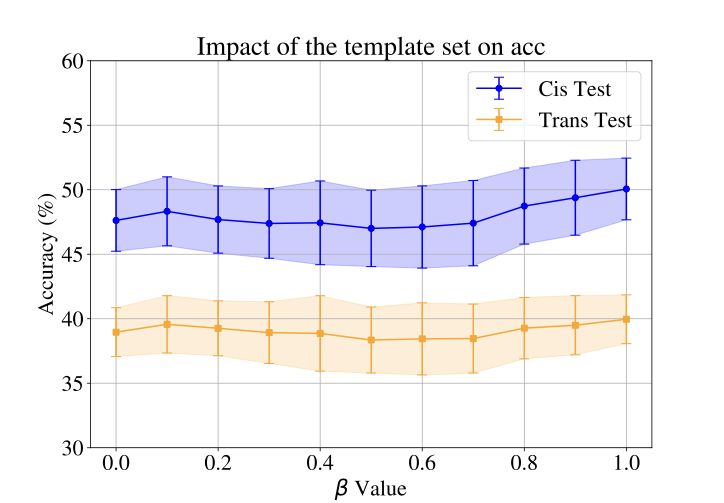
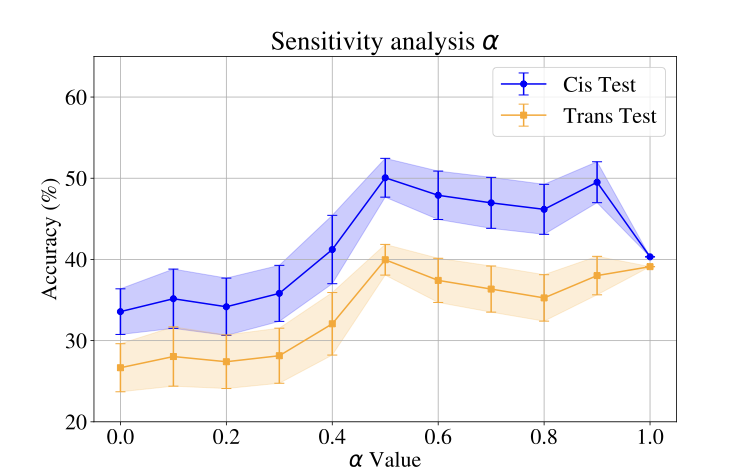
- Title: WildIng A Wildlife Image Invariant Representation Model for Geographical Domain Shift
- ArXiv ID: 2601.00993
- 발행일: 2026-01-02
- 저자: Julian D. Santamaria, Claudia Isaza, Jhony H. Giraldo
📝 초록
카메라 트랩 이미지는 야생동물 모니터링에서 가장 값진 데이터 소스 중 하나로, 생물다양성 보존과 기후 변화 연구에 중요한 역할을 합니다. 이러한 이미지들은 인간의 직접 개입 없이도 광범위한 데이터를 수집할 수 있는 비침해적이고 확장 가능한 방법을 제공합니다. 그러나 대규모 데이터셋에서 자동적인 동물 종 식별을 위한 기술은 필요합니다. 최근 연구에서는 Foundation Models (FMs)을 야생동물 모니터링에 적용하기 시작했으며, 이 모델들은 다양한 시각 인식 작업에서 뛰어난 성능을 보여주었습니다. 본 논문에서는 WildIng이라는 새로운 모델을 소개하며, 이 모델은 텍스트와 이미지를 통합하여 지리적 도메인 변동에 강한 특징을 추출합니다.
💡 논문 해설
1. **신규 모델: WildIng**
- WildIng은 야생동물 모니터링 데이터를 표현하는 새로운 방법으로, 텍스트와 이미지를 통합하여 지리적 도메인 변동에 강한 특징을 추출합니다.
- 이는 동물을 모니터링하는 데 있어 중요한 데이터 출처인 카메라 트랩 이미지에서 지리적 영역이 달라도 성능을 유지할 수 있게 합니다.
성능 향상
WildIng은 기존의 FMs보다 다른 지리적 지역에서 수집된 데이터셋에서도 더 나은 성능을 보여줍니다.
