지만, 미래 성공 예측에서는 한계가 있다. MCTS 검색 알고리즘에 가치 함수를 추가하면 이 문제를 해결할 수 있다.”
고급: “분포 변동 시 VLA 모델의 민감성 문제를 해결하기 위해 V-VLAPS 프레임워크를 제안하고, 이를 통해 로봇 조작 성공률과 효율성이 크게 향상된다.”
📄 논문 발췌 (ArXiv Source)
maketitle 감사 aketitle
요약
Vision-Language-Action(VLA) 모델은 로봇 조작에 강력한 일반화 정책으로 등장했지만, 행동 클로닝에 의존하기 때문에 분포 변동 시 민감하고 취약하다. 사전 훈련된 모델을 Monte Carlo Tree Search(MCTS)와 같은 검색 알고리즘으로 보완해도 VLA prior가 미래의 기대 수익률을 추정하는 데 부족함이 있어, 정확하지 않은 prior는 광범위한 시뮬레이션 없이는 행동 선택을 수정할 수 없다. 이를 해결하기 위해 우리는 Value Vision-Language-Action Planning and Search(V-VLAPS) 프레임워크를 도입하여 MCTS에 가벼운 학습 가능한 가치 함수를 추가한다. VLA 백본의 잠재 표현(Octo) 위에서 간단한 다층 퍼셉트론(MLP)을 훈련시켜 검색에 명시적인 성공 신호를 제공하고, 이를 통해 행동 선택이 높은 가치 영역으로 편향된다. LIBERO 로봇 조작 스위트에서 V-VLAPS를 평가한 결과, 우리의 가치 지향적 검색이 성공률을 5% 이상 향상시키고 MCTS 시뮬레이션의 평균 횟수를 5-15% 줄이는 것으로 나타났다.
startsection section1@-2.0ex plus -0.5ex minus -.2ex1.5ex plus 0.3ex minus0.2ex
소개
로봇 정책을 오픈 월드 환경에 배포하려면 분포 변동 시의 신뢰성이 필요하다. 최근 로봇 학습의 진전은 대규모 VLA 모델, 즉 다중 모달 관찰과 언어 지시로부터 행동 순열을 예측하는 트랜스포머 정책을 통해 이루어졌다. VLA 모델은 일반화 동작에 대한 효과적인 prior로 작용하지만, 행동 클로닝에 의존하기 때문에 근본적으로 제한받는다. 이 결과 OOD 상태를 마주할 때 종종 취약한 동작을 보인다.
