MAESTRO 멀티에이전트 평가 스위트 테스트 신뢰성 관측성
📝 원문 정보
- Title: MAESTRO: Multi-Agent Evaluation Suite for Testing, Reliability, and Observability
- ArXiv ID: 2601.00481
- 발행일: 2026-01-01
- 저자: Tie Ma, Yixi Chen, Vaastav Anand, Alessandro Cornacchia, Amândio R. Faustino, Guanheng Liu, Shan Zhang, Hongbin Luo, Suhaib A. Fahmy, Zafar A. Qazi, Marco Canini
📝 초록 (Abstract)
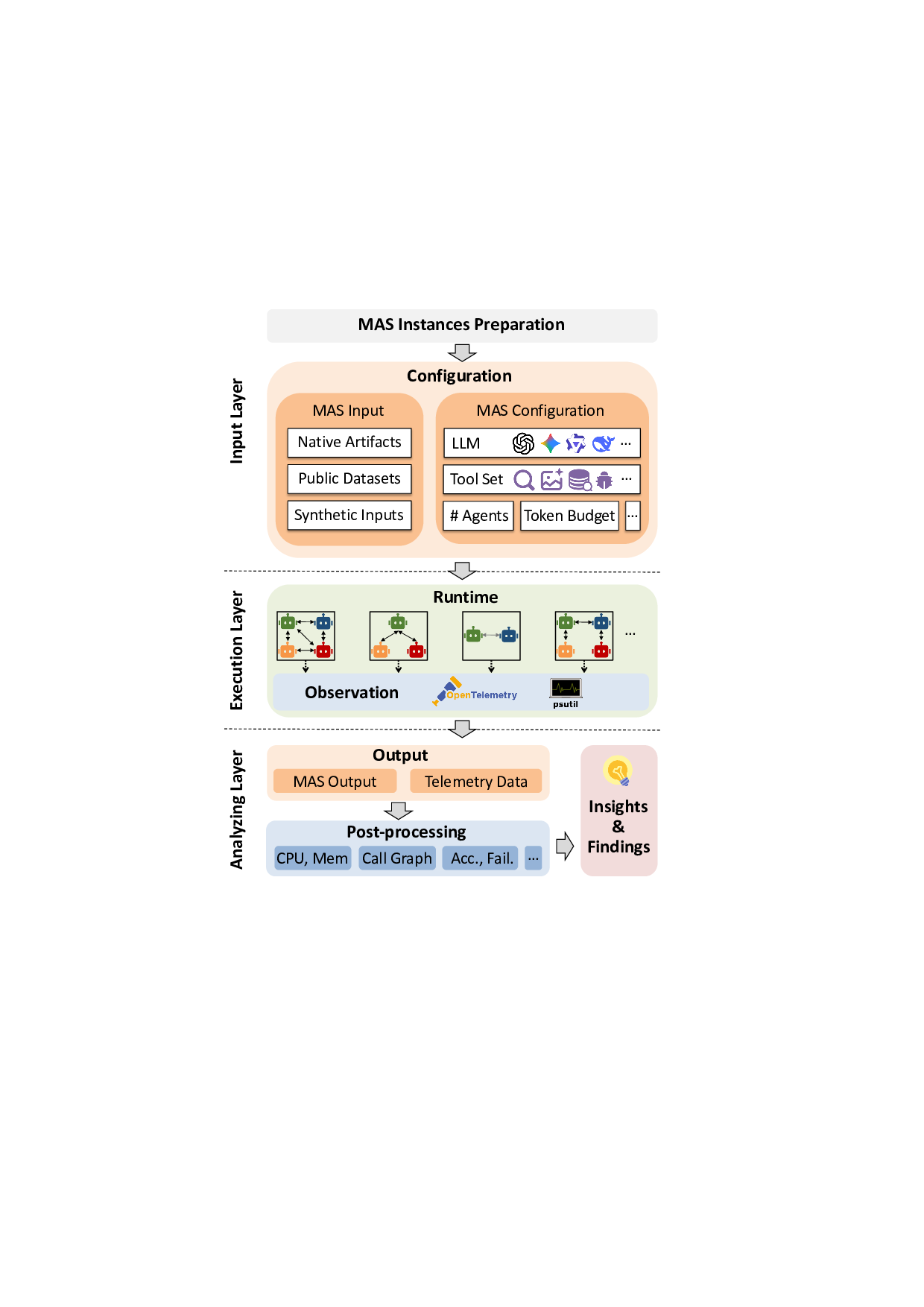
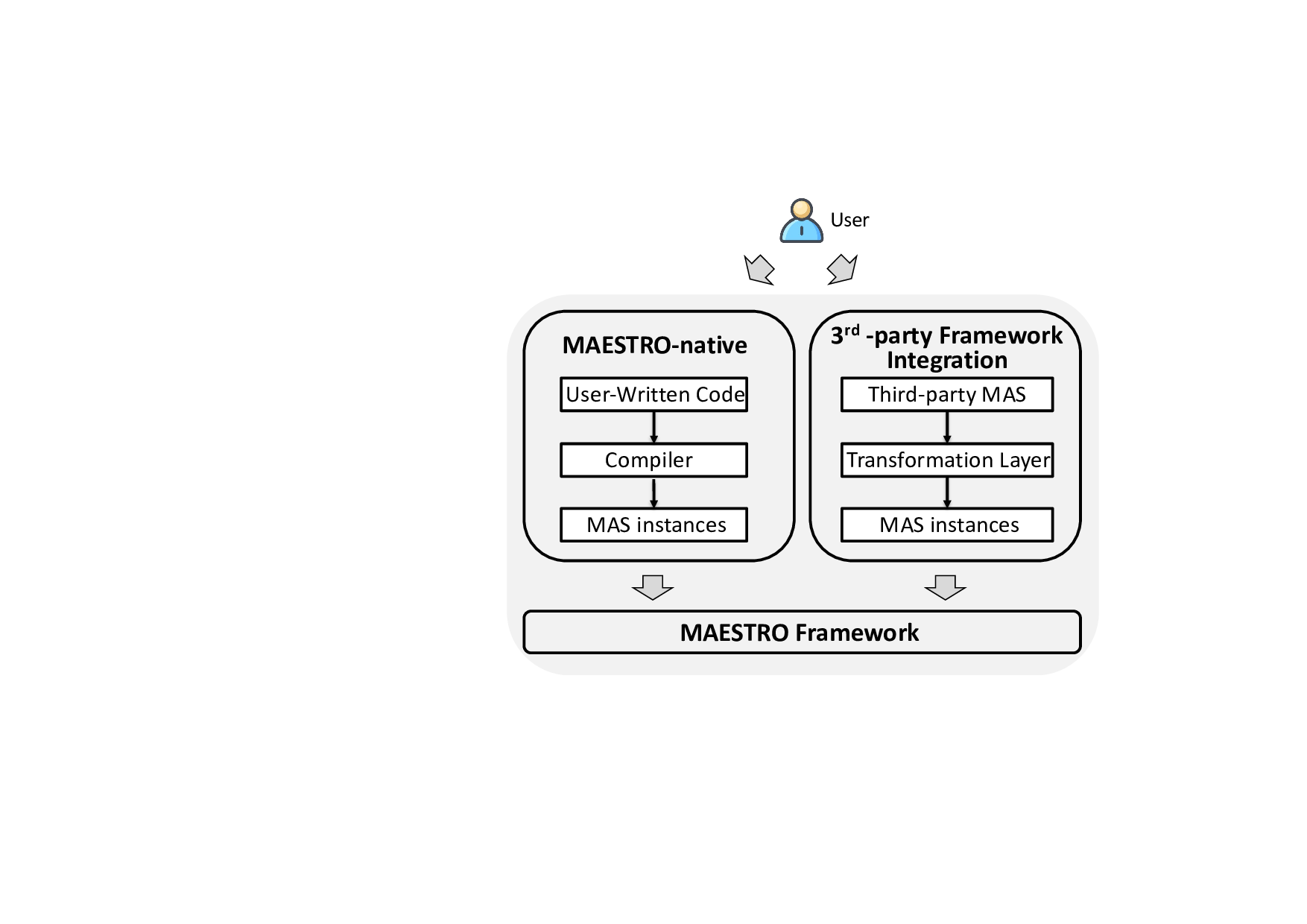
