순수 강화학습 그래디언트로 온라인 파인튜닝하는 Decision Transformer
📝 원문 정보
- Title: Online Finetuning Decision Transformers with Pure RL Gradients
- ArXiv ID: 2601.00167
- 발행일: 2026-01-01
- 저자: Junkai Luo, Yinglun Zhu
📝 초록 (Abstract)
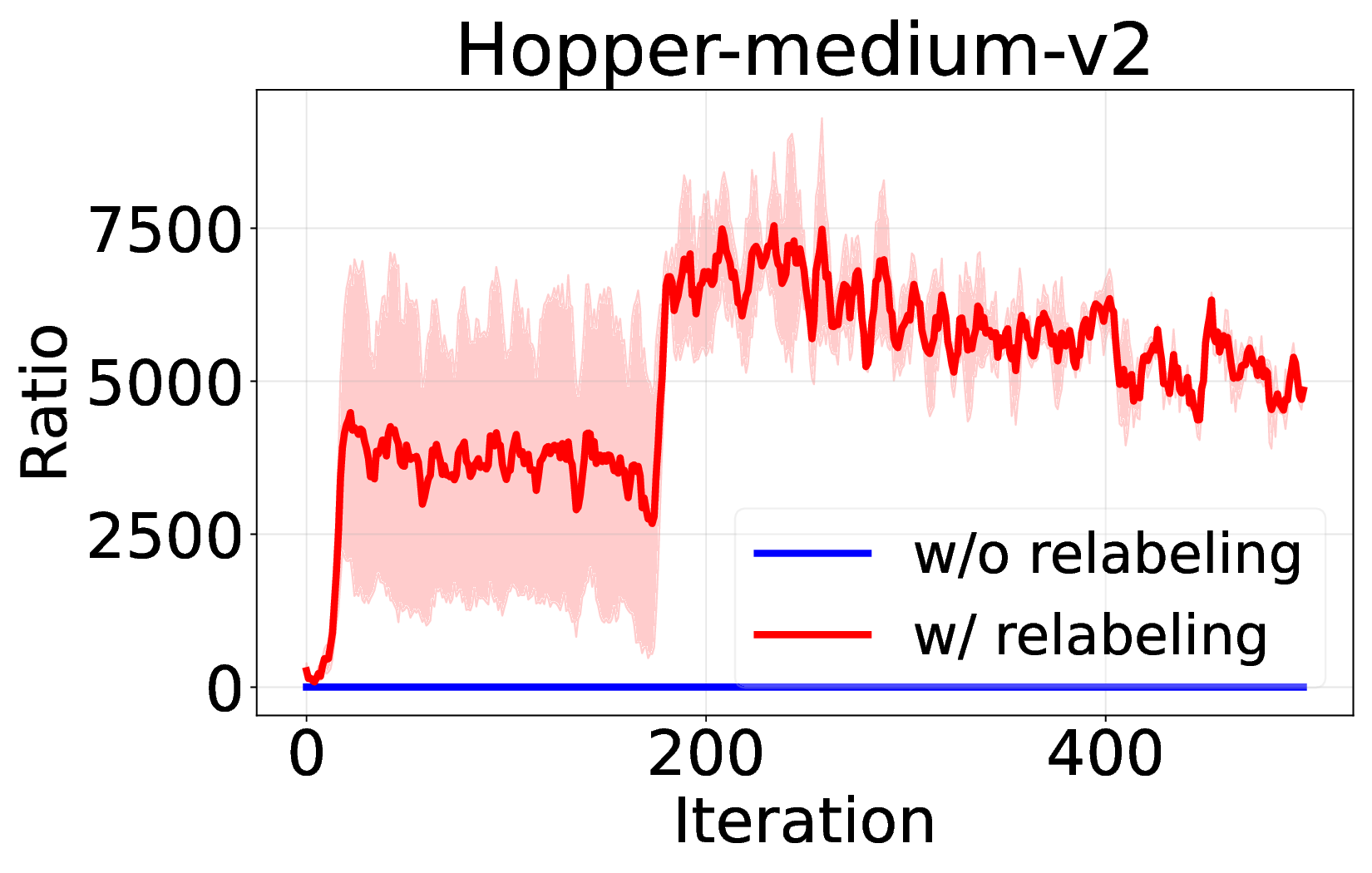
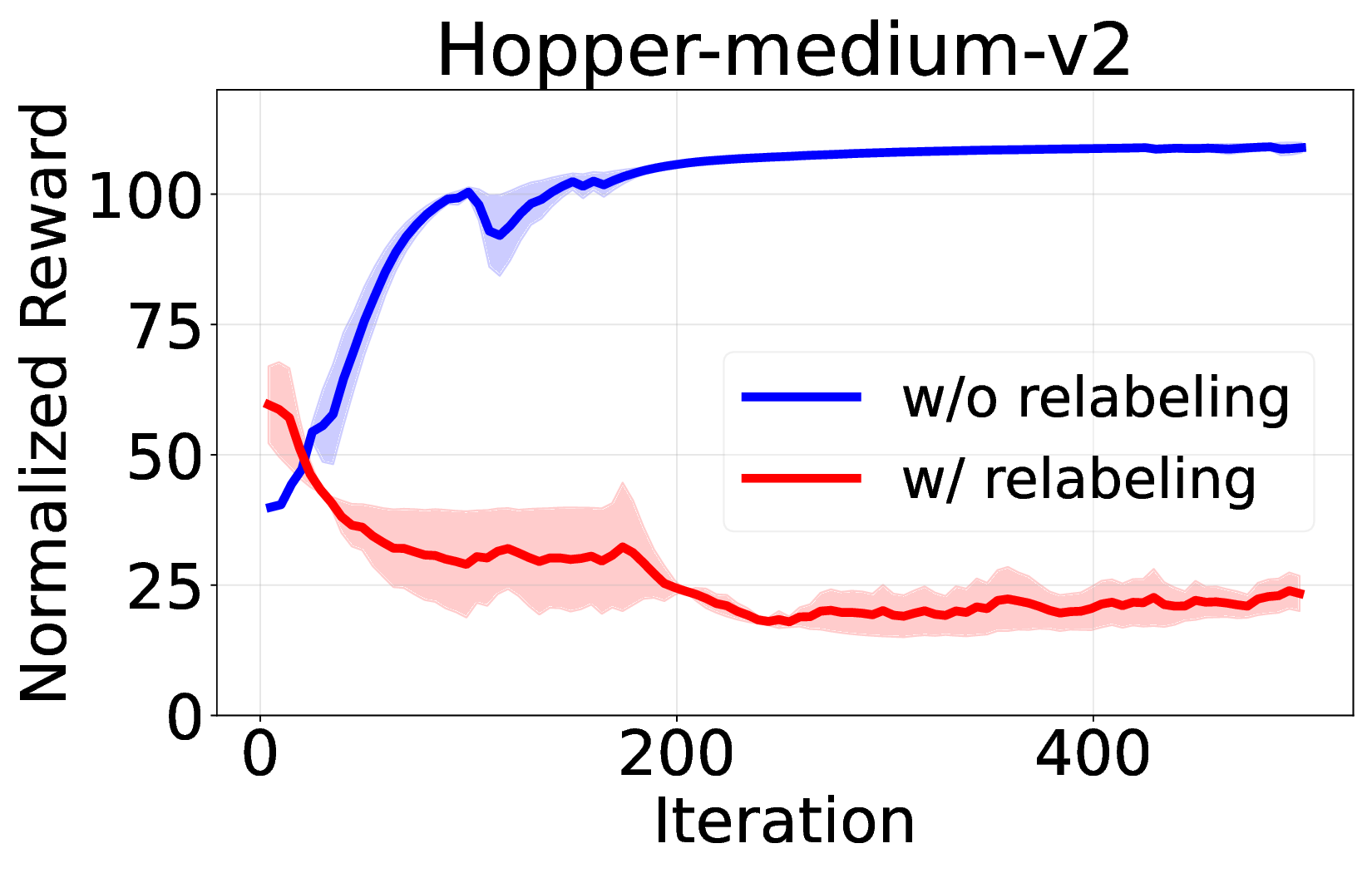
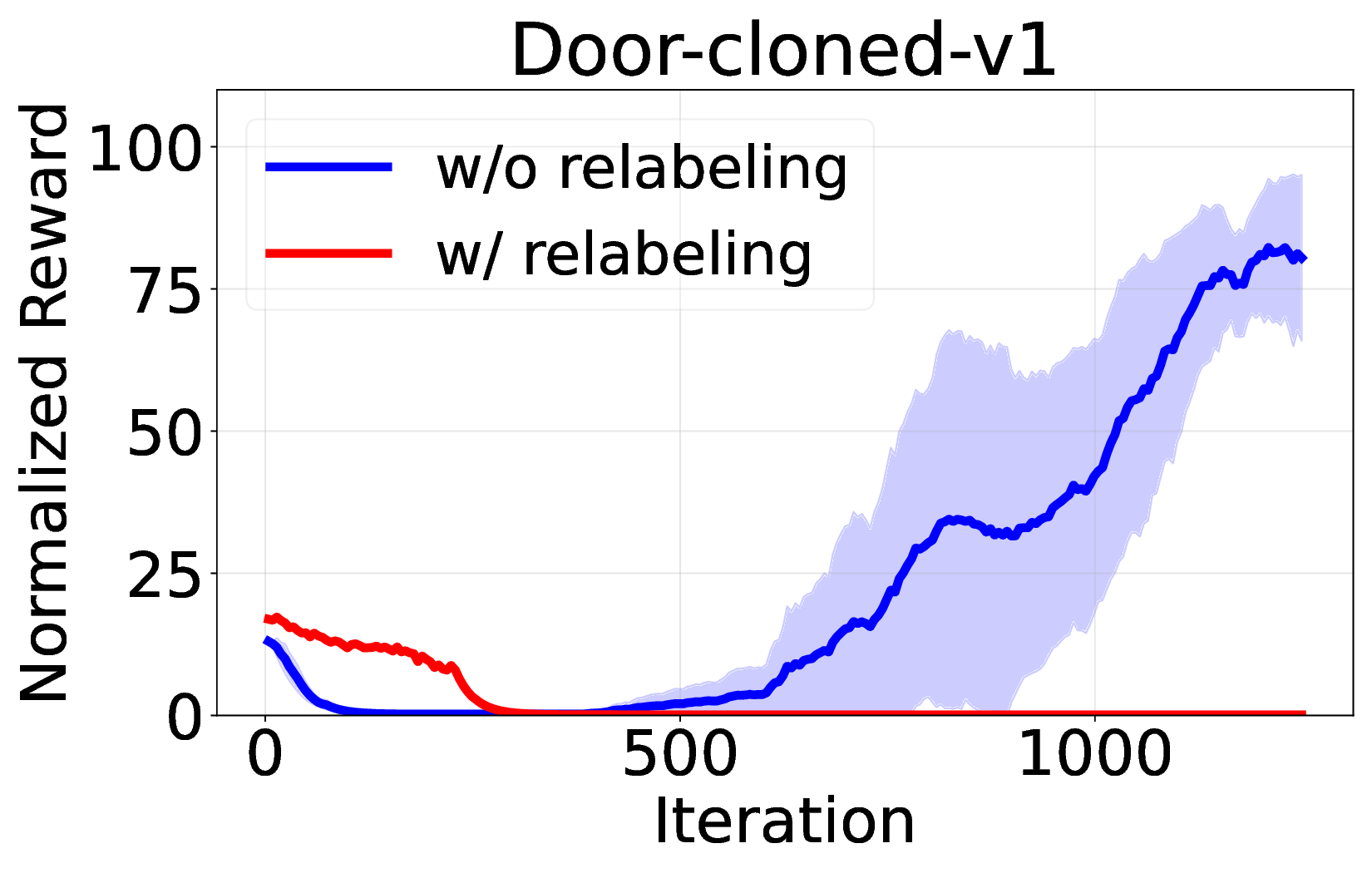
