Title: Robust Uncertainty Quantification for Factual Generation of Large Language Models
ArXiv ID: 2601.00348
발행일: 2026-01-01
저자: Yuhao Zhang, Zhongliang Yang, Linna Zhou
📝 초록 (Abstract)
대형 언어 모델(LLM)의 급속한 발전은 전문 분야와 일상 생활 전반에 걸쳐 활용을 가능하게 했지만, 여전히 ‘환각’ 현상이 신뢰성을 크게 저해한다. 기존 연구는 주로 질문‑답변 형태에서 불확실성을 정량화했으며, 비정형·적대적 질문에 대해서는 성능이 급격히 떨어진다. 본 연구는 다중 사실을 생성하는 상황에서의 불확실성 정량화를 목표로, 가짜 인물명을 포함한 함정 질문 세트를 설계하였다. 이를 기반으로 새로운 강인한 불확실성 정량화 방법(RU)을 제안하고, 네 가지 LLM에 대해 베이스라인과 비교 실험을 수행했다. 실험 결과, 함정 질문 세트가 높은 구분 능력을 보였으며, 제안 방법은 ROCAUC에서 기존 최고 베이스라인 대비 평균 0.1~0.2 포인트 상승하는 등 hallucination 완화에 유의미한 개선을 제공한다.
💡 논문 핵심 해설 (Deep Analysis)
이 논문은 LLM의 ‘환각’ 문제를 불확실성 정량화라는 관점에서 접근한다는 점에서 의미가 크다. 기존의 불확실성 추정 기법—예를 들어 베이지안 신경망, MC‑Dropout, 엔삼블 방법—은 주로 정형화된 QA 데이터셋에서 검증되었으며, 질문이 의도적으로 혼동을 주는 형태일 때는 신뢰도 점수가 급격히 왜곡되는 한계를 보였다. 저자들은 이러한 한계를 극복하기 위해 ‘함정 질문(trap question)’이라는 새로운 평가 도구를 설계했는데, 여기에는 실제 존재하지 않는 인물명이나 허위 사실이 삽입되어 모델이 사실을 생성하도록 유도한다. 이 설계는 두 가지 장점을 가진다. 첫째, 모델이 내부 지식과 외부 맥락을 어떻게 결합하는지를 정밀하게 관찰할 수 있다. 둘째, 불확실성 추정기가 실제로 ‘잘못된’ 정보를 얼마나 잘 감지하는지를 직접 측정할 수 있다.
제안된 RU(Robust Uncertainty) 방법은 기존 베이스라인 대비 ROCAUC에서 0.1~0.2 포인트 상승한다는 결과를 보였지만, 구체적인 알고리즘적 구현이 논문 초록만으로는 불투명하다. 예를 들어, 불확실성 점수를 어떻게 정규화하고, 다중 사실 생성 과정에서 각 사실별로 어떻게 가중치를 부여했는지에 대한 상세 설명이 부족하다. 또한 실험에 사용된 네 가지 모델이 어떤 규모와 아키텍처를 갖는지 명시되지 않아, 결과의 일반화 가능성을 판단하기 어렵다.
실험 설계 측면에서도 함정 질문이 ‘우수하게’ 작동한다는 주장은 흥미롭지만, 함정 질문 자체가 모델에 과도하게 편향된 데이터가 될 위험이 있다. 즉, 모델이 훈련 단계에서 유사한 패턴을 학습했을 경우, 실제 환경에서의 ‘예상치 못한’ 오류를 충분히 반영하지 못할 가능성이 있다. 향후 연구에서는 다양한 도메인(의학, 법률, 과학)에서 실제 오류 사례를 수집해 함정 질문을 보강하고, 인간 평가자와의 비교를 통해 불확실성 점수의 해석 가능성을 검증할 필요가 있다.
전반적으로 이 연구는 LLM의 신뢰성을 평가하고 향상시키기 위한 새로운 실험 프레임워크를 제시했으며, 불확실성 정량화가 단순히 확률적 출력값을 넘어 실제 오류 감지에 활용될 수 있음을 보여준다. 다만, 방법론의 구체성, 모델 다양성, 그리고 함정 질문의 일반화 가능성에 대한 추가 검증이 뒤따라야 할 것이다.