대형 언어 모델(LLM) 기반 멀티에이전트 시스템(MAS)은 데모 단계에서 실사용 단계로 급속히 전환되고 있으나, 동적 실행 특성으로 인해 실행이 확률적이며 오류가 발생하기 쉽고 재현 및 디버깅이 어렵다. 기존 벤치마크는 주로 과제 성공률 등 애플리케이션 수준 결과에 초점을 맞추고 실행 행동에 대한 표준화된 가시성을 제공하지 않아 이질적인 MAS 아키텍처 간의 통제된 비교가 어려웠다. 본 논문에서는 LLM 기반 MAS의 테스트, 신뢰성 및 관측성을 위한 평가 스위트인 MAESTRO를 제안한다. MAESTRO는 통합 인터페이스를 통해 MAS 구성 및 실행을 표준화하고, 네이티브와 서드파티 MAS를 모두 통합할 수 있도록 예제 저장소와 경량 어댑터를 제공한다. 또한 프레임워크에 독립적인 실행 트레이스와 시스템 수준 신호(예: 지연시간, 비용, 실패)를 내보낸다. 우리는 12개의 대표적인 MAS(주요 에이전트 프레임워크와 상호작용 패턴 포함)를 MAESTRO에 구현하고, 반복 실행, 백엔드 모델, 도구 설정을 변형한 통제 실험을 수행하였다. 사례 연구 결과, MAS 실행은 구조적으로는 안정적이지만 시간적으로는 변동성이 커서 실행 간 성능 및 신뢰성에 큰 차이가 발생한다는 것을 확인했다. 또한 MAS 아키텍처가 자원 사용 프로파일, 재현성, 비용‑지연‑정확도 트레이드오프에 가장 큰 영향을 미치며, 백엔드 모델이나 도구 설정 변화보다 우위에 있음을 발견했다. 전반적으로 MAESTRO는 체계적인 평가를 가능하게 하며, 에이전트 시스템 설계 및 최적화를 위한 실증적 가이드를 제공한다.💡 논문 핵심 해설 (Deep Analysis)
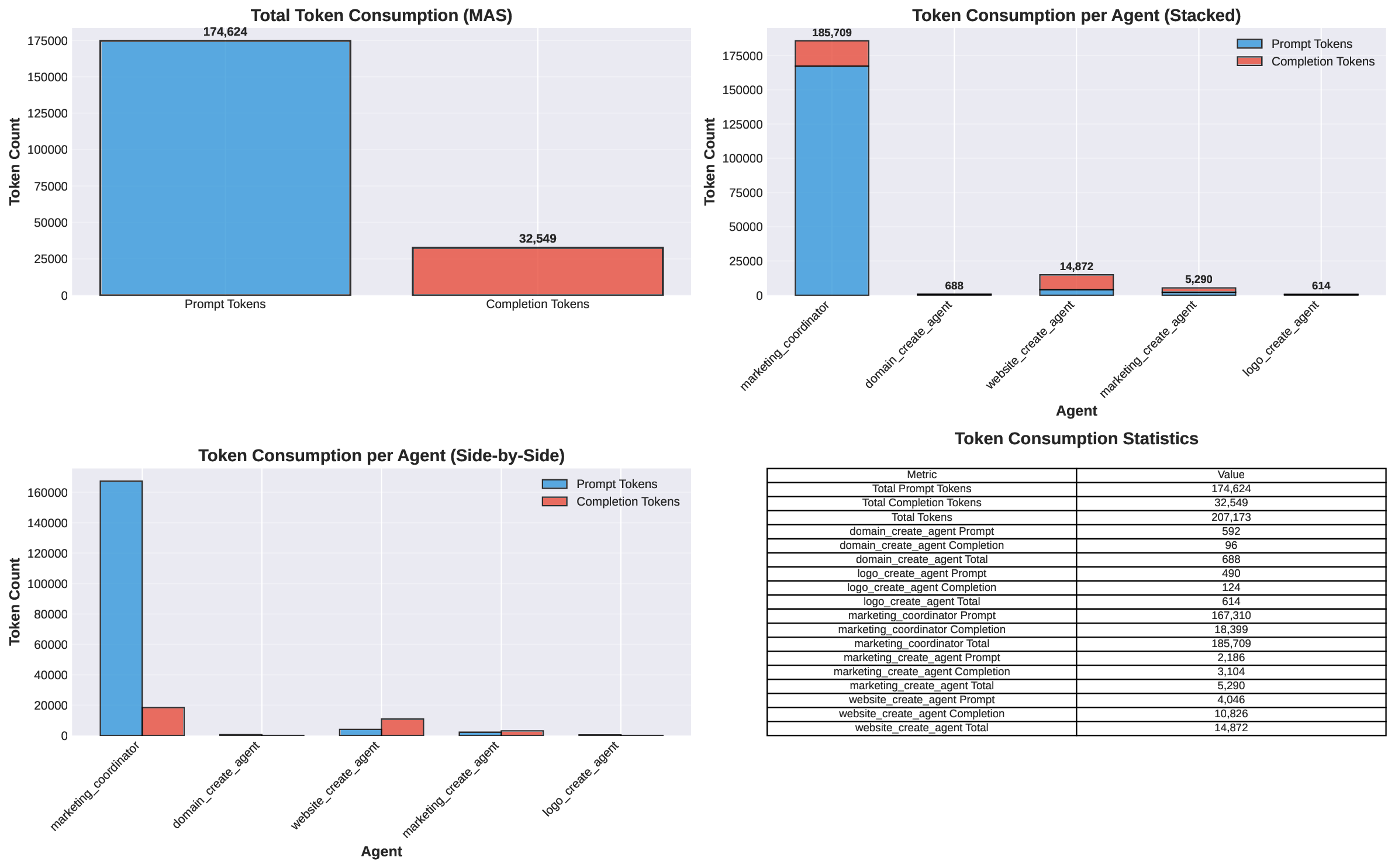
