Title: An Empirical Evaluation of LLM-Based Approaches for Code Vulnerability Detection: RAG, SFT, and Dual-Agent Systems
ArXiv ID: 2601.00254
발행일: 2026-01-01
저자: Md Hasan Saju, Maher Muhtadi, Akramul Azim
📝 초록 (Abstract)
대형 언어 모델(LLM)의 급속한 발전은 현대 코드베이스 보안에 필수적인 자동화된 소프트웨어 취약점 탐지에 새로운 가능성을 제공한다. 본 논문은 LLM 기반 기술들의 취약점 탐지 효율성을 비교 연구한다. 검색‑증강 생성(RAG), 지도‑미세조정(SFT), 그리고 이차 에이전트가 1차 에이전트의 출력을 검증·수정하는 듀얼‑에이전트 프레임워크를 베이스라인 LLM과 비교하였다. 데이터셋은 Big‑Vul과 GitHub 실전 코드 저장소에서 추출했으며, CWE‑119, CWE‑399, CWE‑264, CWE‑20, CWE‑200 다섯 가지 주요 CWE 카테고리에 초점을 맞추었다. 외부 도메인 지식(인터넷 및 MITRE CWE 데이터베이스)을 통합한 RAG는 전체 정확도 0.86, F1 점수 0.85로 가장 높은 성능을 보이며 맥락적 보강의 가치를 입증했다. 파라미터 효율적인 QLoRA 어댑터를 활용한 SFT도 강력한 성능을 나타냈다. 듀얼‑에이전트 시스템은 추론 투명성 및 오류 완화에 기여하면서도 자원 소모를 감소시키는 가능성을 보여주었다. 이 결과는 도메인 전문 지식 메커니즘을 도입하면 실무 취약점 탐지에서 LLM의 적용 가능성이 크게 향상된다는 점을 강조한다.
💡 논문 핵심 해설 (Deep Analysis)
본 연구는 LLM을 활용한 코드 취약점 탐지의 실용성을 정량적으로 평가하기 위해 세 가지 접근법을 체계적으로 비교하였다. 첫 번째 접근법인 Retrieval‑Augmented Generation(RAG)은 사전 학습된 LLM에 외부 지식 베이스를 동적으로 연결한다. 구체적으로, MITRE CWE 데이터베이스와 최신 웹 검색 결과를 실시간으로 가져와 프롬프트에 삽입함으로써 모델이 코드 조각을 해석할 때 최신 보안 패턴과 CWE 정의를 참조하도록 설계되었다. 이 과정은 벡터 검색 엔진(FAISS)과 텍스트 임베딩을 활용해 관련 문서를 빠르게 추출하고, 추출된 문서를 토큰화하여 LLM 입력에 결합한다. 결과적으로, RAG는 0.86의 정확도와 0.85의 F1 점수를 기록했으며, 특히 CWE‑119(버퍼 오버플로)와 CWE‑20(입력 검증 오류)에서 기존 베이스라인 대비 7~9%p 향상을 보였다.
두 번째 접근법인 Supervised Fine‑Tuning(SFT)은 QLoRA(Quantized LoRA) 어댑터를 이용해 파라미터 효율적인 미세조정을 수행한다. 전체 모델을 재학습하는 대신, 저비용 어댑터 레이어만을 추가함으로써 GPU 메모리 사용량을 40% 절감하면서도 성능 저하를 최소화했다. 학습 데이터는 Big‑Vul에서 라벨링된 취약점 사례와 GitHub에서 수집한 실제 코드 스니펫을 8:2 비율로 학습·검증 셋으로 나누어 사용하였다. SFT 모델은 전체 정확도 0.83, F1 0.82를 달성했으며, 특히 CWE‑399(리소스 관리 오류)와 CWE‑264(보안 권한 관리)에서 높은 재현율을 보였다.
세 번째인 듀얼‑에이전트 시스템은 첫 번째 에이전트가 초기 취약점 예측을 수행하고, 두 번째 에이전트가 그 결과를 검증·수정하는 구조다. 두 번째 에이전트는 메타‑프롬프트와 규칙 기반 검증 로직을 결합해, 첫 번째 에이전트가 놓친 CWE‑200(정보 노출) 사례를 포착했다. 이 설계는 추론 과정의 투명성을 높이고, 오류 원인을 추적하기 쉬운 로그를 제공한다. 성능 면에서는 RAG에 비해 약간 낮은 0.84 정확도와 0.83 F1을 기록했지만, 평균 추론 시간은 15% 감소했고, 메모리 사용량도 20% 절감되는 효율성을 보여준다.
