- Title: VEAT Quantifies Implicit Associations in Text-to-Video Generator Sora and Reveals Challenges in Bias Mitigation
- ArXiv ID: 2601.00996
- 발행일: 2026-01-02
- 저자: Yongxu Sun, Michael Saxon, Ian Yang, Anna-Maria Gueorguieva, Aylin Caliskan
📝 초록
텍스트-투-비디오(T2V) 생성기인 소라와 같은 시스템은 생성된 콘텐츠가 사회적 편견을 반영하는지에 대한 우려를 제기한다. 우리는 단어와 이미지에서 비디오로 임베딩 연관 검사를 확장하기 위해 비디오 임베딩 연관 검사(VEAT)와 싱글-카테고리 VEAT(SC-VEAT)를 도입한다. 이 방법들을 널리 사용되는 베이스라인, 특히 암묵적 연관 검사(IAT) 시나리오와 OASIS 이미지 카테고리로부터의 관계 방향과 크기를 재현함으로써 검증한다. 그런 다음 17개 직업과 7개 수상 분야에서 인종(아프리카 계 미국인 대 유럽계 미국인)과 성별(여성 대 남성)이 가치(기분 좋은 것 대 불쾌한 것)와 연관되는 정도를 측정한다. 소라 비디오는 유럽계 미국인과 여성들이 더 기분 좋게 인식된다(d>0.8). 효과 크기는 실제 세계의 인구 분포와 상관관계가 있다: 직업에서 남성과 백인이 차지하는 비율(r=0.93, r=0.83) 및 수상자들 중 남성과 흑인 비율이 아닌 사람들의 비율(r=0.88, r=0.99). 명시적인 디비어스 프롬프트를 적용하면 효과 크기의 크기가 일반적으로 줄지만 역효과를 초래할 수도 있다: 두 개의 흑인 관련 직업(청소원, 우편 서비스)은 디비어싱 이후 더 강하게 흑인 연관성이 증가한다. 이 결과들은 쉽게 접근 가능한 T2V 생성기가 철저히 평가되지 않고 책임감 있게 배치되지 않는 경우 표현적 피해를 실제로 확대할 수 있음을 보여준다.
💡 논문 해설
1. **비디오 임베딩 연관성 시험(VEAT) 개발**
이 연구에서는 VEAT와 SC-VEAT를 도입하여 텍스트에서 비디오로 생성된 모델의 편견을 측정할 수 있는 방법론을 제안합니다. 이를 통해 꽃과 곤충, 남성과 여성 등 다양한 그룹 간의 연관성을 정량화할 수 있습니다.
메타포 설명: 이 연구는 비디오를 보는 것과 마찬가지로, 편견을 측정하는 데 필요한 도구를 개발했다고 생각하면 됩니다. 이를 통해 우리는 다양한 그룹 간의 연관성을 쉽게 이해할 수 있습니다.
인종 및 성별 관련 편견 분석
이 연구에서는 여성과 백인이 더 긍정적인 연관성이 있음을 발견하였습니다. 또한 STEM 분야의 상과 직업에서 남성과 백인에 대한 연관성이 더 높은 것으로 나타났습니다.
메타포 설명: 이 연구는 사회에서 특정 그룹이 얼마나 긍정적으로 인식되는지 측정하는 작업과 같습니다. 이를 통해 우리는 사회적 편견의 양상을 이해할 수 있습니다.
프롬프트 기반 편견 완화 전략의 위험성
프롬프트를 사용하여 특정 그룹을 더 긍정적으로 연관시키려는 시도는 때로는 반대 효과를 초래할 수 있음을 발견하였습니다.
메타포 설명: 이 연구는 치료가 오히려 병을 악화시킬 수 있는 상황과 같습니다. 편견을 완화하려고 노력하는 과정에서 주의해야 할 위험성을 조사한 것입니다.