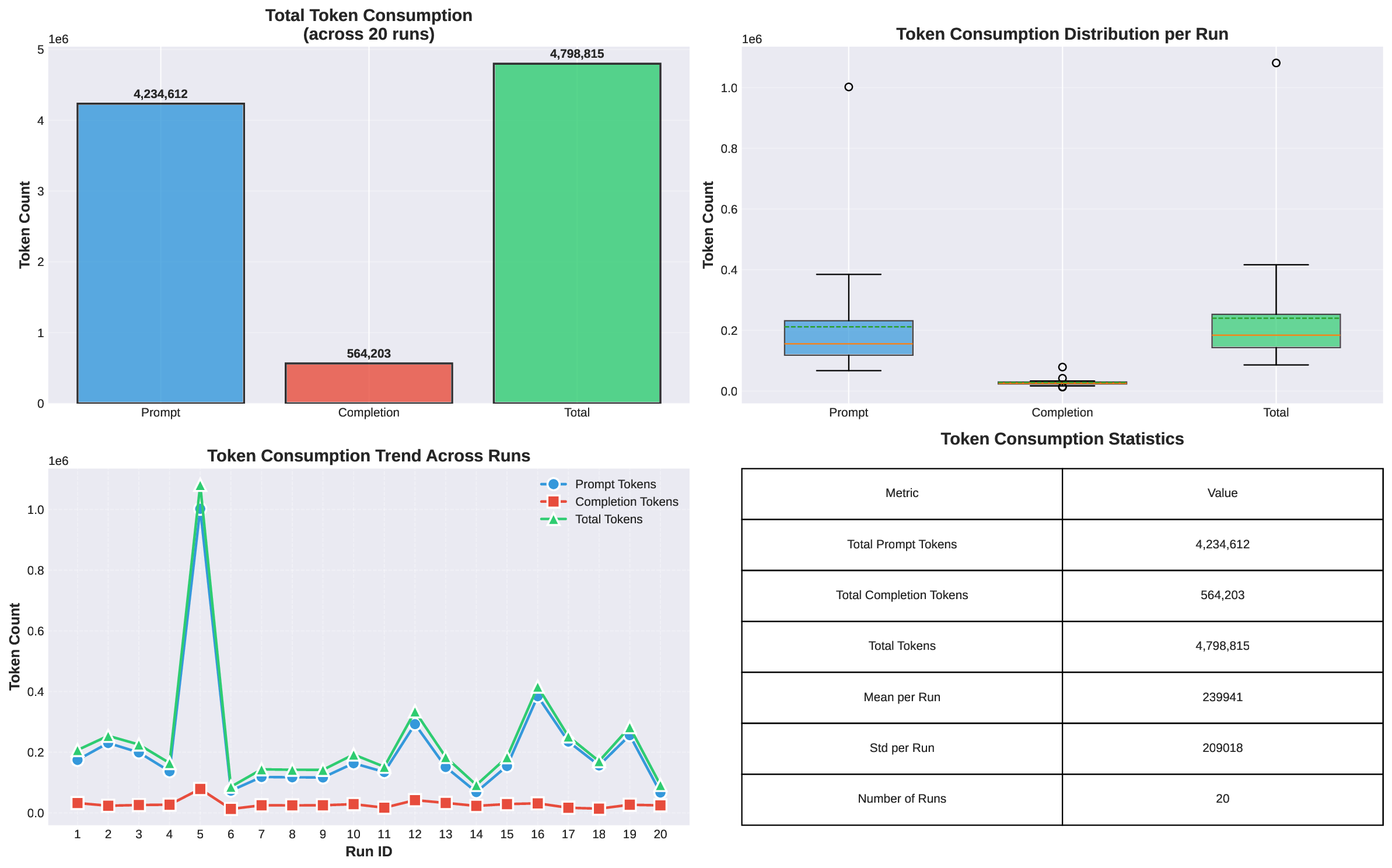
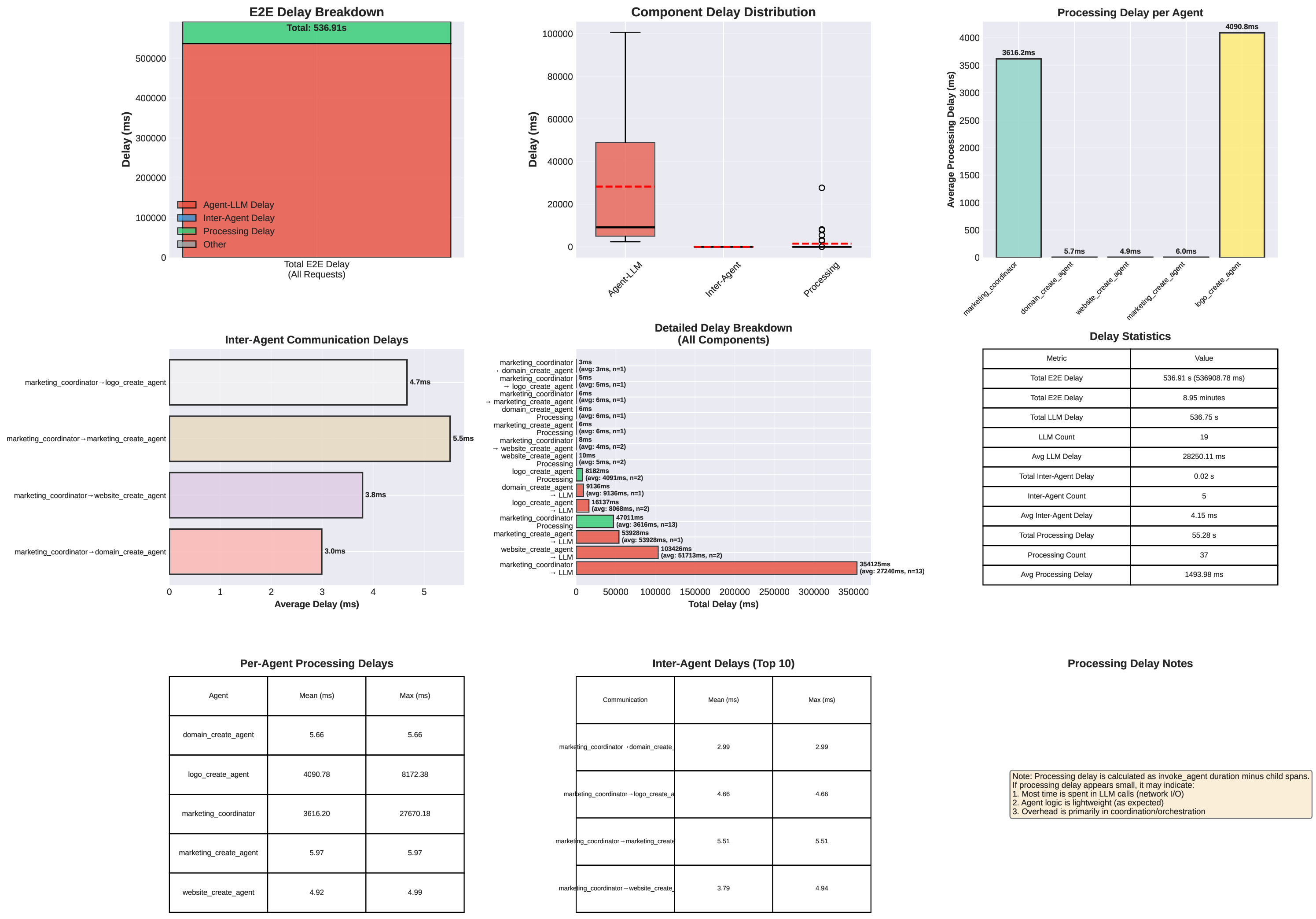
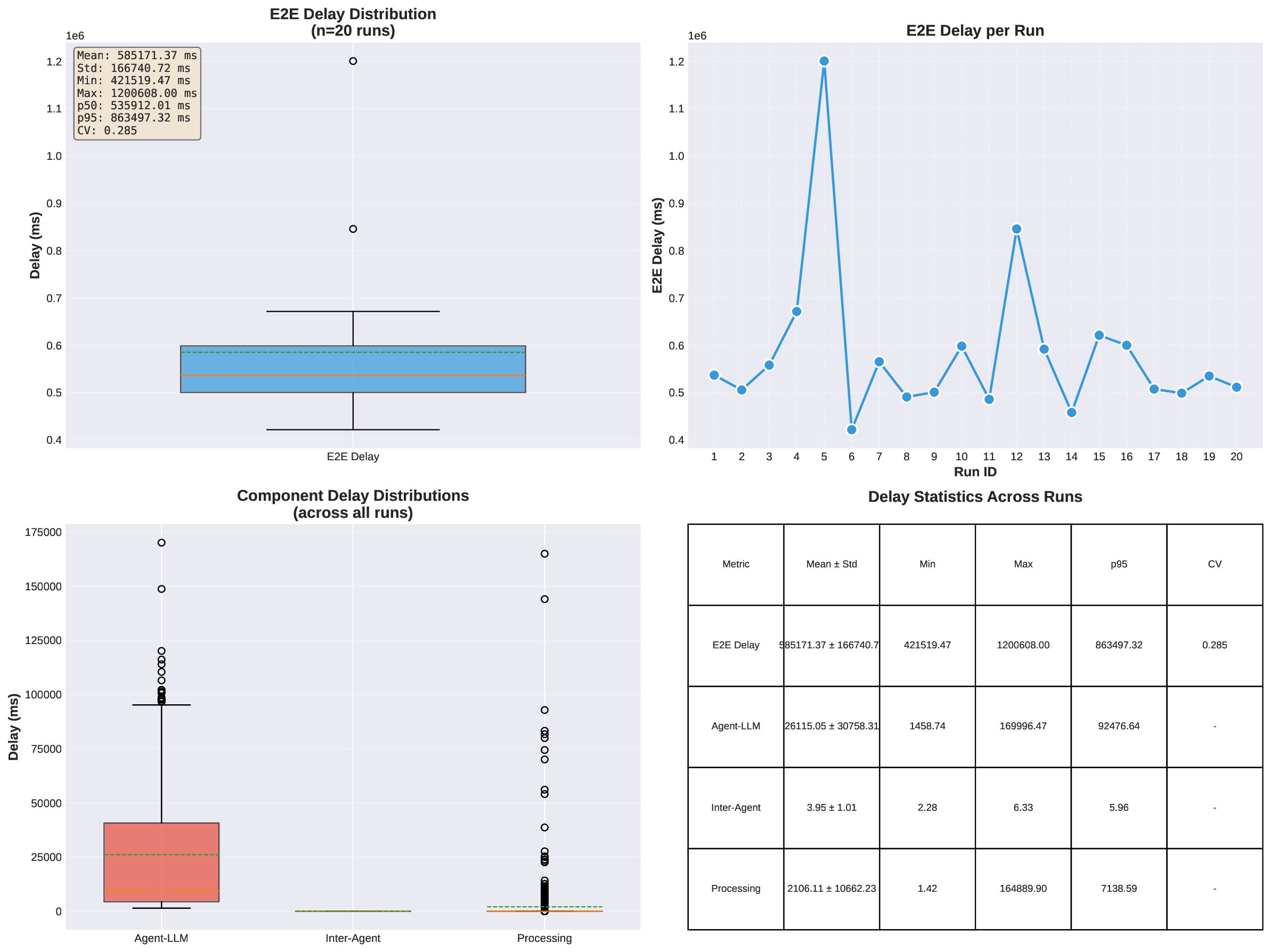
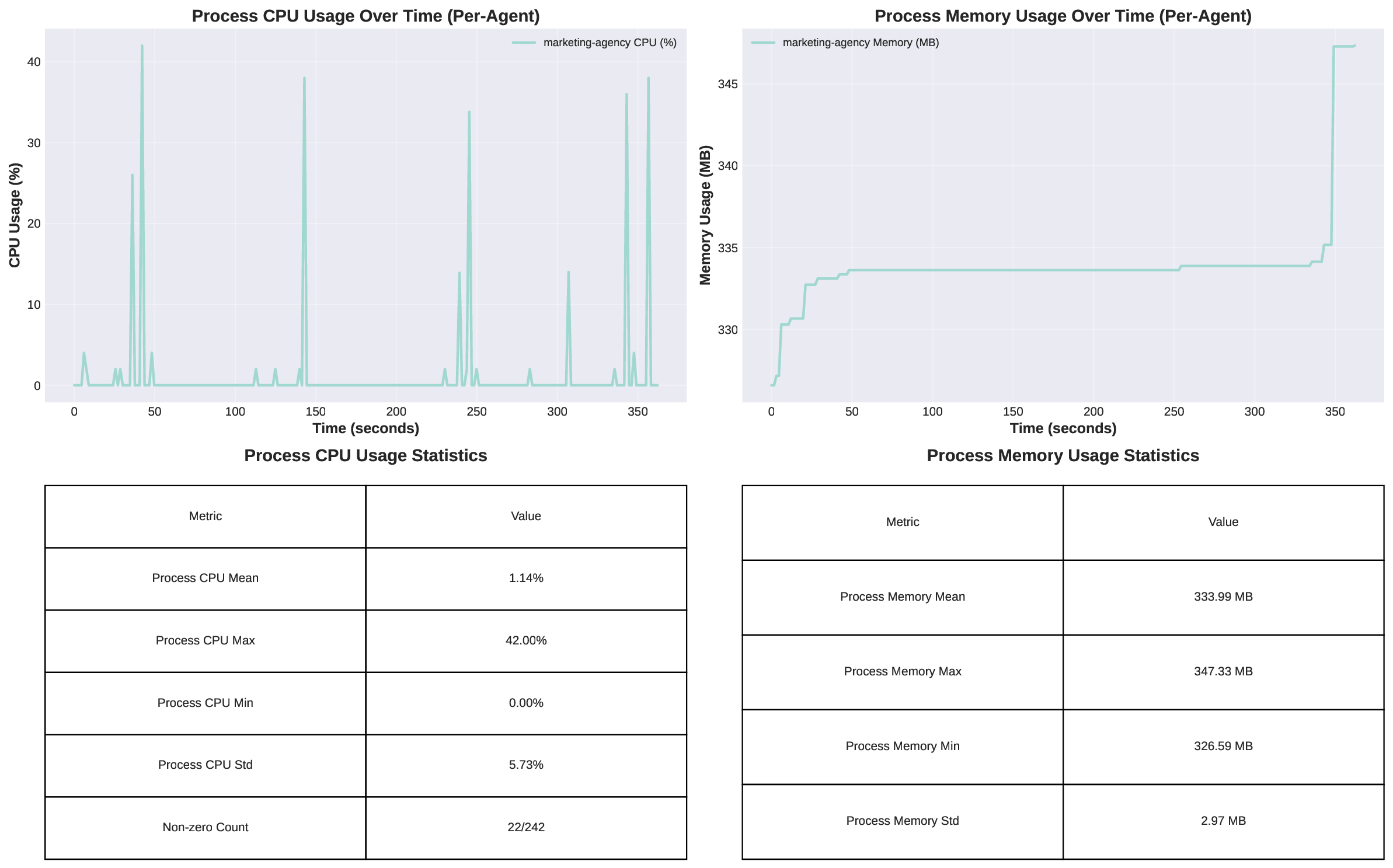
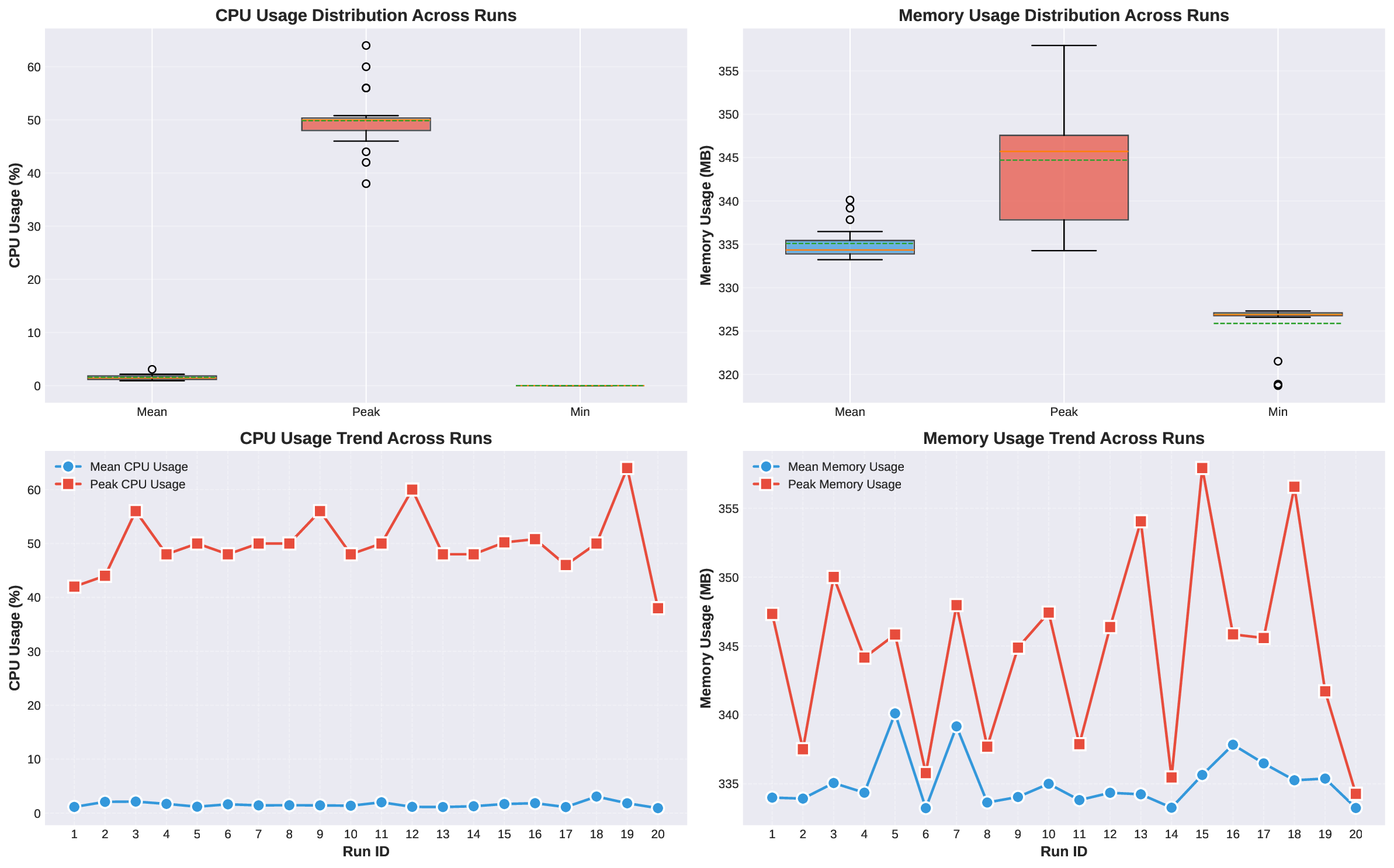
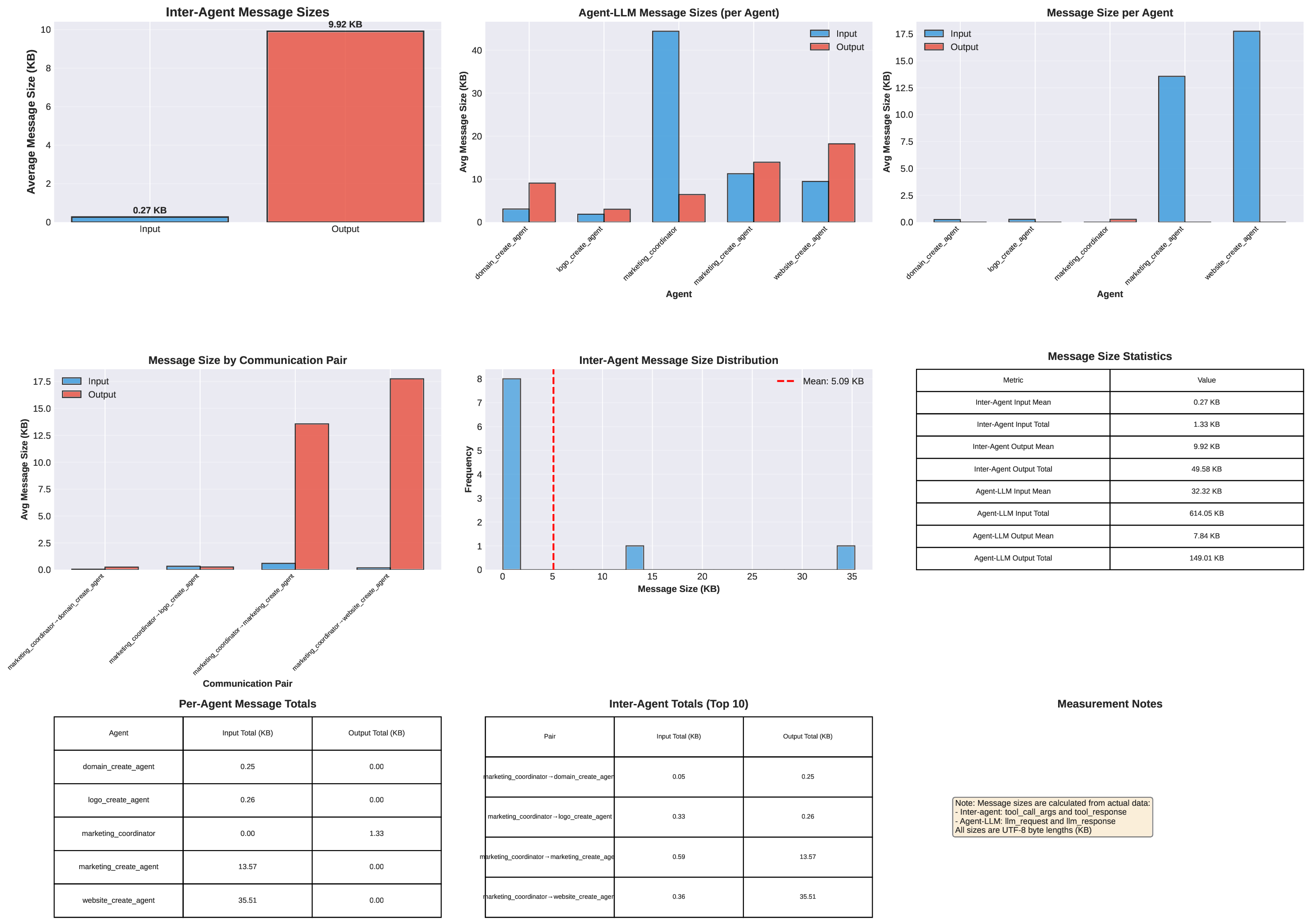
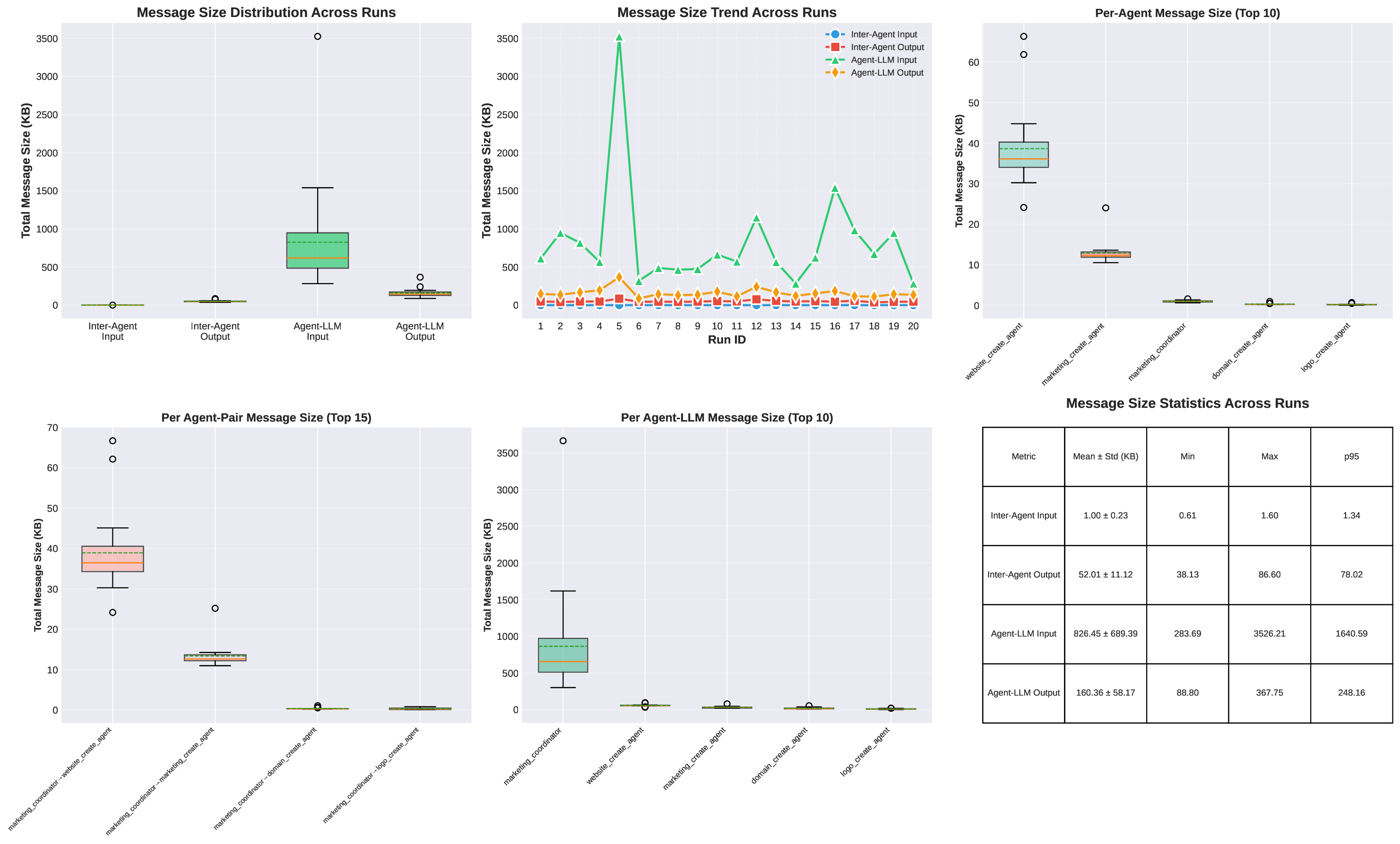
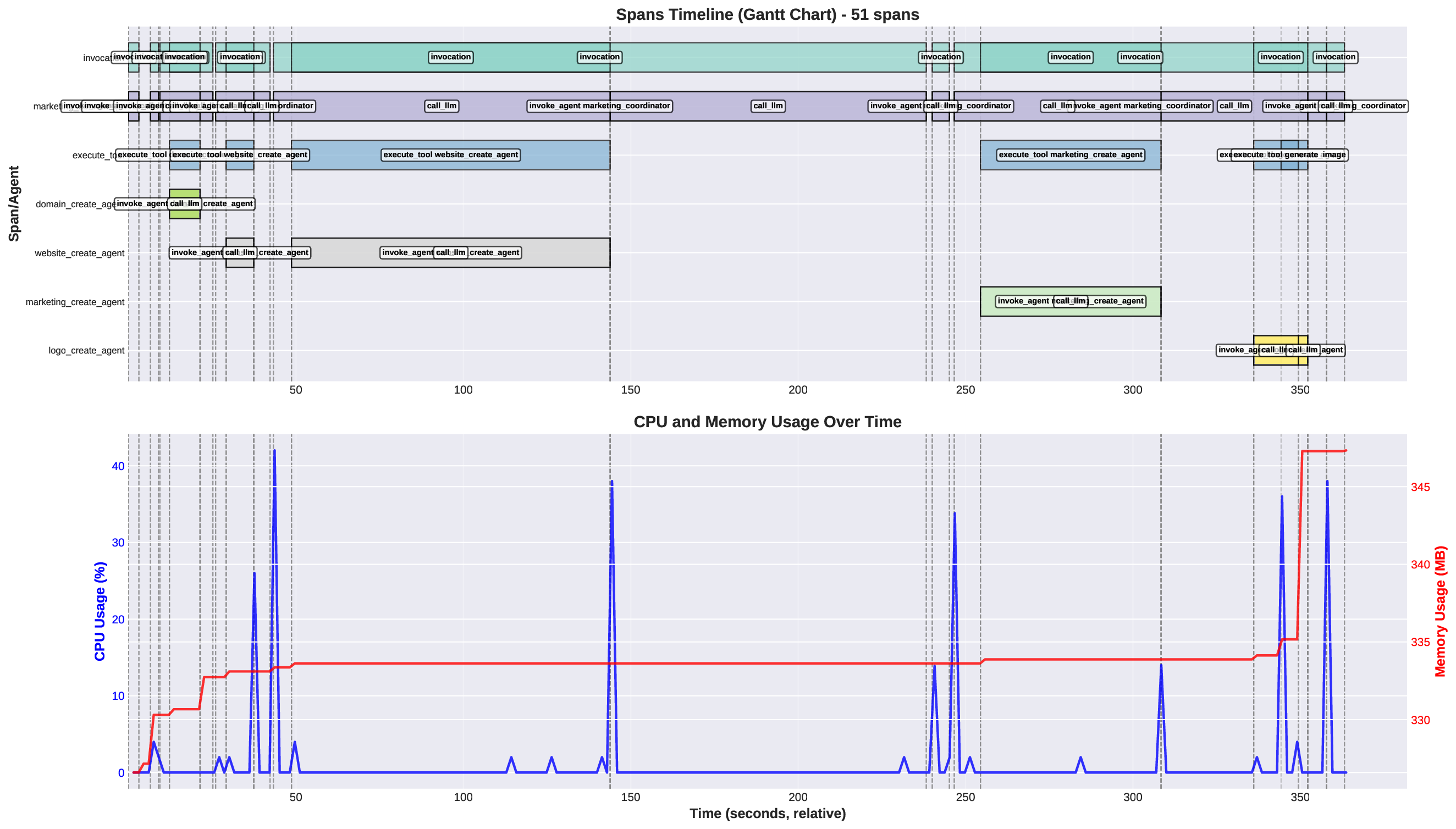
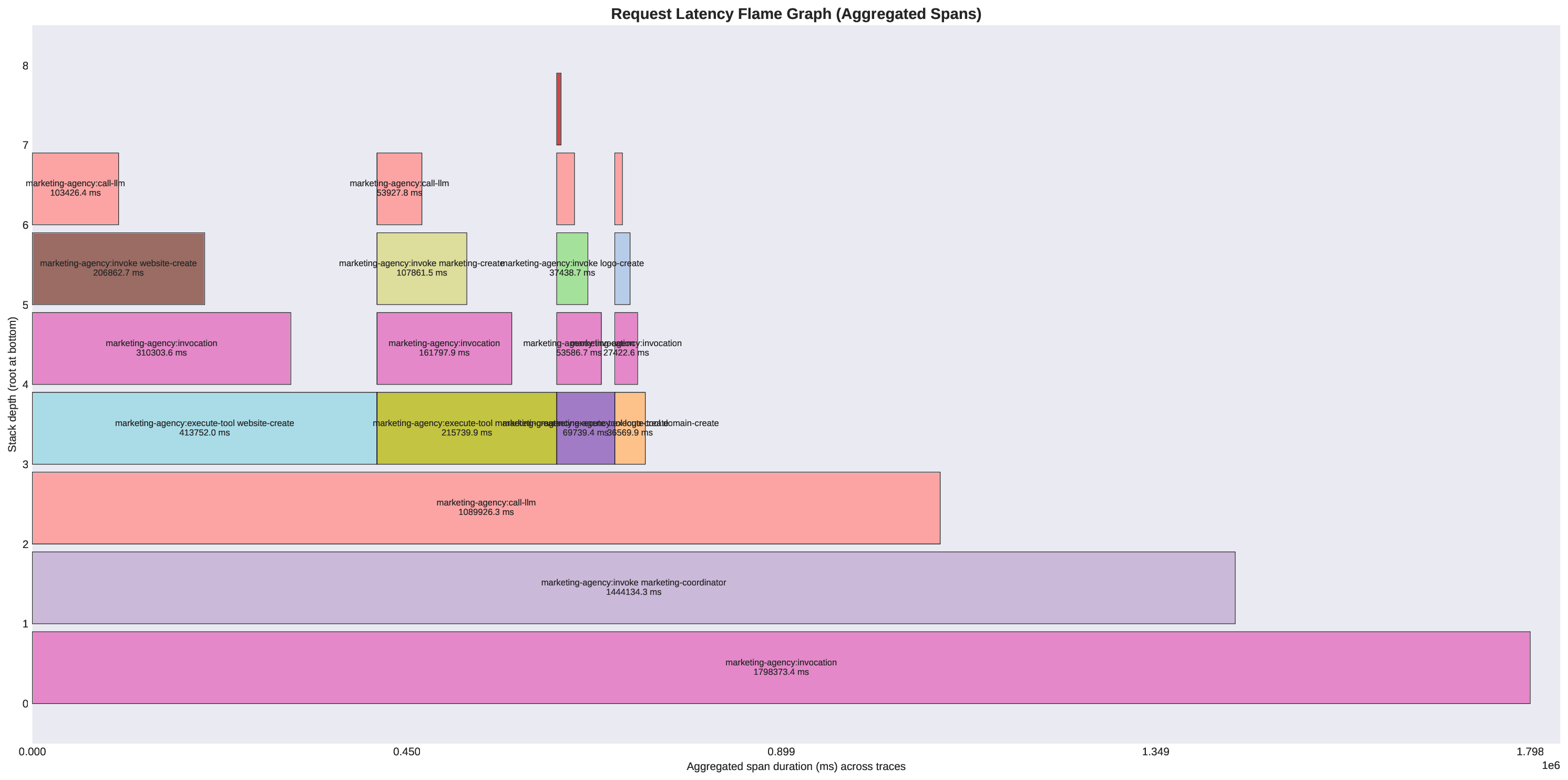
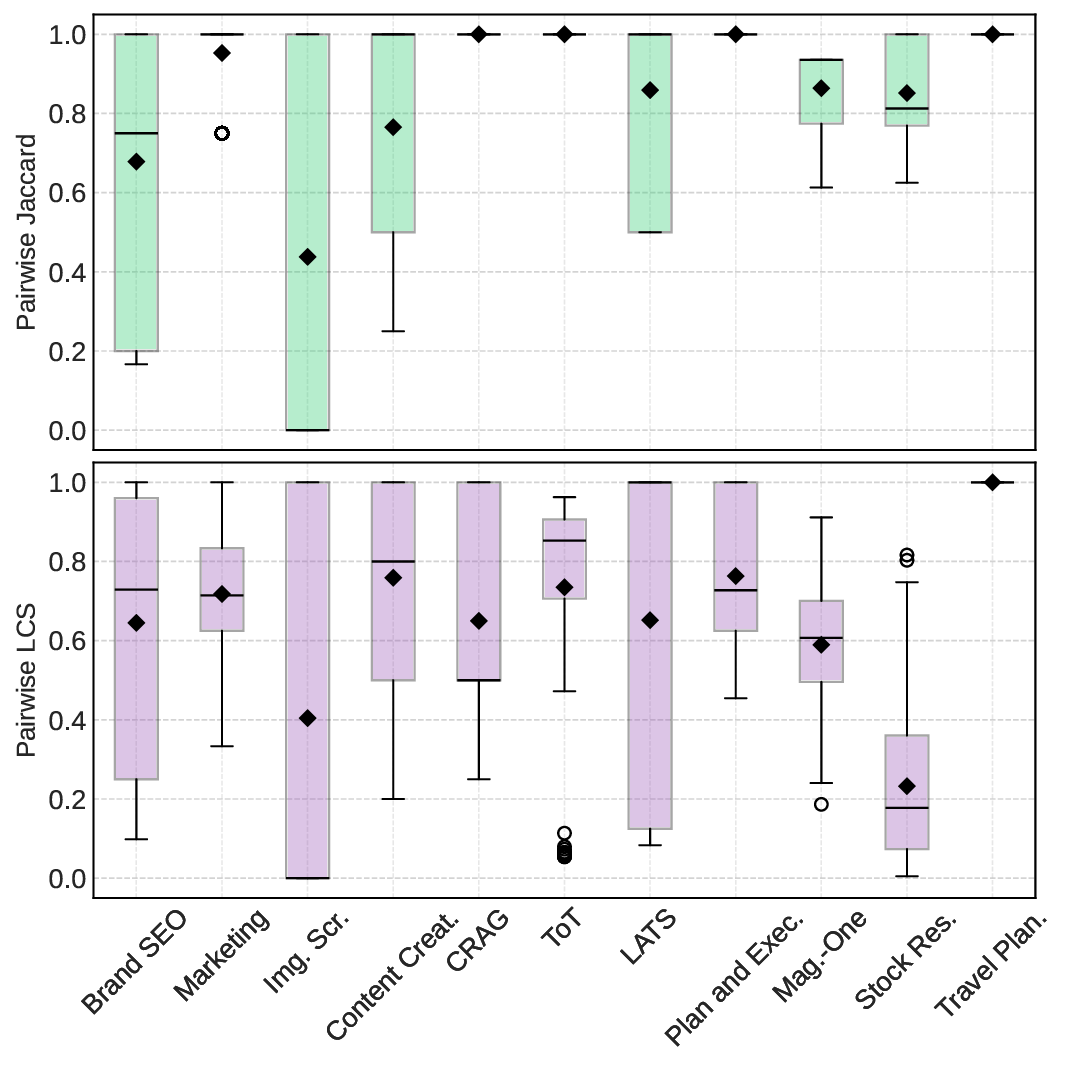
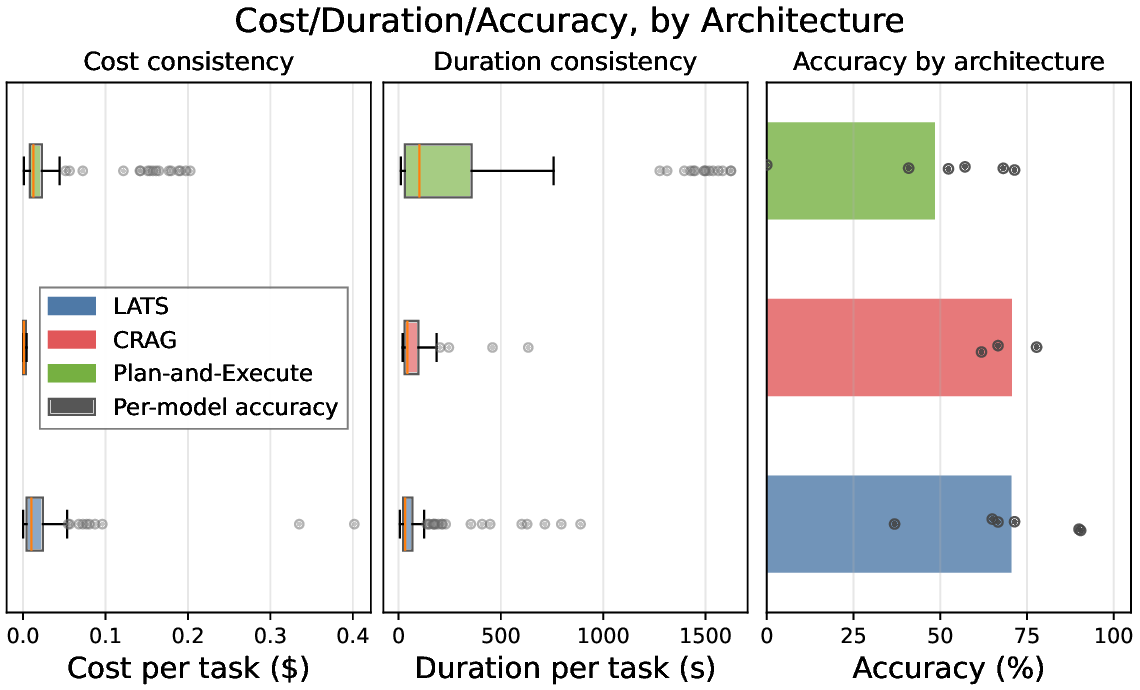