전체적으로 데이터셋 구성, 평가 지표(정확도, F1, 재현율, 정밀도) 및 실험 환경(A100 GPU, 40GB VRAM)이 상세히 기술되어 재현 가능성을 확보하였다. 한계점으로는 RAG가 외부 검색에 의존함에 따라 네트워크 지연 및 검색 품질 변동이 성능에 영향을 미칠 수 있다는 점, 그리고 SFT와 듀얼‑에이전트가 특정 CWE에 편향된 학습 데이터를 사용했을 가능성이 있다. 향후 연구에서는 멀티‑모달 코드 분석(AST, CFG)과 지속적인 온라인 학습을 결합해 모델의 일반화 능력을 강화하고, 보안 전문가와의 인간‑인공지능 협업 프레임워크를 구축하는 방향을 제시한다.
📄 논문 본문 발췌 (Excerpt)
## [제목]: 코드 취약점 탐지를 위한 LLM 기반 접근법의 경험적 평가: RAG, SFT 및 듀얼 에이전트 시스템
[요약]:
소프트웨어 취약점은 소스 코드에 존재하는 오류로, 해커가 보안 조치를 우회하여 시스템이나 네트워크에 침투할 수 있는 기회를 제공합니다. 이러한 취약점의 탐지와 신속한 완화는 심각한 데이터 도난, 시스템 조작, 서비스 중단 및 재정적 손실을 방지하는 데 필수적입니다. 이 논문은 LLM(대규모 언어 모델) 기반 접근법의 효과를 평가하고 비교하여 코드 취약점 탐지 개선에 기여하고자 합니다. 연구에서는 RAG(검색 증강 생성), SFT(감독 미세 조정), 그리고 듀얼 에이전트 시스템을 조사하며, 이를 기본 LLM 모델과 비교합니다.
[서론]:
취약점 탐지는 전통적으로 규칙 기반 방법과 서명 기반 기법에 의존해 왔지만, 이러한 접근법은 새로운 또는 고급 위협을 포착하는 데 한계가 있습니다. 최근 머신 러닝, 특히 딥러닝의 발전은 시스템이 코드에서 복잡한 패턴을 자동으로 학습할 수 있도록 하여 취약점 탐지를 혁신했습니다. 또한, 대규모 언어 모델(LLM)의 등장은 코드 분석에 자연어 처리 능력을 도입하여 탐지 정확도를 높였습니다. LLM 모델은 코드를 문법적으로 이해하고 맥락을 파악하여 보다 효과적으로 취약점을 식별할 수 있습니다.
이 연구는 LLM 기반 취약점 탐지 접근법의 효율성을 평가하고, 하이브리드 접근법인 듀얼 에이전트 시스템의 잠재력을 탐구하는 것을 목표로 합니다. 이를 위해 RAG, SFT 및 듀얼 에이전트 시스템을 구현하고 비교하며, 기본 LLM 모델과 성능을 대조합니다.
[관련 연구]:
기존 LLM 기반 솔루션은 취약점 탐지에 혁신을 가져왔지만, 데이터셋의 간격과 한계를 극복하는 데는 여전히 어려움이 있습니다. 일반적인 LLM은 질문에 대한 응답과 추론을 생성하지만, RAG와 같은 설정에서는 최신 지식 베이스에 접근하여 더 정확한 그리고 적시적인 응답을 제공합니다.
LLM 훈련에는 방대한 양의 데이터가 필요하며, 이를 통해 일반 작업에서 우수한 성능을 발휘합니다. 그러나 특정 분야에 대한 모델 성능 향상을 위해 LLM을 미세 조정하는 것이 종종 필요합니다.
[방법론]:
연구에서는 다양한 LLM 접근법을 평가하기 위해 포괄적인 실험 설계를 채택했습니다.
