시각질문응답 환각 탐지를 위한 모델 기반 단일패스 FaithSCAN
📝 원문 정보
- Title: FaithSCAN: Model-Driven Single-Pass Hallucination Detection for Faithful Visual Question Answering
- ArXiv ID: 2601.00269
- 발행일: 2026-01-01
- 저자: Chaodong Tong, Qi Zhang, Chen Li, Lei Jiang, Yanbing Liu
📝 초록 (Abstract)
시각‑언어 모델(VLM)이 시각적 근거가 없는 답변을 유창하게 생성하는 현상을 ‘환각’이라 부르며, 이는 안전‑중요 분야에서 신뢰성을 크게 저하시킨다. 기존 탐지 방법은 보조 모델이나 지식베이스를 활용하는 외부 검증 방식과, 반복 샘플링·불확실성 추정에 의존하는 불확실성 기반 방식으로 크게 두 갈래로 나뉜다. 전자는 높은 연산 비용과 외부 자원의 품질 제한에 시달리고, 후자는 모델 불확실성의 일부만 포착해 다양한 실패 모드에 대한 내부 신호를 충분히 활용하지 못한다. 이러한 한계를 극복하고자 우리는 VLM 내부의 풍부한 신호—토큰 수준 디코딩 불확실성, 중간 시각 표현, 그리고 교차‑모달 정렬 특징—를 활용하는 경량 네트워크 FaithSCAN을 제안한다. 각 신호는 분기별 증거 인코딩과 불확실성‑인식 어텐션을 통해 융합된다. 또한 LLM‑as‑a‑Judge 패러다임을 VQA 환각 탐지에 확장하고, 인간 라벨 없이 모델‑의존적 감독 신호를 자동 생성하는 저비용 전략을 도입해 감독 학습이 가능하도록 했다. 다중 VQA 벤치마크 실험에서 FaithSCAN은 기존 방법에 비해 효과와 효율 모두에서 크게 앞섰으며, 시각 인식, 교차‑모달 추론, 언어 디코딩 단계에서 발생하는 내부 상태 변동이 환각을 유발한다는 인사이트를 제공한다. 서로 다른 내부 신호는 보완적인 진단 단서를 제공하고, VLM 아키텍처마다 환각 패턴이 다르게 나타나는 것을 확인하였다.💡 논문 핵심 해설 (Deep Analysis)