📄 논문 발췌 (ArXiv Source)
# 서론
style="width:100.0%" />
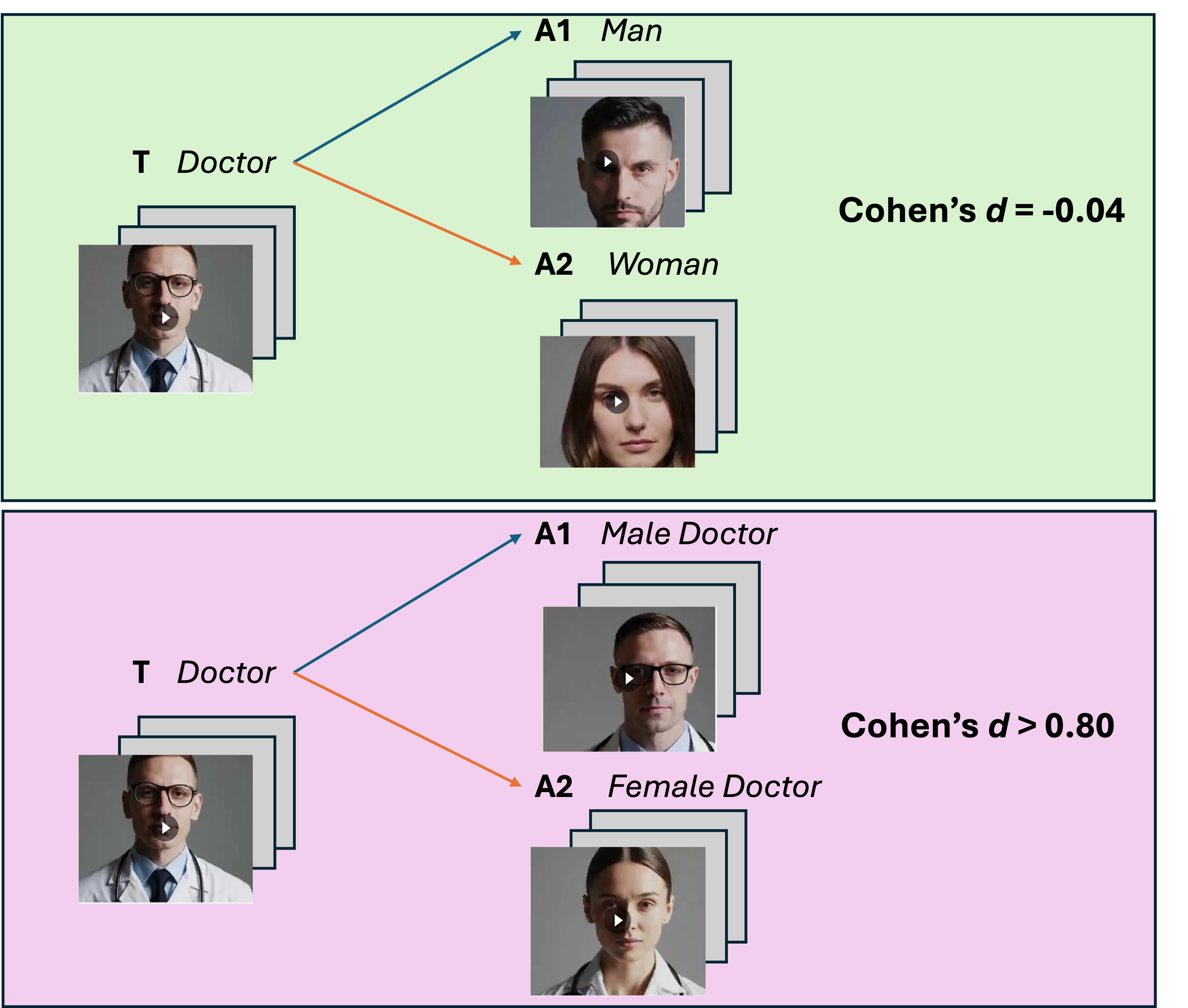
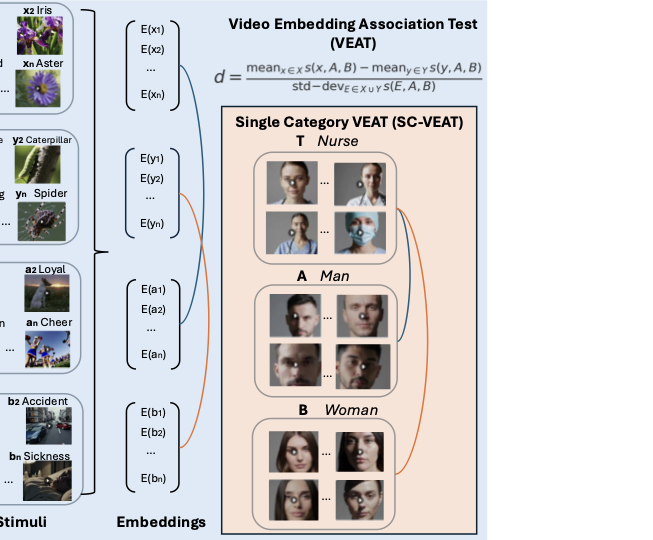
비디오 임베딩 연관성 테스트(VEAT)는 두 개의 대상 그룹과 두 개의 속성 그룹 사이의 연관성을 측정하며, 단일 카테고리 VEAT(SC-VEAT)는 단일 대상 그룹에 대해 두 개의 속성 집합을 평가합니다. 연관성 크기와 방향은 효과 크기(Cohen's d)를 사용하여 측정됩니다. 대상과 속성은 비사회적 개념(예: 꽃 vs 곤충), 사회적 그룹(남자 vs 여자), 직업(예: 간호사), 또는 가치감(쾌적한 vs 불쾌한)을 나타낼 수 있습니다. 각 대상과 속성 집합은 30개의 동영상으로 구성됩니다. 사람들을 포함하는 이미지는 블러 처리되어 있습니다.
텍스트에서 비디오로 생성(T2V) 모델이 사회적으로 점점 더 널리 사용됨에 따라, 이러한 모델에서 내재된 유해한 고정관념과 편견의 지속 가능성에 대한 우려가 증가하고 있습니다. 시각 언어 모델은 사회적 그룹에 관련된 인간 같은 편견을 학습하며, 이러한 편견은 취업, 교육, 그리고 사회적 상호작용과 같이 중요한 분야에서 차별적인 관행과 선입관을 강화할 수 있는 심각한 현실적 영향을 미칠 수 있습니다. 따라서 T2V 생성기의 편향 크기와 방향성을 정량적으로 평가하고 이를 완화하기 위한 잠재적인 방법을 탐색하는 것이 중요합니다. 이미지 모드에서 EATs가 연관성과 편견을 측정했지만, 동영상 모드로 확장되지 않았습니다. 우리는 Video Embedding Association Test (VEAT)와 Single-Category VEAT (SC-VEAT)를 소개하며, 이들은 임베딩을 사용하여 T2V 모델에서 편향 연관성을 정량적으로 측정합니다. 그림 1은 VEAT와 SC-VEAT가 대상과 속성 동영상 집합 사이의 연관성을 어떻게 측정하는지 보여줍니다.