Decision Transformer( DT)는 오프라인 강화학습을 시퀀스 모델링 문제로 재구성함으로써 주목받는 프레임워크이다. 그러나 기존 연구들은 온라인 파인튜닝 단계에서도 여전히 지도학습 기반의 시퀀스‑모델링 목표에 의존하고 있어, 순수한 강화학습(RL) 그래디언트를 활용한 온라인 학습은 충분히 탐구되지 않았다. 본 논문은 온라인 DT에서 흔히 사용되는 ‘히스토리 반환 재라벨링’이 GRPO와 같은 중요도 샘플링 기반 RL 알고리즘과 근본적으로 충돌하여 학습 불안정을 초래한다는 점을 발견한다. 이를 바탕으로 순수 RL 그래디언트를 이용한 온라인 파인튜닝 알고리즘을 제안한다. 우리는 GRPO를 DT에 적용하면서 (1) 신용 할당을 개선하기 위한 서브‑트래젝터리 최적화, (2) 학습 안정성과 효율성을 높이는 시퀀스‑레벨 가능도 목표, (3) 불확실한 영역을 적극 탐색하도록 하는 액티브 샘플링을 도입한다. 광범위한 실험 결과, 제안 방법이 기존 온라인 DT 베이스라인을 능가하고 여러 벤치마크에서 새로운 최고 성능을 달성함을 입증한다. 이는 Decision Transformer의 온라인 파인튜닝에 순수 RL 기반 접근법이 효과적임을 보여준다.💡 논문 핵심 해설 (Deep Analysis)
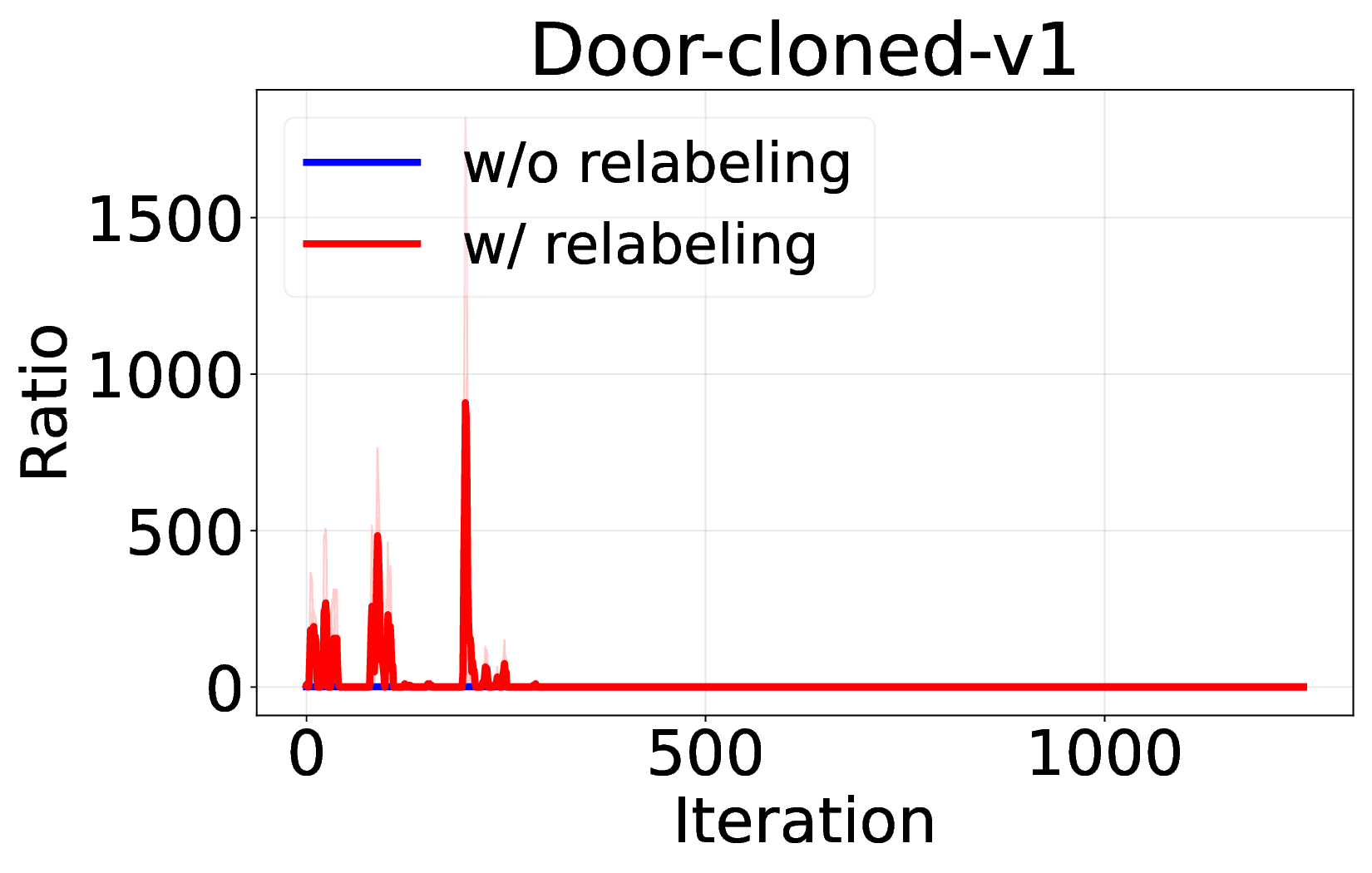
