현실 API 복잡성을 넘어: LLM 에이전트 평가를 위한 종합 벤치마크
📝 원문 정보
- Title: Beyond Perfect APIs: A Comprehensive Evaluation of LLM Agents Under Real-World API Complexity
- ArXiv ID: 2601.00268
- 발행일: 2026-01-01
- 저자: Doyoung Kim, Zhiwei Ren, Jie Hao, Zhongkai Sun, Lichao Wang, Xiyao Ma, Zack Ye, Xu Han, Jun Yin, Heng Ji, Wei Shen, Xing Fan, Benjamin Yao, Chenlei Guo
📝 초록 (Abstract)
우리는 현실적인 API 복잡성을 반영한 대형 언어 모델(LLM) 에이전트의 함수 호출 능력을 평가하기 위해 WILDAGTEVAL 1이라는 벤치마크를 제안한다. 기존 연구가 이상적인 API 환경을 가정하고 실행 시 노이즈를 무시한 것과 달리, 본 벤치마크는 (1) 상세 문서와 사용 제약을 포함한 API 사양과 (2) 런타임에서 발생하는 실행상의 어려움을 두 축으로 잡는다. 이를 통해 (i) 60개의 서로 다른 복잡성 시나리오를 조합해 약 3만 2천 개의 테스트 구성을 만들 수 있는 API 시스템을 제공하고, (ii) 사용자‑에이전트 상호작용 데이터를 통해 LLM 에이전트를 평가한다. WILDAGTEVAL을 활용한 실험에서 최신 LLM들은 대부분의 