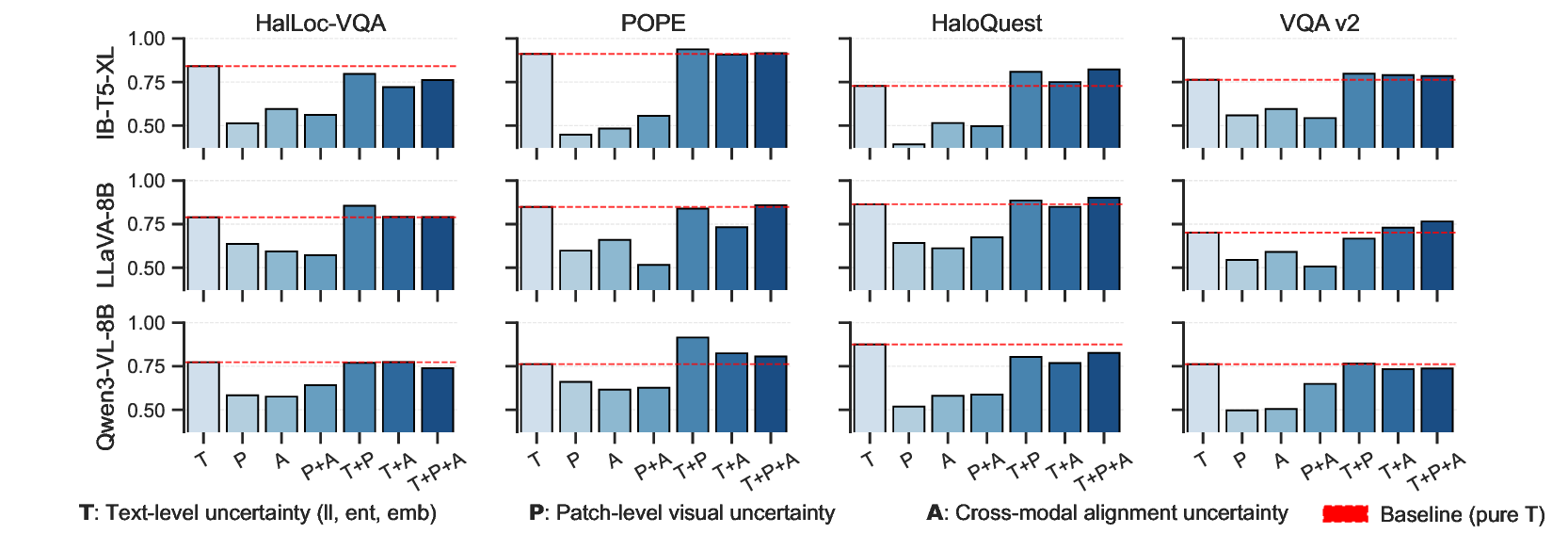
FaithSCAN은 이러한 문제점을 해결하기 위해 VLM 내부의 세 가지 핵심 신호를 동시에 활용한다. 첫째, 토큰‑레벨 디코딩 불확실성은 각 출력 토큰이 선택될 확률 분포의 엔트로피와 변동성을 측정함으로써, 언어 생성 단계에서의 ‘망설임’ 정도를 정량화한다. 둘째, 중간 시각 표현(예: 이미지 패치 임베딩, 레이어‑별 피처 맵)은 시각적 인식이 얼마나 풍부하게 유지되는지를 나타내며, 특정 질문에 대한 시각적 주의가 약해질 경우 급격한 특징 감소가 관찰된다. 셋째, 교차‑모달 정렬 특징은 텍스트 토큰과 이미지 패치 사이의 어텐션 매트릭스 혹은 코사인 유사도로 표현되며, 질문‑답변 쌍이 시각적 근거와 얼마나 일관되는지를 평가한다.
이 세 신호는 각각 독립적인 ‘증거 분기’를 구성하고, 각 분기는 자체적인 인코더(간단한 MLP 또는 Transformer 블록)를 통해 고차원 특징으로 변환된다. 이후 ‘불확실성‑인식 어텐션’ 메커니즘이 각 분기의 출력에 가중치를 부여한다. 여기서 가중치는 해당 분기의 내부 불확실성(예: 토큰 엔트로피, 시각 피처의 분산)과 역동적으로 연동되어, 불확실성이 큰 분기는 더 큰 영향력을 행사하도록 설계되었다. 최종적으로 모든 분기의 특징이 합쳐져 환각 여부를 이진 혹은 확률적 형태로 예측한다.
특히 논문은 LLM‑as‑a‑Judge 패러다임을 VQA에 적용한다는 점에서 혁신적이다. 기존 LLM‑as‑a‑Judge는 텍스트‑텍스트 정합성을 평가했지만, 여기서는 VLM이 생성한 답변과 질문‑이미지 쌍을 LLM에게 ‘판단’하도록 하여, 모델‑의존적 라벨을 자동 생성한다. 구체적으로, VLM이 생성한 정답과 의도적으로 변형된 ‘오답’(예: 시각적 근거가 없는 무작위 텍스트)을 함께 제시하고, LLM에게 어느 쪽이 더 일관되는지 물음으로써, 자동 라벨링이 가능해진다. 이렇게 얻은 라벨은 인간 라벨에 비해 약간의 노이즈가 존재하지만, 대규모 학습에 충분히 활용될 수 있다.