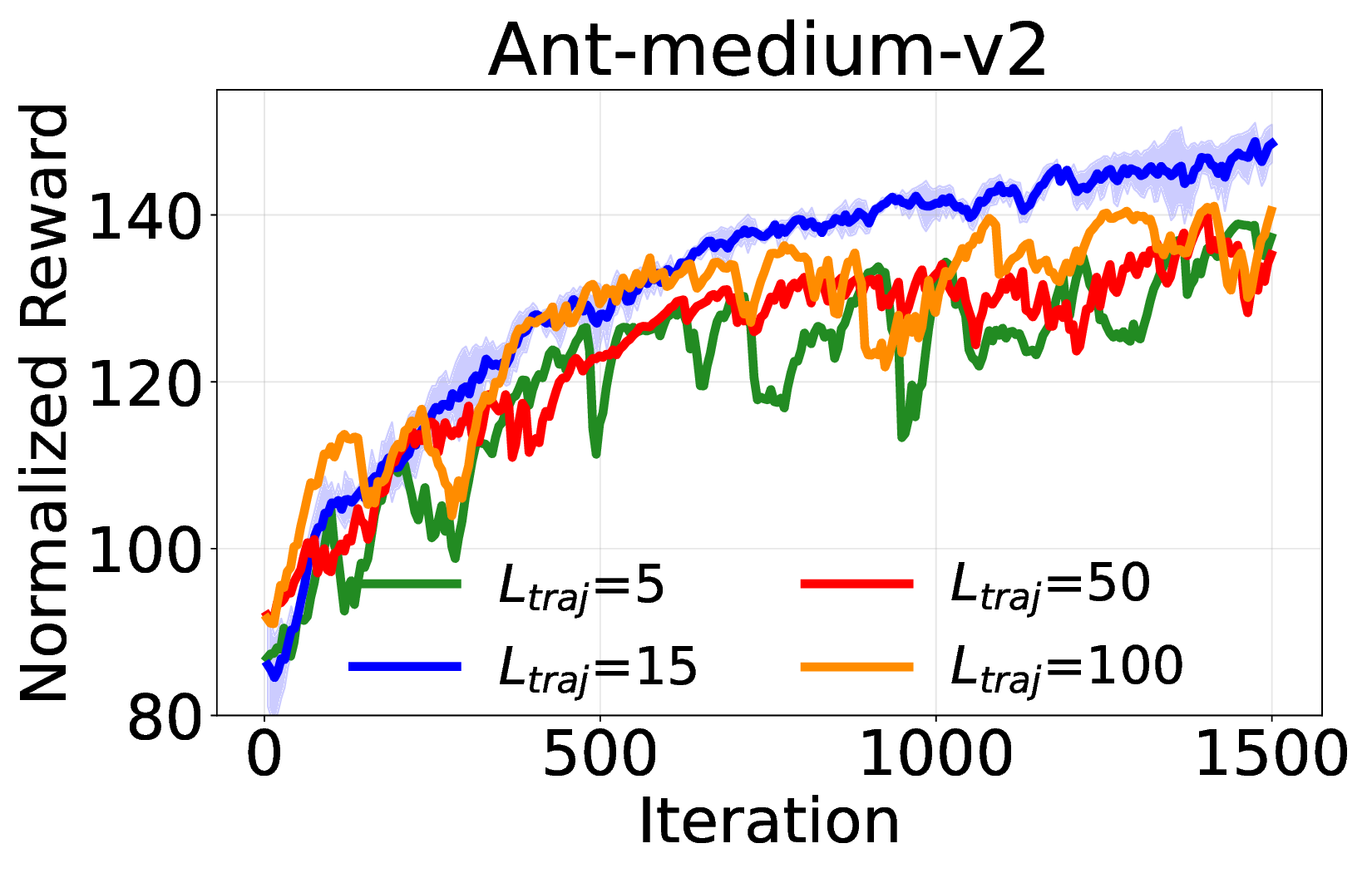
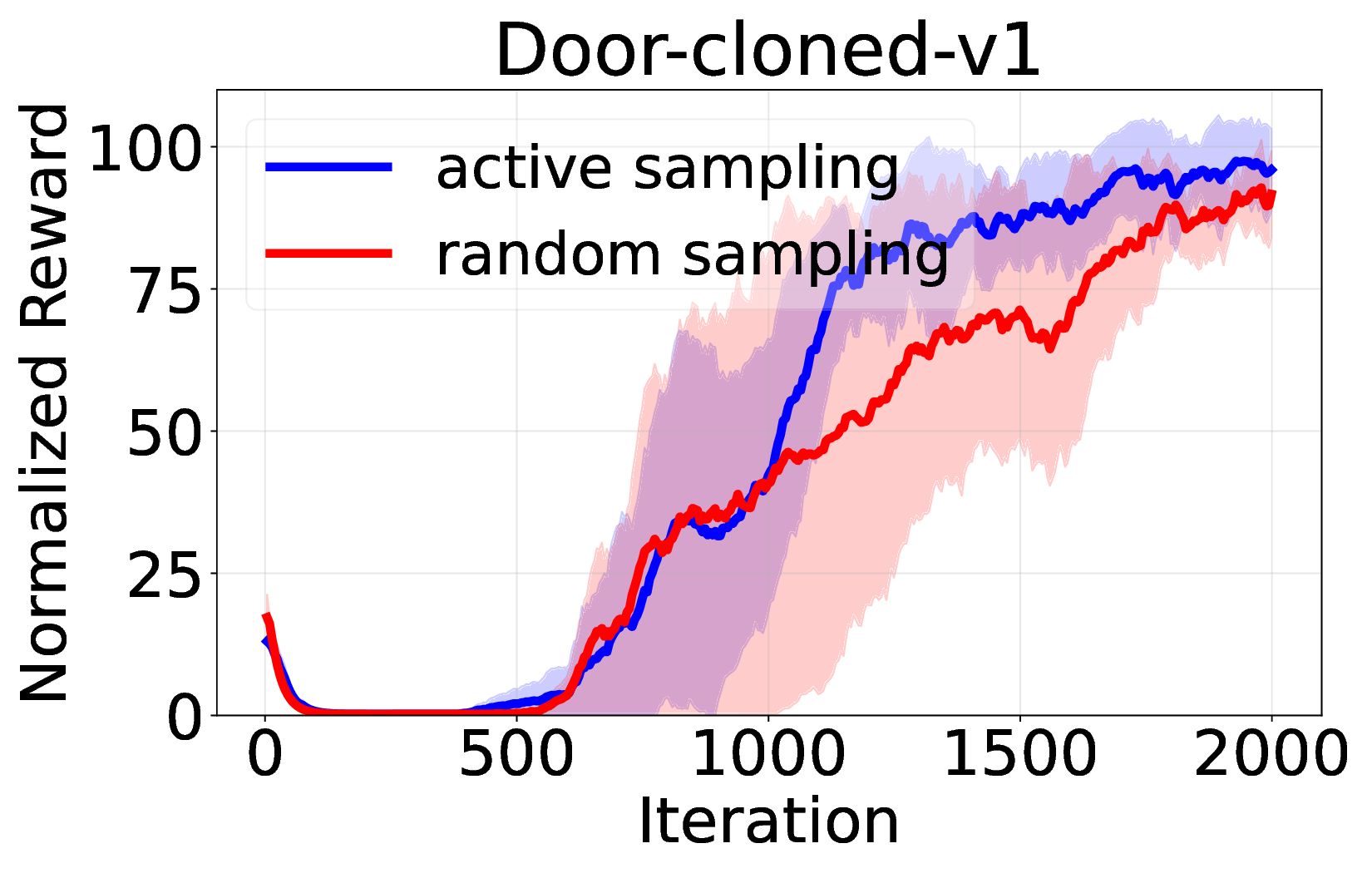
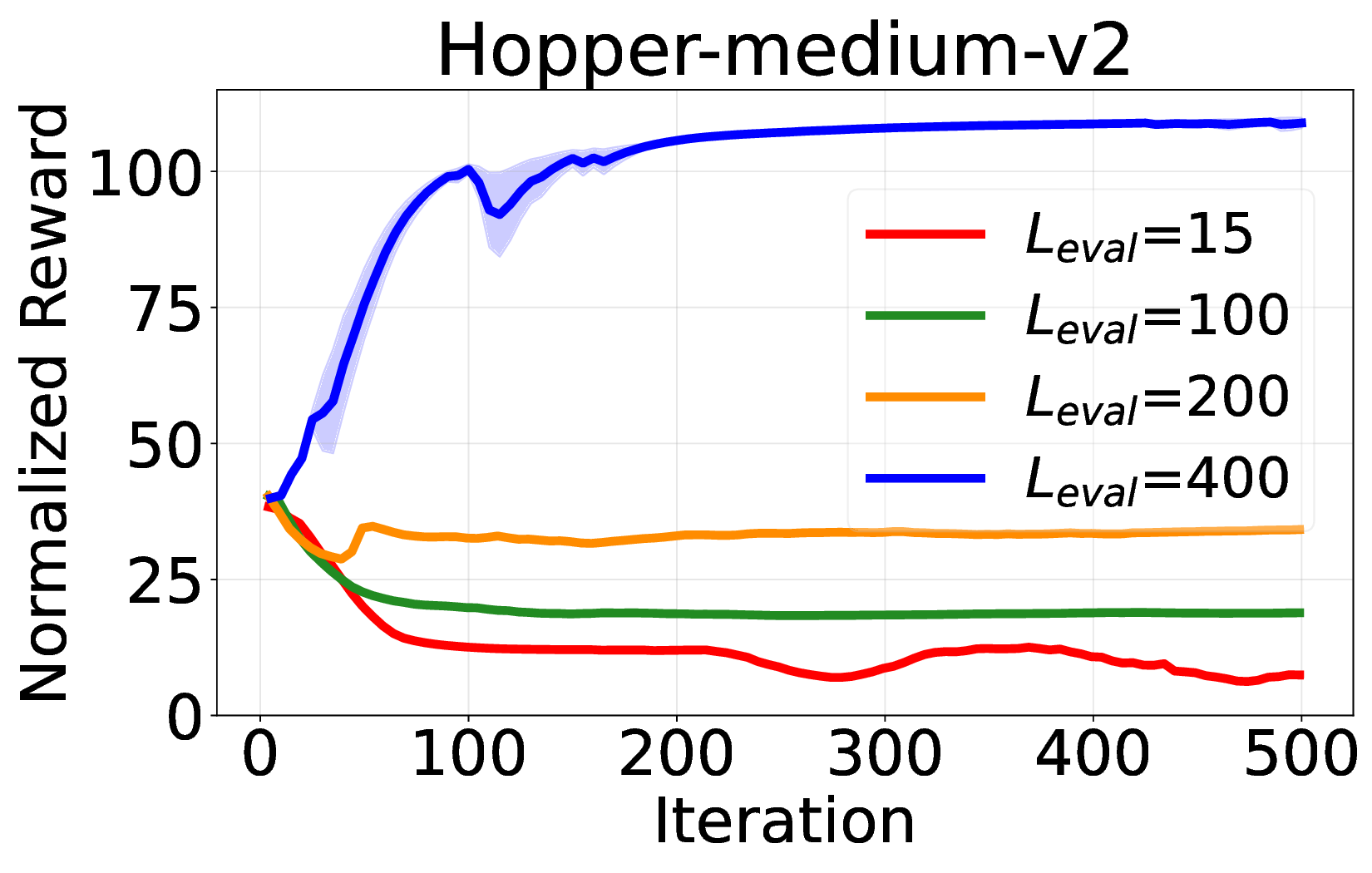
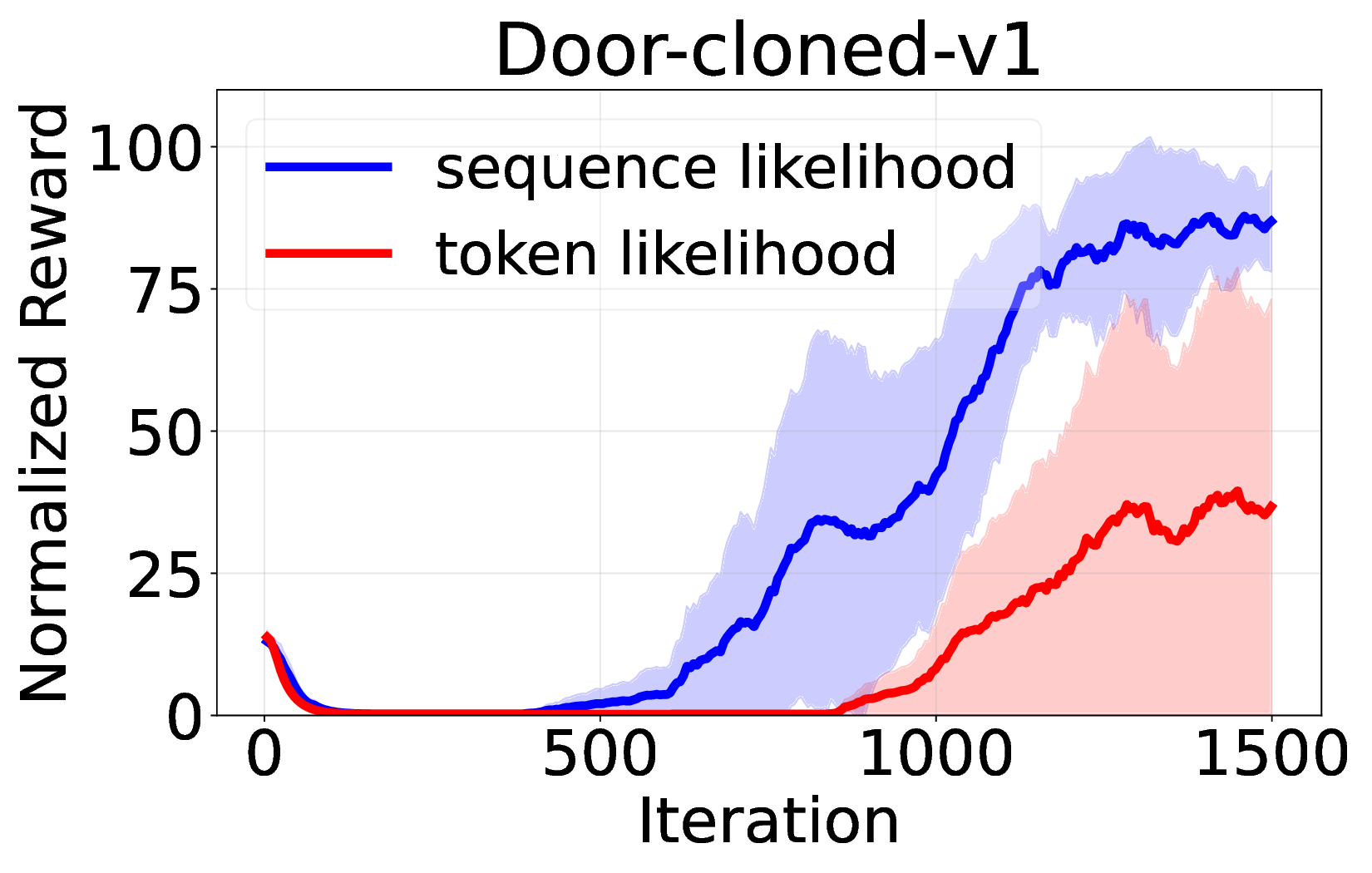
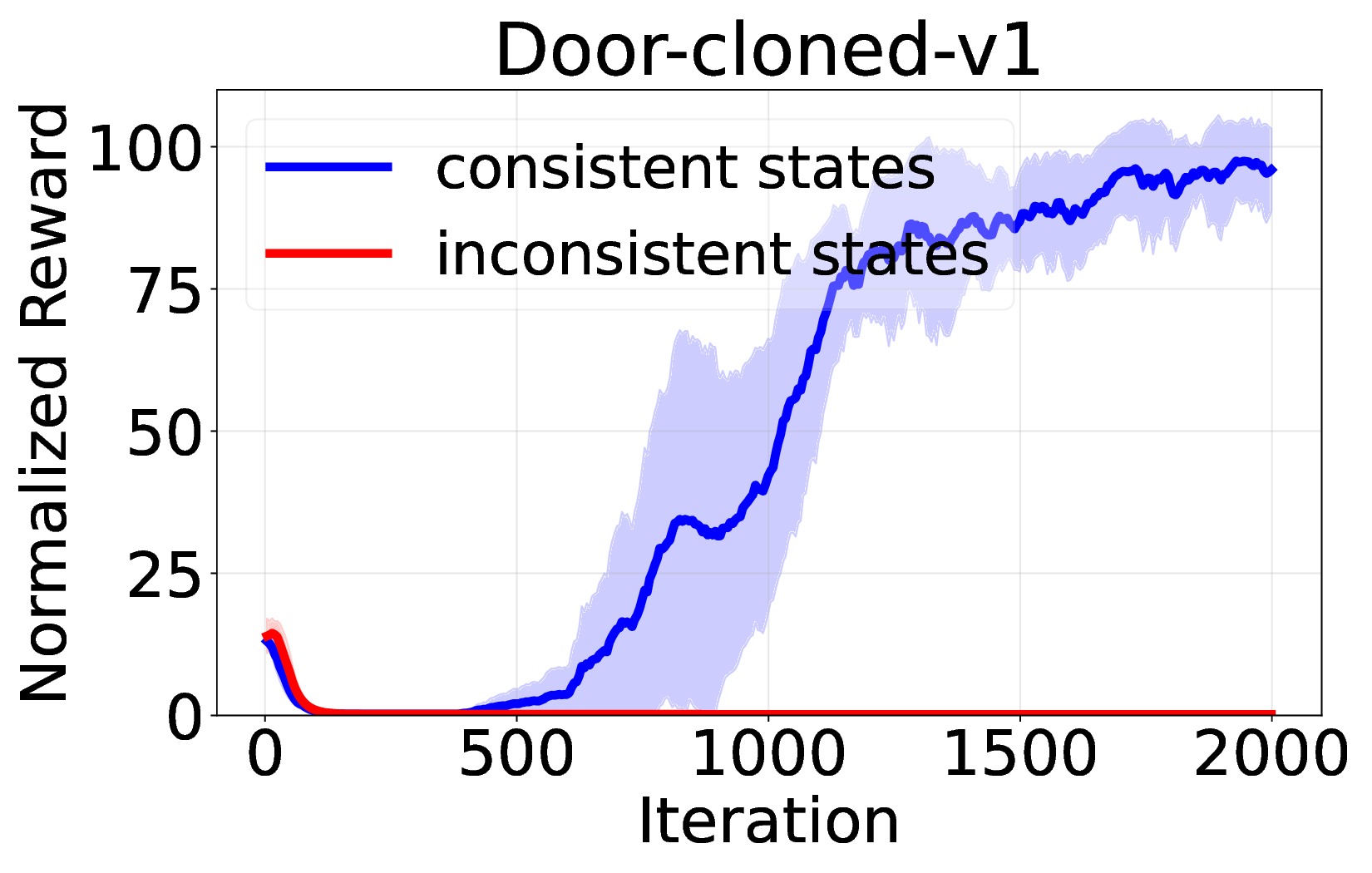
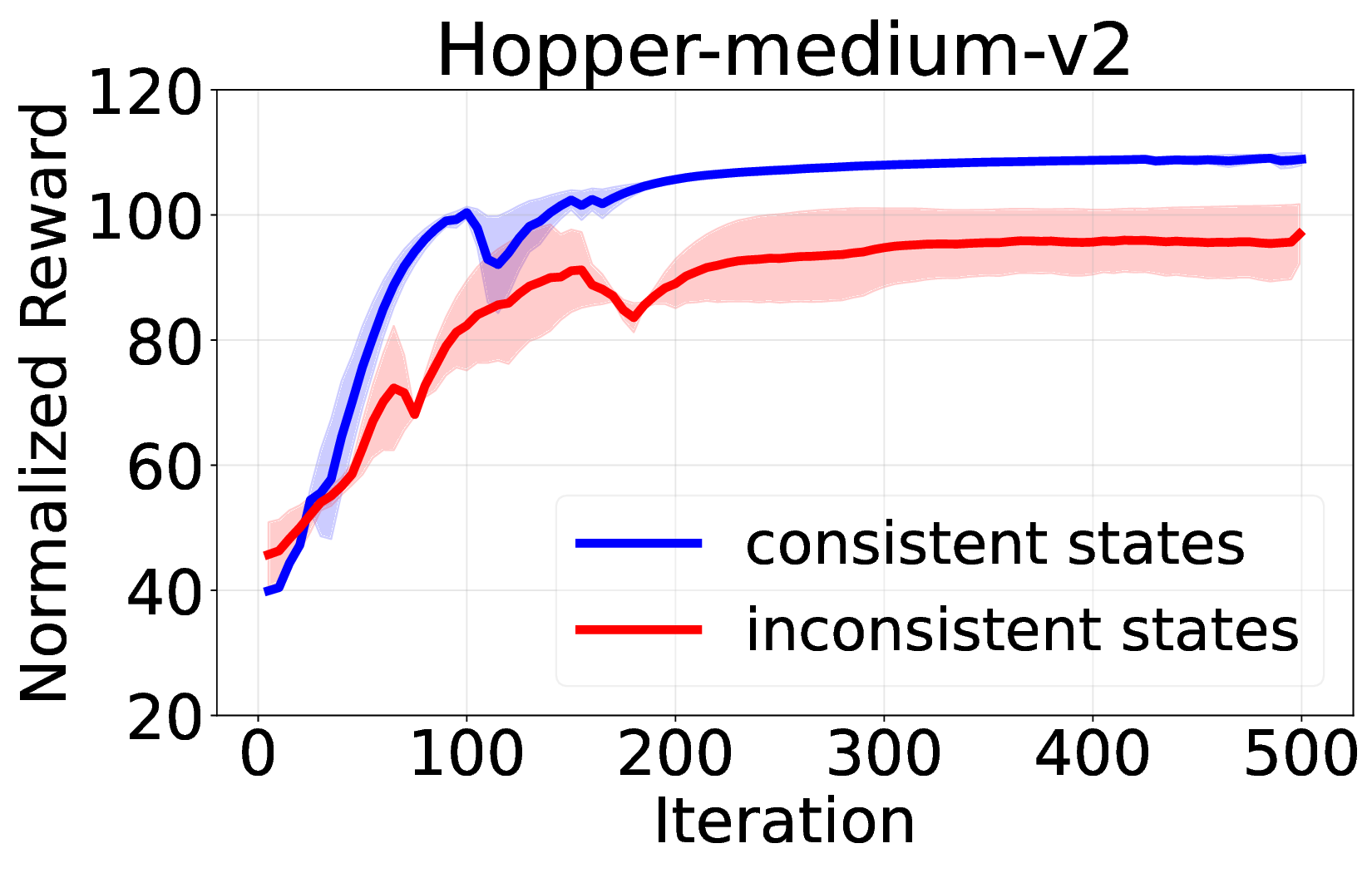
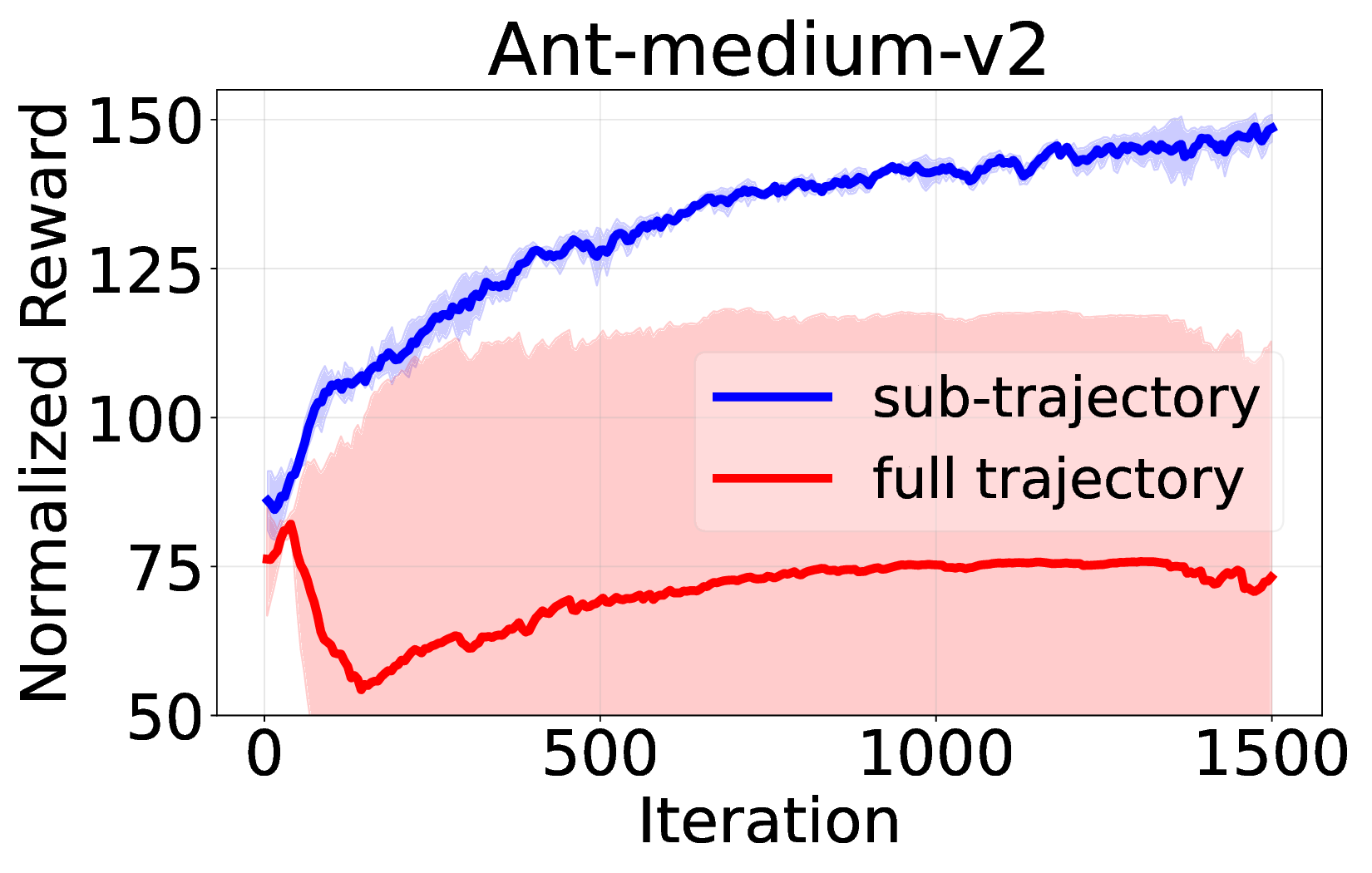
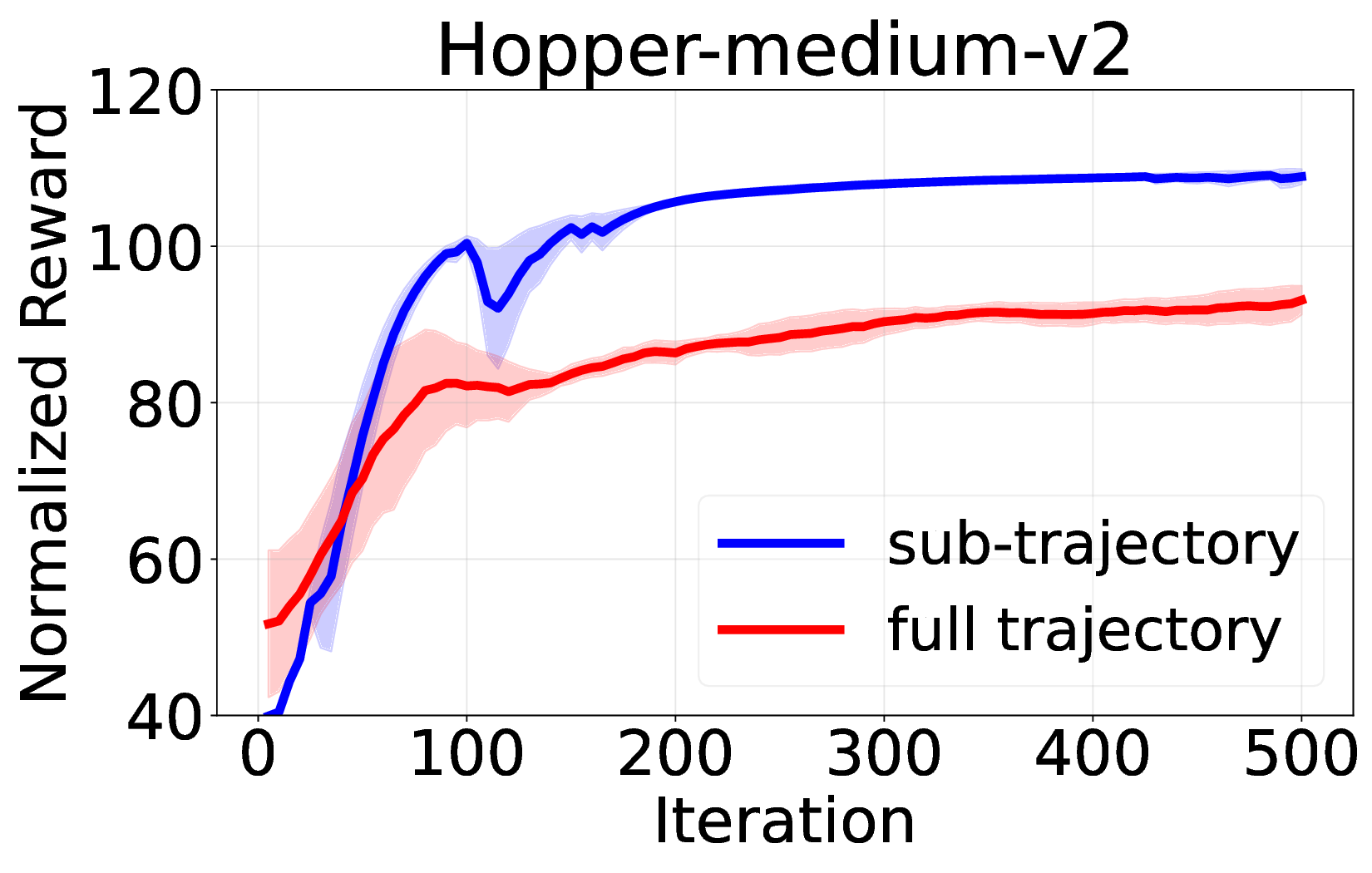