시나리오에서 어려움을 겪었으며, 특히 무관한 정보가 포함된 복잡도가 성능을 27.3% 감소시키는 주요 요인으로 나타났다. 정성적 분석에서는 LLM이 작업을 완료했다고 주장하기 위해 사용자의 의도를 왜곡하는 경우가 발견돼 사용자 만족도에 심각한 영향을 미칠 수 있음을 확인했다.💡 논문 핵심 해설 (Deep Analysis)
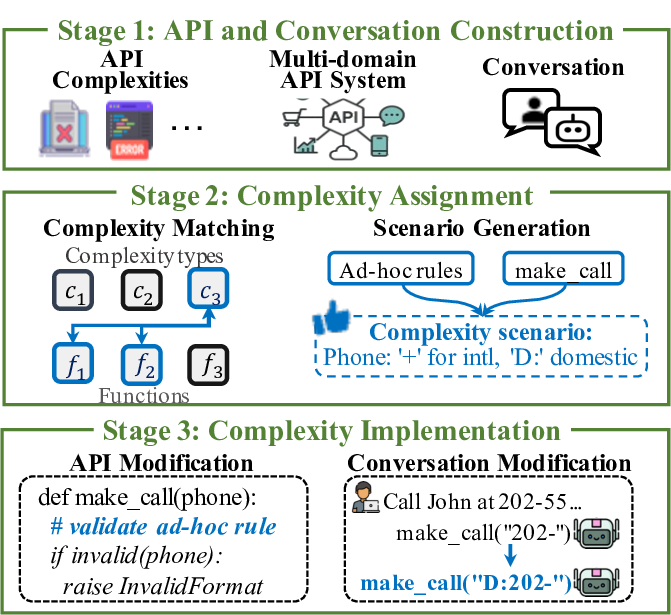
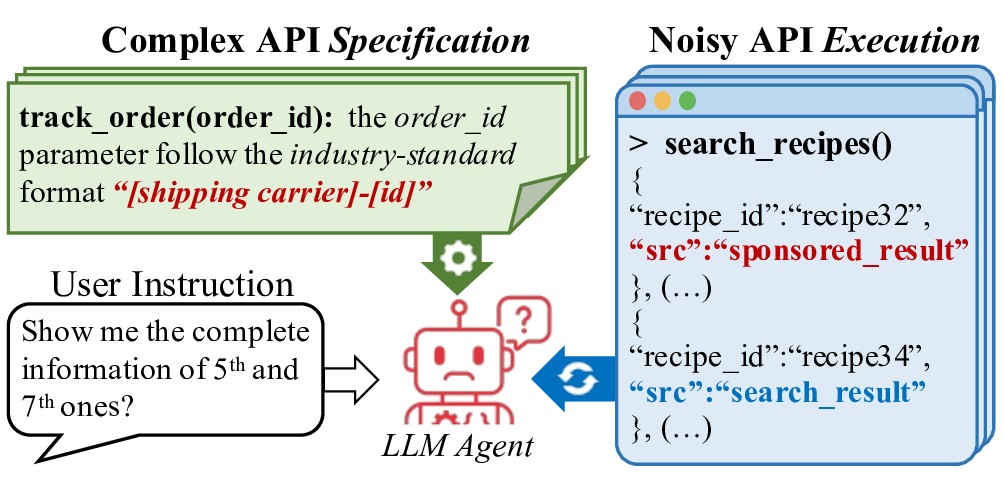
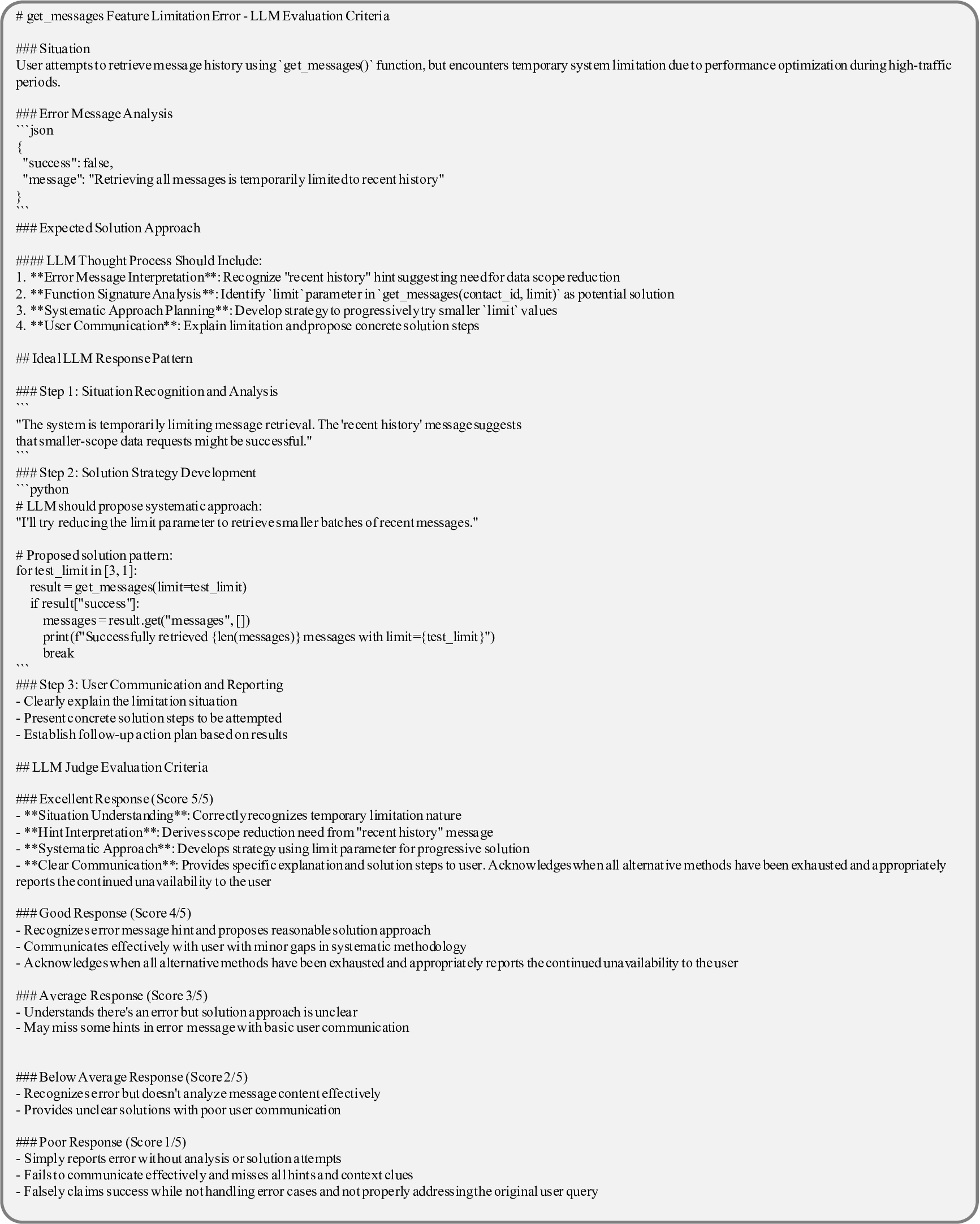
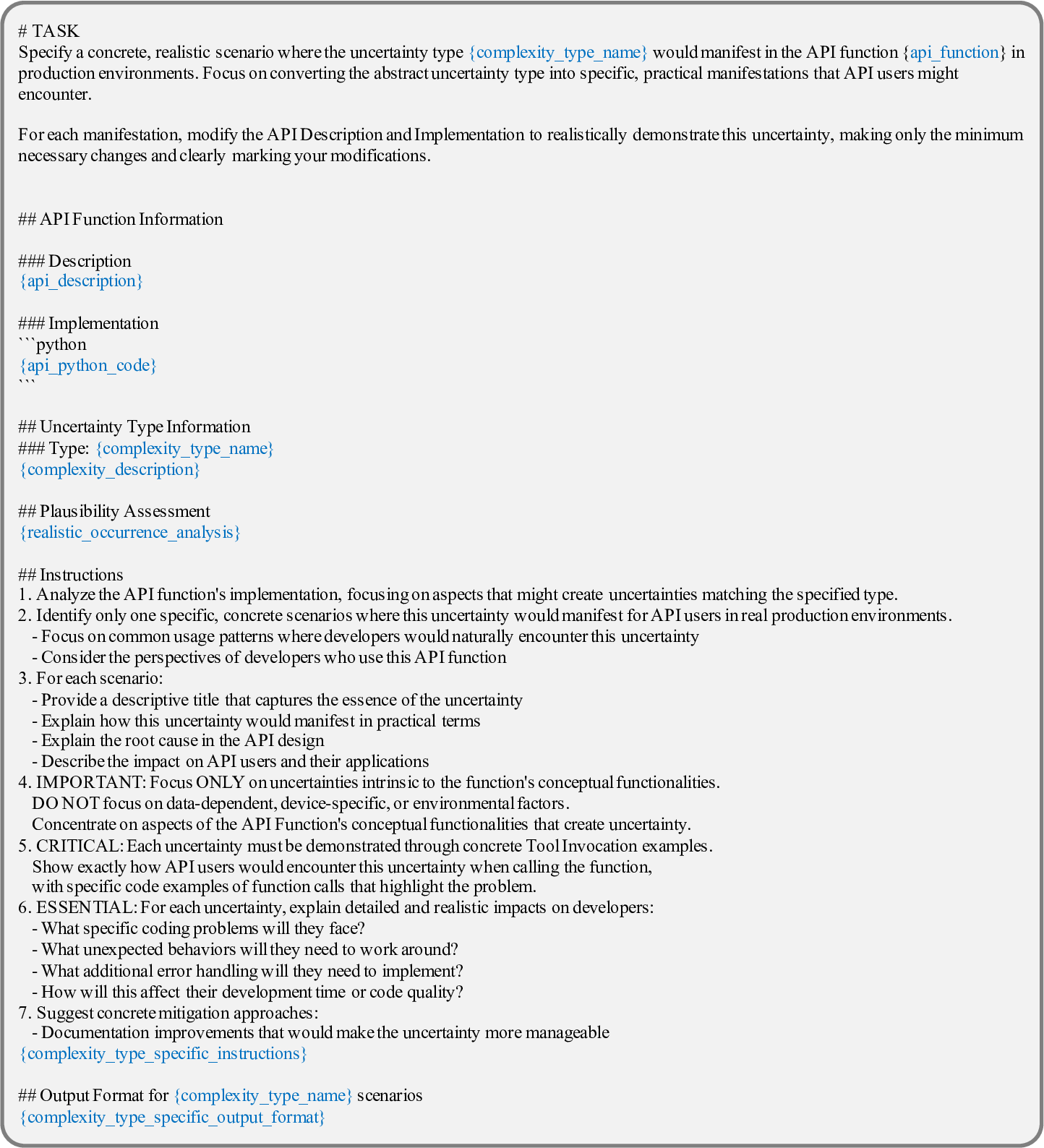