이는 모델이 다양한 배경과 조명, 동물 종류에 대한 변화를 잘 처리할 수 있다는 것을 의미합니다.
성분별 효과 검증
WildIng의 각 구성 요소가 얼마나 중요한지 확인하기 위해 세부 실험을 수행했습니다.
이를 통해 모델이 어떻게 작동하는지 더 깊게 이해할 수 있습니다.
Sci-Tube 스타일 스크립트 (한국어)
기초 레벨: WildIng은 야생동물을 관찰하고 보호하기 위한 새로운 카메라 트랩 모델입니다. 이 모델은 텍스트와 이미지를 결합하여 다양한 지리적 지역에서도 잘 작동합니다.
중급 레벨: WildIng은 텍스트와 이미지 정보를 사용해 야생동물의 행동 패턴을 분석하고, 이를 통해 다른 지리적 위치에서도 동물을 정확하게 식별할 수 있습니다. 이는 기존 모델보다 더 나은 성능을 보여줍니다.
고급 레벨: WildIng은 LLM과 VLM을 통합하여 텍스트와 이미지의 특징을 추출하고, 이를 통해 야생동물 모니터링 데이터셋에서 지리적 도메인 변동에 강한 성능을 제공합니다.
📄 논문 발췌 (ArXiv Source)
# 서론
카메라 트랩 이미지는 야생동물 모니터링에 있어 가장 값진 데이터 소스 중 하나로, 생물다양성 보존과 기후 변화 연구에서 중요한 역할을 합니다. 이러한 이미지들은 인간의 직접 개입 없이도 광범위한 데이터를 수집할 수 있는 비침해적이고 확장 가능한 방법을 제공합니다. 원격 지역에서 캡처되는 이들 이미지는 야생동물 모니터링 연구에 필수적인 도구가 됩니다. 수집된 대량의 이미지를 고려할 때, 이미지 내에 존재하는 동물 종 식별을 위한 자동 기술이 필요합니다.
대규모 딥러닝 모델의 등장과 함께 연구자들은 야생동물 모니터링에서 Foundation Models (FMs)을 사용하기 시작했습니다. FMs은 광범위하고 다양한 데이터셋에 대해 학습하며 때때로 수십억 개의 데이터 샘플이 포함되어 있어 풍부하고 전이 가능한 표현을 배울 수 있습니다. 이러한 모델들은 이미지 분류, 객체 탐지, 그리고 의미적 세분화와 같은 다양한 시각 인식 작업에서 뛰어난 성능을 보여주었습니다.
최근 연구자들은 FMs를 카메라 트랩 이미지 인식에 맞게 조정하기 시작했습니다. 이를 위해 모델을 처음부터 학습하는 대신, 이미 학습된 FMs를 미세 조정하거나 도메인 특화 지식을 통합하려고 합니다. 일부 방법은 어댑터를 도입하여 모델이 카메라 트랩 이미지에 특화되면서도 일반적인 지식을 잃지 않게 합니다. 다른 모델들은 학습 후 잊지 않기 전략을 사용하여 모델이 광범위한 능력을 유지하면서 야생동물 이미지에서 성능을 개선합니다. 또한 일부 접근법은 인터넷 데이터베이스와 같은 외부 지식 소스를 활용해 특정 동물 종과 그 특성에 대한 모델의 이해를 정교하게 합니다. 이러한 전략들은 FMs의 일반적인 지식과 카메라 트랩 이미지 인식의 특수한 요구 사항 사이의 간극을 메우려고 합니다.
이러한 FM 기반 접근법은 내부 지역 지리적 데이터(동일한 지리적 위치에서 온 데이터)에 대해 뛰어난 성능을 보여주지만, 외부 지역 지리적 데이터(훈련 및 테스트 데이터가 다른 지리적 위치에서 온 것)에서는 종종 어려움을 겪습니다. 이 제한은 특히 카메라 트랩 응용 프로그램에 있어 훈련 단계 동안 본 적이 없는 지리적 위치들 사이의 상당히 큰 차이가 있는 경우 문제가 됩니다.
