컨텍스트 인라인을 통한 저장소 수준 코드 생성
📝 원문 정보
- Title: In Line with Context: Repository-Level Code Generation via Context Inlining
- ArXiv ID: 2601.00376
- 발행일: 2026-01-01
- 저자: Chao Hu, Wenhao Zeng, Yuling Shi, Beijun Shen, Xiaodong Gu
📝 초록 (Abstract)
저장소 수준 코드 생성은 전체 코드베이스를 이해하고 함수·클래스·모듈 간 복잡한 의존성을 추론해야 하는 과제로 최근 주목받고 있다. 기존의 검색 기반 생성(RAG)이나 컨텍스트 기반 함수 선택 방식은 표면적인 유사도에 의존해 저장소 전반의 의미론적 연관성을 포착하는 데 한계가 있다. 본 논문에서는 이러한 문제를 해결하기 위해 InlineCoder라는 새로운 프레임워크를 제안한다. InlineCoder는 미완성 함수를 호출 그래프에 인라인함으로써 저장소 이해를 보다 쉬운 함수 수준 코딩 문제로 전환한다. 먼저 함수 시그니처를 입력받아 초안(앵커)을 생성하고, 이 앵커를 이용해 퍼플렉시티 기반 신뢰도를 추정한다. 이후 양방향 인라인 과정을 수행한다: (i) 상위 인라인은 앵커를 호출자에 삽입해 다양한 사용 상황을 제공하고, (ii) 하위 검색은 앵커가 호출하는 함수들을 프롬프트에 포함시켜 정확한 의존성 정보를 제공한다. 이렇게 풍부해진 컨텍스트는 LLM에게 저장소 전체에 대한 포괄적인 시야를 제공한다. DevEval 및 RepoExec 벤치마크에서 광범위한 실험을 수행한 결과, InlineCoder는 기존 최강 모델 대비 RepoExec에서 EM 29.73 %, ES 20.82 %, BLEU 49.34 %의 평균 상대 향상을 기록하였다. 이는 저장소 수준 컨텍스트 이해와 도메인 일반화 능력에서 뛰어난 효과를 입증한다.💡 논문 핵심 해설 (Deep Analysis)

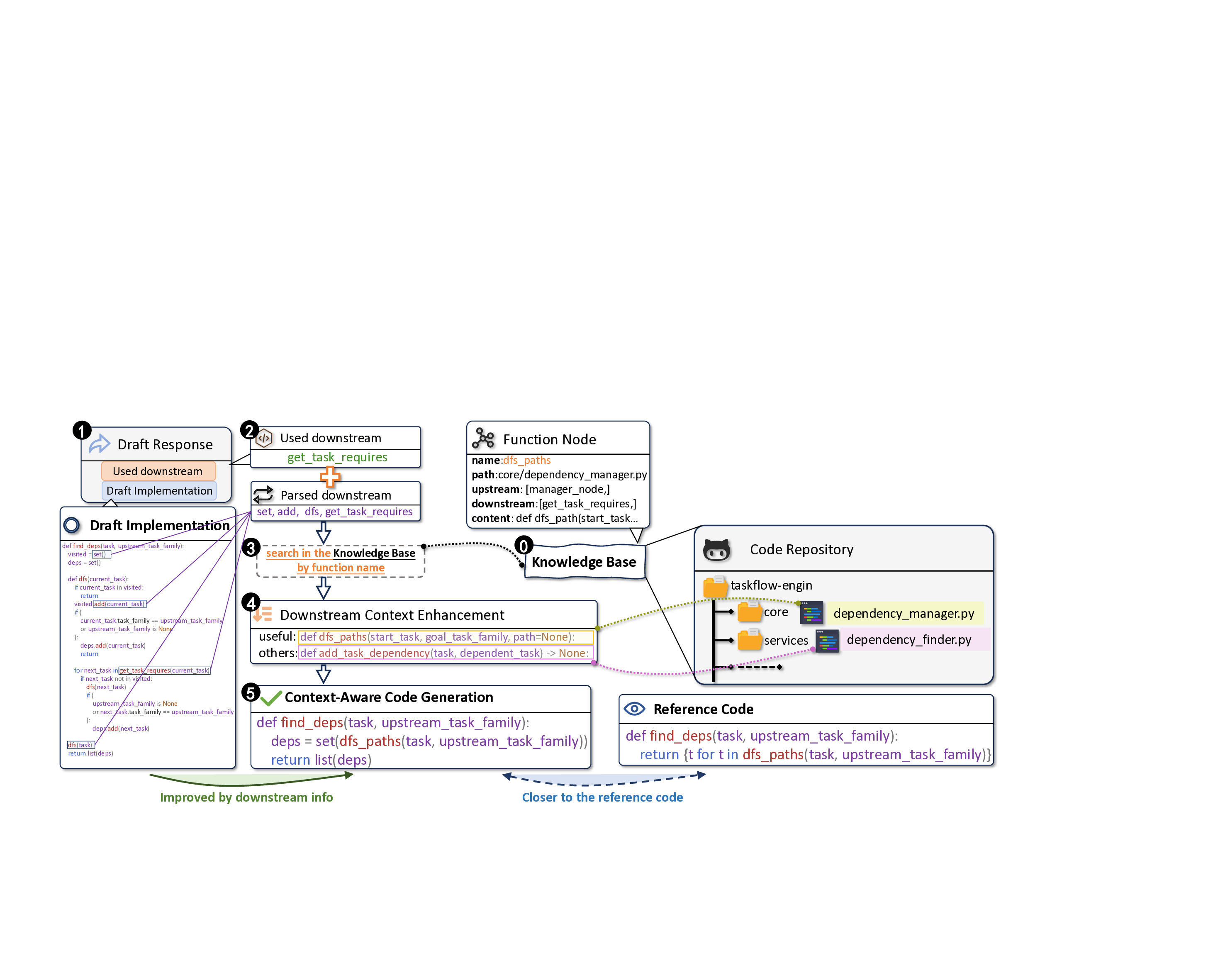