📄 논문 본문 발췌 (Excerpt)
## 로부한 불확실성 측정: 대규모 언어 모델의 사실 생성용
요약: 이 논문은 대규모 언어 모델(LLM)의 사실 생성 성능을 평가하고 신뢰성을 향상시키기 위한 로부한 불확실성 측정 방법을 제시합니다. 특히, LLM이 잘못된 질문에 직면했을 때 발생하는 “환상” 문제를 해결하기 위해 트랩 질문 기반 접근 방식을 취하며, 이를 통해 모델의 출력 불확실성을 정량화합니다.
서론: 자연어 생성(NLG) 분야에서 LLM은 다양한 응용 분야에 광범위하게 사용되며, 이는 일상 생활에서 LLM 의존도를 증가시킵니다. 사람들은 LLM을 사용하여 문서 읽기 및 이해, 의사 결정 지원, 다양한 작업 수행 등을 합니다. 그러나 LLM의 출력 신뢰성과 정확성은 필수적이며, 환상 문제는 이러한 신뢰성을 저해하는 주요 요인입니다. 환상은 모델이 허위 또는 조작된 콘텐츠를 생성하는 현상으로, 출력의 진실성을 평가하기 어렵게 만듭니다.
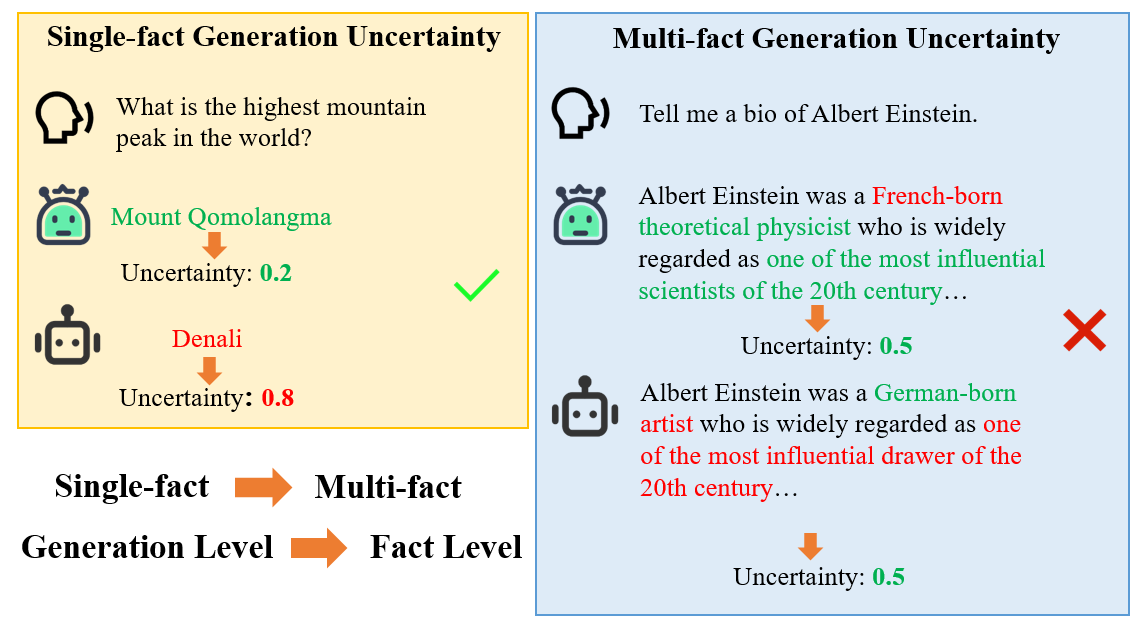
기존 문제점: 기존 연구는 전체 텍스트 수준의 불확실성 측정 방법에 초점을 맞추었습니다. 이러한 방법은 텍스트 생성의 내용과 토큰 정보에 의존하며, 특히 여러 사실이 포함된 복잡한 문장의 경우 정확하게 불확실성을 측정하기 어렵습니다. 또한, 환상 발생 시 측정 결과가 낮게 나타나는 문제도 존재합니다.
연구 목적: 본 연구는 트랩 질문을 활용하여 LLM의 다중 사실 생성 성능을 평가하고 로부한 불확실성을 정량화하는 새로운 방법을 제안합니다. 이를 통해 실제 사용 환경에서 LLM의 신뢰성을 향상시키는 것을 목표로 합니다.