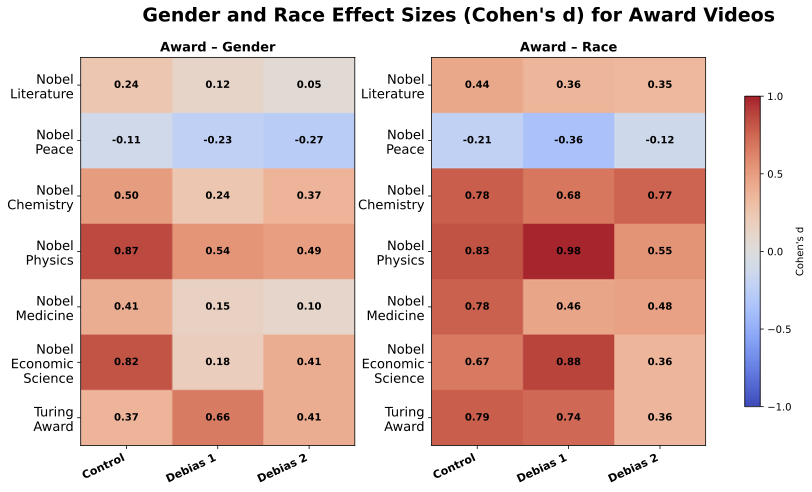
생산 모델이 점점 더 많이 사용되고 통합됨에 따라, 그룹을 부정적 태도와 연결함으로써 가치기반 편견을 강화할 수 있습니다. 가치감은 사람이나 물체에 대한 긍정성 또는 부정성을 의미합니다. 인간이 인식한 그룹의 가치감은 사회적 태도와 차별을 형성하는 데 중요한 역할을 하며, 가치기반 편견을 드라이브합니다. 우리는 T2V 생성에서 인종과 성별 관련 가치감 편향을 정량화하는 첫 번째 연구를 제시합니다. [^1] 명예직 및 상의 배제 또는 소수대표는 할당적 및 표현적 피해를 초래할 수 있으므로, 우리의 분석은 7개의 상과 17개의 직업에 대한 비디오에서 인종 및 성별 편향을 정량화하며, 이들에는 인종이나 성별에 관련된 고정관념이 기록되어 있습니다.
우리의 결과는 T2V 생성기의 편향 크기와 방향성이 인종과 성별에 대한 암묵적 연관성 시험(IAT), 텍스트 모드, 그리고 이미지 모드에서 기록된 것들과 일치함을 제시합니다. 이 연구의 다음과 같은 주요 기여를 강조합니다:
T2V 생성기 출력에서 연관성 정량화: VEAT와 SC-VEAT는 꽃과 곤충, 남자와 여자, 흑인과 백인 등의 비사회적 및 사회적 그룹, 그리고 긍정성과 부정성 같은 추상적인 개념에 대해 일반화 가능한 연관성 정량화 방법을 개발합니다. 우리는 미래의 연구가 우리의 접근법을 활용하여 T2V 출력에서 다차원적이고 교차적 편향 연관성을 연구할 것을 권장합니다.
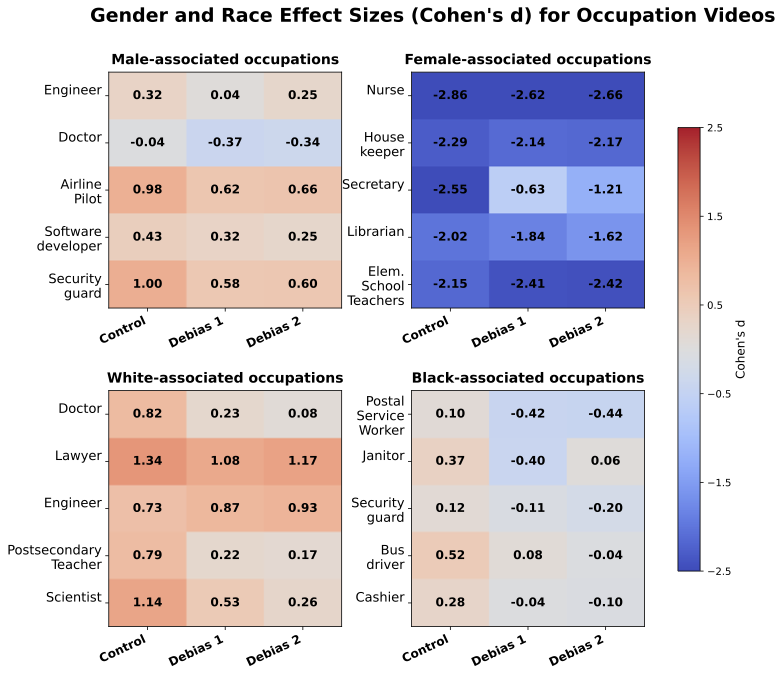
T2V 생성기 출력에서 인종 및 성별 편향 식별: 여성은 남성보다 긍정성이 더 강하게 연결되어 있습니다($`d>0.8`$), 그리고 유럽계 미국인은 흑인 아메리칸보다 긍정성이 더 강하게 연결되어 있습니다 ($`d>0.8`$). STEM 상들은 남성과 유럽계 미국인에게 더 많이 연결되어 있으며, 여성과 흑인 아메리칸에 비해 적게 연결되었습니다. 또한 효과 크기는 17개의 직업과 7개의 상에서 성별과 인종 인구 통계와 양적으로 관련되어 있습니다.