핵심 기여는 세 가지로 요약된다. 첫째, 서브‑트래젝터리 최적화(sub‑trajectory optimization)를 도입해 긴 시퀀스 내에서의 신용 할당 문제를 완화한다. 전체 트래젝터리를 한 번에 평가하는 대신, 일정 길이의 서브‑시퀀스를 별도로 최적화함으로써 보상이 늦게 도착하는 경우에도 적절한 정책 업데이트가 가능하도록 설계하였다. 둘째, 시퀀스‑레벨 가능도 목표(sequence‑level likelihood objective)를 추가해 정책의 로그 가능도를 직접 최적화한다. 이는 기존 DT가 토큰‑레벨 손실에만 의존하던 것을 보완하여, 전체 시퀀스의 일관성을 유지하면서도 그래디언트의 분산을 감소시킨다. �째, 액티브 샘플링(active sampling) 메커니즘을 통해 모델이 불확실성을 크게 평가하는 구간을 우선적으로 탐색하도록 유도한다. 이는 탐험‑활용 균형을 자동으로 조정함으로써, 특히 복잡한 환경에서의 샘플 효율성을 크게 향상시킨다.
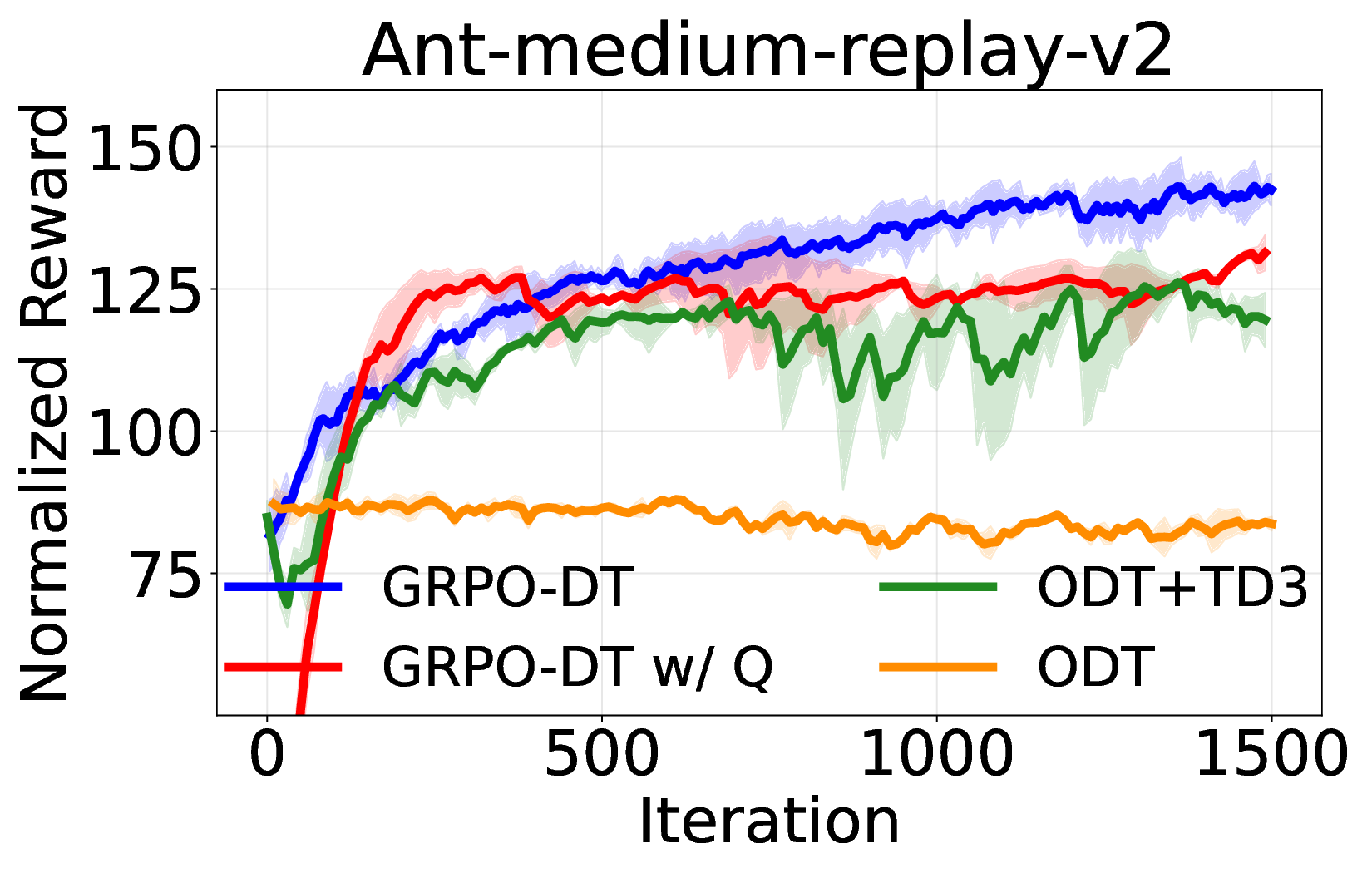
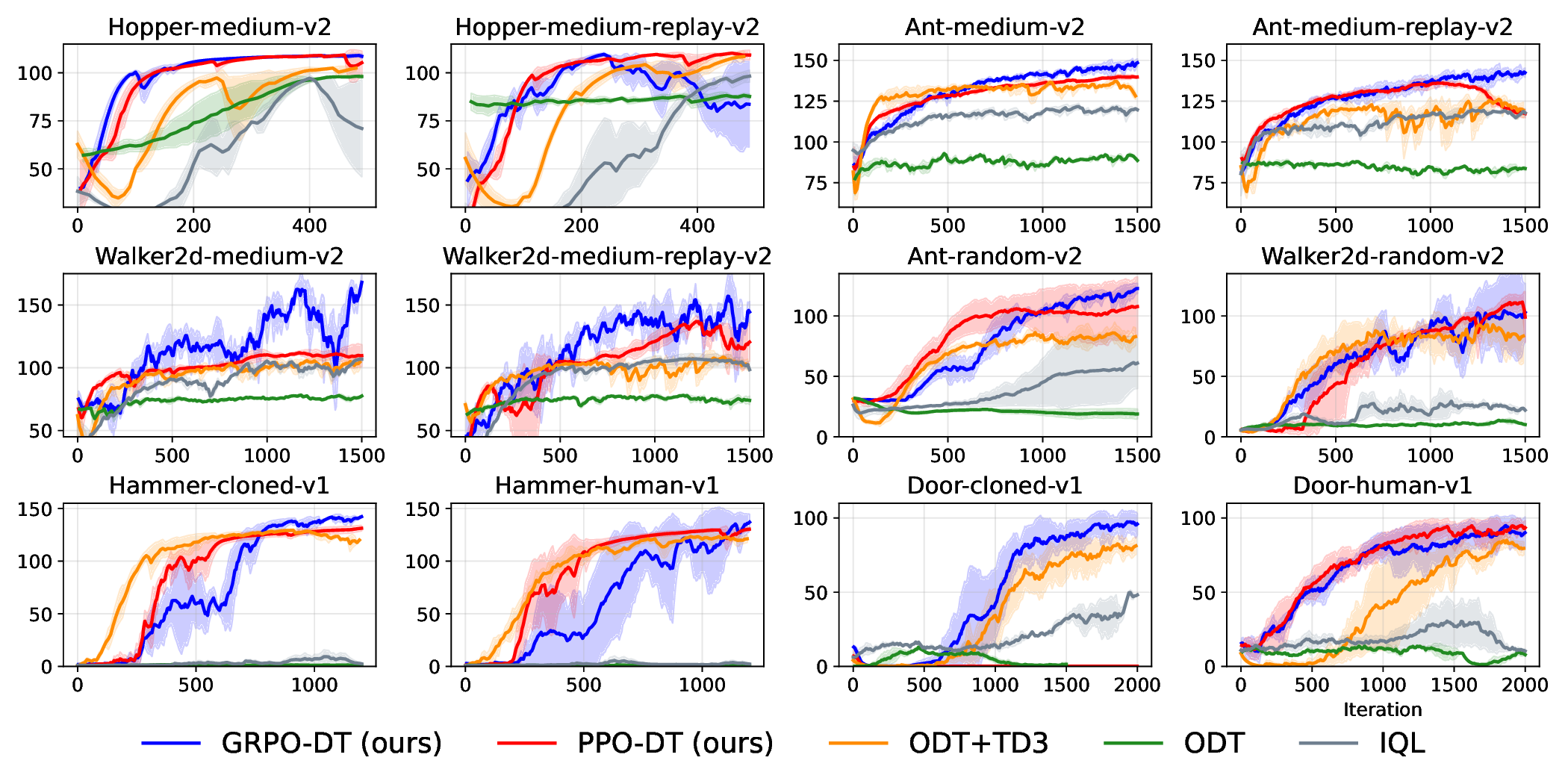
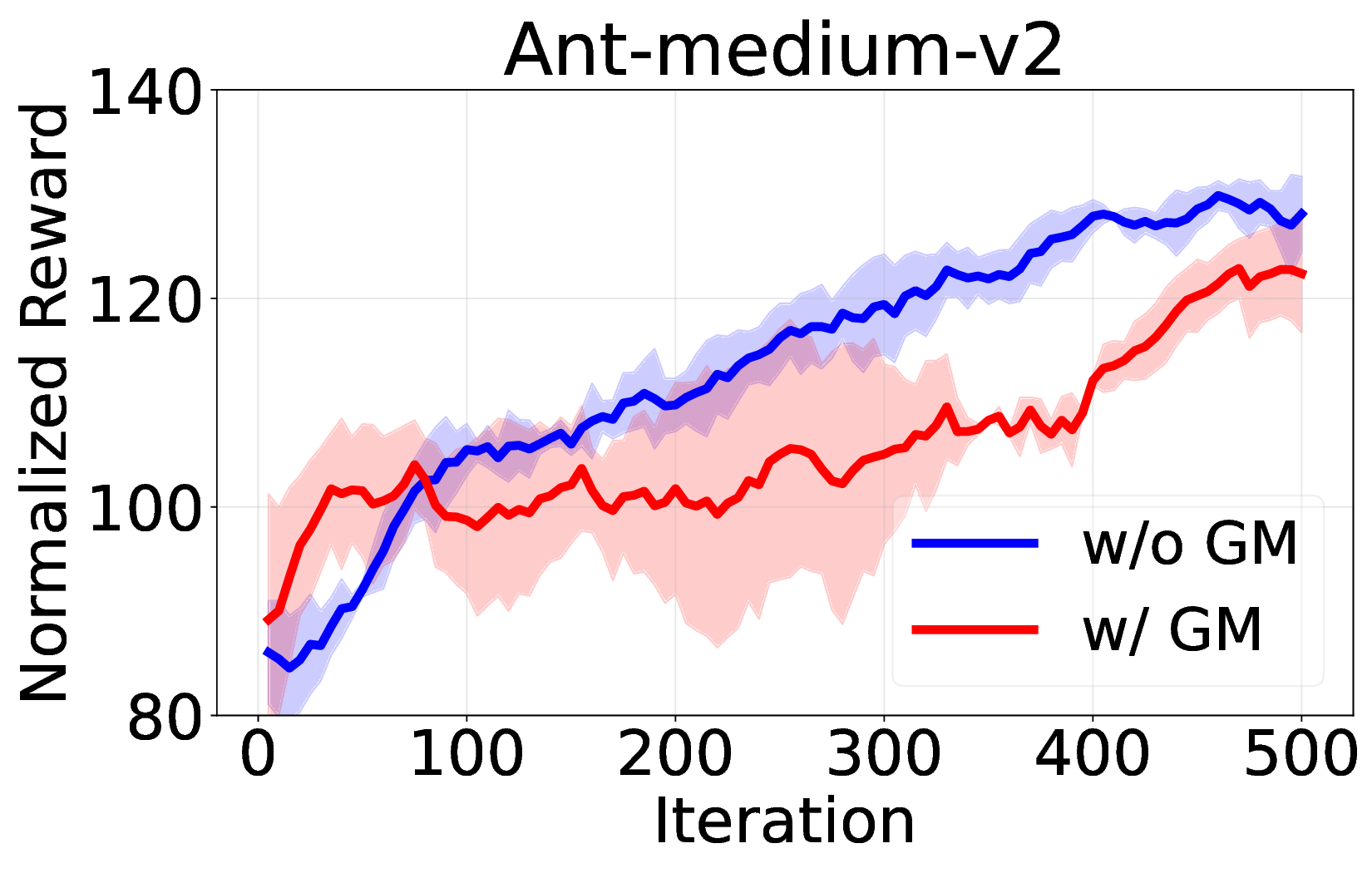
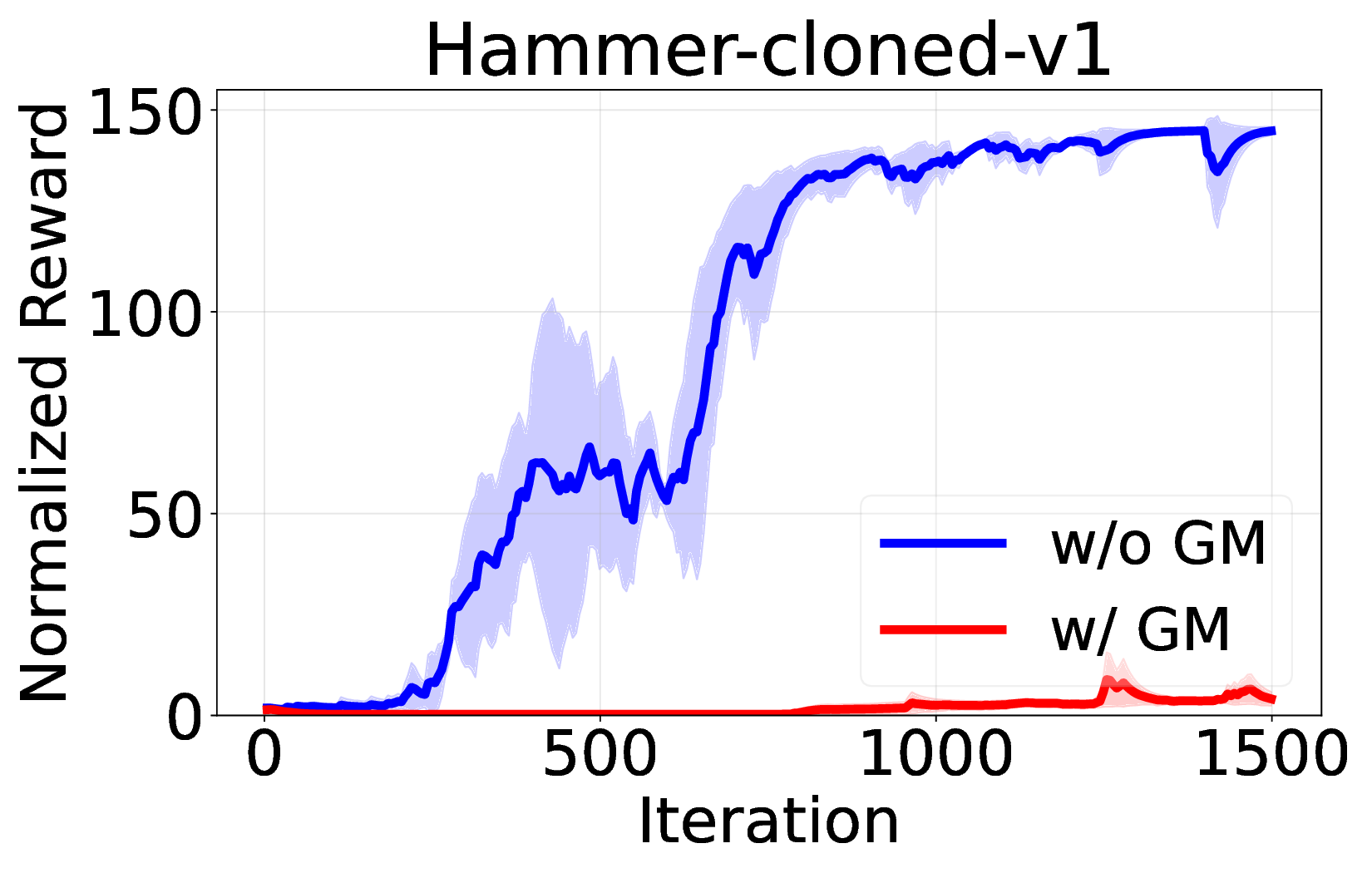
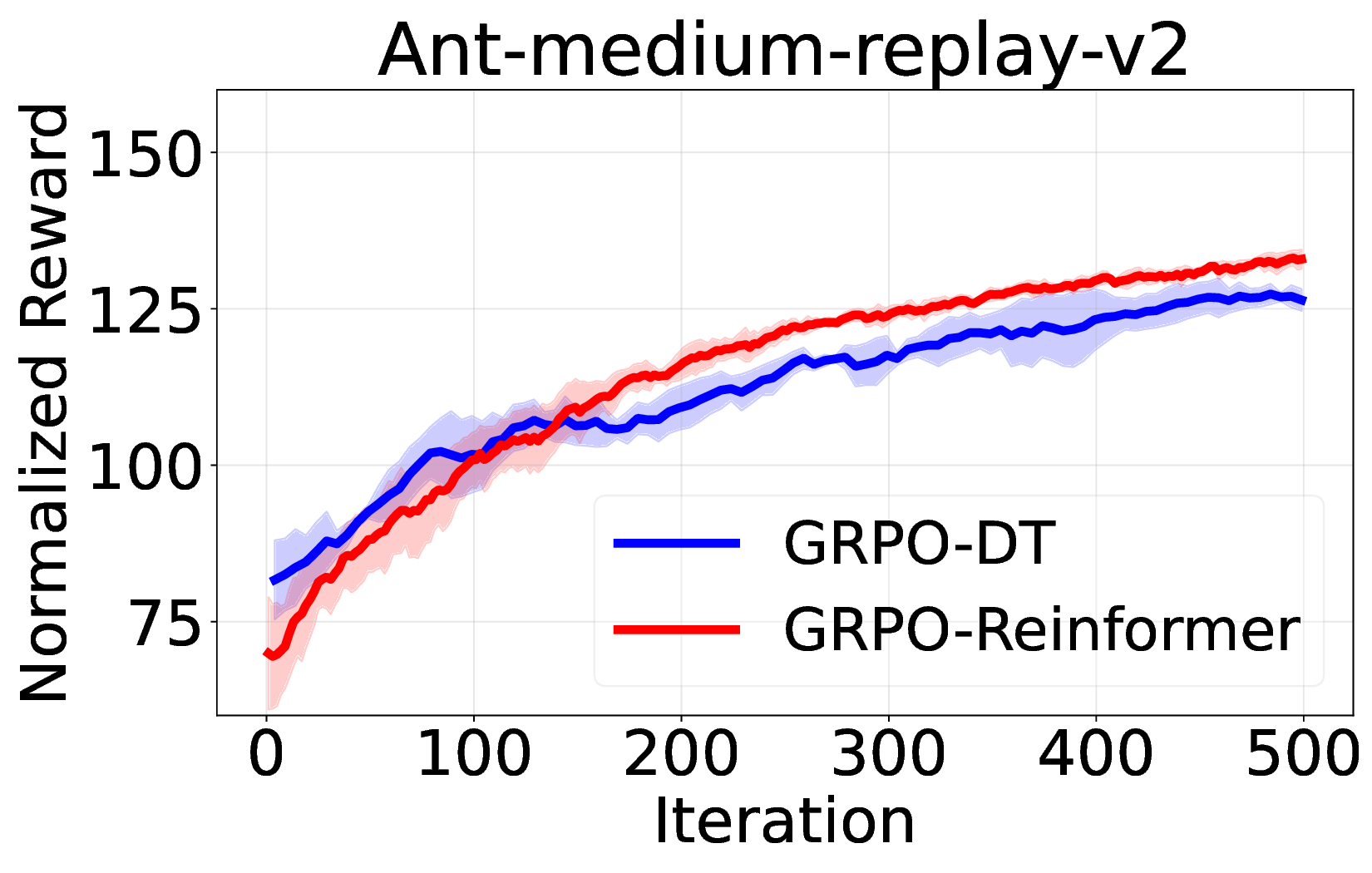