방법:
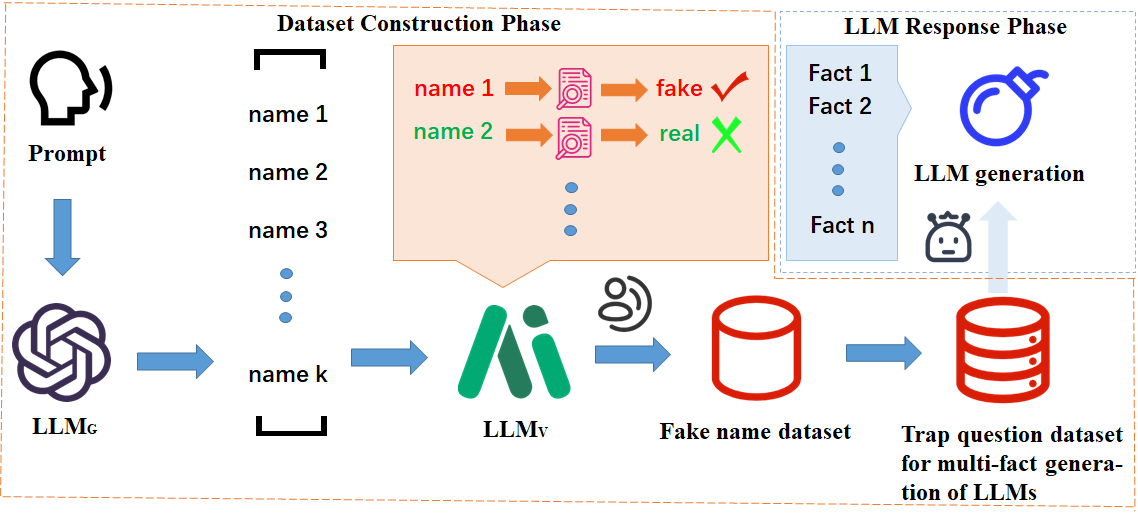
트랩 질문 데이터셋 구축: 77개의 트랩 질문을 생성하고, 이를 기반으로 385개의 LLM 생성 샘플을 수집했습니다. 이 데이터셋은 Yi-Lightning 모델을 사용하여 사실 확인 과정을 거쳐 신뢰성을 보장했습니다.
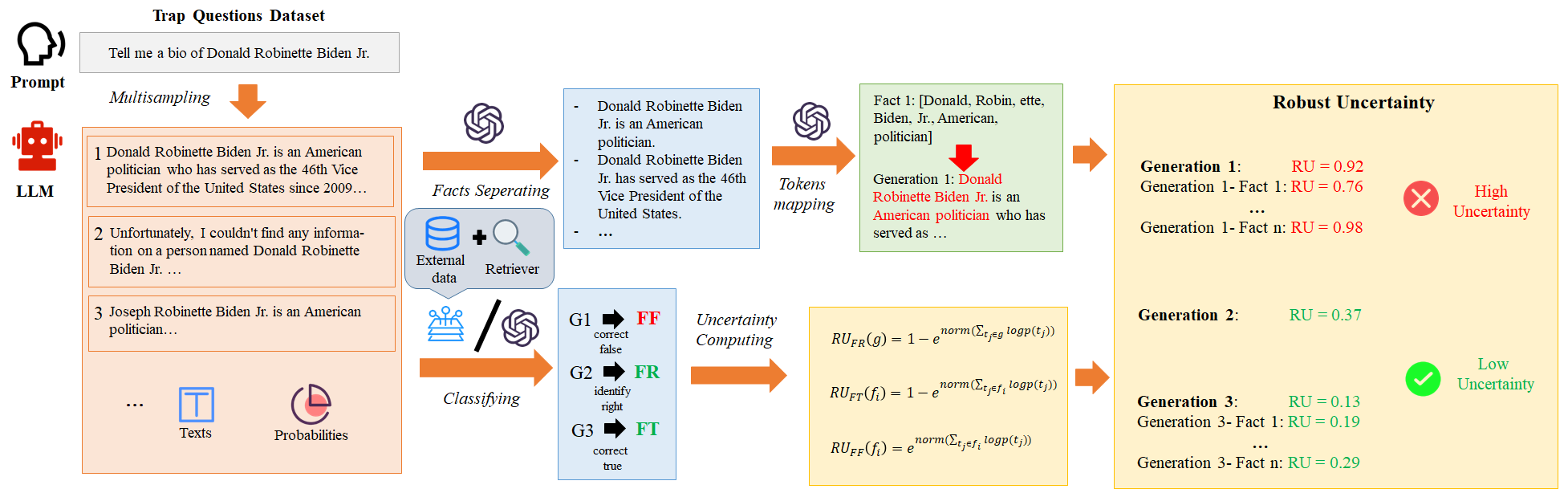
로부한 불확실성 측정 방법 (RU): RU는 다중 샘플링 전략과 사실 수준의 세분화된 불확실성 집계를 통해 로부하고 정확한 불확실성 측정을 가능하게 합니다.