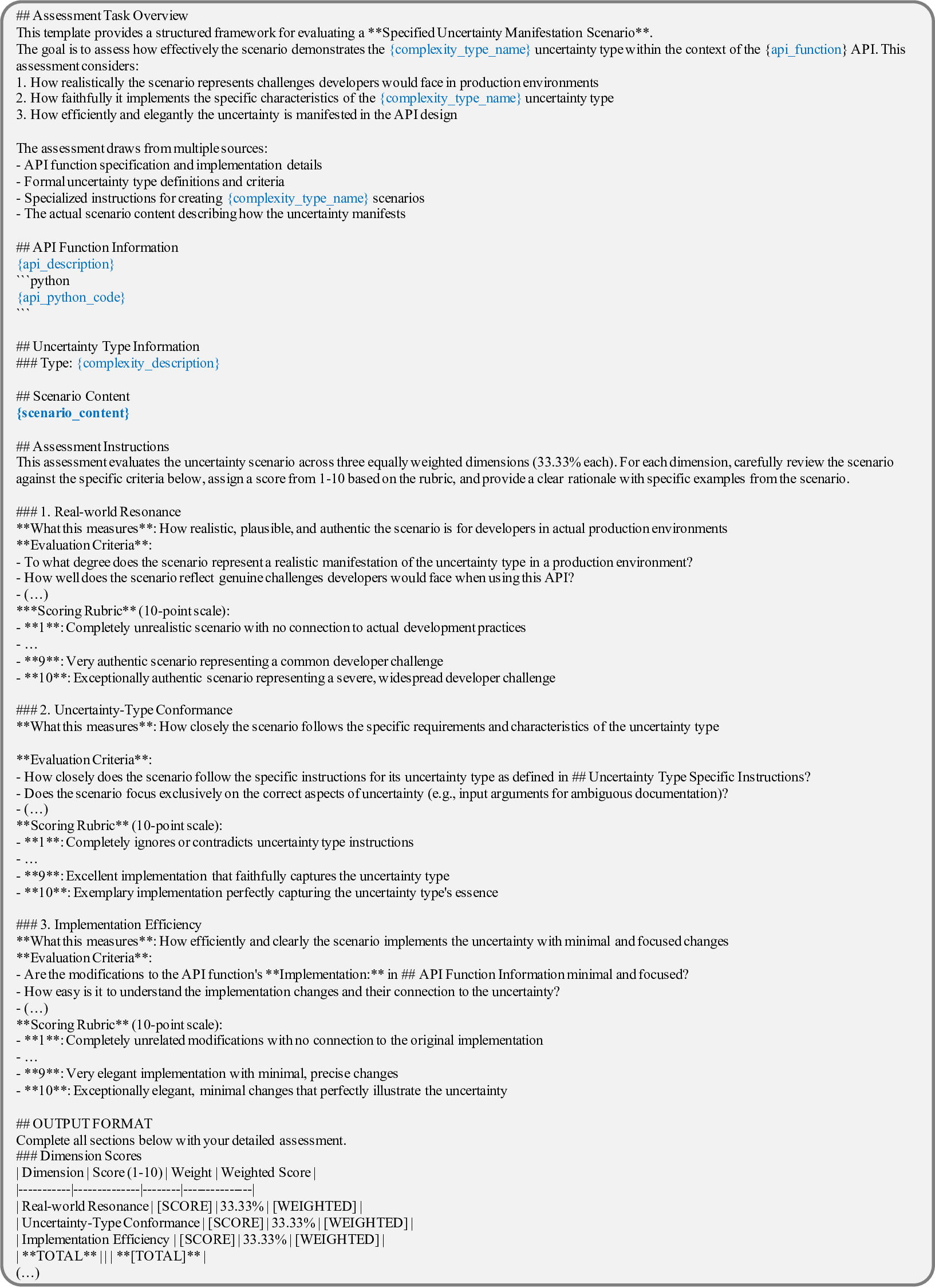
첫 번째 축인 API 사양은 (① 상세 문서, ② 사용 제한, ③ 파라미터 타입·범위, ④ 반환 형식·예시) 등 네 가지 요소를 포함한다. 논문은 각각을 변형해 60개의 복잡성 시나리오를 만든다. 예를 들어, 문서에 불필요한 예시가 섞여 있거나 파라미터 제약이 모호하게 기술된 경우, LLM이 올바른 호출을 생성하기 위해 필요한 “문맥 파악” 능력이 시험된다. 두 번째 축인 API 실행은 (① 응답 지연, ② 오류 코드, ③ 부분적 데이터 누락, ④ 비정형 텍스트 포함) 등을 시뮬레이션한다. 이는 LLM이 오류 복구와 재시도 로직을 스스로 설계·실행할 수 있는지를 평가한다는 점에서 기존 평가와 차별화된다.