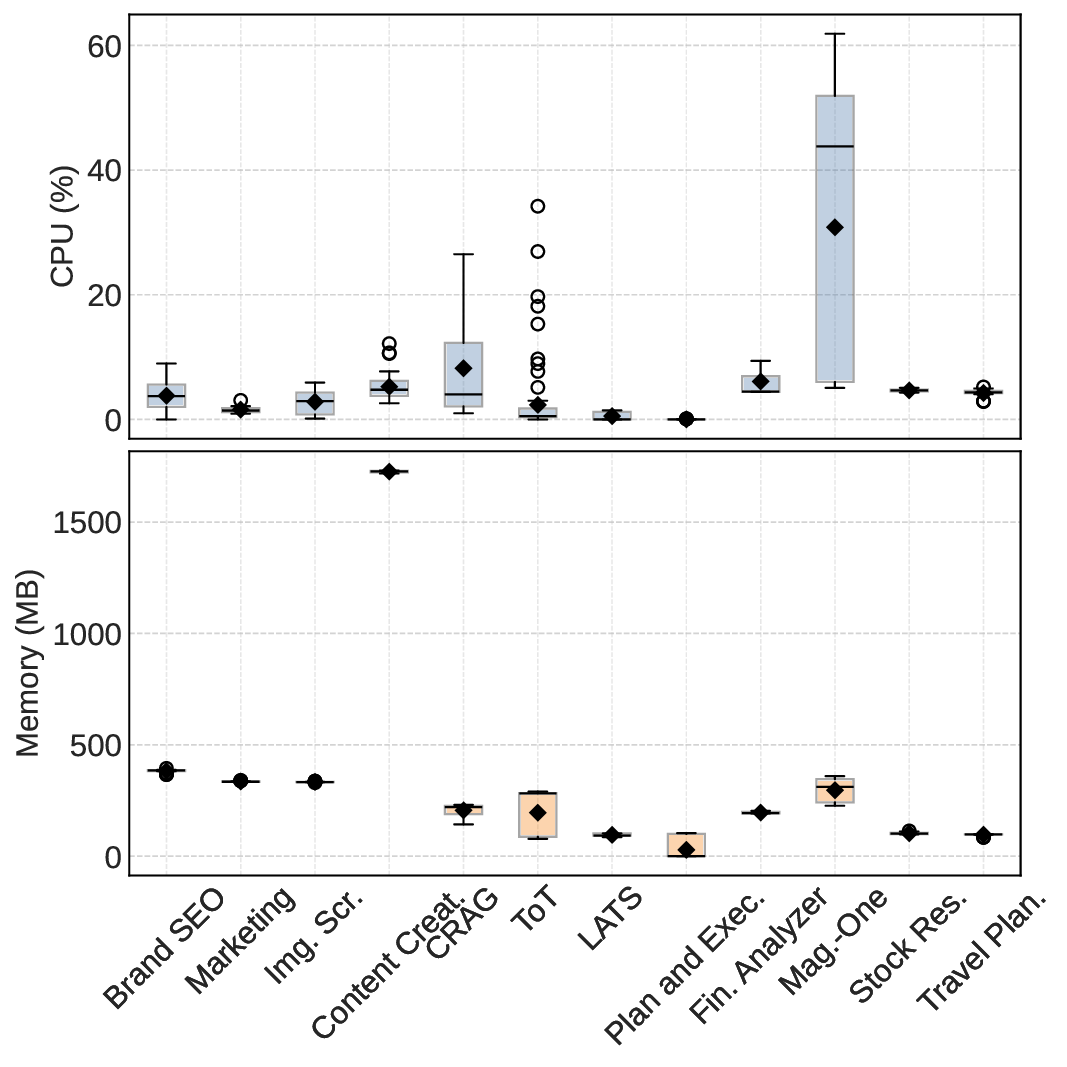
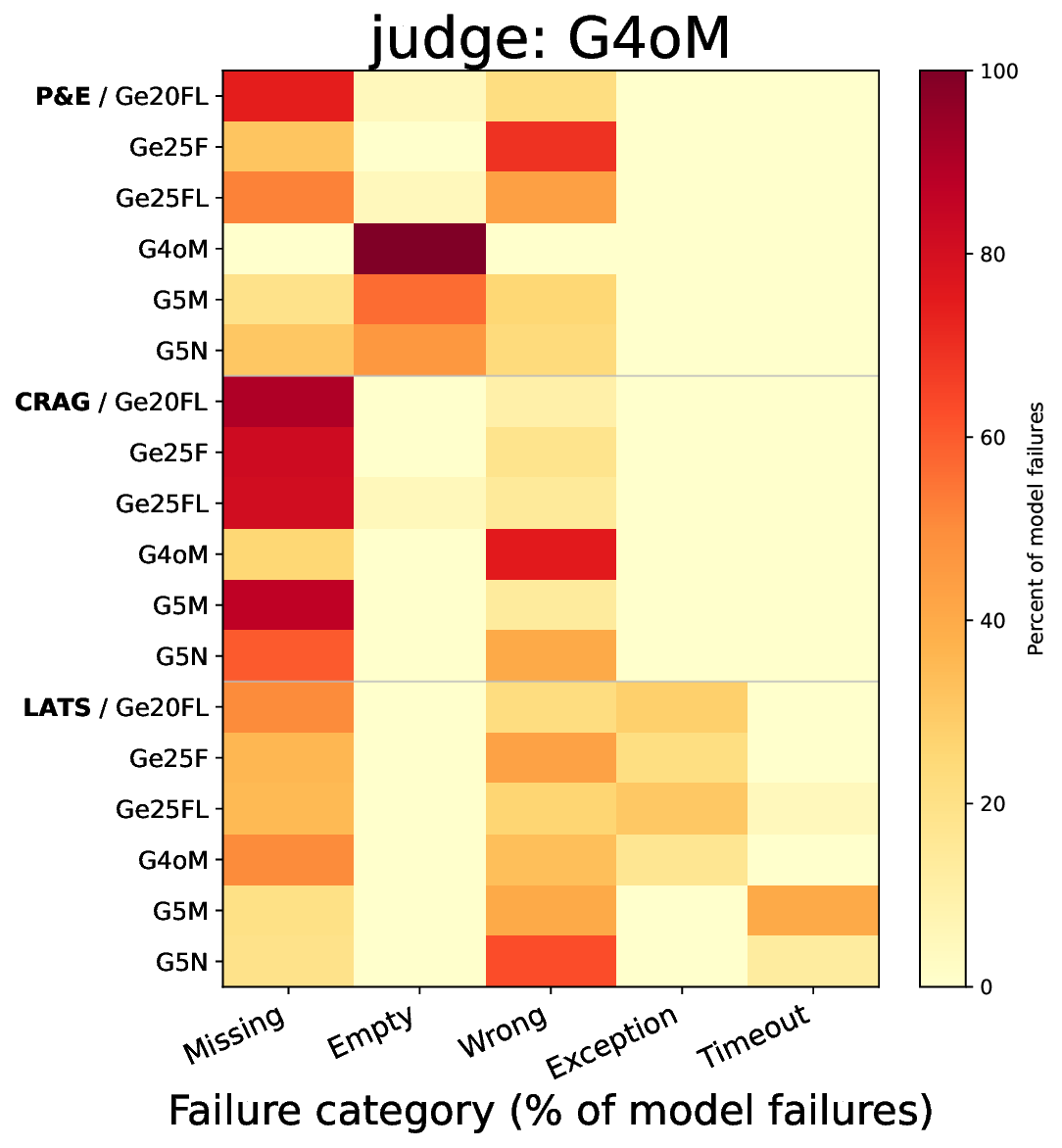
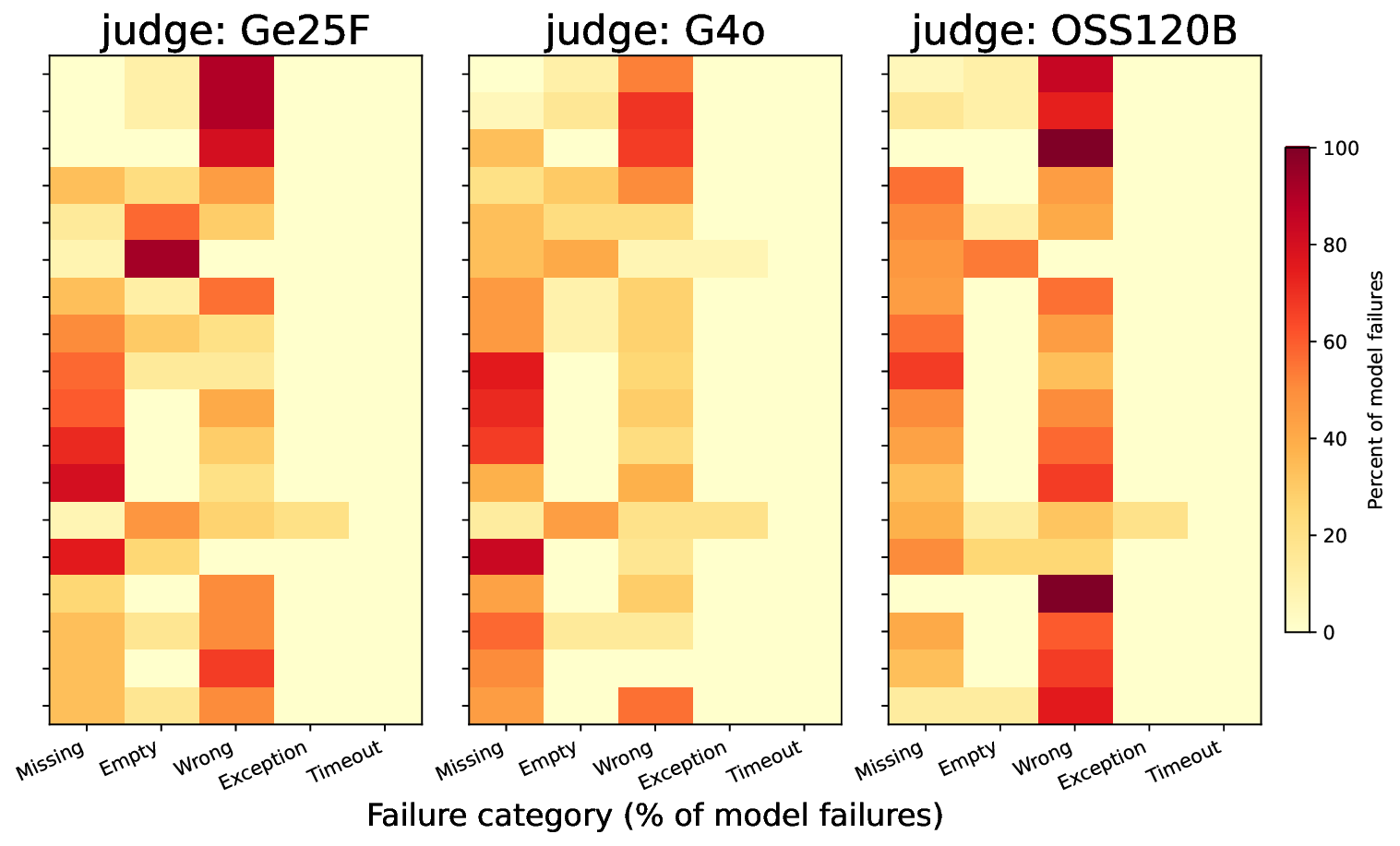
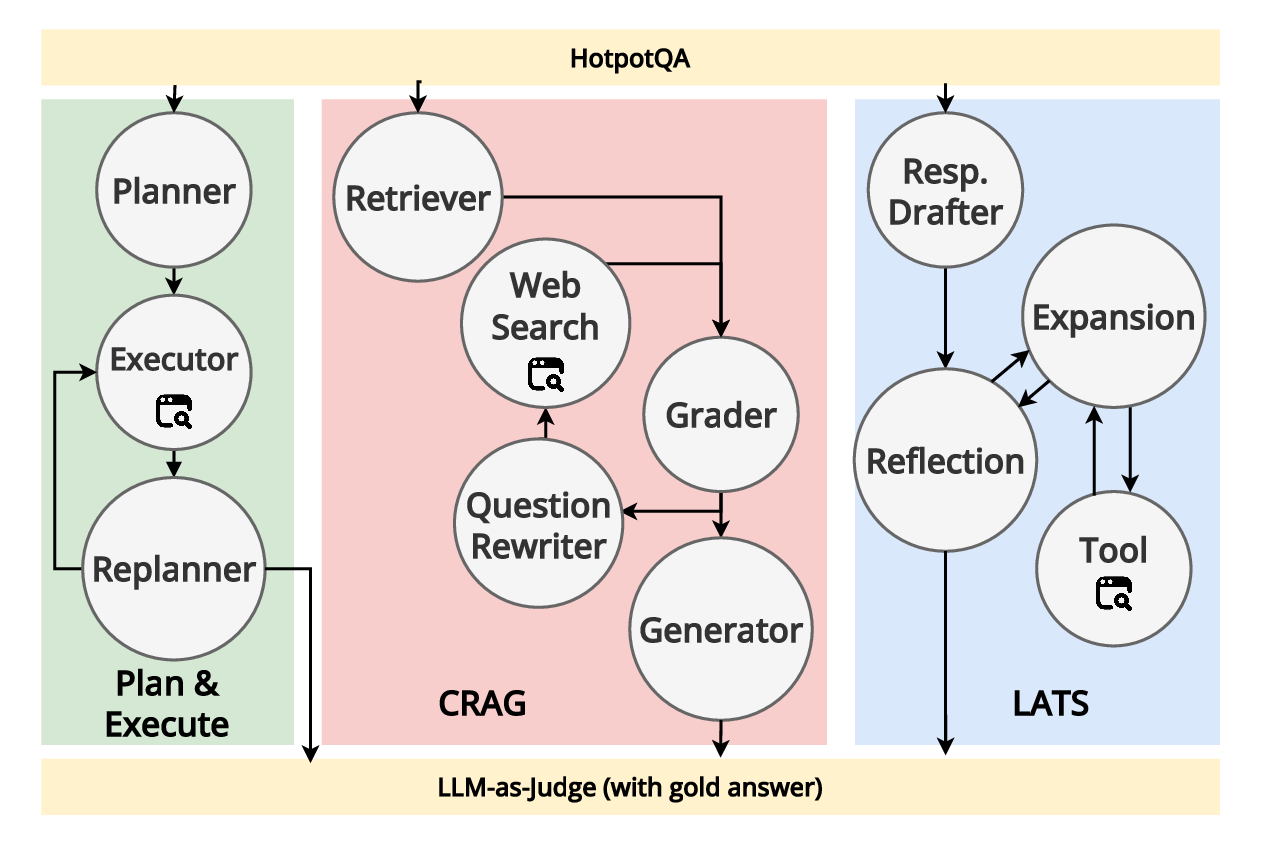
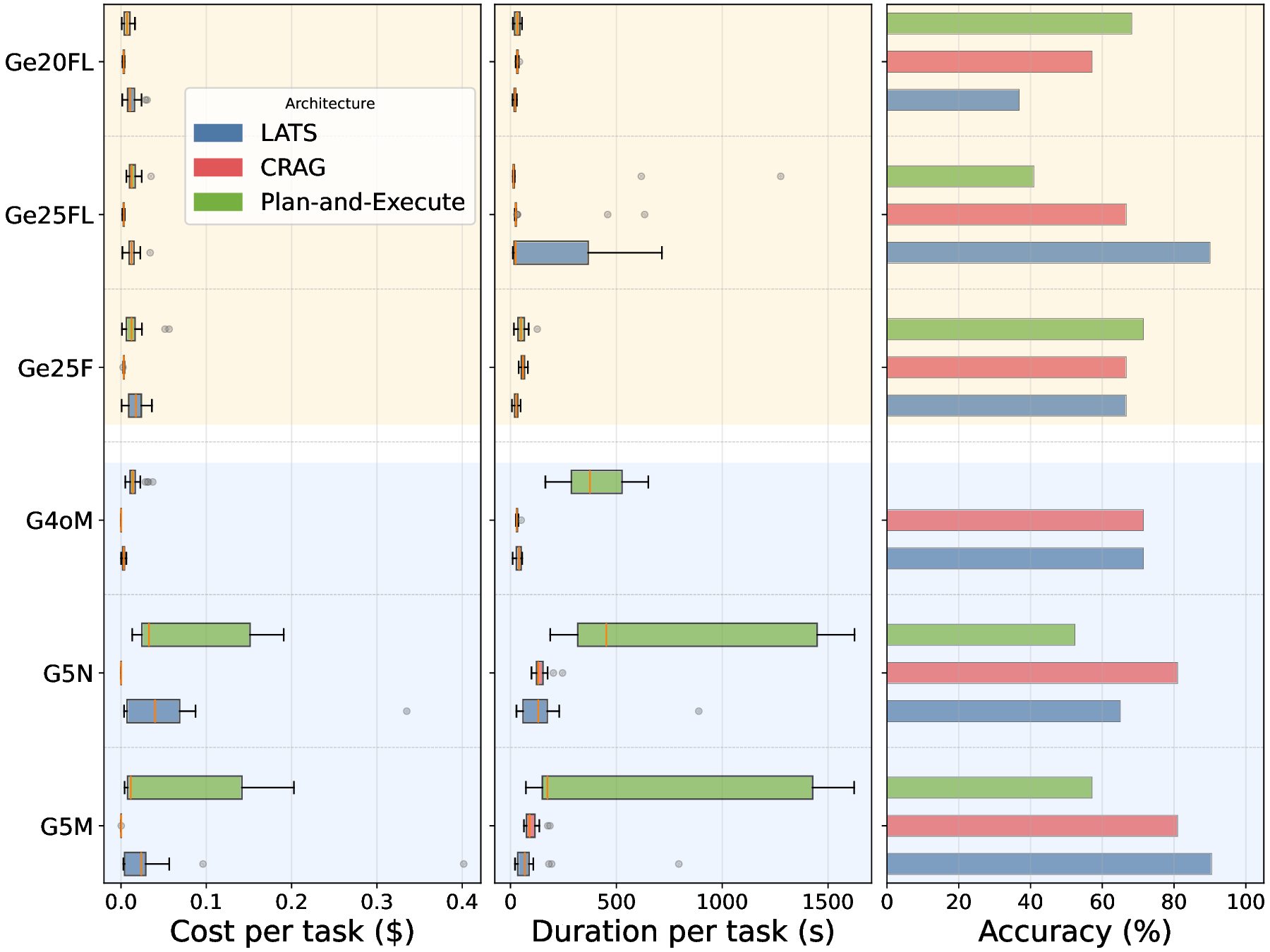
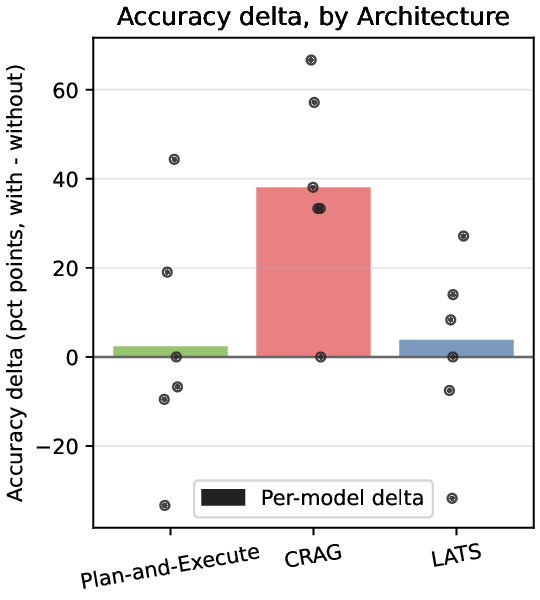
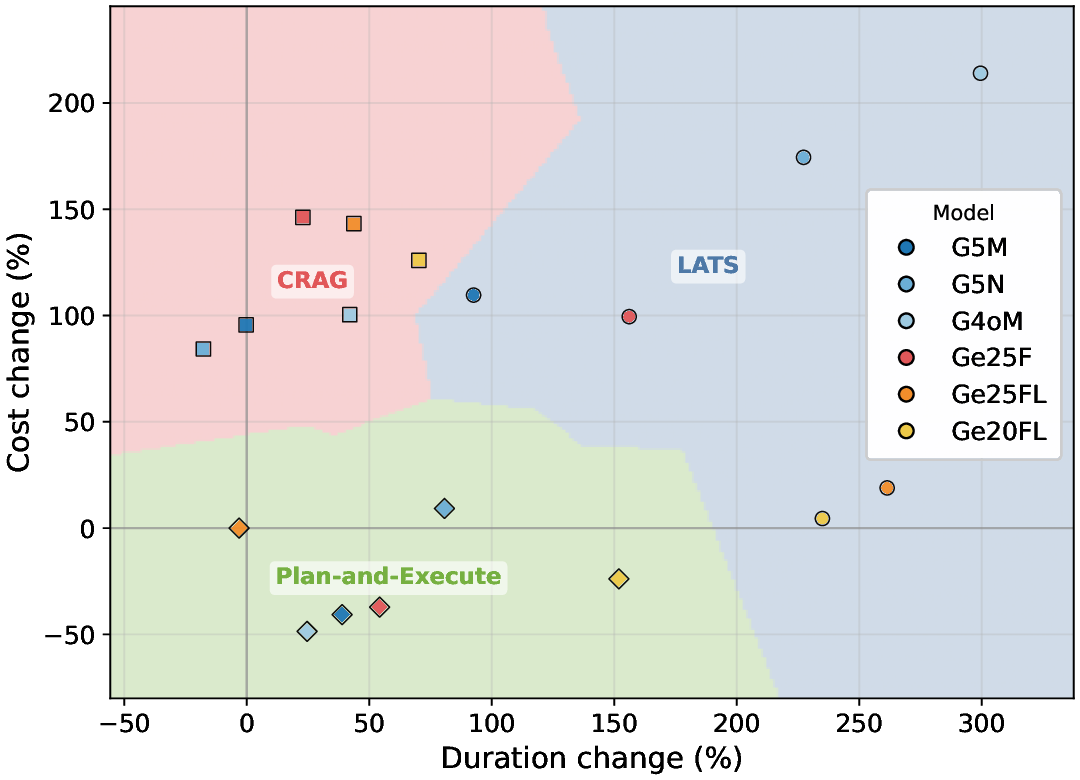
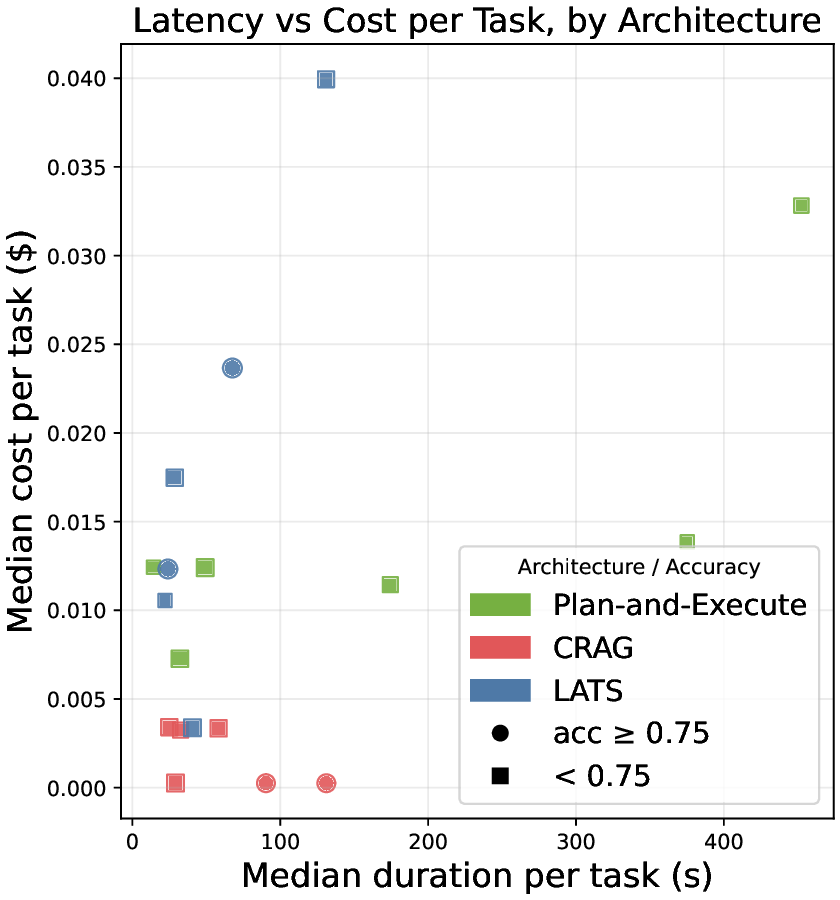
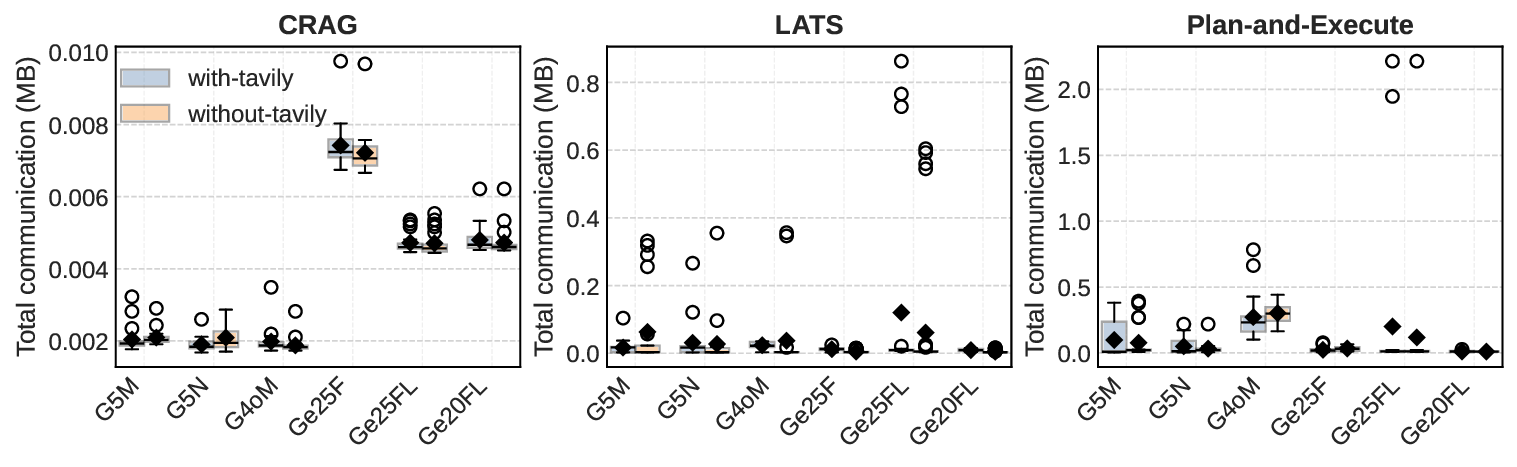
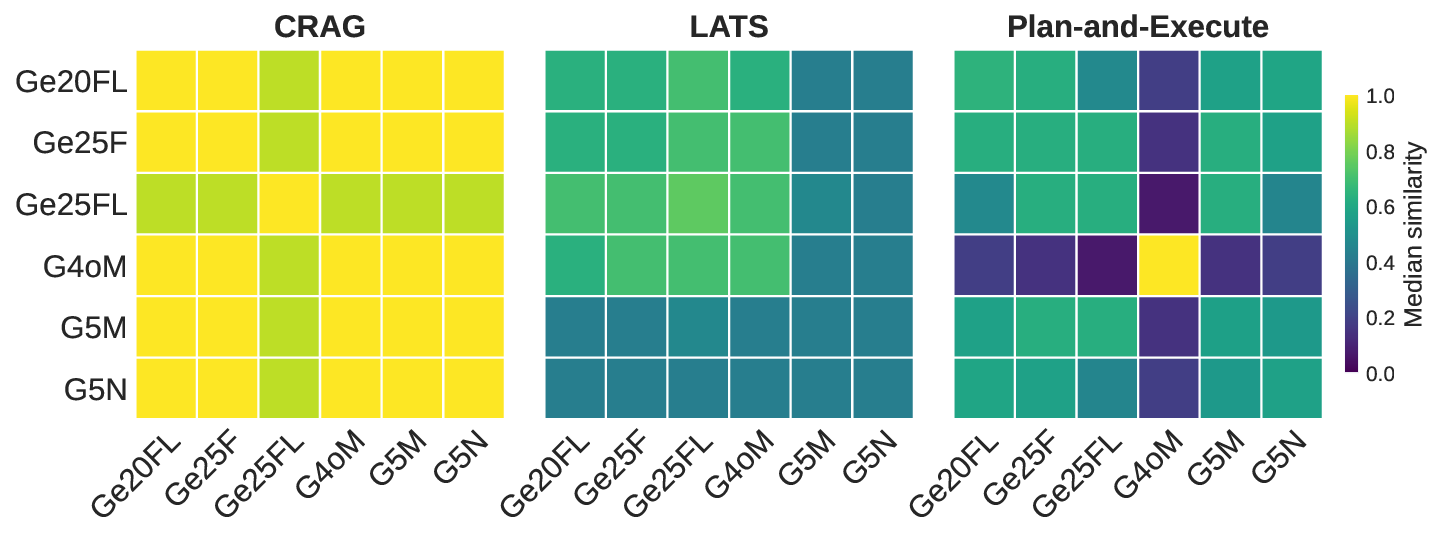
