VisNet 효율적인 사람 재식별을 위한 알파다이버전스 손실 특징 융합 동적 다중작업 학습
📝 원문 정보
- Title: VisNet: Efficient Person Re-Identification via Alpha-Divergence Loss, Feature Fusion and Dynamic Multi-Task Learning
- ArXiv ID: 2601.00307
- 발행일: 2026-01-01
- 저자: Anns Ijaz, Muhammad Azeem Javed
📝 초록 (Abstract)
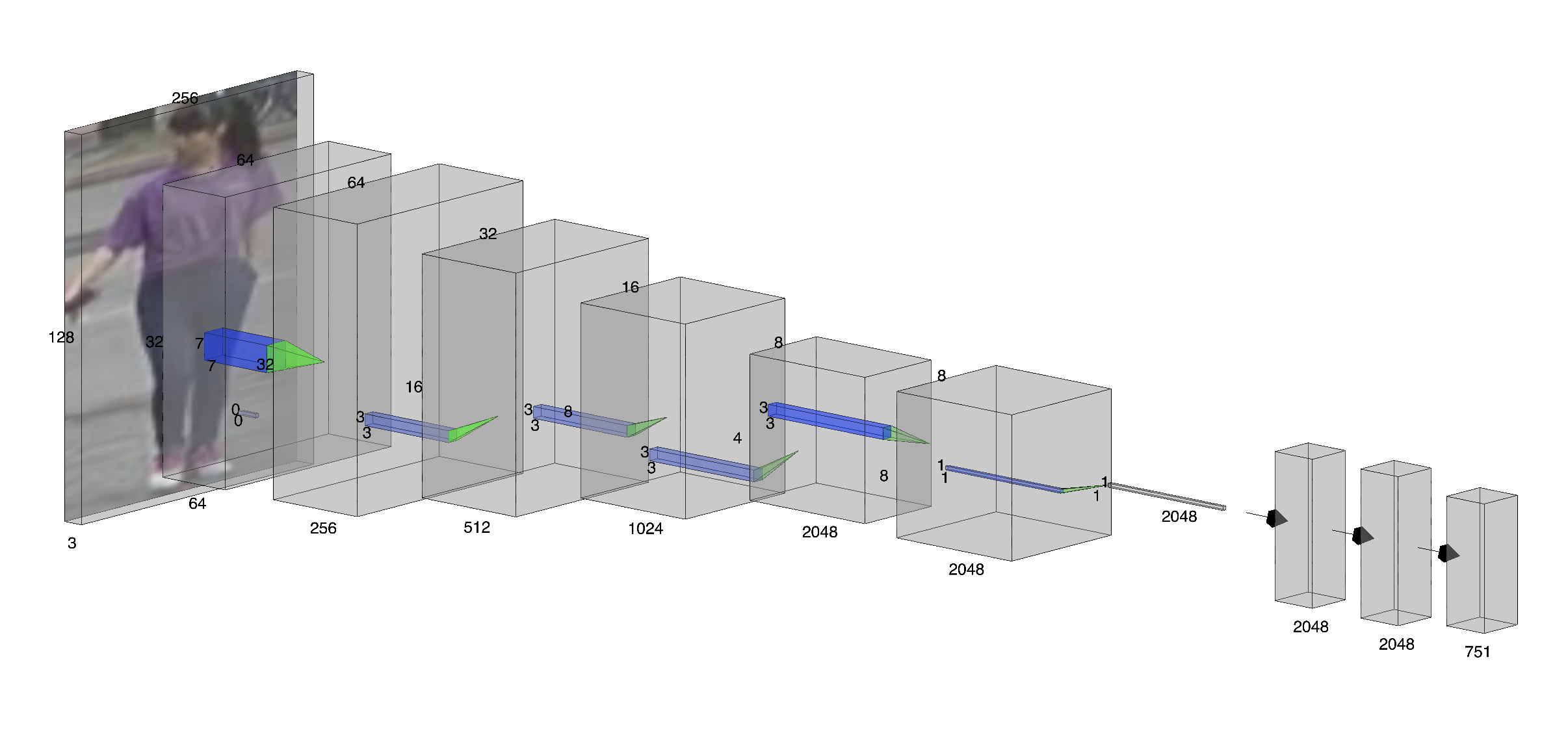
본 논문은 감시 및 모바일 환경에서 실시간으로 활용 가능한 경량화된 사람 재식별 모델 VisNet을 제안한다. VisNet은 다중 스케일 특징 융합, 자동 주의 메커니즘, 인체 부위 기반 의미 클러스터링, 동적 가중치 평균(Dynamic Weight Averaging) 기법을 결합하여 분류 정규화와 메트릭 학습을 동시에 최적화한다. ResNet‑50의 1~4단계를 순차적으로 결합하고, 병렬 경로 없이 효율적인 피처 통합을 구현한다. 