이 문제를 해결하는 유망한 접근 방법은 사전 훈련된 모델에 시뮬레이션에서 가능한 결과를 탐색하는 계획 검색 알고리즘을 추가하는 것이다. MCTS는 추정 트레일을 시뮬레이션하여 불확실한 행동의 탐색과 높은 가능성의 행동의 활용 사이의 균형을 이루는 검색 트리를 생성하는 알고리즘이다. VLA 모델을 prior로 사용하고 방문 수 기반 휴리스틱으로 탐색을 관리할 수 있지만, 이러한 접근 방법만으로는 강건한 장기 계획에 부족하다. 이 방식은 검색이 가치 함수를 갖지 않아 미래의 기대 수익률 추정치가 없다는 것을 의미한다. 따라서 VLA prior가 정확하지 않은 경우, 플래너는 광범위한 방문 수 기반 탐색을 통해만 이러한 편향을 수정할 수 있다.
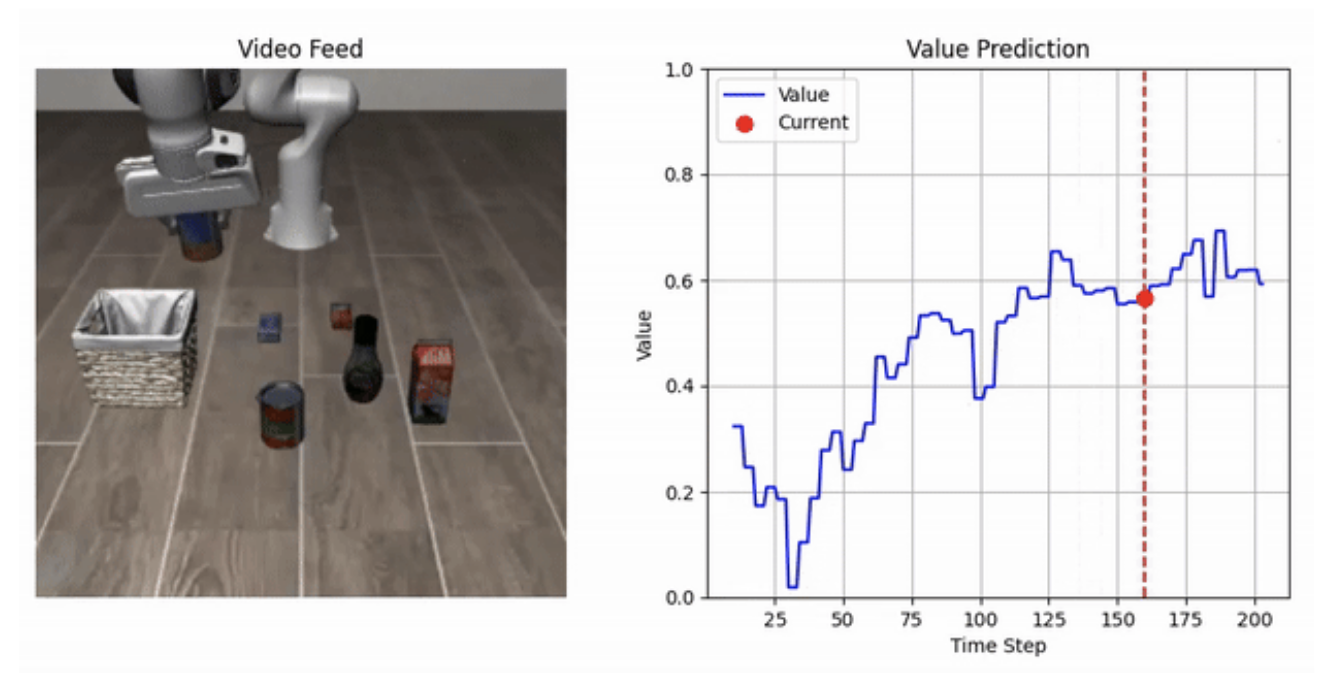
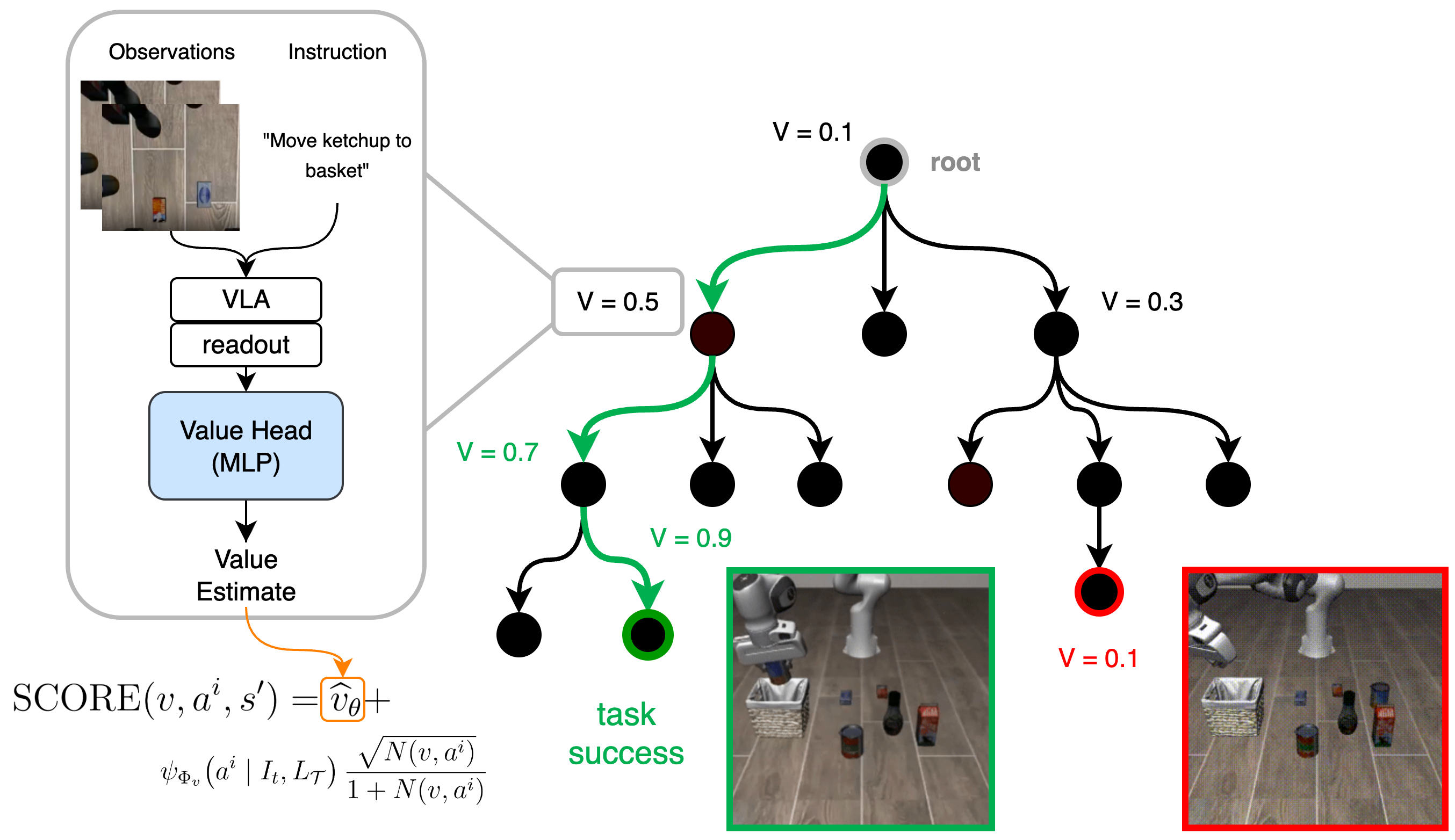
이 한계를 해결하기 위해 우리는 Value Vision-Language-Action Planning and Search(V-VLAPS)를 도입한다. 그림 1과 같이, MCTS 행동 선택에 가벼운 학습 가능한 가치 머리를 추가하여 검색에 부족한 보상 신호를 제공하고, 이는 prior 정책이 정확하지 않을 때 검색을 효과적으로 수정한다.
V-VLAPS의 개요. 각 MCTS 노드에서 현재 관찰과 언어 지시가 고정된 VLA 백본 및 우리의 가치 머리(MLP)를 통해 스칼라 값 추정치를 생성한다. 이 값은 해당 노드에 연결되고 VLAPS 점수 규칙에 사용되어 노드 선택을 편향시킨다. 높게 예측된 값의 노드는 더 자주 선택되며 성공적인 작업 완료로 이어지지만, 낮은 가치의 노드는 검색 중 가중치가 낮아진다.
startsection section1@-2.0ex plus -0.5ex minus -.2ex1.5ex plus 0.3ex minus0.2ex
관련 연구
[Title_Easy_KO]: 로봇 행동 개선: 가치 기반 검색
[Title_Easy_EN]: Improving Robot Actions with Value-Based Search