T2V 생성기에서 프롬프트 기반 편향 완화 전략 위험성: 우리는 LLM의 편향 감소 프롬프트를 T2V 생성에 적용하였으며, 이는 17개의 직업과 7개의 상에 대해 소수 그룹과 더 많이 연결되었습니다. 그러나 주요 그룹이 과도하게 대표되는 경우 편향을 줄이지만, 소수 그룹이 전형적으로 관련된 맥락에서는 편향을 증폭시킬 수 있습니다.
관련 작업
텍스트에서 비디오 생성 모델: 우리는 가장 고급화된 T2V 생성기인 OpenAI의 Sora를 연구합니다. Sora는 인터넷 규모 데이터로 일반적 기능을 습득하는 대형 언어 모델에서 영감을 받았습니다. 그러나 Sora는 토큰이 아닌 “시각 패치"에 의존합니다. 이러한 시각 패치들은 원래 비디오의 차원을 축소한 것으로, Sora가 공간-시간 종속성을 학습할 수 있게 합니다. Sora는 사회적 편향을 재현하는 인터넷 규모 데이터로 학습되었습니다.
다중 모달 생성기에서 편향 측정 및 완화: IAT는 인간의 암묵적 편향을 반응 시간 비교를 통해 측정합니다. WEAT는 IAT의 대상과 속성 자극을 임베딩 공간으로 확장하여 단어 임베딩에서 암묵적 연관성을 측정합니다. 이 접근법은 이미지 모드로 Image Embedding Association Test (iEAT)를 통해 확장되었습니다. 우리는 이를 T2V 생성에 대한 연관성 측정으로 확장하였습니다. 우리는 T2V 출력에서 암묵적 편향을 4가지 WEAT 시나리오로 연구했습니다. 우리는 도덕적으로 중립적인 시나리오(꽃 vs 곤충, 도구 vs 무기)에서 가치감 연관성을 측정하는 두 가지 WEAT 시나리오를 적응시켰습니다. 그런 다음 성별(Male vs Female 용어)과 인종(European American 이름 vs African American 이름) 편향을 관련된 생성 비디오의 가치감 속성에 대해 연구했습니다.
생산 모델은 사회적 그룹과 관련된 편향을 강화하는 것으로 발견되었습니다. 이미지 생성 모델은 “남성"과 관련된 이미지를 경력 관련 속성 이미지와 연결하고, “여성"과 관련된 이미지는 가족 관련 속성 이미지와 연결합니다. 이전 연구는 다중 모달 생성 시스템에서 편향을 측정하는 방법을 개발했지만, 우리의 연구는 비디오 모드에서 이러한 편향을 정량화한 첫 번째 연구입니다. 이전 연구에서는 언어 모델에 대한 프롬프트 기반 전략으로 편향을 측정하고 완화하는 방법을 연구했습니다. T2V 생성기의 편향 완화 전략을 연구한 연구는 거의 없습니다. 220억 개 이상의 모델 매개변수가 있는 LLM이 자체 수정 능력을 갖추었다고 제안되었습니다. 우리는 명시적 편향 감소 프롬프트가 T2V 출력에서 편향을 줄일 수 있는지 가설을 검증합니다. Sora는 전적으로 프롬프트 인터페이스를 통해만 접근 가능하며, 훈련 데이터나 모델 가중치에 대한 연구자의 접근이 제한되어 있습니다. 따라서 우리의 편향 완화 실험은 프롬프트 기반 전략에 한정됩니다.