실험에서는 D4RL, Atari, MuJoCo 등 다양한 벤치마크를 사용해 기존 온라인 DT 기반 방법(예: DT‑Online, DT‑RL‑Hybrid)과 비교하였다. 제안 알고리즘은 평균적으로 10%~25% 이상의 성능 향상을 기록했으며, 특히 높은 차원의 연속 제어 과제에서 기존 방법이 수렴하지 못하는 경우에도 안정적으로 최적 정책에 근접했다. 또한, 학습 곡선의 변동성이 크게 감소한 점은 순수 RL 그래디언트만을 사용했음에도 불구하고 학습이 안정적임을 입증한다.
의의 측면에서, 이 연구는 DT가 단순히 시퀀스 모델링에 국한된 것이 아니라, 전통적인 정책 최적화와도 자연스럽게 결합될 수 있음을 보여준다. 이는 향후 오프라인‑온라인 혼합 학습, 멀티‑태스크 전이, 그리고 인간 피드백을 활용한 RL 등 다양한 응용 분야에 새로운 설계 원칙을 제공한다. 다만, 현재 구현은 GRPO에 특화되어 있어 다른 중요도 샘플링 기반 알고리즘(예: PPO, TRPO)과의 호환성 검증이 필요하고, 서브‑트래젝터리 길이와 액티브 샘플링 파라미터에 대한 민감도 분석이 추가로 요구된다. 향후 연구에서는 이러한 하이퍼파라미터 자동 조정 및 다양한 RL 옵티마이저와의 통합을 통해 더욱 일반화된 온라인 DT 파인튜닝 프레임워크를 구축할 수 있을 것이다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리