두 번째 강점은 ‘프레임워크 독립적인 실행 트레이스’와 ‘시스템 수준 신호’를 동시에 수집한다는 점이다. 트레이스는 에이전트 간 메시지 교환, 툴 호출, LLM 프롬프트·응답 등을 시간 순서대로 기록하고, 메타데이터(예: 토큰 사용량, API 비용, 지연시간, 오류 코드)를 함께 저장한다. 이러한 데이터는 사후 분석을 통해 구조적 안정성(예: 동일한 의사결정 트리 유지)과 시간적 변동성(예: 응답 지연, 재시도 횟수) 사이의 관계를 정량화할 수 있게 한다. 논문에서는 12개의 MAS를 대상으로 반복 실행(30회 이상), 백엔드 모델 교체(GPT‑3.5 vs. GPT‑4), 툴 설정(검색 엔진, 코드 실행기) 변화를 적용한 실험을 수행했으며, 결과는 다음과 같다. (1) 구조적 안정성은 대부분의 MAS에서 높은 편이었지만, 실행 시간과 비용은 실행마다 크게 달라졌다. (2) 아키텍처 차이가 리소스 프로파일에 가장 큰 영향을 미쳤으며, 같은 백엔드 모델을 사용하더라도 아키텍처에 따라 비용‑지연‑정확도 트레이드오프가 크게 달라졌다. (3) 모델 교체는 성능(정답률)에는 미미한 영향을 주었지만, 비용과 지연시간에는 눈에 띄는 차이를 만들었다.
이러한 결과는 두 가지 중요한 시사점을 제공한다. 첫째, MAS 설계 단계에서 ‘아키텍처 선택’이 비용 효율성과 신뢰성에 결정적인 역할을 하므로, 단순히 최신 LLM을 적용하는 것이 최선이 아니다. 둘째, MAESTRO와 같은 표준화된 평가 프레임워크가 없었다면, 위와 같은 미세한 차이를 발견하기 어려웠을 것이다. 다만 논문에는 몇 가지 제한점도 존재한다. 현재 지원하는 12개의 MAS는 주로 오픈소스 프레임워크에 국한되어 있어, 기업용 폐쇄형 시스템에 대한 적용 가능성을 검증하지 않았다. 또한, 트레이스 수집이 로그 기반이기 때문에 실시간 모니터링이나 자동화된 오류 복구와 같은 ‘관측성(Observability)’ 기능을 완전하게 구현하지는 못한다. 향후 연구에서는 보다 다양한 도메인(예: 금융, 의료)과 실시간 대시보드 연동을 통해 MAESTRO의 적용 범위를 확대하고, 자동화된 원인 분석 및 복구 메커니즘을 추가하는 것이 필요하다.
요약하면, MAESTRO는 LLM 기반 멀티에이전트 시스템의 테스트·신뢰성·관측성을 체계화하는 첫 번째 통합 플랫폼이며, 아키텍처 수준에서의 설계 선택이 시스템 전체 비용·성능에 미치는 영향을 실증적으로 보여준다. 이는 학계와 산업계 모두에게 MAS 개발·운영에 있어 보다 과학적인 의사결정을 가능하게 하는 중요한 도구가 될 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리