우리는 카메라 트랩 이미지에 텍스트를 입력 표현에 포함시키는 것이 강력한 특징을 추출하고 지리적 도메인 변동 문제를 완화한다는 것을 관찰했습니다. 반면, 현재 모델들은 시각적인 특징만 의존하여 데이터 분포의 변화에 매우 민감합니다. 또한 이들 중 많은 모델은 CLIP 위에 구축되어 있으며, 이는 모델이 미세 조정될 때 일반화 능력을 잃고 더 쉽게 허위 상관관계에 노출되기 경향이 있습니다. 결과적으로 시각적 특징만을 의존하는 CLIP 기반 모델 (예: WildCLIP 및 BioCLIP)은 새로운 지리적 위치에서 이미지를 올바르게 인식하는 데 어려움을 겪습니다. [그림 1]은 이러한 관찰의 예를 제공하며, 이러한 지리적 변동이 모델의 학습된 특징이 효과적으로 일반화하지 못하도록 하여 오분류로 이어짐을 보여줍니다.
/>
WildIng과 WildCLIP[1] 사이의 지리적 도메인 변동 비교. 두 모델은 아프리카에서 온 Snapshot Serengeti 데이터셋을 학습하고 미국에서 온 Terra Incognita 데이터셋을 평가합니다. WildIng이 우수한 성능을 보여줍니다.
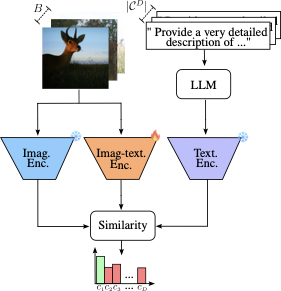
본 논문에서는 Wildlife image Invariant representation model for geographical domain shift (WildIng)를 소개합니다. 우리의 접근법은 지리적 도메인 변동에 대한 야생동물 모니터링 데이터의 새로운 표현을 간단하면서도 효과적으로 제시합니다. 이 표현은 입력 이미지에 대한 시각적 특징과 텍스트 설명을 사용하는 것을 포함합니다. 이를 통해 모델은 텍스트 설명을 활용하여 다양한 지리적 지역에서 일관된 특징을 캡처할 수 있습니다. WildIng은 세 가지 주요 구성 요소를 포함합니다: 텍스트 인코더, 대형 언어 모델 (LLM)을 포함; 이미지 인코더; 그리고 이미지-텍스트 인코더로, 비전-언어 모델 (VLM)과 다중 층 퍼셉트론 (MLP)이 포함되어 있습니다. MLP는 VLM 및 LLM 구성 요소가 도입하는 서로 다른 특징 공간으로 인해 발생하는 인코더 간의 도메인 변동을 해결하기 위해 사용됩니다. 아키텍처 개요는 [섹션 3.2]에서 제공되며 [그림 2]에 설명되어 있습니다.
WildIng을 평가하기 위해, 모델은 한 데이터셋에서 학습하고 다른 지리적 지역의 데이터셋에서 테스트합니다. 이 설정은 배경, 조명 및 종 구성의 차이로 인해 지리적 도메인 변동이 발생하는 새로운 환경에 어떻게 적응하는지를 분석할 수 있게 합니다. 우리의 결과는 WildIng이 특히 지리적 변화로 인해 학습 및 테스트 분포가 다를 때 일반적인 목적으로 사용되는 도메인 특화 FMs보다 우수하거나 경쟁력 있는 성능을 보여준다는 것을 나타냅니다.
