LLM으로 라벨링된 룩셈부르크어 NER 품질 평가
📝 원문 정보
- Title: Do LLMs Judge Distantly Supervised Named Entity Labels Well? Constructing the JudgeWEL Dataset
- ArXiv ID: 2601.00411
- 발행일: 2026-01-01
- 저자: Alistair Plum, Laura Bernardy, Tharindu Ranasinghe
📝 초록 (Abstract)
우리는 룩셈부르크어 명명 엔터티 인식(NER)용 데이터셋인 judgeWEL을 제시한다. 이 데이터셋은 자동으로 라벨링된 뒤 대형 언어 모델(LLM)을 활용해 검증하는 새로운 파이프라인을 통해 구축되었다. 자원 부족과 언어적 특수성으로 인해 저자원 언어에 대한 대규모 주석 작업이 비용이 많이 들고 일관성이 떨어지는 것이 주요 병목 현상이다. 이를 해결하기 위해 우리는 위키피디아와 위키데이터를 약한 감독(weak supervision)의 구조화된 소스로 활용한다. 위키피디아 문서 내 내부 링크를 이용해 해당 엔터티의 위키데이터 항목을 조회하고, 이를 통해 엔터티 유형을 추론함으로써 최소한의 인간 개입만으로 초기 주석을 생성한다. 그러나 이러한 링크는 일관되지 않을 수 있으므로, 우리는 여러 LLM을 적용해 노이즈를 제거하고 고품질 라벨링 문장만을 선별한다. 최종 코퍼스는 기존에 공개된 룩셈부르크어 NER 데이터셋보다 약 5배 규모이며, 엔터티 카테고리별로 보다 폭넓고 균형 잡힌 커버리지를 제공한다. 이는 다국어 및 저자원 NER 연구에 중요한 새로운 자원을 제공한다.💡 논문 핵심 해설 (Deep Analysis)
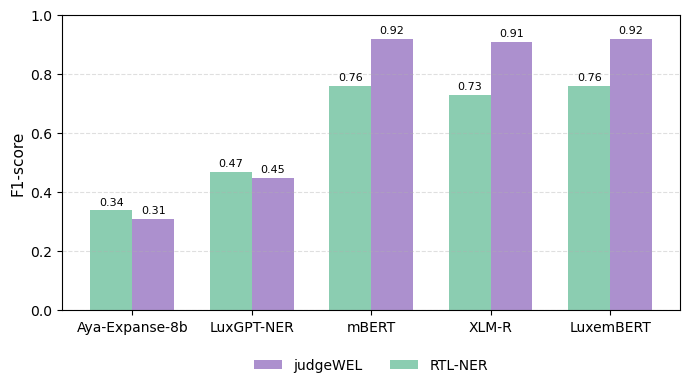
하지만 몇 가지 한계도 존재한다. 첫째, LLM 기반 검증 과정이 “블랙박스” 특성을 가지고 있어, 어떤 라벨이 왜 제거되었는지에 대한 설명 가능성이 부족하다. 이는 데이터셋을 활용하는 downstream 연구자가 라벨링 오류를 추적하거나, 특정 도메인에 맞게 재조정할 때 장애물이 될 수 있다. 둘째, 위키피디아와 위키데이터 자체가 영어 중심 구조를 가지고 있기 때문에, 룩셈부르크어 위키 페이지가 상대적으로 적고, 엔터티 유형 매핑이 불완전할 가능성이 있다. 논문에서는 이러한 편향을 완화하기 위해 인간 검증을 최소화했지만, 실제로는 소수의 전문가 검토가 데이터 품질을 크게 향상시킬 수 있다. 셋째, LLM을 “판단자”로 활용할 때 사용된 프롬프트 설계와 모델 파라미터에 대한 상세 정보가 부족하다. 이는 동일한 파이프라인을 다른 언어에 적용하려는 연구자에게 재현성을 저해한다.
연구의 의의는 크게 두 가지로 요약할 수 있다. 첫째, 약한 감독과 LLM 검증을 결합한 하이브리드 파이프라인이 저자원 언어 데이터 구축에 실용적이며, 비용 효율적인 대안을 제공한다는 점이다. 둘째, 기존 룩셈부르크어 NER 데이터셋 대비 5배 규모의 코퍼스를 공개함으로써, 다국어 NER 모델의 사전 학습 및 파인튜닝에 필요한 풍부한 학습 자원을 제공한다. 향후 연구에서는 라벨링 오류에 대한 설명 가능성을 높이기 위한 메타데이터(예: 라벨 신뢰도 점수) 제공, 인간‑LLM 협업 라벨링 인터페이스 구축, 그리고 다른 저자원 언어에 대한 파이프라인 일반화 실험이 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리