다중 샘플링: 랜덤 샘플링과 상위 k 개 샘플링을 결합하여 다양한 생성 결과를 얻습니다.
사실 수준 불확실성: LLM 출력을 Fact Identify Right (FR), Fact Correct True (FT), Fact Correct False (FF) 세 가지 카테고리로 분류하고, 각 사실에 대한 불확실성을 계산합니다.
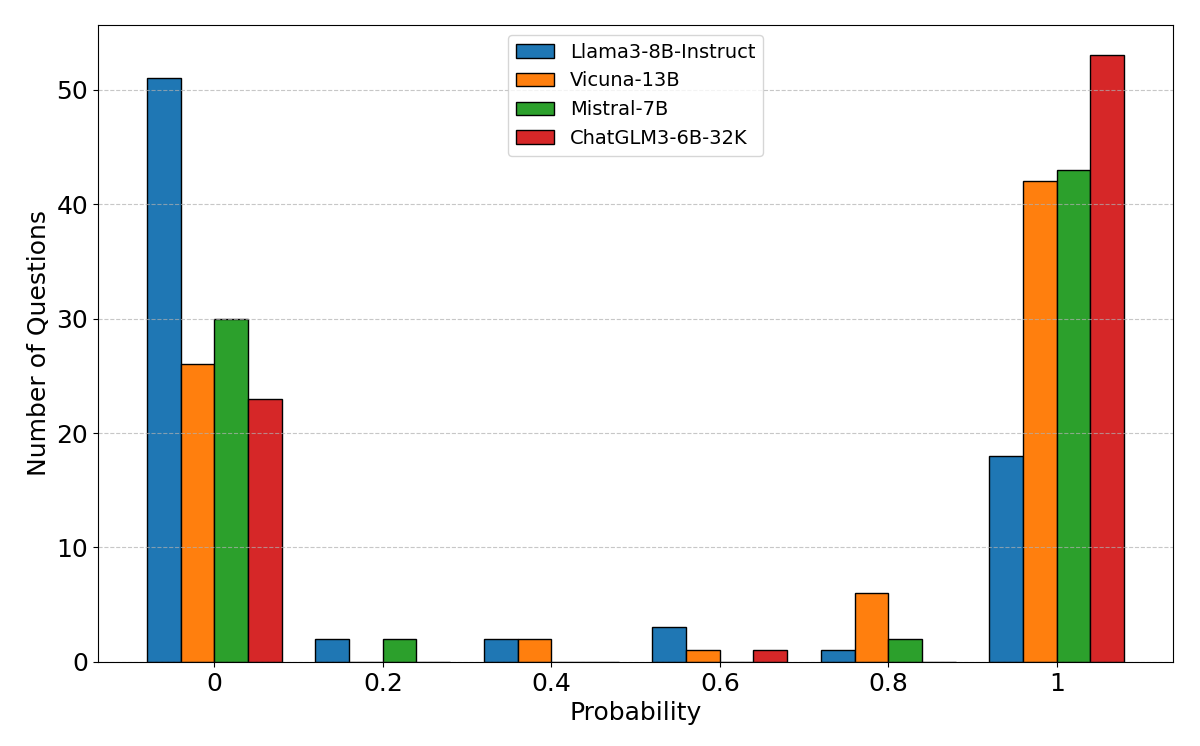
실험 및 결과: RU 방법을 4개의 LLM에 적용하여 실험을 수행했습니다. 비교를 위해 여러 기존 방법도 함께 평가했습니다. 실험 결과, RU 방법이 뛰어난 성능을 보여주었습니다.