의미 클러스터링은 규칙 기반 의사 라벨링을 통해 공간적 제약을 부여하고, 손실 함수 FIDI(Feature‑Invariant Divergence Interaction)를 적용해 거리 학습 성능을 향상시킨다. Market‑1501 데이터셋에서 VisNet은 Rank‑1 87.05 %와 mAP 77.65 %를 달성했으며, 파라미터 32.41 M, 연산량 4.601 GFLOPs로 실시간 배포가 가능한 수준이다.💡 논문 핵심 해설 (Deep Analysis)
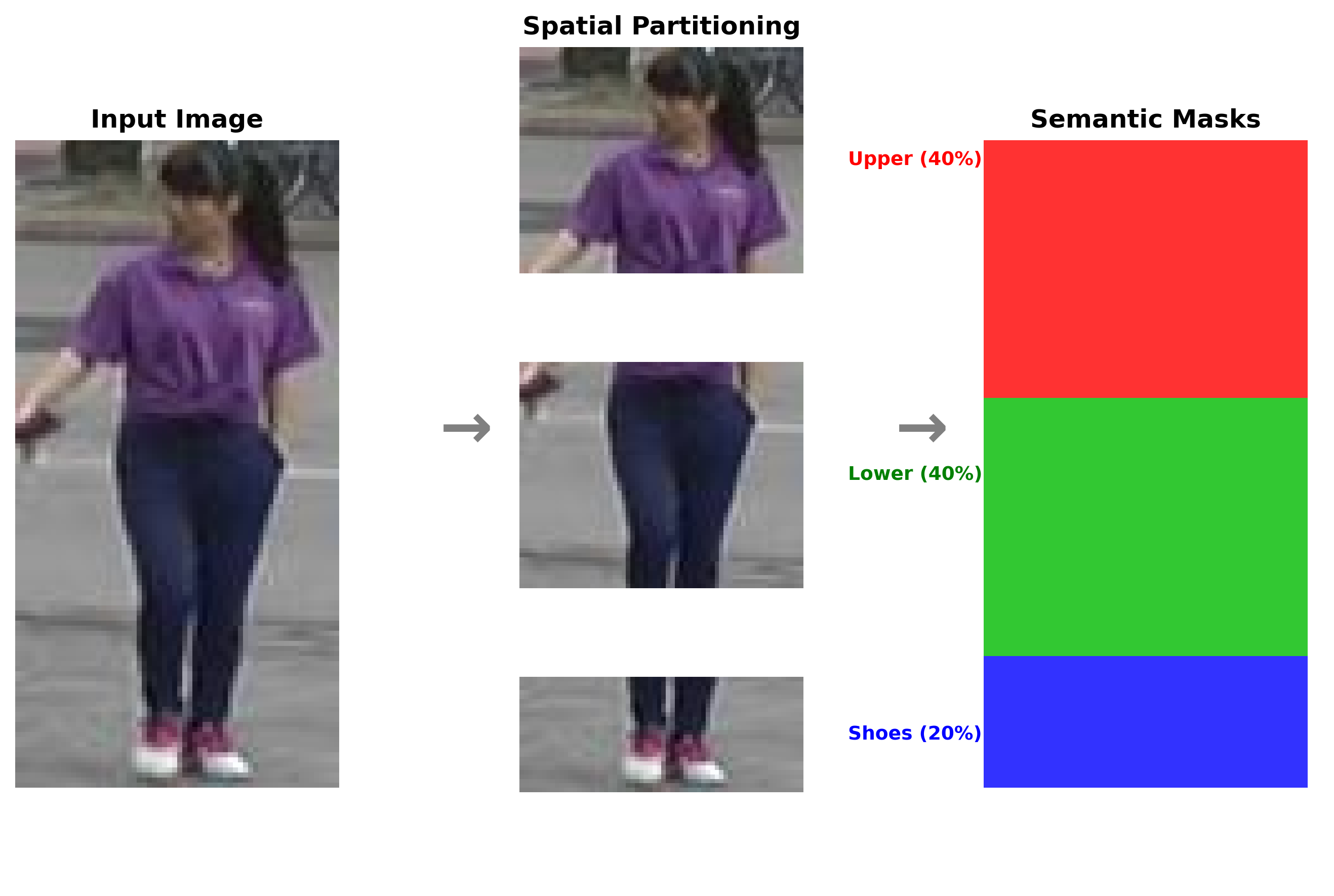
두 번째 기여는 “의미 클러스터링”이다. 저자들은 인체를 머리·상체·하체와 같은 해부학적 파티션으로 나누고, 규칙 기반 의사 라벨링(rule‑based pseudo‑labeling)을 통해 각 파티션에 대한 공간적 제약을 부여한다. 이는 동일 인물의 다양한 포즈와 카메라 각도에서도 파티션 간 일관성을 유지하도록 유도하여, 기존의 전역 특징만을 활용하는 방법보다 더 강인한 매칭을 가능하게 한다.
세 번째로 도입된 “동적 가중치 평균(Dynamic Weight Averaging, DWA)”은 다중 작업(분류와 메트릭 학습) 사이의 손실 가중치를 학습 과정에서 자동으로 조정한다. 고정된 가중치 설정이 종종 한 작업에 편향되는 문제를 해결하고, 훈련 초반에는 분류 손실에, 후반부에는 거리 손실에 더 큰 비중을 두어 최적의 균형을 찾는다. 이는 특히 데이터 불균형이나 라벨 노이즈가 존재할 때 모델의 일반화 능력을 크게 향상시킨다.