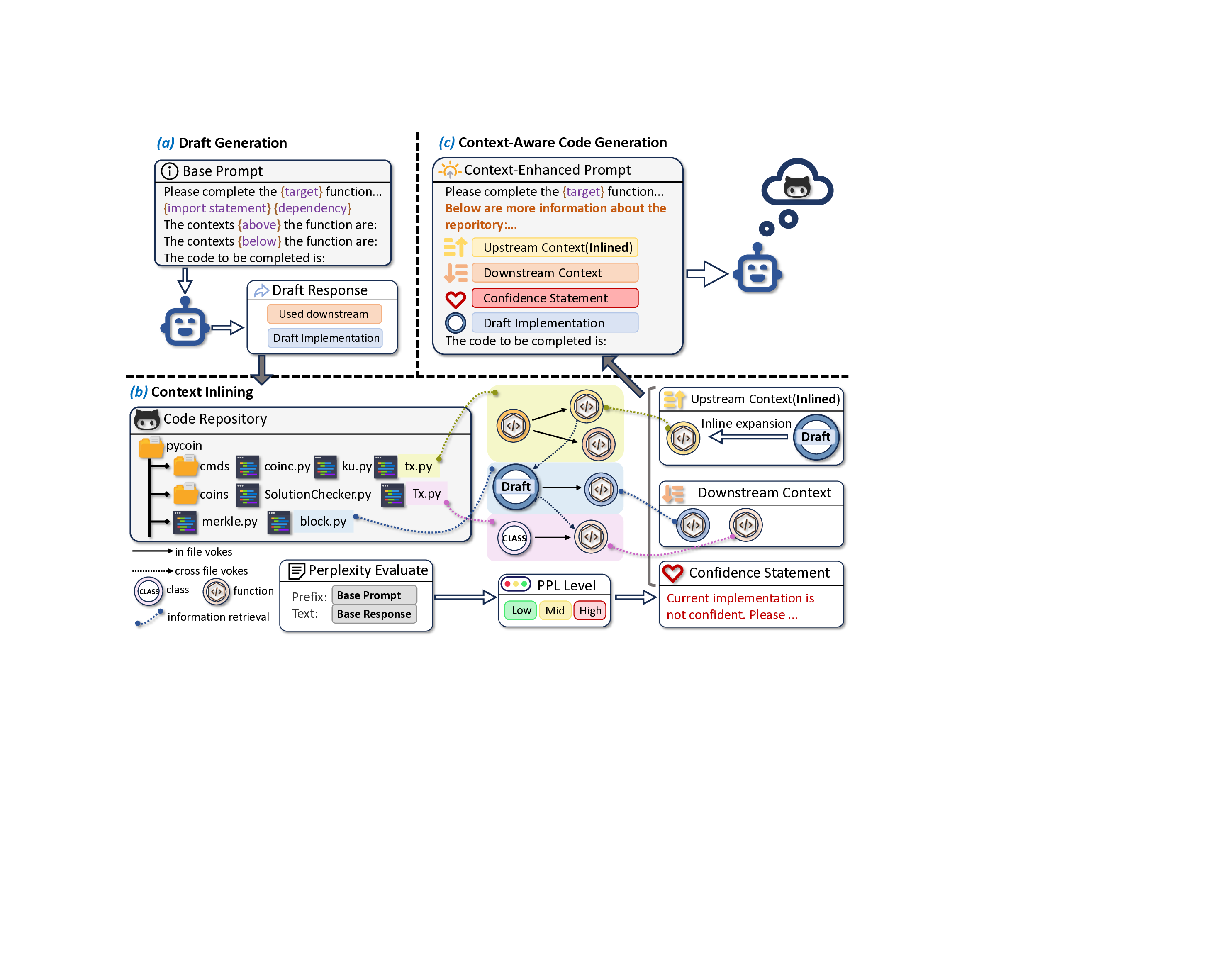
InlineCoder는 먼저 목표 함수의 시그니처만을 입력받아 “앵커”라 불리는 초안 코드를 생성한다. 이 초안은 아직 완전하지 않지만, 함수가 어떤 형태의 파라미터와 반환값을 가질지, 그리고 어느 정도의 로직을 포함할지에 대한 추정치를 제공한다. 퍼플렉시티 기반 신뢰도 추정은 이 앵커가 얼마나 일관된지를 정량화함으로써, 이후 인라인 단계에서 활용할 후보를 선별하는 기준이 된다.
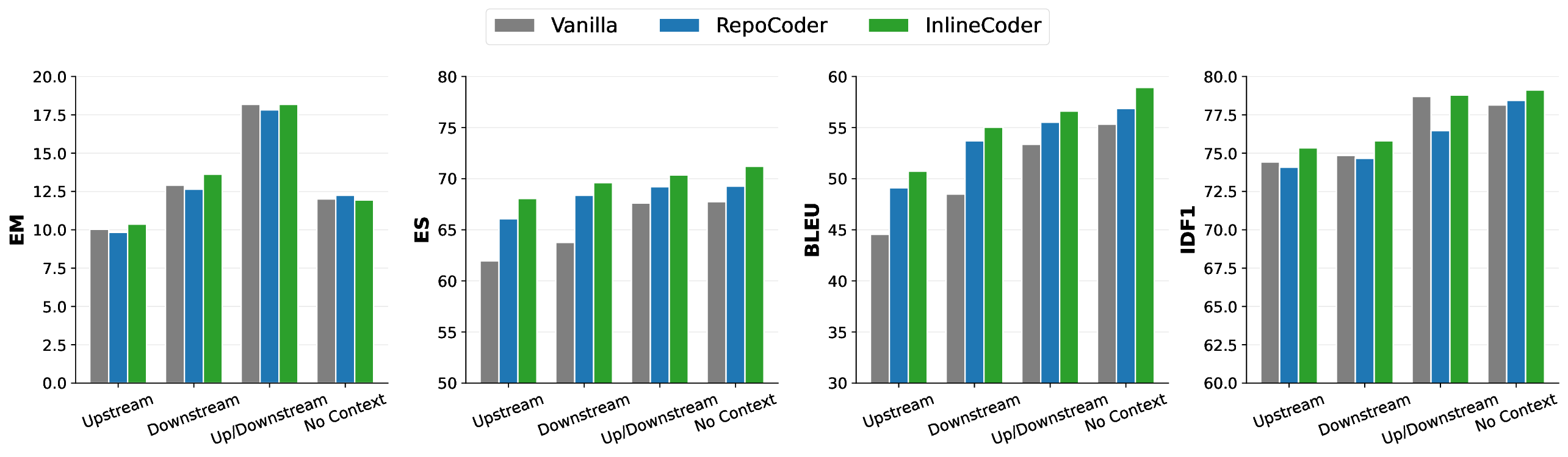
양방향 인라인 과정은 두 축으로 이루어진다. 상위 인라인(Upstream Inlining)에서는 앵커를 호출하는 모든 함수(또는 메서드)를 찾아 그 위치에 삽입한다. 이렇게 하면 모델은 “이 함수가 실제로 어떻게 사용되는가”라는 구체적인 사용 사례를 학습하게 된다. 예를 들어, 동일한 함수가 여러 컨텍스트에서 서로 다른 인자를 전달받는 경우, 각각의 호출 상황이 프롬프트에 포함되어 모델이 보다 일반화된 구현을 도출하도록 돕는다.