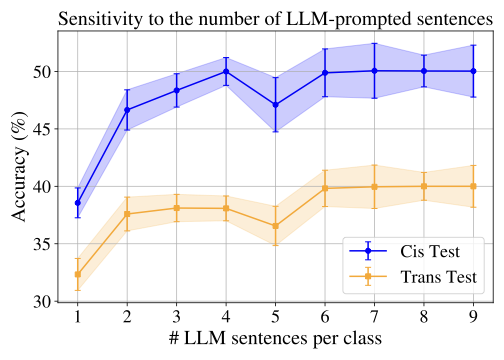
본 연구에서는 원래의 사전 연구에 기반하여 개선점을 제시합니다. 이를 위해 모델 아키텍처에 수정을 가하고 추가 실험을 수행했습니다. 구체적으로, 우리는 CLIP (Contrastive Language-Image Pre-Training)과 BERT (Bidirectional Encoder Representations from Transformers)의 조합을 Long-CLIP으로 바꾸었습니다. 또한 클래스 표현을 LLM에서 제공하는 정보만 사용하도록 수정했습니다. WildIng이 다양한 무작위 초기화에 대한 견고성을 평가하여 도입된 변화가 성능에 미치는 영향을 분석하고, 새로운 베이스라인을 추가하여 비교를 수행합니다. 마지막으로 추가적인 ablation 연구와 민감도 분석을 수행하여 접근법의 각 구성 요소가 어떻게 기여하는지 더 깊게 이해할 수 있게 합니다.
요약하자면, 주요 기여는 다음과 같습니다:
야생동물 모니터링 데이터를 표현하기 위해 새로운 WildIng 모델을 소개하여 지리적 도메인 변동에 강한 특징을 추출합니다.
다른 데이터셋으로 테스트했을 때, WildIng이 전반적으로 동물을 정확히 식별하는 데 기존 FMs보다 우수하거나 경쟁력을 갖추고 있습니다.
각 구성 요소의 효과를 검증하기 위해 일련의 ablation 연구를 수행했습니다.
관련 작업
Foundation Models
최근 몇 년 동안, FMs는 특화된 훈련 없이도 다양한 작업에서 뛰어난 성능을 보여주는 새로운 접근 방식으로 부상했습니다. 이러한 모델들은 대규모 사전 학습을 활용하여 고수준의 표현을 배우며, 이로 인해 머신러닝 분야에 큰 발전이 이루어졌습니다. 이 분야에서 주요 진보 중 하나는 CLIP였으며, 시각적 특징과 텍스트 설명 사이를 정렬하는 새로운 학습 접근 방식을 도입했습니다. CLIP은 다양한 작업에서 일반화 능력을 크게 향상시켰습니다. 이후 모델인 Long-CLIP은 더 나은 컨텍스트 이해를 위해 시퀀스 길이를 확장했습니다. CLIP-Adapter는 가볍게 수정된 레이어를 사용하여 CLIP의 학습된 표현을 정교하게 만들었습니다. 최근에는 LLMs과 VLMs가 텍스트와 시각적 콘텐츠 처리 및 생성에 강한 능력을 보여주고 있습니다.
Foundation Models for Biology
FMs는 복잡하고 특화된 데이터를 가진 생물학 연구에서 도메인 특정 문제 해결을 위해 적응되었습니다. 생물학에서 FM의 대부분의 적응은 텍스트 처리, 생물학적 정보 추출 및 생물학적 구조 모델링과 관련되어 있습니다. 언어 처리와 구조적 모델링 외에도 FMs는 시각 기반 생물학 작업에도 적용되었습니다. 예를 들어 BioCLIP은 CLIP의 원칙을 생물학 데이터에 확장하여 식물, 동물 및 곤충과 같은 다양한 범주의 분류가 가능하게 합니다.
Foundation Models for Camera Trap Images
FMs는 일반적인 목적으로 사용되는 것에서 넘어 카메라 트랩 이미지 인식에도 적응되어 야생동물 모니터링과 보존에 중요한 역할을 합니다. WildCLIP은 CLIP의 시각적 특징과 텍스트 설명 사이의 정렬 능력을 활용하여 카메라 트랩 이미지에서 동물을 정확히 분류합니다. WildMatch는 자세한 시각적 설명을 생성하고 외부 지식 기반에 매칭하는 제로샷 분류 프레임워크를 도입했습니다. Eco-VLM은 시각적 특징과 텍스트 설명 사이의 정렬을 개선하기 위해 야생동물 특정 데이터셋에서 미세 조정하고 텍스트 증강 기법을 적용합니다.