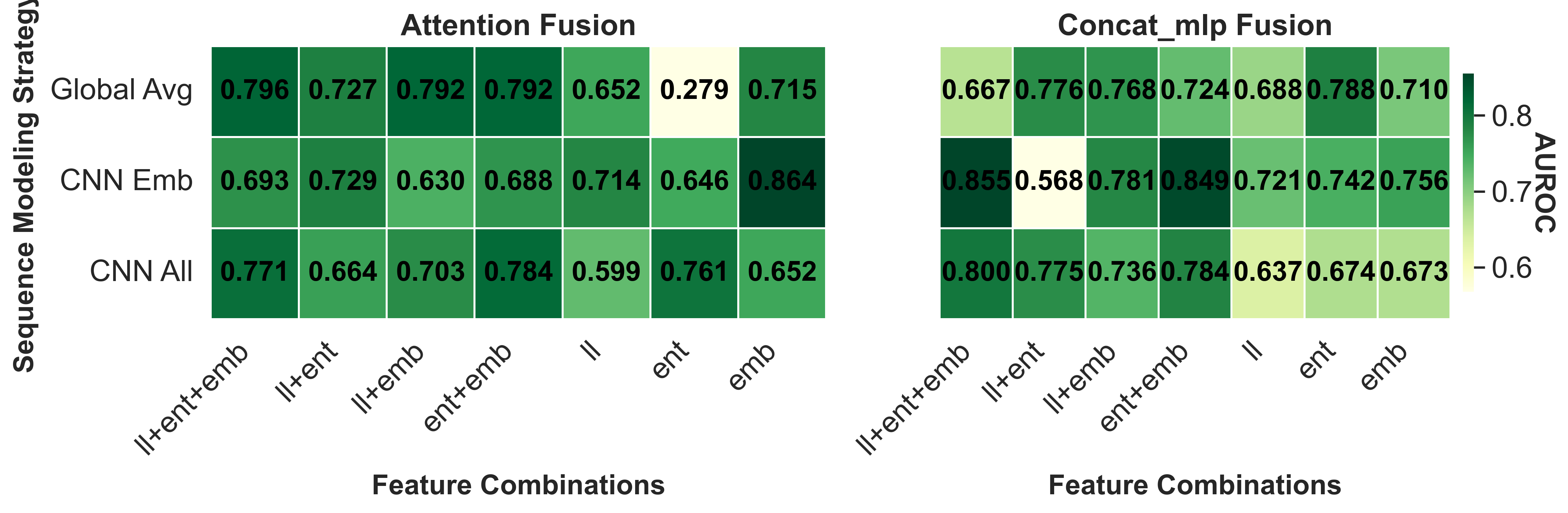
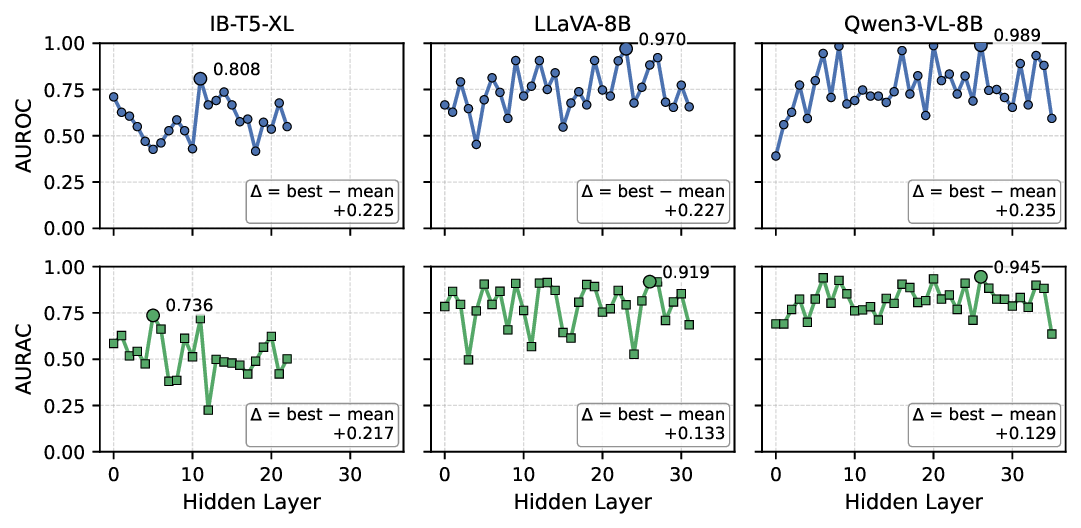
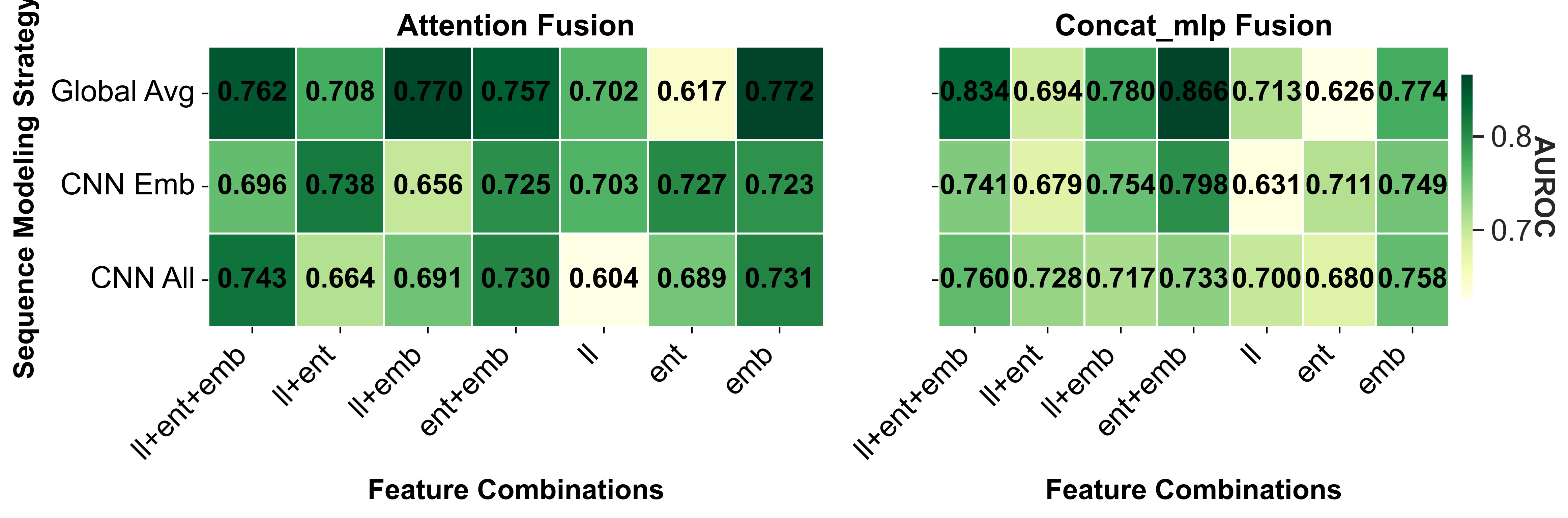
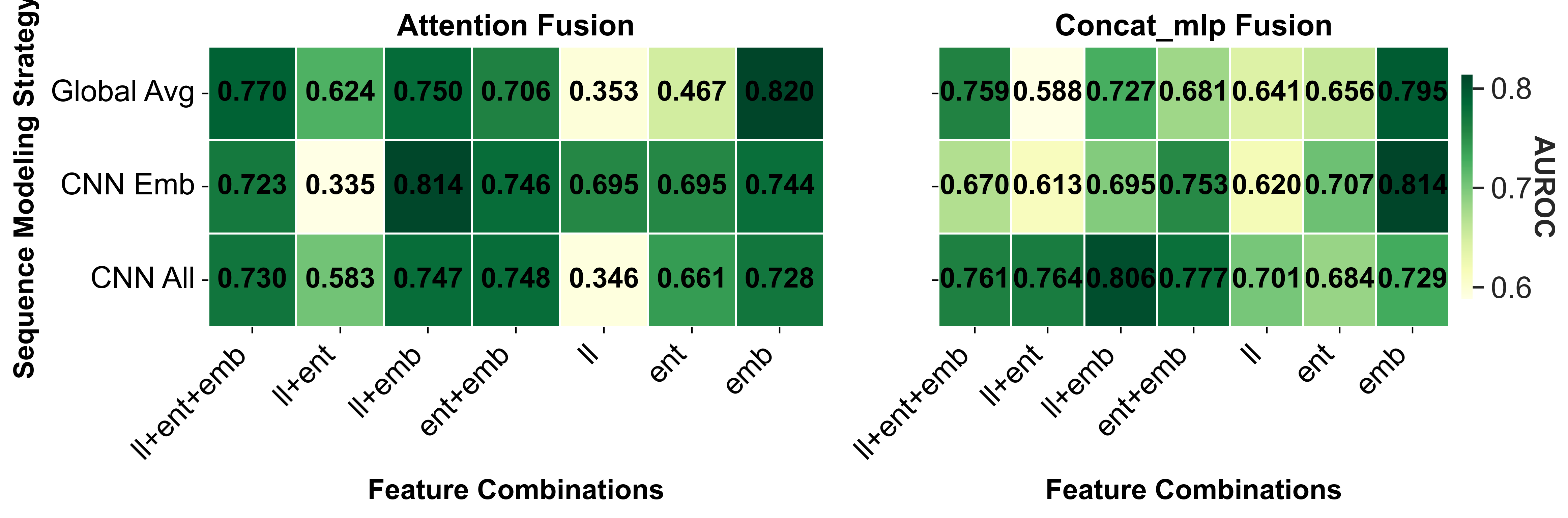
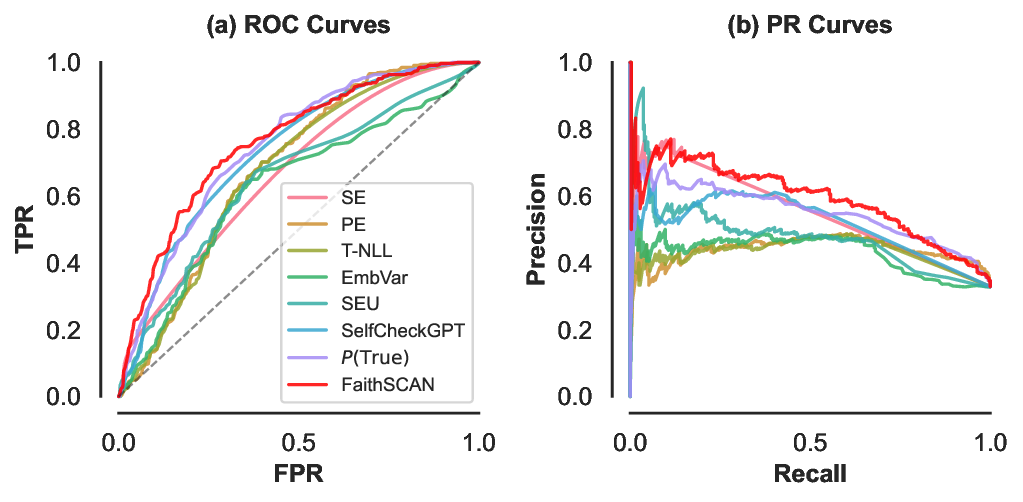
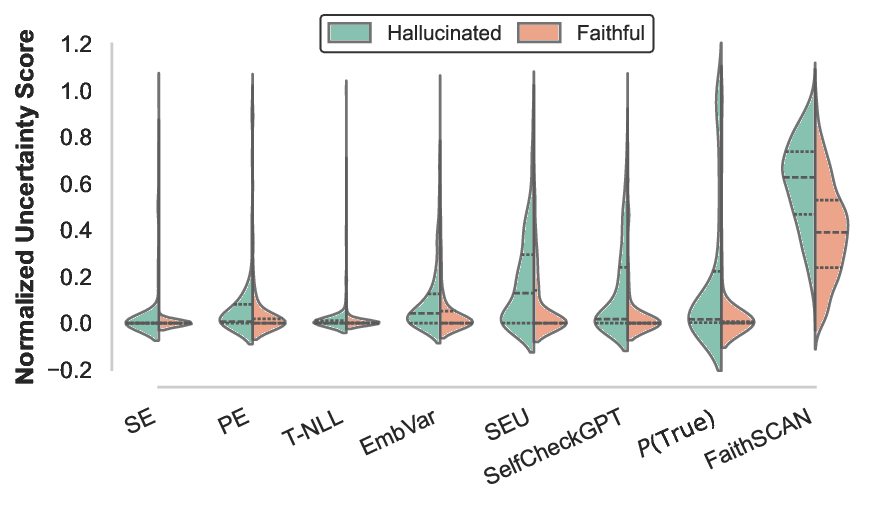