하위 검색(Downstream Retrieval)에서는 앵커가 호출하는 함수들을 역추적하여 해당 구현 코드를 프롬프트에 추가한다. 이는 함수 내부에서 어떤 외부 API나 유틸리티를 활용하는지를 명시적으로 제공함으로써, 모델이 의존성 해결에 필요한 정보를 놓치지 않게 만든다. 두 방향의 정보를 결합하면, “함수가 어디서 호출되고, 무엇을 호출하는가”라는 완전한 호출 그래프가 텍스트 형태로 모델에 전달된다.
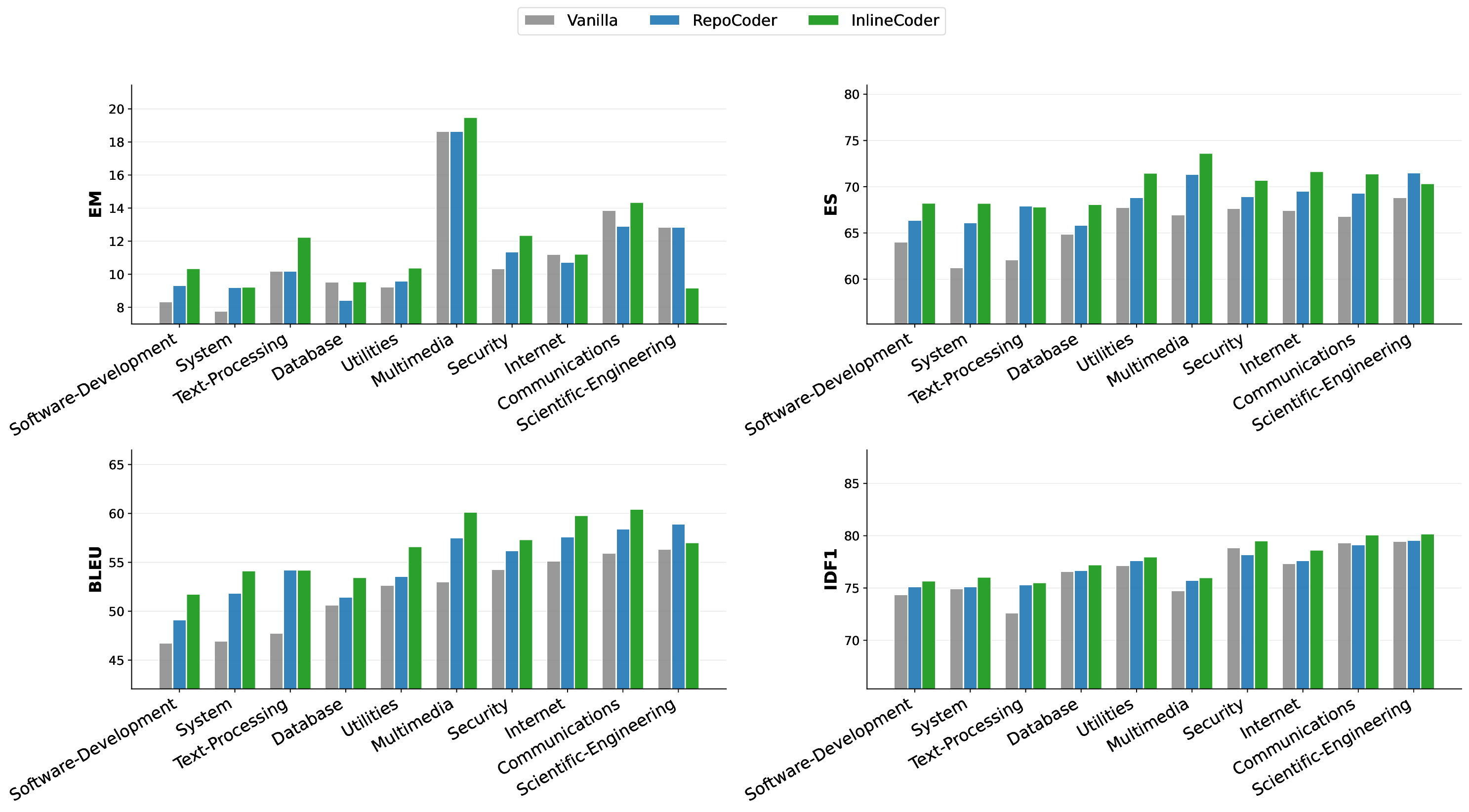
실험 결과는 이 설계가 실제로 효과적임을 강력히 뒷받침한다. DevEval과 RepoExec 두 벤치마크 모두 다양한 언어와 도메인을 포함하고 있어 일반화 능력을 검증하기에 적합한데, InlineCoder는 EM(Exact Match)에서 평균 29.73 % 향상, ES(Exact Set)에서 20.82 % 향상, BLEU 점수에서는 무려 49.34 % 상승을 기록했다. 특히 BLEU 점수의 큰 폭 상승은 모델이 보다 자연스럽고 문법적으로 정확한 코드를 생성함을 의미한다.
한편 한계점도 존재한다. 앵커 생성 단계가 초기 품질에 크게 의존하므로, 초안이 부정확하면 상위·하위 인라인 모두 오류를 증폭시킬 위험이 있다. 또한, 호출 그래프가 매우 큰 경우(수천 개의 호출자·피호출자) 전체 인라인을 수행하면 프롬프트 길이 제한에 걸릴 수 있다. 향후 연구에서는 앵커 품질을 향상시키는 사전 학습 전략과, 그래프 압축·샘플링 기법을 도입해 확장성을 확보하는 방안을 모색해야 할 것이다.
요약하면, InlineCoder는 “컨텍스트 인라인”이라는 새로운 패러다임을 통해 저장소 수준 코드 생성의 핵심 난제인 의존성 파악과 전역 이해를 함수 수준으로 효율적으로 전이시킨다. 이는 LLM 기반 코드 생성 연구에 새로운 설계 원칙을 제시하며, 향후 복잡한 소프트웨어 시스템 자동화에 중요한 기반이 될 것으로 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리