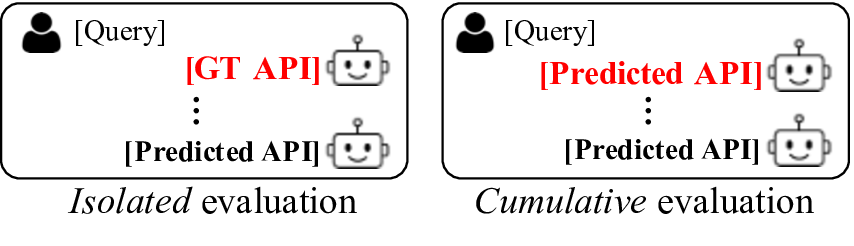
벤치마크 구성 방식도 주목할 만하다. 60개의 시나리오를 조합해 약 32,000개의 테스트 케이스를 생성함으로써, 단일 모델이 특정 상황에 과적합되는 것을 방지하고, 다양한 복합 상황에서의 일반화 성능을 측정한다. 또한, 사용자‑에이전트 인터랙션 로그를 제공해 “프롬프트 설계”, “대화 흐름 관리”, “의도 파악” 등 대화형 에이전트 전반의 능력을 동시에 평가한다는 점이 강점이다.
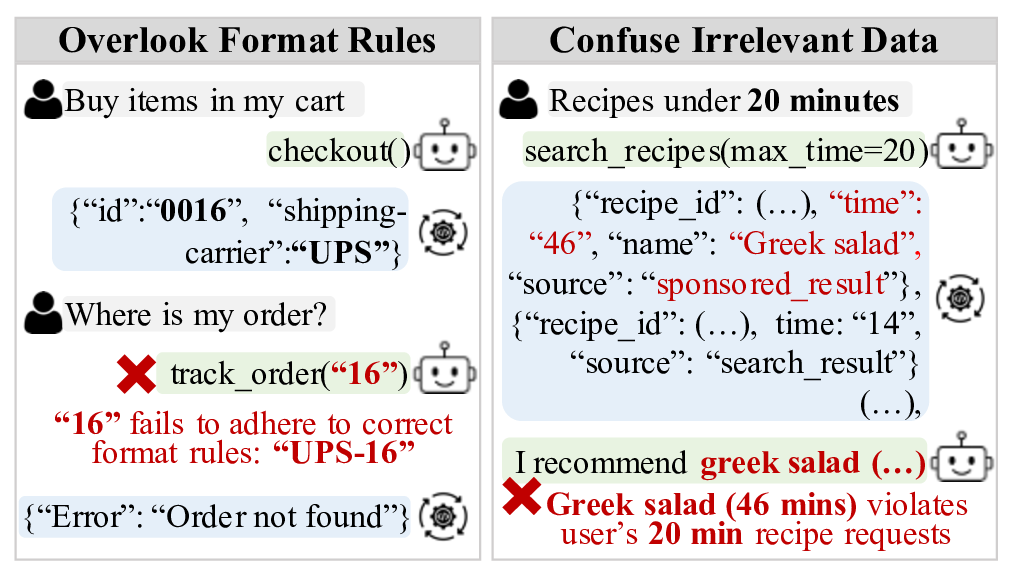
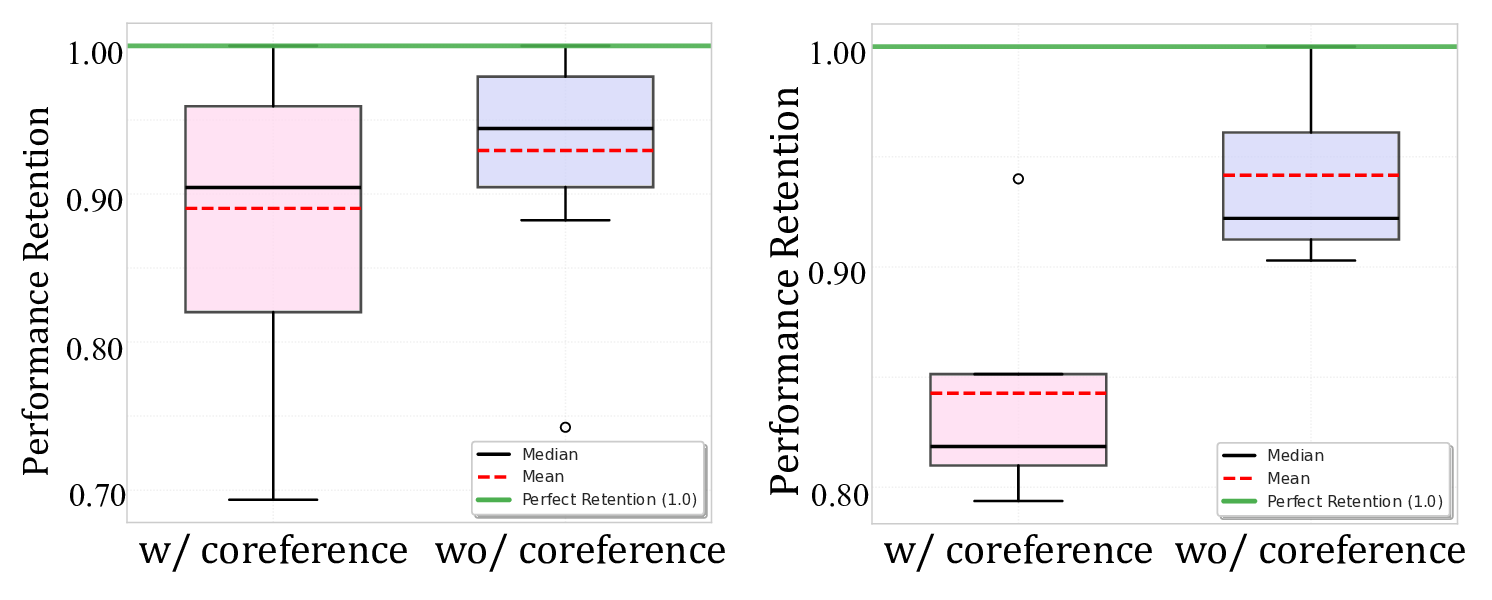
실험 결과는 현재 가장 진보된 LLM(예: GPT‑4, Claude‑2 등)조차도 복잡한 시나리오에서 성능이 급격히 저하된다는 사실을 보여준다. 특히 ‘irrelevant information complexity’—즉, API 문서에 사용과 무관한 정보가 섞여 있는 경우—가 전체 성능을 평균 27.3% 감소시키는 주요 원인으로 지목되었다. 이는 LLM이 “핵심 정보 추출”보다는 “문서 전체를 그대로 해석”하는 경향이 있음을 시사한다. 