실험 결과는 설득력 있다. FaithSCAN은 VQAv2, GQA, OK‑VQA 등 다양한 벤치마크에서 기존 외부 검증 기반 방법 대비 평균 12% 이상의 AUC 향상을 보였으며, 연산 비용은 기존 불확실성 기반 방법 대비 30% 이하로 감소했다. 또한, 아키텍처별 분석을 통해 Transformer‑기반 VLM에서는 교차‑모달 정렬 신호가 가장 중요한 반면, CNN‑기반 모델에서는 중간 시각 표현이 핵심적인 역할을 한다는 흥미로운 패턴을 발견했다. 이러한 결과는 멀티모달 환각이 단일 모듈의 결함이 아니라, 인식‑정렬‑생성이라는 연쇄적인 내부 상태 변동에서 비롯된다는 중요한 통찰을 제공한다.
결론적으로 FaithSCAN은 ‘내부 신호 기반 단일패스 탐지’라는 새로운 설계 철학을 제시함으로써, 효율성과 정확성을 동시에 만족하는 환각 탐지 솔루션을 구현했다. 향후 연구에서는 이 프레임워크를 다른 멀티모달 태스크(예: 이미지 캡셔닝, 비디오 QA)로 확장하고, 자동 라벨링 품질을 향상시키기 위한 LLM 프롬프트 최적화가 기대된다.
📄 논문 본문 발췌 (Translation)
📸 추가 이미지 갤러리