마지막으로 제안된 FIDI 손실은 알파‑다이버전스(alpha‑divergence)를 기반으로 하여, 특징 간의 분포 차이를 보다 정교하게 측정한다. 기존의 트리플렛 손실이나 교차 엔트로피 손실이 갖는 경계 효과(boundary effect)를 완화하고, 서로 다른 클러스터 간의 거리를 크게 벌리는 동시에 같은 클러스터 내 변동성을 최소화한다.
실험 결과는 이 모든 요소가 상호 보완적으로 작용함을 보여준다. Market‑1501에서 Rank‑1 87.05 %와 mAP 77.65 %는 최신 SOTA 모델들과 비교해도 뒤처지지 않으며, 파라미터 32.41 M와 4.601 GFLOPs는 모바일 디바이스나 엣지 서버에서 실시간 추론이 가능한 수준이다. 다만, 논문에서는 DukeMTMC‑reID와 MSMT17 같은 대규모 데이터셋에 대한 평가가 부족하고, 실제 모바일 환경에서의 전력 소비와 메모리 프로파일링이 제시되지 않은 점은 향후 연구에서 보완될 필요가 있다. 또한, 규칙 기반 의사 라벨링이 복잡한 포즈나 부분 가림 현상에 얼마나 견고한지에 대한 정량적 분석이 추가된다면, 모델의 적용 범위가 더욱 확대될 것이다. 전반적으로 VisNet은 “경량화 + 고성능”이라는 목표를 실현한 실용적인 프레임워크라 할 수 있다.
📄 논문 본문 발췌 (Excerpt)
📸 추가 이미지 갤러리