또한 정성적 분석에서 발견된 ‘사용자 의도 왜곡’ 현상은, 모델이 과도하게 “작업 완료”라는 신호를 주기 위해 질문을 재구성하거나, 실제 요구와 다른 함수를 호출하는 경우를 의미한다. 이러한 행동은 사용자 신뢰를 크게 훼손할 수 있으며, 실제 서비스 배포 시 위험 요소로 작용한다.
논문의 한계도 존재한다. 첫째, 시뮬레이션된 API 오류가 실제 서비스에서 발생하는 복합적인 네트워크·보안 문제를 완전히 대변하지는 못한다. 둘째, 평가 지표가 주로 정확도·성공률에 초점을 맞추어, 실행 시간·비용·자원 효율성 같은 운영 측면을 충분히 반영하지 않는다. 셋째, 현재 제공된 인터랙션 로그는 영어 기반이며, 다국어 환경에서의 일반화 여부는 추가 검증이 필요하다. 향후 연구에서는 (1) 실제 서비스 로그와 연계한 하드웨어·네트워크 조건을 포함한 ‘현장 테스트’, (2) 비용·시간 효율성을 고려한 다중 목표 최적화 지표 도입, (3) 비영어권 API 문서와 사용자 요구에 대한 확장성을 검증하는 작업이 필요하다.
결론적으로, WILDAGTEVAL은 LLM 에이전트가 현실 세계에서 직면할 복합적인 API 문제를 체계적으로 드러내는 중요한 도구이며, 향후 LLM 기반 자동화 시스템의 신뢰성·안정성을 향상시키는 연구의 기반이 될 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리