데이터
우리는 Sora[^2]을 사용하여 3,660개의 비디오를 수집하였습니다. 이 데이터셋에는 122개의 비디오 집합으로 구성된 대상과 속성 비디오가 포함되어 있습니다. 각 집합은 30개의 비디오로 구성됩니다. Sora와 비디오 생성 프롬프트에 대한 설명은 부록 10.2을 참조하십시오. 우리는 측정한 암묵적 연관성을 4가지 IAT 시나리오에서 평가하였습니다. 또한 인종(European Americans와 African Americans)과 성별(Man과 Woman)에 대한 가치감 속성(Pleasant와 Unpleasant), 그리고 직업과 학술 상의 인종 및 성별 고정관념을 측정하기 위해 비디오를 평가하였습니다. 또한 편향 완화 전략을 탐색하기 위해 개발한 명시적 편향 감소 프롬프트를 포함하여 직업과 상에 대한 비디오 집합을 생성했습니다.
사회적 및 비사회적 개념의 비디오 생성
Open Affective Standardized Image Set (OASIS)은 다양한 인간, 동물, 물체, 그리고 장면을 포함하는 컬러 이미지와 인류 주석가들의 가치감 평가를 포함하고 있습니다. 우리는 OASIS에서 10개의 이미지 카테고리를 선택하여 이 접근법이 생성된 이러한 범주에 대해 생산한 효과 크기가 OASIS 인간 기준선에서 보고된 가치감 속성의 방향과 규모를 복제하는지를 테스트하였습니다. 또한 우리는 WEAT 대상 및 속성 자극을 사용하여 T2V 출력에서 비사회적 및 사회적 그룹 간 암묵적 연관성을 조사하기 위해 비디오를 생성했습니다(자극 전체 목록은 부록 10.1, 프롬프트 템플릿 및 생성 과정은 부록 10.2 참조).
우리는 인종, 성별, 그리고 그 교차점을 명시적으로 언급하는 프롬프트를 사용하여 비디오를 생성했습니다: 남자, 여자, 유럽계 미국인 남자, 흑인 아메리칸 남자, 유럽계 미국인 여자, 그리고 흑인 아메리칸 여자. 각 인구통계 그룹에 대해 30개의 비디오를 생성하여 “회색 배경 위의 __의 얼굴"이라는 템플릿을 사용했습니다. 프롬프트 민감도의 영향을 최소화하기 위해 우리는 의미적으로 중립적인 용어를 사용하였습니다.
직업 및 상에 대한 비디오 생성
우리는 이전 연구에서 자연 이미지에서 편향을 연구한 직업들, 예를 들어 소프트웨어 엔지니어와 하우스키퍼 등을 선택했습니다. 각 성별(Men/Women)과 인종(Black/White)에 대해 5개의 직업이 선택되었습니다. 상은 6개의 노벨상과 투링상을 포함합니다. 이전 연구는 이러한 명예직에서 소수 집단이 크게 대표되지 않는다는 것을 제시했습니다, 특히 STEM 분야인 화학과 의학에서는 더욱 그렇습니다. 연관성 크기가 실제 통계와 어떻게 일치하는지 평가하기 위해 2024년 인구통계를 각 인종과 성별에 대해 수집하였습니다. 직업과 상의 전체 목록은 부록 10.3에서 찾을 수 있으며, 데이터 수집 소스는 부록 10.4에 있습니다. 각 직업과 상에 대해 우리는 “회색 배경 위의 __의 얼굴 비디오"라는 프롬프트를 사용하여 30개의 비디오를 생성하였습니다.
명시적 편향 감소 프롬프트를 포함한 직업 및 상에 대한 비디오 생성
T2V 생성에서 편향 완화 전략을 평가하기 위해 우리는 명시적 편향 감소 프롬프트를 통합하였습니다. 우리는 각 조건별 프롬프트 템플릿(부록 10.7 참조)에서 직업과 상에 대한 비디오 생성 프롬프트 뒤에 명시적 편향 감소 프롬프트를 추가하였습니다.