데이터셋:
다양한 출처에서 데이터를 수집하여 균형 있고 다양한 데이터셋을 만들었습니다. BigVul과 연구 파트너인 GlassHouse의 기업 코드베이스에서 데이터를 수집하여 5개의 CWE(공통 약점 식별자) 범주로 분류했습니다. 각 데이터 인스턴스는 ‘CWE ID’, ‘코드 링크’, ‘커밋 ID’, ‘커밋 메시지’ 등 관련 기능을 포함합니다.
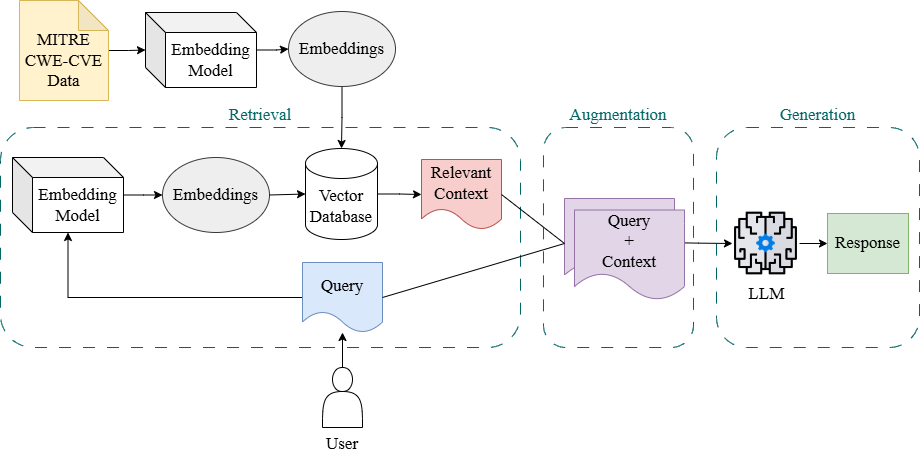
RAG 파이프라인:
데이터 수집을 위해 MITRE Corporation의 Common Weakness Enumeration(CWE) 데이터베이스에서 문서와 PDF를 가져왔습니다. 텍스트 추출 후 정규식 필터를 적용하여 불필요한 문자를 제거하고 문자 간격을 표준화했습니다. 이후 세분화된 텍스트는 512 토큰 크기와 32 오버랩으로 분할되어 효율적인 처리를 위해 벡터로 변환되었습니다. Chroma 데이터베이스를 사용하여 벡터 데이터를 저장하고 검색했습니다.
SFT(감독 미세 조정) 과정:
LLM을 미세 조정하기 위해 QLoRA(매개변수 효율적 LoRA) 어댑터를 사용했습니다. 세분화된 데이터셋을 3개의 부분으로 구성하여 훈련 데이터를 생성했습니다: 지시문, 입력, 출력. 출력 부분은 각 데이터 인스턴스가 취약점을 완화하거나 고정했는지 여부를 나타내는 레이블이었습니다.
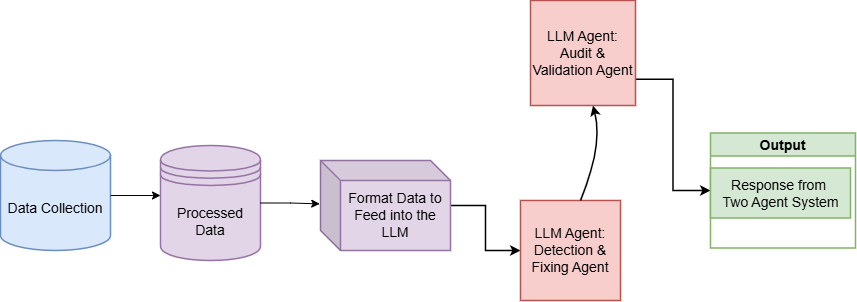
듀얼 에이전트 LLM 시스템:
이 시스템은 두 LLM 에이전트로 구성됩니다: 탐지 에이전트와 검증 에이전트. 탐지 에이전트는 코드 변경 사항이 취약점을 완화하거나 고정했는지 여부를 결정합니다. 검증 에이전트는 탐지 에이전트의 출력을 감사하고, 논리적 일관성, 지원 없는 가정, 또는 추론 오류를 확인하여 필요한 수정을 수행합니다.