접근법
우리의 접근법은 T2V 출력에서 연관성과 편향을 정량적으로 평가하도록 설계되었습니다. 이 섹션에서는 생성된 비디오를 나타내는 임베딩을 큐레이팅하는 절차부터 시작하여, VEAT와 SC-VEAT로 개발한 T2V 출력에서 연관성을 측정하는 방법론을 공식화합니다. VEAT는 두 가지 대상 집합(예: 남자 vs 여자)과 두 가지 속성 집합(예: 긍정적 vs 부정적)이 포함될 때 사용됩니다. SC-VEAT는 단일 대상(예: 소프트웨어 엔지니어)과 두 가지 속성 집합(예: 남자 vs 여자) 간의 연관성을 측정합니다.
임베딩을 이용한 비디오 표현
우리는 각 비디오에 대한 CLIP 이미지 인코더를 사용하여 임베딩을 추출합니다. 각 비디오는 5초 길이이며, 우리는 전체 20개의 프레임 임베딩을 얻기 위해 0.25초마다 하나씩 캡처합니다. 최종 임베딩은 평균 풀링됩니다. 이 접근법은 단순 배경과 낮은 움직임 비디오를 생성하는 데 효과적입니다. 이러한 간단한 예제를 통해 우리는 인구 통계 속성 및 암묵적 연관성을 충분히 캡처하기 위해 평균 풀링된 CLIP 임베딩이 필요함을 발견하였습니다.
비디오 임베딩 연관성 시험 (VEAT)
VEAT에서는 두 가지 대상 집합, $`\mathrm{X}`$와 $`\mathrm{Y}`$, 그리고 두 가지 속성 집합, $`\mathrm{A}`$와 $`\mathrm{B}`$를 사용합니다. 각 대상과 속성 집합은 30개의 비디오로 구성되어 있으며, 이는 해당 비디오 수준 임베딩으로 인코딩됩니다. $`E`$를 대상 비디오의 임베딩으로 표시하고, $`a`$와 $`b`$를 각각 집합 $`A`$ 및 $`B`$에서 추출한 속성 비디오의 임베딩으로 표시합니다. VEAT는 각 대상 임베딩과 두 개의 속성 집합 간의 코사인 유사성을 비교하고, 그 차이를 표준화합니다.
여기서 $`s(E, \mathrm{A}, \mathrm{B})`$는 비디오 임베딩 $`E`$가 $`\mathrm{A}`$보다 $`\mathrm{B}`$에 더 강하게 연결되어 있는지 측정합니다. 그 결과,
$`s(\mathrm{X}, \mathrm{Y}, \mathrm{A}, \mathrm{B})`$는 두 대상 집합이 속성 집합과 어떻게 다르게 연결되는지를 포착합니다. $`s(\mathrm{X}, \mathrm{Y}, \mathrm{A}, \mathrm{B})`$의 통계적 중요성을 평가하기 위해 우리는 일방향 순열 검정을 사용합니다. $`\{(\mathrm{X}_i, \mathrm{Y}_i)\}_i`$는 두 개의 동일한 크기 집합으로 나누어진 $`\mathrm{X} \cup \mathrm{Y}`$의 모든 분할입니다. 일방향 $`p`$-값은 다음과 같습니다:
편향을 측정할 때 Cohen의 $`d`$를 사용하면, 효과 크기가 0.8, 0.5, 그리고 0.2는 각각 대상과 속성 그룹 간에 큰, 중간, 작은 연관성을 나타냅니다. $`\bar{s}_{\mathrm{X}} = \mathrm{mean}_{\,x \in \mathrm{X}}\,s\bigl(x, \mathrm{A}, \mathrm{B}\bigr)`$와
$`\bar{s}_{\mathrm{B}} = \mathrm{mean}_{\,b \in \mathrm{B}}\,s\bigl(b, \mathrm{A}, \mathrm{B}\bigr)`$. $` # Limit to 15k chars for stability